Recognition: 2 theorem links
· Lean TheoremTunable Domain Adaptation Using Unfolding
Pith reviewed 2026-05-14 23:24 UTC · model grok-4.3
The pith
Unrolled networks enable tunable domain adaptation for regression tasks at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
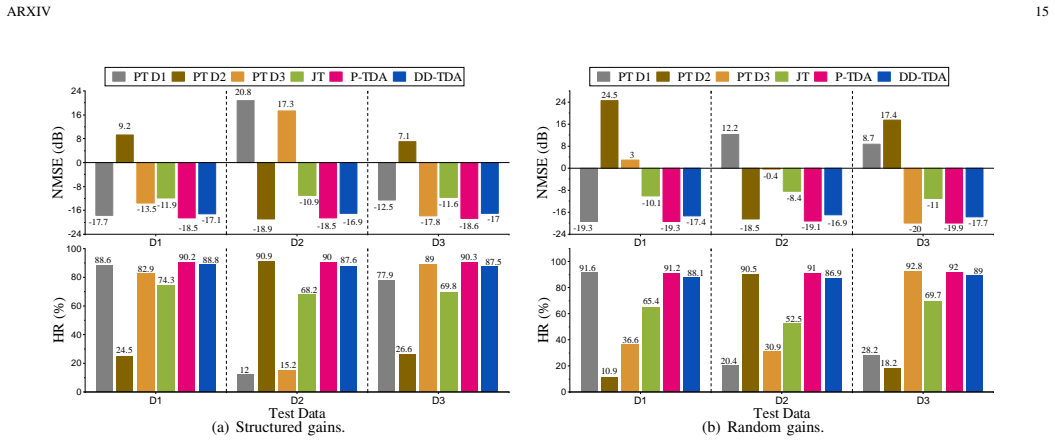
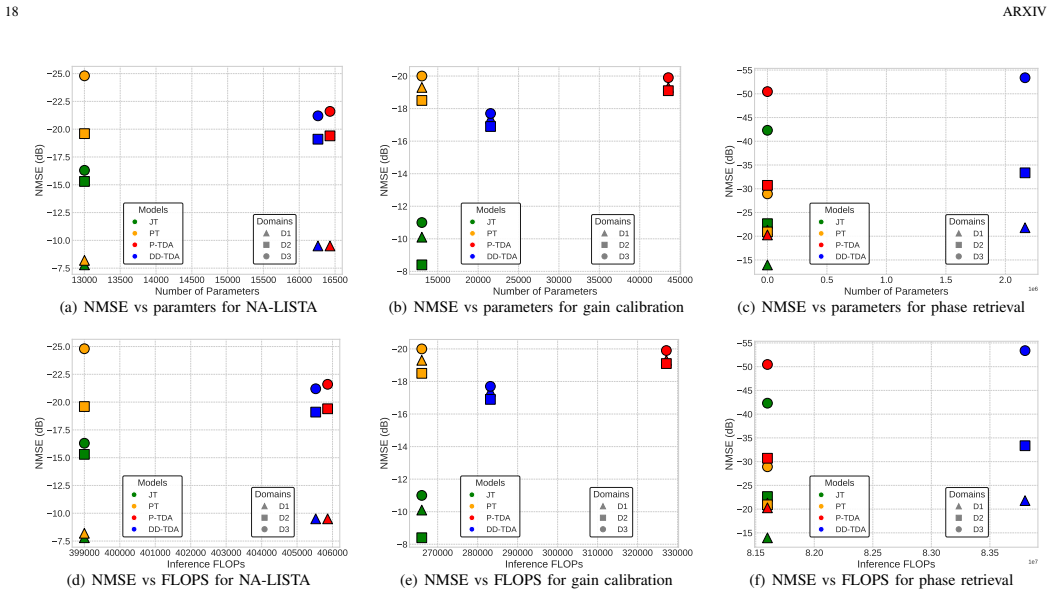
The central claim is that interpretable unrolled networks, derived from iterative optimization algorithms, achieve effective domain adaptation in regression by exploiting the functional dependence of tunable parameters on domain variables. This yields two concrete methods: P-TDA, which incorporates known domain parameters for controlled adjustment at inference, and DD-TDA, which learns to infer domain adaptation from the input itself. Experiments on noise-adaptive sparse signal recovery and related compressed sensing tasks show these methods match or exceed the accuracy of domain-specific models while outperforming standard joint-training baselines.
What carries the argument
Interpretable unrolled networks that embed domain-dependent tunable parameters to enable controlled adaptation during inference without retraining.
If this is right
- Outperforms joint training baselines across multiple compressed sensing regression tasks.
- Achieves accuracy comparable to separately trained domain-specific models.
- Supports adaptation to varying noise without requiring full retraining per domain.
- Extends to gain calibration and phase retrieval problems under domain shifts.
- Preserves interpretability by tying parameter changes directly to domain variables.
Where Pith is reading between the lines
- The same unrolling strategy could reduce storage and compute costs when deploying models across many similar but non-identical environments.
- Applying DD-TDA to regression tasks outside compressed sensing, such as time-series forecasting with sensor drift, would test whether inference-time inference of domain variables generalizes.
- Combining these tunable parameters with other iterative algorithms might yield adaptation rules that remain stable even when domain variables are only partially observed.
Load-bearing premise
That the functional dependence of select tunable parameters on domain variables can be leveraged to enable controlled adaptation during inference without degrading performance on the core task.
What would settle it
If a P-TDA or DD-TDA model applied to a held-out domain with an unseen noise level produces higher reconstruction error than a model trained specifically on that domain.
Figures













read the original abstract
Machine learning models often struggle to generalize across domains with varying data distributions, such as differing noise levels, leading to degraded performance. Traditional strategies like personalized training, which trains separate models per domain, and joint training, which uses a single model for all domains, have significant limitations in flexibility and effectiveness. To address this, we propose two novel domain adaptation methods for regression tasks based on interpretable unrolled networks--deep architectures inspired by iterative optimization algorithms. These models leverage the functional dependence of select tunable parameters on domain variables, enabling controlled adaptation during inference. Our methods include Parametric Tunable-Domain Adaptation (P-TDA), which uses known domain parameters for dynamic tuning, and Data-Driven Tunable-Domain Adaptation (DD-TDA), which infers domain adaptation directly from input data. We validate our approach on compressed sensing problems involving noise-adaptive sparse signal recovery, domain-adaptive gain calibration, and domain-adaptive phase retrieval, demonstrating improved or comparable performance to domain-specific models while surpassing joint training baselines. This work highlights the potential of unrolled networks for effective, interpretable domain adaptation in regression settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two novel domain adaptation methods for regression tasks, Parametric Tunable-Domain Adaptation (P-TDA) and Data-Driven Tunable-Domain Adaptation (DD-TDA), based on interpretable unrolled networks. These leverage the functional dependence of select tunable parameters on domain variables to enable controlled adaptation during inference. The methods are validated on three compressed sensing problems (noise-adaptive sparse signal recovery, domain-adaptive gain calibration, and domain-adaptive phase retrieval), claiming performance that is improved or comparable to domain-specific models while surpassing joint training baselines.
Significance. If the empirical results hold with full details, the work provides a flexible, interpretable alternative to personalized or joint training for handling domain shifts in regression settings, particularly in signal processing applications. The use of unrolled networks for tunable adaptation could advance domain adaptation by avoiding full retraining while maintaining performance.
major comments (2)
- [Experiments] Experiments section: the abstract reports validation on three compressed sensing problems with claims of improved performance, but without full details on metrics, baselines, error analysis, or statistical significance, the support for the central claim that the methods match domain-specific models remains unverified. Please provide quantitative tables and ablation studies.
- [Method] Method description (P-TDA and DD-TDA): the functional dependence of tunable parameters on domain variables is load-bearing for the adaptation claim; clarify the exact parameterization and training procedure to ensure it does not implicitly rely on target-domain information during inference.
minor comments (2)
- [Abstract] Abstract: the description of the three problems is clear but could briefly note the specific domain variables (e.g., noise levels) used in each to aid reader understanding.
- [Notation] Notation: ensure consistent use of symbols for domain variables and tunable parameters across equations and text to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract reports validation on three compressed sensing problems with claims of improved performance, but without full details on metrics, baselines, error analysis, or statistical significance, the support for the central claim that the methods match domain-specific models remains unverified. Please provide quantitative tables and ablation studies.
Authors: We agree that expanded experimental details will better support the claims. In the revised manuscript we will add comprehensive quantitative tables reporting metrics such as MSE and recovery error for P-TDA, DD-TDA, domain-specific models, and joint-training baselines across all three tasks (noise-adaptive sparse recovery, gain calibration, and phase retrieval). We will also include ablation studies on the functional mappings and tunable parameters, plus error bars and statistical significance (paired t-tests or Wilcoxon tests over 10+ random seeds) to verify that performance is improved or comparable to domain-specific models. revision: yes
-
Referee: [Method] Method description (P-TDA and DD-TDA): the functional dependence of tunable parameters on domain variables is load-bearing for the adaptation claim; clarify the exact parameterization and training procedure to ensure it does not implicitly rely on target-domain information during inference.
Authors: We will clarify the parameterization and training procedure in the revised Method section. For P-TDA the tunable parameters (e.g., step sizes or thresholds in the unrolled iterations) are expressed as an explicit function of the known domain variable (noise level, gain factor, etc.), implemented as a small neural network or polynomial whose weights are learned during multi-domain training; at inference only the scalar domain variable is supplied and no target-domain samples or labels are used. For DD-TDA an auxiliary network predicts the domain variable (or directly the parameters) solely from the input measurement vector. We will add explicit equations, a training pseudocode block, and a statement confirming that inference uses neither target data nor target labels. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes P-TDA and DD-TDA as modeling choices that leverage functional dependence of tunable parameters on domain variables within standard unrolled network architectures. This is presented as an empirical design for controlled adaptation rather than a derivation that reduces to fitted inputs by construction. Validation consists of direct performance comparisons on three compressed sensing tasks against domain-specific and joint-training baselines, with no self-definitional equations, no predictions that are statistically forced by prior fits, and no load-bearing self-citations whose content is itself unverified. The central claims rest on external empirical results and architectural inspiration, remaining self-contained against benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unrolled networks can incorporate functional dependence of tunable parameters on domain variables for controlled adaptation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
leverage the functional dependence of select tunable parameters on domain variables, enabling controlled adaptation during inference
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unfolded network architecture is derived from a parametric optimization algorithm
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
How transferable are features in deep neural networks?
J. Yosinski, J. Clune, Y . Bengio, and H. Lipson, “How transferable are features in deep neural networks?” inProc. Adv. Neural Info. Process. Sys. (NeurIPS), 2014, pp. 3320–3328. ARXIV 19
work page 2014
-
[2]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Int. Conf. Comput. Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
work page 2016
-
[3]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProc. North American Chap. Asso. Comput. Linguistics (NAACL-HLT), 2019, pp. 4171–4186
work page 2019
-
[4]
A survey on transfer learning,
S. J. Pan and Q. Yang, “A survey on transfer learning,”IEEE Trans. Knowl. Data Eng., vol. 22, no. 10, pp. 1345–1359, 2010
work page 2010
-
[5]
Interpretations of domain adaptations via layer variational analysis,
H.-H. Tseng, H.-Y . Lin, K.-H. Hung, and Y . Tsao, “Interpretations of domain adaptations via layer variational analysis,”arXiv preprint arXiv:2302.01798, 2023
-
[6]
Gradual domain adaptation: Theory and algorithms,
Y . He, H. Wang, B. Li, and H. Zhao, “Gradual domain adaptation: Theory and algorithms,”J Machine Learning Res., vol. 25, no. 361, pp. 1–40, 2024
work page 2024
-
[7]
A brief review of domain adaptation,
A. Farahani, S. V oghoei, K. Rasheed, and H. R. Arabnia, “A brief review of domain adaptation,” inProc. Adv. Data Sci. Info. Engg.Cham: Springer International Publishing, 2021, pp. 877–894
work page 2021
-
[8]
Deep domain adaptation for regression,
A. Singh and S. Chakraborty, “Deep domain adaptation for regression,” inDevelopment and Analysis of Deep Learning Architectures. Springer, 2019, pp. 91–115
work page 2019
-
[10]
S. Li, T. T. Cai, and H. Li, “Transfer learning for high-dimensional linear regression: Prediction, estimation and minimax optimality,”J. Royal Stat. Society Series B: Statistical Methodology, vol. 84, no. 1, pp. 149–173, 2022
work page 2022
-
[11]
W. Mao, K. Liu, Y . Zhang, X. Liang, and Z. Wang, “Self-supervised deep tensor domain-adversarial regression adaptation for online remaining useful life prediction across machines,”IEEE Trans. Inst. Meas., vol. 72, pp. 1–16, 2023
work page 2023
-
[12]
Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing,
V . Monga, Y . Li, and Y . C. Eldar, “Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing,”IEEE Mag. Signal Processing, vol. 38, no. 2, pp. 18–44, 2021
work page 2021
-
[13]
D. Donoho, “Compressed sensing,”IEEE Trans. Inf. Theory, vol. 52, no. 4, pp. 1289–1306, 2006
work page 2006
-
[14]
An iterative thresholding al- gorithm for linear inverse problems with a sparsity constraint,
I. Daubechies, M. Defrise, and C. De Mol, “An iterative thresholding al- gorithm for linear inverse problems with a sparsity constraint,”Commun. Pure Applied Math., vol. 57, no. 11, pp. 1413–1457, 2004
work page 2004
-
[15]
Learning fast approximations of sparse coding,
K. Gregor and Y . LeCun, “Learning fast approximations of sparse coding,” inProc. Int. Conf. Machine Learn. (ICML), 2010, pp. 399– 406
work page 2010
-
[16]
Ideal spatial adaptation by wavelet shrinkage,
D. L. Donoho and I. M. Johnstone, “Ideal spatial adaptation by wavelet shrinkage,”Biometrika, vol. 81, no. 3, pp. 425–455, 1994
work page 1994
-
[17]
Spot- tune: transfer learning through adaptive fine-tuning,
Y . Guo, H. Shi, A. Kumar, K. Grauman, T. Rosing, and R. Feris, “Spot- tune: transfer learning through adaptive fine-tuning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4805–4814
work page 2019
-
[18]
Transfer feature learning with joint distribution adaptation,
M. Long, J. Wang, G. Ding, J. Sun, and P. S. Yu, “Transfer feature learning with joint distribution adaptation,” inProc. Int. Conf. Computer Vision (ICCV), 2013, pp. 2200–2207
work page 2013
-
[19]
Learning transferable features with deep adaptation networks,
M. Long, Y . Cao, J. Wang, and M. I. Jordan, “Learning transferable features with deep adaptation networks,” inProc. Int. Conf. on Machine Learning (ICML), 2015, pp. 97–105
work page 2015
-
[20]
Deep Domain Confusion: Maximizing for Domain Invariance
E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, and T. Darrell, “Deep domain confusion: Maximizing for domain invariance,”arXiv preprint arXiv:1412.3474, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
Unified deep supervised domain adaptation and generalization,
S. Motiian, M. Piccirilli, D. A. Adjeroh, and G. Doretto, “Unified deep supervised domain adaptation and generalization,” inProc. Int. Conf. Computer Vision (ICCV), 2017, pp. 5715–5725
work page 2017
-
[22]
Transfer learning for linear regression: A statistical test of gain,
B. Tolooshams, X. Wang, X. He, Y . Zhang, and M. Jacob, “Transfer learning for linear regression: A statistical test of gain,” inarXiv preprint arXiv:2102.09504, 2021
-
[23]
Deep domain adaptation for regression,
Y . Lu, J. Qin, and Y . Wang, “Deep domain adaptation for regression,” inProc. Int. Conf. Machine Learning (ICML), 2019, pp. 97–105
work page 2019
-
[24]
Transfer learning for high-dimensional linear regression: Prediction via information borrowing,
H. Li, Y . Wang, and X. Xie, “Transfer learning for high-dimensional linear regression: Prediction via information borrowing,”J. Royal Sta- tistical Soc.: Series B, vol. 84, no. 1, pp. 149–175, 2023
work page 2023
-
[25]
Representation transfer learning for semiparametric regression,
Y . Zhang, X. Wang, and X. He, “Representation transfer learning for semiparametric regression,”arXiv preprint arXiv:2406.13197, 2024
-
[26]
Self-supervised deep domain-adversarial regression adaptation for remaining useful life prediction,
W. Chen, Y . Li, and Y . Zhou, “Self-supervised deep domain-adversarial regression adaptation for remaining useful life prediction,” inIEEE Trans. Ind. Electron., 2022, p. 9769904
work page 2022
-
[27]
Boosting for regression transfer,
D. Pardoe and P. Stone, “Boosting for regression transfer,” inProc. Int. Conf. on Machine Learning (ICML), 2010, pp. 863–870
work page 2010
-
[28]
Algorithm-Induced Prior for Image Restoration
S. H. Chan, “Algorithm-induced prior for image restoration,”arXiv preprint arXiv:1602.00715, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
A. Beck and M. Teboulle, “A fast iterative shrinkage-thresholding algorithm with application to wavelet-based image deblurring,” inProc. IEEE Int. Conf. Acoust., Speech, and Signal Process. (ICASSP), 2009, pp. 693–696
work page 2009
-
[30]
Ada-lista: Learned solvers adaptive to varying models,
A. Aberdam, A. Golts, and M. Elad, “Ada-lista: Learned solvers adaptive to varying models,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 12, pp. 9222–9235, 2021
work page 2021
-
[31]
Theoretical linear convergence of unfolded ISTA and its practical weights and thresholds,
X. Chen, J. Liu, Z. Wang, and W. Yin, “Theoretical linear convergence of unfolded ISTA and its practical weights and thresholds,”Adv. Neural Info. Process. Syst., vol. 31, 2018
work page 2018
-
[32]
ALISTA: Analytic weights are as good as learned weights in LISTA,
J. Liu and X. Chen, “ALISTA: Analytic weights are as good as learned weights in LISTA,” inInt. Conf. Learning Representations (ICLR), 2019
work page 2019
-
[33]
Hyperparameter tuning is all you need for LISTA,
X. Chen, J. Liu, Z. Wang, and W. Yin, “Hyperparameter tuning is all you need for LISTA,”Adv. Neural Info. Process. Syst., vol. 34, pp. 11 678–11 689, 2021
work page 2021
-
[34]
Learned ISTA with error-based thresholding for adaptive sparse coding,
Z. Li, K. Wu, Y . Guo, and C. Zhang, “Learned ISTA with error-based thresholding for adaptive sparse coding,” inInt. Conf. Acoust. Speech Signal Process. (ICASSP). IEEE, 2024, pp. 9301–9305
work page 2024
-
[35]
N. P. Galatsanos and A. K. Katsaggelos, “Methods for choosing the regularization parameter and estimating the noise variance in image restoration and their relation,”IEEE Trans. Image Process., vol. 1, no. 3, pp. 322–336, 1992
work page 1992
-
[36]
Automatic estimation and removal of noise from a single image,
C. Liu, R. Szeliski, S. B. Kang, C. L. Zitnick, and W. T. Freeman, “Automatic estimation and removal of noise from a single image,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 30, no. 2, pp. 299–314, 2008
work page 2008
-
[37]
Noise level estimation using weak textured patches of a single noisy image,
X. Liu, M. Tanaka, and M. Okutomi, “Noise level estimation using weak textured patches of a single noisy image,” inInt. Conf. Image Process. IEEE, 2012, pp. 665–668
work page 2012
-
[38]
Generalized cross-validation as a method for choosing a good ridge parameter,
G. H. Golub, M. Heath, and G. Wahba, “Generalized cross-validation as a method for choosing a good ridge parameter,”Technometrics, vol. 21, no. 2, pp. 215–223, 1979
work page 1979
-
[39]
Deep unfolding of tail-based methods for robust sparse recovery under noise and model mismatch,
Y . Kvich, P. Reshma, P. Pradhan, R. Randhi, and Y . C. Eldar, “Deep unfolding of tail-based methods for robust sparse recovery under noise and model mismatch,”IEEE Trans. on Neural Networks and Learning Systems, 2025
work page 2025
-
[40]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[41]
Mnist handwritten digit classifier (handwritten- digit-recognition),
A. Jhawar, “Mnist handwritten digit classifier (handwritten- digit-recognition),” https://github.com/aakashjhawar/ handwritten-digit-recognition, 2018, gitHub repository
work page 2018
-
[42]
Calibration of time-of-flight range imaging cameras,
O. Steiger, J. Felder, and S. Weiss, “Calibration of time-of-flight range imaging cameras,” inProc. Int. Conf. on Image Process.IEEE, 2008, pp. 1968–1971
work page 2008
-
[43]
Calibration of time-of-flight cameras for accurate intraoperative surface reconstruction,
S. Mersmann, A. Seitel, M. Erz, B. J ¨ahne, F. Nickel, M. Mieth, A. Mehrabi, and L. Maier-Hein, “Calibration of time-of-flight cameras for accurate intraoperative surface reconstruction,”Medical Physics, vol. 40, no. 8, p. 082701, 2013
work page 2013
-
[44]
Direction of arrival estimation by eigenstruc- ture methods with unknown sensor gain and phase,
A. Paulraj and T. Kailath, “Direction of arrival estimation by eigenstruc- ture methods with unknown sensor gain and phase,” inProc. IEEE Int. Conf. Acoust., Speech, and Signal Process. (ICASSP), vol. 10, 1985, pp. 640–643
work page 1985
-
[45]
Blind calibration in compressed sensing using message passing algorithms,
C. Schulke, F. Caltagirone, F. Krzakala, and L. Zdeborov ´a, “Blind calibration in compressed sensing using message passing algorithms,” Adv. Neural Info. Process. Syst., vol. 26, 2013
work page 2013
-
[46]
Unrolled compressed blind-deconvolution,
B. Tolooshams, S. Mulleti, D. Ba, and Y . C. Eldar, “Unrolled compressed blind-deconvolution,”IEEE Trans. Signal Process., vol. 71, pp. 2118– 2129, 2023
work page 2023
-
[47]
Sparse phase retrieval via truncated amplitude flow,
G. Wang, L. Zhang, G. B. Giannakis, M. Akc ¸akaya, and J. Chen, “Sparse phase retrieval via truncated amplitude flow,”IEEE Transactions on Signal Processing, vol. 66, no. 2, pp. 479–491, 2017
work page 2017
-
[48]
Unfolded algorithms for deep phase retrieval,
N. Naimipour, S. Khobahi, M. Soltanalian, H. Safavi, and H. C. Shaw, “Unfolded algorithms for deep phase retrieval,”Algorithms, vol. 17, no. 12, p. 587, 2024
work page 2024
-
[49]
A fast and provable algorithm for sparse phase retrieval,
J. F. CAI, Y . Long, R. WEN, and J. Ying, “A fast and provable algorithm for sparse phase retrieval,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[50]
Estimating unknown sparsity in compressed sensing,
M. Lopes, “Estimating unknown sparsity in compressed sensing,” in International Conference on Machine Learning. PMLR, 2013, pp. 217–225
work page 2013
-
[51]
Sparsity order estima- tion for compressed sensing system using sparse binary sensing matrix,
S. Thiruppathirajan, S. Sreelal, B. Manojet al., “Sparsity order estima- tion for compressed sensing system using sparse binary sensing matrix,” IEEE Access, vol. 10, pp. 33 370–33 392, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.