Recognition: no theorem link
Learnable Quantum Efficiency Filters for Urban Hyperspectral Segmentation
Pith reviewed 2026-05-14 23:32 UTC · model grok-4.3
The pith
Learnable quantum efficiency filters raise segmentation accuracy on hyperspectral urban driving data by enforcing realistic sensor response shapes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LQE parameterizes smooth high-order spectral response functions that emulate plausible sensor quantum efficiency curves. The formulation enforces a single dominant peak, smoothness, and bounded bandwidth so that the resulting low-dimensional representation stays fully differentiable and end-to-end trainable inside semantic segmentation models. Systematic comparison on HyKo, HSI-Drive, and Hyperspectral City shows that, averaged across six segmentation backbones, LQE records the highest mean IoU, exceeding conventional dimensionality-reduction baselines by 2.45 %, 0.45 %, and 1.04 % and unconstrained learnable baselines by 1.18 %, 1.56 %, and 0.81 % respectively, while remaining parameter-fru
What carries the argument
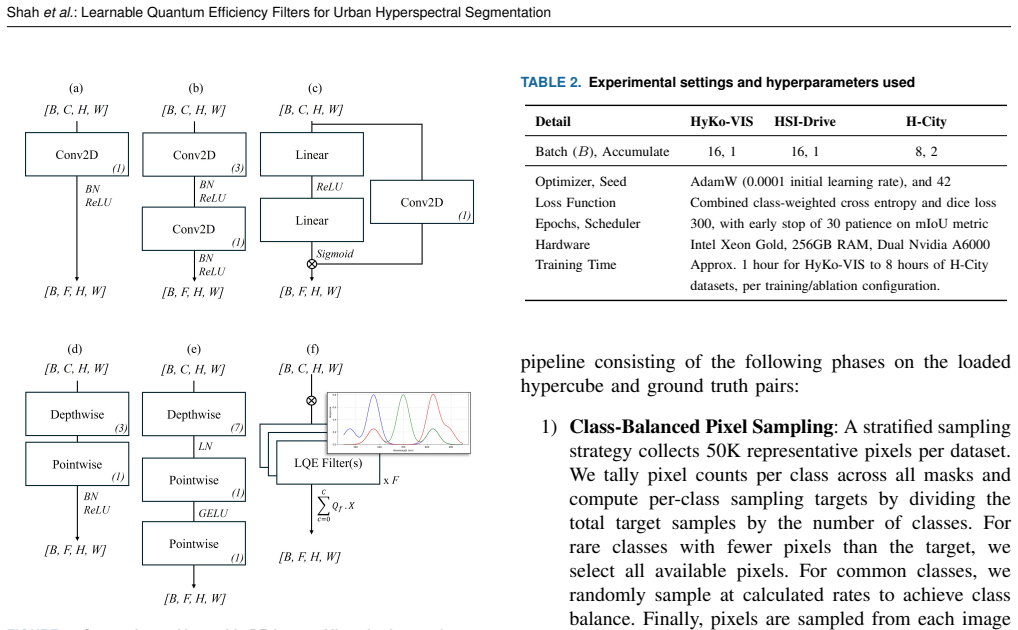
Learnable Quantum Efficiency (LQE) layer: a set of differentiable spectral-response functions constrained to a single dominant peak, smoothness, and bounded bandwidth that replace the first convolutional stage of a segmentation network.
If this is right
- LQE integrates directly into any semantic segmentation architecture as a drop-in, physics-constrained front-end layer.
- The learned filters converge to dataset-specific wavelength patterns, offering an interpretable view of which spectral regions matter most for urban classes.
- Low-order polynomial parameterizations suffice and are optimal, keeping the parameter count between 12 and 36.
- Inference latency remains competitive with conventional dimensionality-reduction methods while delivering measurable accuracy gains.
- The same constrained formulation can serve as a bridge between data-driven training and the design of physical multispectral camera filters.
Where Pith is reading between the lines
- The approach could be used to optimize the spectral bands of future automotive multispectral sensors by treating the learned LQE curves as target filter designs.
- Similar smoothness and peak constraints might improve dimensionality reduction in other high-dimensional sensing tasks such as multispectral satellite imagery or fluorescence microscopy.
- Because the filters remain differentiable, the method opens a route to jointly optimize sensor hardware parameters and downstream perception models in a single training loop.
Load-bearing premise
Enforcing a single dominant peak, smoothness, and bounded bandwidth on the learnable spectral responses preserves all necessary discriminative information for accurate multi-class segmentation without discarding critical urban scene details.
What would settle it
Training the same segmentation backbones on any of the three datasets with the peak or bandwidth constraints removed and observing whether mean IoU rises above the reported LQE figures would falsify the claim that the physical constraints are performance-neutral or beneficial.
Figures




read the original abstract
Hyperspectral sensing provides rich spectral information for scene understanding in urban driving, but its high dimensionality poses challenges for interpretation and efficient learning. We introduce Learnable Quantum Efficiency (LQE), a physics-inspired, interpretable dimensionality reduction (DR) method that parameterizes smooth high-order spectral response functions that emulate plausible sensor quantum efficiency curves. Unlike conventional methods or unconstrained learnable layers, LQE enforces physically motivated constraints, including a single dominant peak, smooth responses, and bounded bandwidth. This formulation yields a compact spectral representation that preserves discriminative information while remaining fully differentiable and end-to-end trainable within semantic segmentation models (SSMs). We conduct systematic evaluations across three publicly available multi-class hyperspectral urban driving datasets, comparing LQE against six conventional and seven learnable baseline DR methods across six SSMs. Averaged across all SSMs and configurations, LQE achieves the highest average mIoU, improving over conventional methods by 2.45\%, 0.45\%, and 1.04\%, and over learnable methods by 1.18\%, 1.56\%, and 0.81\% on HyKo, HSI-Drive, and Hyperspectral City, respectively. LQE maintains strong parameter efficiency (12--36 parameters compared to 51--22K for competing learnable approaches) and competitive inference latency. Ablation studies show that low-order configurations are optimal, while the learned spectral filters converge to dataset-intrinsic wavelength patterns. These results demonstrate that physics-informed spectral learning can improve both performance and interpretability, providing a principled bridge between hyperspectral perception and data-driven multispectral sensor design for automotive vision systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Learnable Quantum Efficiency (LQE) filters as a physics-inspired dimensionality reduction technique for hyperspectral semantic segmentation in urban driving scenes. LQE parameterizes smooth high-order spectral response functions that emulate plausible quantum efficiency curves, enforcing constraints including a single dominant peak, smoothness, and bounded bandwidth. These filters are end-to-end trainable within semantic segmentation models (SSMs) and are evaluated against six conventional and seven learnable baseline DR methods across six SSMs on three public datasets (HyKo, HSI-Drive, Hyperspectral City). The central claim is that LQE achieves the highest average mIoU while using only 12-36 parameters and maintaining competitive inference latency, with reported gains of 2.45%/0.45%/1.04% over conventional methods and 1.18%/1.56%/0.81% over learnable methods on the three datasets respectively. Ablations indicate low-order configurations are optimal and learned filters converge to dataset-intrinsic patterns.
Significance. If the results hold under rigorous controls, the work provides a valuable bridge between physical sensor modeling and data-driven learning for hyperspectral perception. The parameter efficiency and interpretability of the constrained filters are clear strengths, as is the systematic comparison across multiple datasets and models. This could inform future multispectral sensor design for automotive applications by showing that physics priors can yield both performance and efficiency gains without sacrificing end-to-end trainability.
major comments (3)
- [Ablation studies and experimental results] The central claim that the single-dominant-peak, smoothness, and bounded-bandwidth constraints preserve all task-relevant discriminative information is load-bearing but unsupported by a controlled ablation. No experiment compares LQE to an unconstrained learnable filter with matched parameter count (12-36), leaving open the possibility that gains arise from implicit regularization rather than physics fidelity (see ablation studies and results sections).
- [Experimental results] The modest average mIoU improvements (≤2.45% over conventional, ≤1.56% over learnable) are reported as averages across SSMs without per-run standard deviations, statistical significance tests, or variance analysis. This weakens confidence that the gains are robust rather than dataset- or initialization-specific (see quantitative results on HyKo, HSI-Drive, Hyperspectral City).
- [Method formulation and discussion] Urban hyperspectral scenes contain narrow absorption features and multi-modal signatures (e.g., in road surfaces and vehicle paints) that may be pruned by the single-peak constraint. The paper does not test whether these constraints discard critical information via synthetic data with known narrow-band features or by comparing spectral reconstruction error before/after filtering.
minor comments (2)
- [Abstract and experiments] The abstract states evaluation across 'six SSMs' but does not name them; this list should appear in the first paragraph of the experiments section for immediate clarity.
- [Results tables] A consolidated table listing parameter counts and inference latencies for all 13 baseline methods alongside LQE would improve readability and allow direct verification of the efficiency claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the strengths and limitations of our work on Learnable Quantum Efficiency filters. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Ablation studies and experimental results] The central claim that the single-dominant-peak, smoothness, and bounded-bandwidth constraints preserve all task-relevant discriminative information is load-bearing but unsupported by a controlled ablation. No experiment compares LQE to an unconstrained learnable filter with matched parameter count (12-36), leaving open the possibility that gains arise from implicit regularization rather than physics fidelity (see ablation studies and results sections).
Authors: We agree that a direct comparison against an unconstrained learnable filter with an identical parameter budget (12-36) would more rigorously isolate the contribution of the physics constraints versus implicit regularization. Our existing learnable baselines use substantially higher parameter counts (51-22K), so they do not fully address this point. In the revision we will add this controlled ablation, training an unconstrained low-parameter filter under the same experimental protocol and reporting the resulting mIoU differences. revision: yes
-
Referee: [Experimental results] The modest average mIoU improvements (≤2.45% over conventional, ≤1.56% over learnable) are reported as averages across SSMs without per-run standard deviations, statistical significance tests, or variance analysis. This weakens confidence that the gains are robust rather than dataset- or initialization-specific (see quantitative results on HyKo, HSI-Drive, Hyperspectral City).
Authors: We acknowledge that the absence of per-run standard deviations and statistical significance testing limits the strength of the claims. In the revised manuscript we will recompute all tables with means and standard deviations over multiple random seeds, and we will include paired statistical tests (e.g., Wilcoxon signed-rank or t-tests) to assess whether the observed improvements are significant across the six segmentation models. revision: yes
-
Referee: [Method formulation and discussion] Urban hyperspectral scenes contain narrow absorption features and multi-modal signatures (e.g., in road surfaces and vehicle paints) that may be pruned by the single-peak constraint. The paper does not test whether these constraints discard critical information via synthetic data with known narrow-band features or by comparing spectral reconstruction error before/after filtering.
Authors: The single-peak constraint is derived from the typical unimodal shape of real sensor quantum-efficiency curves; however, we recognize that certain urban materials can exhibit multi-modal or narrow-band signatures. We will expand the discussion section to explicitly address this potential limitation and add a quantitative analysis of spectral reconstruction error (L1 or MSE between original and filtered spectra) on the three real datasets. A full synthetic narrow-band experiment is outside the current scope but can be noted as future work; the primary evidence remains the consistent mIoU gains on real urban driving data. revision: partial
Circularity Check
No significant circularity; empirical evaluation on independent datasets
full rationale
The paper defines LQE as a parameterized spectral filter with explicit physical constraints (single dominant peak, smoothness, bounded bandwidth) that are design choices, not derived from the target segmentation performance. These filters are trained end-to-end within SSMs and evaluated via direct mIoU comparisons against conventional and learnable baselines on three public datasets (HyKo, HSI-Drive, Hyperspectral City). No equation or claim reduces by construction to a fitted input renamed as prediction, no self-citation chain supports a uniqueness theorem, and no ansatz is smuggled via prior work. The reported gains (e.g., 2.45% mIoU) are measured outcomes, not definitional. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- LQE filter coefficients =
12-36
axioms (1)
- domain assumption Spectral response functions must exhibit a single dominant peak, smoothness, and bounded bandwidth to emulate plausible sensor quantum efficiency.
Reference graph
Works this paper leans on
-
[1]
How strong metamerism disturbs color spaces,
W. A. Thornton, “How strong metamerism disturbs color spaces,” Color Research & Application: Endorsed by Inter-Society Color Council, The Colour Group (Great Britain), Canadian Society for Color, Color Science Association of Japan, Dutch Society for the Study of Color, The Swedish Colour Centre Foundation, Colour Society of Australia, Centre Français de l...
work page 1998
-
[2]
Recent advances of hyperspectral imaging technology and applications in agriculture,
B. Lu, P. D. Dao, J. Liu, Y . He, and J. Shang, “Recent advances of hyperspectral imaging technology and applications in agriculture,” Remote Sensing, vol. 12, no. 16, p. 2659, 2020
work page 2020
-
[3]
Neural network based pavement condition assessment with hyper- spectral images,
O. B. Özdemir, H. Soydan, Y . Yardımcı Çetin, and H. ¸ S. Düzgün, “Neural network based pavement condition assessment with hyper- spectral images,”Remote Sensing, vol. 12, no. 23, p. 3931, 2020
work page 2020
-
[4]
Pavement crack detection from hyperspectral images using a novel asphalt crack index,
M. Abdellatif, H. Peel, A. G. Cohn, and R. Fuentes, “Pavement crack detection from hyperspectral images using a novel asphalt crack index,”Remote sensing, vol. 12, no. 18, p. 3084, 2020
work page 2020
-
[5]
Hyperspectral vs. rgb for pedestrian segmentation in urban driving scenes: A comparative study,
J. Li, I. A. Shah, D. Geever, E. Ward, M. Glavin, E. Jones, and B. Deegan, “Hyperspectral vs. rgb for pedestrian segmentation in urban driving scenes: A comparative study,” in2025 IEEE International Conference on Vehicular Electronics and Safety (ICVES), 2025, pp. 387–392
work page 2025
-
[6]
Urban scene understanding via hyperspectral images: Dataset and benchmark,
Q. Shen, Y . Huang, T. Ren, Y . Fu, and S. You, “Urban scene understanding via hyperspectral images: Dataset and benchmark,” Available at SSRN 4560035
-
[7]
Hsi-drive v2. 0: More data for new chal- lenges in scene understanding for autonomous driving,
J. Gutiérrez-Zaballa, K. Basterretxea, J. Echanobe, M. V . Martínez, and U. Martinez-Corral, “Hsi-drive v2. 0: More data for new chal- lenges in scene understanding for autonomous driving,” in2023 IEEE Symposium Series on Computational Intelligence (SSCI). IEEE, 2023, pp. 207–214
work page 2023
-
[8]
Sensor technology in autonomous vehicles: A review,
S. Campbell, N. O’Mahony, L. Krpalcova, D. Riordan, J. Walsh, A. Murphy, and C. Ryan, “Sensor technology in autonomous vehicles: A review,” in2018 29th Irish Signals and Systems Conference (ISSC). IEEE, 2018, pp. 1–4
work page 2018
-
[9]
Hyperspectral sensors and autonomous driving: Technologies, limitations, and opportunities,
I. A. Shah, J. Li, R. George, T. Brophy, E. Ward, M. Glavin, E. Jones, and B. Deegan, “Hyperspectral sensors and autonomous driving: Technologies, limitations, and opportunities,”IEEE Open Journal of Vehicular Technology, vol. 7, pp. 124–143, 2026
work page 2026
-
[10]
Spectral textile detection in the vnir/swir band,
J. A. Arneal, “Spectral textile detection in the vnir/swir band,” Tech. Rep., 2015
work page 2015
-
[11]
Snapshot hyperspectral imaging with quantum correlated photons,
Y . Zhang, D. England, and B. Sussman, “Snapshot hyperspectral imaging with quantum correlated photons,”Optics Express, vol. 31, no. 2, pp. 2282–2291, 2023
work page 2023
-
[12]
What are the differences between ASI662MC and ASI462MC?
ZWO ASTRO, “What are the differences between ASI662MC and ASI462MC?” https://www.zwoastro.com/2023/03/13/ what-are-the-differences-between-asi662mc-and-asi462mc/. Published: March 3, 2023. Accessed: October 5, 2025
work page 2023
-
[13]
Road condition estimation using deep learning with hyperspectral images: detection of water and snow
D. Valme, J. Galindos, and D. C. Liyanage, “Road condition estimation using deep learning with hyperspectral images: detection of water and snow.”Proceedings of the Estonian Academy of Sciences, vol. 73, no. 1, 2024
work page 2024
-
[14]
CSNR and JMIM Based Spectral Band Selection for Reducing Metamerism in Urban Driving
J. Li, I. A. Shah, D. Geever, F. Collins, E. Ward, M. Glavin, E. Jones, and B. Deegan, “Csnr and jmim based spectral band selection for reducing metamerism in urban driving,” 2025. [Online]. Available: https://arxiv.org/abs/2508.10962 VOLUME 00, 2024 11 Shahet al.: Learnable Quantum Efficiency Filters for Urban Hyperspectral Segmentation
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Hyko: A spectral dataset for scene understanding,
C. Winkens, F. Sattler, V . Adams, and D. Paulus, “Hyko: A spectral dataset for scene understanding,” inProceedings of the IEEE Interna- tional Conference on Computer Vision Workshops, 2017, pp. 254–261
work page 2017
-
[16]
Liii. on lines and planes of closest fit to systems of points in space,
K. Pearson, “Liii. on lines and planes of closest fit to systems of points in space,”The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, vol. 2, no. 11, pp. 559–572, 1901. [Online]. Available: https://doi.org/10.1080/14786440109462720
-
[17]
Independent component analysis: algo- rithms and applications,
A. Hyvärinen and E. Oja, “Independent component analysis: algo- rithms and applications,”Neural networks, vol. 13, no. 4-5, pp. 411– 430, 2000
work page 2000
-
[18]
Dimensionality reduction of image features using the canonical contextual correlation projection,
M. Loog, B. v. Ginneken, and R. P. W. Duin, “Dimensionality reduction of image features using the canonical contextual correlation projection,”Pattern Recognition, vol. 38, no. 12, pp. 2409–2418, 2005. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0031320305001974
work page 2005
-
[19]
Nonlinear dimensionality reduction by locally linear embedding,
S. T. Roweis and L. K. Saul, “Nonlinear dimensionality reduction by locally linear embedding,”science, vol. 290, no. 5500, pp. 2323–2326, 2000
work page 2000
-
[20]
A global geometric framework for nonlinear dimensionality reduction,
J. B. Tenenbaum, V . d. Silva, and J. C. Langford, “A global geometric framework for nonlinear dimensionality reduction,”science, vol. 290, no. 5500, pp. 2319–2323, 2000
work page 2000
-
[21]
A. A. Green, M. Berman, P. Switzer, and M. D. Craig, “A transfor- mation for ordering multispectral data in terms of image quality with implications for noise removal,”IEEE Transactions on geoscience and remote sensing, vol. 26, no. 1, pp. 65–74, 1988
work page 1988
-
[22]
Learning the parts of objects by non- negative matrix factorization,
D. D. Lee and H. S. Seung, “Learning the parts of objects by non- negative matrix factorization,”nature, vol. 401, no. 6755, pp. 788–791, 1999
work page 1999
-
[23]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
work page 2016
-
[24]
Hyperspectral image classifica- tion using deep pixel-pair features,
W. Li, G. Wu, F. Zhang, and Q. Du, “Hyperspectral image classifica- tion using deep pixel-pair features,”IEEE Transactions on Geoscience and Remote Sensing, vol. 55, no. 2, pp. 844–853, 2016
work page 2016
-
[25]
Deep learning-based classification of hyperspectral data,
Y . Chen, Z. Lin, X. Zhao, G. Wang, and Y . Gu, “Deep learning-based classification of hyperspectral data,”IEEE Journal of Selected topics in applied earth observations and remote sensing, vol. 7, no. 6, pp. 2094–2107, 2014
work page 2094
-
[26]
Cbam: Convolutional block attention module,
S. Woo, J. Park, J.-Y . Lee, and I. S. Kweon, “Cbam: Convolutional block attention module,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 3–19
work page 2018
-
[27]
Q. A. Dang and D. D. Nguyen, “Coordinate attention unet.” in ROBOVIS, 2021, pp. 122–127
work page 2021
-
[28]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141
work page 2018
-
[29]
Learning sensor multiplexing design through back- propagation,
A. Chakrabarti, “Learning sensor multiplexing design through back- propagation,”Advances in Neural Information Processing Systems, vol. 29, 2016
work page 2016
-
[30]
Differen- tiable compound optics and processing pipeline optimization for end- to-end camera design,
E. Tseng, A. Mosleh, F. Mannan, K. St-Arnaud, A. Sharma, Y . Peng, A. Braun, D. Nowrouzezahrai, J.-F. Lalonde, and F. Heide, “Differen- tiable compound optics and processing pipeline optimization for end- to-end camera design,”ACM Transactions on Graphics (TOG), vol. 40, no. 2, pp. 1–19, 2021
work page 2021
-
[31]
Wavelength- aware 2d convolutions for hyperspectral imaging,
L. A. Varga, M. Messmer, N. Benbarka, and A. Zell, “Wavelength- aware 2d convolutions for hyperspectral imaging,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 3788–3797
work page 2023
-
[32]
Cycleisp: Real image restoration via improved data synthesis,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, and L. Shao, “Cycleisp: Real image restoration via improved data synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2696–2705
work page 2020
-
[33]
Unsupervised learning of invariant feature hierarchies with applications to object recognition,
M. Ranzato, F. J. Huang, Y .-L. Boureau, and Y . LeCun, “Unsupervised learning of invariant feature hierarchies with applications to object recognition,” in2007 IEEE conference on computer vision and pattern recognition. IEEE, 2007, pp. 1–8
work page 2007
-
[34]
Stacked convolutional auto-encoders for hierarchical feature extraction,
J. Masci, U. Meier, D. Cire¸ san, and J. Schmidhuber, “Stacked convolutional auto-encoders for hierarchical feature extraction,” in International conference on artificial neural networks. Springer, 2011, pp. 52–59
work page 2011
-
[35]
Eca-net: Efficient channel attention for deep convolutional neural networks,
Q. Wang, B. Wu, P. Zhu, P. Li, W. Zuo, and Q. Hu, “Eca-net: Efficient channel attention for deep convolutional neural networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 534–11 542
work page 2020
-
[36]
Xception: Deep learning with depthwise separable convo- lutions,
F. Chollet, “Xception: Deep learning with depthwise separable convo- lutions,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1251–1258
work page 2017
-
[37]
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 976–11 986. 12 VOLUME 00, 2024
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.