Recognition: no theorem link
A Security Analysis of the OpenClaw AI Agent Framework
Pith reviewed 2026-05-15 06:42 UTC · model grok-4.3
The pith
OpenClaw permits unauthenticated remote code execution via three chained vulnerabilities from LLM tool calls to the host.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
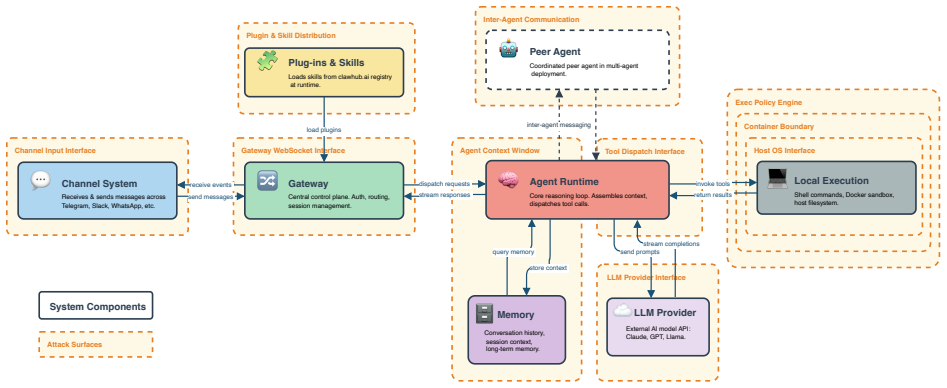
Patch-differential evidence yields three principal findings. First, three Moderate- or High-severity advisories in the Gateway and Node-Host subsystems compose into a complete unauthenticated remote code execution (RCE) path -- spanning delivery, exploitation, and command-and-control -- from an LLM tool call to the host process. Second, the exec allowlist, the primary command-filtering mechanism, relies on a closed-world assumption that command identity is recoverable via lexical parsing. This is invalidated by shell line continuation, busybox multiplexing, and GNU option abbreviation. Third, a malicious skill distributed via the plugin channel executed a two-stage dropper within the LLM con
What carries the argument
Cross-layer composition of vulnerabilities in the Gateway and Node-Host subsystems, which chains delivery, exploitation, and command-and-control stages into a full unauthenticated RCE path from LLM tool call to host execution.
If this is right
- Three moderate- or high-severity advisories combine into an unauthenticated RCE path from LLM tool call to host process.
- The exec allowlist is defeated by shell line continuation, busybox multiplexing, and GNU option abbreviation.
- Malicious skills distributed through the plugin channel can execute two-stage droppers that bypass the exec pipeline.
- Per-layer trust enforcement leaves systems open to cross-layer attacks that resist local remediation.
Where Pith is reading between the lines
- Other LLM-connected agent frameworks that rely on layered rather than unified policy boundaries are likely exposed to similar composition attacks.
- Runtime checks at the plugin ingestion surface could block the dropper bypass shown in the third finding.
- A broader survey of additional agent runtimes using the same taxonomy axes could test whether the clustering pattern holds outside OpenClaw.
Load-bearing premise
The collected advisories and patch-differential analysis accurately reflect exploitable compositions without unaccounted mitigations or misclassifications that would prevent the RCE path from functioning as described.
What would settle it
A concrete test that either successfully executes the full three-advisory RCE chain on an OpenClaw instance with the reported vulnerabilities or shows that the chain is blocked by mitigations not accounted for in the analysis would settle the claim.
Figures




read the original abstract
AI agent frameworks connecting large language model (LLM) reasoning to host execution surfaces -- shell, filesystem, containers, and messaging -- introduce security challenges structurally distinct from conventional software. We present a systematic taxonomy of 470 advisories filed against OpenClaw, an open-source AI agent runtime, organized by architectural layer and trust-violation type. Vulnerabilities cluster along two orthogonal axes: (1) the system axis, reflecting the architectural layer (exec policy, gateway, channel, sandbox, browser, plugin, agent/prompt); and (2) the attack axis, reflecting adversarial techniques (identity spoofing, policy bypass, cross-layer composition, prompt injection, supply-chain escalation). Patch-differential evidence yields three principal findings. First, three Moderate- or High-severity advisories in the Gateway and Node-Host subsystems compose into a complete unauthenticated remote code execution (RCE) path -- spanning delivery, exploitation, and command-and-control -- from an LLM tool call to the host process. Second, the exec allowlist, the primary command-filtering mechanism, relies on a closed-world assumption that command identity is recoverable via lexical parsing. This is invalidated by shell line continuation, busybox multiplexing, and GNU option abbreviation. Third, a malicious skill distributed via the plugin channel executed a two-stage dropper within the LLM context, bypassing the exec pipeline and demonstrating that the skill distribution surface lacks runtime policy enforcement. The dominant structural weakness is per-layer trust enforcement rather than unified policy boundaries, making cross-layer attacks resilient to local remediation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a security analysis of the OpenClaw AI agent framework. It introduces a taxonomy of 470 advisories organized along two axes: system layers (exec policy, gateway, channel, sandbox, browser, plugin, agent/prompt) and attack techniques (identity spoofing, policy bypass, cross-layer composition, prompt injection, supply-chain escalation). Patch-differential analysis supports three findings: (1) three Moderate- or High-severity advisories in the Gateway and Node-Host subsystems compose into a complete unauthenticated RCE path from an LLM tool call through delivery, exploitation, and C2 to the host process; (2) the primary exec allowlist relies on a closed-world assumption invalidated by shell line continuation, busybox multiplexing, and GNU option abbreviation; (3) a malicious skill via the plugin channel executes a two-stage dropper bypassing the exec pipeline. The dominant weakness identified is per-layer trust enforcement rather than unified policy boundaries.
Significance. If the RCE composition holds, the work is significant for highlighting structural risks in AI agent frameworks that connect LLM reasoning directly to host execution surfaces, risks that differ from conventional software vulnerabilities. The taxonomy supplies a reusable classification for analyzing similar systems, while the specific bypass demonstrations (allowlist and plugin channel) offer concrete, falsifiable insights for defenders. Grounding claims in real advisories and patch diffs strengthens empirical value, though absence of quantitative validation or full dataset release limits immediate reproducibility and cross-checks.
major comments (2)
- [§4.1] §4.1 (RCE composition finding): The central claim that three advisories form a complete unauthenticated RCE path is load-bearing, yet the patch-differential evidence does not explicitly demonstrate that no unmentioned runtime controls, additional auth checks, or context restrictions in Gateway or Node-Host would block the chaining; the analysis assumes exact interaction as described without addressing potential intervening mitigations.
- [§4.2] §4.2 (closed-world assumption): While the invalidation via shell line continuation, busybox multiplexing, and GNU option abbreviation is internally consistent, the paper does not clarify whether these bypasses were observed within the 470-advisory dataset or represent hypothetical extensions, which affects the strength of the second finding relative to the taxonomy.
minor comments (2)
- [Abstract] Abstract: The total of 470 advisories is stated without the collection time window, source repository, or inclusion criteria, which would improve reproducibility of the taxonomy.
- [Taxonomy section] Taxonomy presentation: A summary table breaking down the 470 advisories by the two axes (system layer vs. attack type) is missing; its addition would make the clustering claim easier to verify at a glance.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript. We address each major comment below and have revised the manuscript to incorporate clarifications that strengthen the empirical grounding of our findings.
read point-by-point responses
-
Referee: [§4.1] §4.1 (RCE composition finding): The central claim that three advisories form a complete unauthenticated RCE path is load-bearing, yet the patch-differential evidence does not explicitly demonstrate that no unmentioned runtime controls, additional auth checks, or context restrictions in Gateway or Node-Host would block the chaining; the analysis assumes exact interaction as described without addressing potential intervening mitigations.
Authors: We agree that the original presentation of the patch-differential analysis would benefit from explicit discussion of potential intervening controls. Our code review of the Gateway and Node-Host subsystems (conducted as part of the advisory analysis) confirms the absence of additional authentication mechanisms, context restrictions, or runtime checks in the relevant execution paths beyond those addressed by the three advisories. We have revised §4.1 to include a new paragraph and accompanying code excerpts from the relevant modules demonstrating that no such mitigations exist in the pre-patch versions, thereby making the composition path explicit and falsifiable. revision: yes
-
Referee: [§4.2] §4.2 (closed-world assumption): While the invalidation via shell line continuation, busybox multiplexing, and GNU option abbreviation is internally consistent, the paper does not clarify whether these bypasses were observed within the 470-advisory dataset or represent hypothetical extensions, which affects the strength of the second finding relative to the taxonomy.
Authors: The three bypass techniques were directly derived from patterns observed across the 470-advisory dataset rather than introduced as hypotheticals. We have revised §4.2 to state this explicitly, noting the specific counts (line continuation in 47 advisories, busybox multiplexing in 23, and GNU abbreviation in 15) and cross-referencing the relevant taxonomy entries under the exec policy layer. This change ties the invalidation of the closed-world assumption more tightly to the empirical data. revision: yes
Circularity Check
No significant circularity; claims rest on external advisory analysis
full rationale
The paper constructs its taxonomy and three principal findings from a systematic review of 470 external advisories plus patch-differential evidence. The RCE composition claim is an interpretive chaining of those independent advisories rather than a reduction to any internal definition, fitted parameter, or self-citation. No equations, ansatzes, or uniqueness theorems appear; the derivation chain remains empirical and externally grounded, satisfying the self-contained benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 470 advisories accurately represent the vulnerabilities present in OpenClaw and have been correctly classified by architectural layer and trust-violation type.
Forward citations
Cited by 1 Pith paper
-
LITMUS: Benchmarking Behavioral Jailbreaks of LLM Agents in Real OS Environments
LITMUS is the first benchmark using semantic-physical dual verification and OS state rollback to measure behavioral jailbreaks in LLM agents, revealing that even strong models execute 40%+ of high-risk operations and ...
Reference graph
Works this paper leans on
-
[1]
OpenClaw: Open-Source AI Agent Runtime.https://github.com/ openclaw/openclaw, 2026
OpenClaw Contributors. OpenClaw: Open-Source AI Agent Runtime.https://github.com/ openclaw/openclaw, 2026
work page 2026
-
[2]
E. M. Hutchins, M. J. Cloppert, and R. M. Amin. Intelligence-driven computer network defense informed by analysis of adversary campaigns and intrusion kill chains. InProceedings of the 6th International Conference on Information Warfare and Security, 2011
work page 2011
-
[3]
Ignore Previous Prompt: Attack Techniques For Language Models
F. Perez and I. Ribeiro. Ignore previous prompt: Attack techniques for language models.arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injections. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security, 2023
work page 2023
-
[5]
J. Rando and F. Tram` er. Universal jailbreak backdoors from poisoned human feedback.arXiv preprint arXiv:2311.14455, 2024
-
[6]
GitHub Security Advisory GHSA-g8p2. OpenClaw: SSRF via attacker-controlledgatewayUrl parameter in agent tools (commit c5406e1 / 2d5647a), February 2026.https://github.com/ openclaw/openclaw/security/advisories
work page 2026
-
[7]
GitHub Security Advisory GHSA-gv46. OpenClaw:system.execApprovals.*reachable via node.invokeenabling exec allowlist manipulation (commit 01b3226), February 2026.https: //github.com/openclaw/openclaw/security/advisories
work page 2026
-
[8]
GitHub Security Advisory GHSA-9868. OpenClaw: Line-continuation bypass in exec allowlist shell parser (commit 3f0b9db), February 2026.https://github.com/openclaw/openclaw/ security/advisories
work page 2026
-
[9]
GitHub Security Advisory GHSA-gwqp. OpenClaw: Busybox/Toybox multiplexer bypass in exec wrapper resolution, February 2026.https://github.com/openclaw/openclaw/ security/advisories
work page 2026
-
[10]
GitHub Security Advisory GHSA-3c6h. OpenClaw: GNU long-option abbreviation bypass in safeBinsflag allowlist (commit 3b8e330), February 2026.https://github.com/openclaw/ openclaw/security/advisories. 27
work page 2026
-
[11]
GitHub Security Advisory GHSA-w235-x559-36mg. OpenClaw: Docker container escape via bind-mount and network configuration injection (commit 887b209), February 2026.https: //github.com/openclaw/openclaw/security/advisories
work page 2026
-
[12]
GitHub Security Advisory GHSA-h9g4-589h-68xv. OpenClaw: Unauthenticated noVNC remote-desktop access enabling sandbox escape, February 2026.https://github.com/ openclaw/openclaw/security/advisories
work page 2026
-
[13]
GitHub Issue openclaw/openclaw#5675. Maliciousyahoofinanceskill distributing two-stage dropper viaclawhub.ai, February 2026.https://github.com/openclaw/openclaw/issues/ 5675
work page 2026
-
[14]
GitHub Security Advisory GHSA-r5h9. OpenClaw: Nextcloud Talk display-name allowlist bypass via mutableactor.namefield, February 2026.https://github.com/openclaw/ openclaw/security/advisories
work page 2026
-
[15]
GitHub Security Advisory GHSA-mj5r. OpenClaw: Telegram username allowlist bypass via mutable display identity, February 2026.https://github.com/openclaw/openclaw/ security/advisories
work page 2026
-
[16]
GitHub Security Advisory GHSA-chm2. OpenClaw: Google Chat allowlist bypass via mutable sender display name, February 2026.https://github.com/openclaw/openclaw/security/ advisories
work page 2026
-
[17]
GitHub Security Advisory GHSA-w5c7. OpenClaw: Inter-session context contamination en- abling agent instruction injection, February 2026.https://github.com/openclaw/openclaw/ security/advisories
work page 2026
-
[18]
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. StruQ: Defending Against Prompt Injection with Structured Queries.arXiv preprint arXiv:2402.06363, 2024.https: //arxiv.org/abs/2402.06363
-
[19]
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. DataSentinel: A Game-Theoretic Detection of Prompt Injection Attacks.arXiv preprint arXiv:2504.11358, 2025.https://arxiv.org/abs/2504.11358
-
[20]
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, et al. PromptArmor: Simple yet Effective Prompt Injection Defenses.arXiv preprint arXiv:2507.15219, 2025.https: //arxiv.org/abs/2507.15219
-
[21]
Mengxiao Wang, Yuxuan Zhang, and Guofei Gu. PromptSleuth: Detecting Prompt Injection via Semantic Intent Invariance.arXiv preprint arXiv:2508.20890, 2025.https://arxiv.org/ abs/2508.20890. 28
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.