Recognition: no theorem link
Kwame 2.0: Human-in-the-Loop Generative AI Teaching Assistant for Large Scale Online Coding Education in Africa
Pith reviewed 2026-05-14 00:33 UTC · model grok-4.3
The pith
Human-in-the-loop generative AI combines scalability with human reliability for large-scale coding support across Africa.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
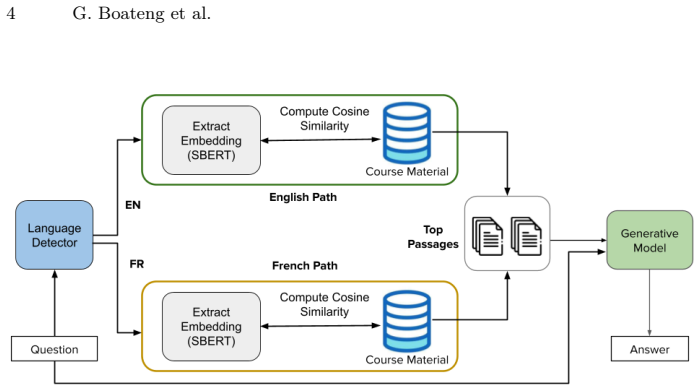
Kwame 2.0 retrieves relevant course materials and generates responses in English or French while running inside a forum that encourages human oversight and community participation. Evaluation via community feedback and expert ratings in the 15-month study found high accuracy on curriculum-related questions, with human intervention effectively mitigating errors on administrative queries and demonstrating that the combined system offers scalable learning assistance for underrepresented populations in constrained environments.
What carries the argument
Kwame 2.0, a retrieval-augmented generation system placed in a human-in-the-loop forum that incorporates oversight and community input to refine AI outputs.
If this is right
- Large numbers of learners can receive immediate course-specific help without a proportional increase in full-time human staff.
- Students in multiple countries and languages gain consistent access to accurate guidance on coding topics.
- AI generation errors are caught through human review, particularly for queries outside the core curriculum.
- The model supports education delivery in resource-constrained regions by leveraging both automated speed and targeted human correction.
Where Pith is reading between the lines
- The same human-in-the-loop structure could extend to other subjects such as mathematics or basic science in similar low-resource settings.
- Over repeated deployments the amount of required human review might decrease if the retrieval and generation components improve from accumulated corrections.
- Educational providers could test cost reductions by substituting some traditional tutoring hours with this AI-plus-oversight approach.
Load-bearing premise
Community feedback and expert ratings provide unbiased and comprehensive evidence of support quality, and human oversight remains scalable without becoming a bottleneck.
What would settle it
A larger deployment in which the volume of AI responses overwhelms human reviewers, resulting in a measurable rise in uncorrected errors and lower expert ratings on support quality.
Figures


read the original abstract
Providing timely and accurate learning support in large-scale online coding courses is challenging, particularly in resource-constrained contexts. We present Kwame 2.0, a bilingual (English-French) generative AI teaching assistant built using retrieval-augmented generation and deployed in a human-in-the-loop forum within SuaCode, an introductory mobile-based coding course for learners across Africa. Kwame 2.0 retrieves relevant course materials and generates context-aware responses while encouraging human oversight and community participation. We deployed the system in a 15-month longitudinal study spanning 15 cohorts with 3,717 enrollments across 35 African countries. Evaluation using community feedback and expert ratings shows that Kwame 2.0 provided high-quality and timely support, achieving high accuracy on curriculum-related questions, while human facilitators and peers effectively mitigated errors, particularly for administrative queries. Our findings demonstrate that human-in-the-loop generative AI systems can combine the scalability and speed of AI with the reliability of human support, offering an effective approach to learning assistance for underrepresented populations in resource-constrained settings at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Kwame 2.0, a bilingual (English-French) generative AI teaching assistant built with retrieval-augmented generation (RAG) and deployed in a human-in-the-loop forum for the SuaCode introductory mobile coding course. It describes a 15-month longitudinal deployment across 15 cohorts with 3,717 enrollments in 35 African countries. Evaluation relies on community feedback and expert ratings, with the central claim that the system achieves high accuracy on curriculum questions while human facilitators and peers effectively mitigate errors, particularly for administrative queries, thereby combining AI scalability with human reliability at scale for resource-constrained settings.
Significance. If the effectiveness claims are substantiated, the work could offer a practical template for hybrid AI-human support systems in large-scale online education targeting underrepresented learners in Africa and similar contexts. The deployment scale (3,717 enrollments) and bilingual focus are notable strengths. However, the absence of objective metrics, baseline comparisons, and quantified human intervention rates substantially weakens the ability to assess whether the approach genuinely scales without human bottlenecks or selection bias in feedback.
major comments (3)
- [Abstract] Abstract: The claim that Kwame 2.0 achieved 'high accuracy on curriculum-related questions' provides no supporting details on measurement (e.g., expert-written reference answers, multiple-choice probes, error rates, or inter-rater reliability for expert ratings), which is load-bearing for the central effectiveness assertion.
- [Evaluation] Evaluation/Deployment description: No counts or fractions are reported for queries handled fully automatically versus those requiring human intervention across the 3,717 enrollments, preventing assessment of whether human oversight remains scalable or introduces bottlenecks as claimed.
- [Longitudinal study] Longitudinal study section: The 15-cohort results lack baseline comparisons to non-AI support methods and details on how post-hoc adjustments or potential biases in community feedback were handled, undermining the cross-cohort reliability claims.
minor comments (2)
- [Abstract] Abstract: Consider specifying response latency metrics or exact accuracy percentages if quantified elsewhere in the manuscript to strengthen the timeliness claim.
- [Methods] Notation and terminology: The term 'human-in-the-loop' is used without a precise definition of the escalation protocol or decision criteria for when humans intervene, which could be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below, proposing revisions where feasible while noting limitations inherent to the study design.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that Kwame 2.0 achieved 'high accuracy on curriculum-related questions' provides no supporting details on measurement (e.g., expert-written reference answers, multiple-choice probes, error rates, or inter-rater reliability for expert ratings), which is load-bearing for the central effectiveness assertion.
Authors: We agree that the abstract would benefit from greater specificity on the accuracy measurement. In the revised manuscript, we will update the abstract to briefly describe the expert rating process (a sample of curriculum responses rated by domain experts against reference materials from the course, with details on the rating scale and agreement metrics provided in the Evaluation section). revision: yes
-
Referee: [Evaluation] Evaluation/Deployment description: No counts or fractions are reported for queries handled fully automatically versus those requiring human intervention across the 3,717 enrollments, preventing assessment of whether human oversight remains scalable or introduces bottlenecks as claimed.
Authors: We acknowledge this omission and will add the requested statistics to the Evaluation/Deployment section. Our system logs tracked intervention events, allowing us to report the fraction of queries resolved automatically by the RAG model versus those escalated to human facilitators or peers. revision: yes
-
Referee: [Longitudinal study] Longitudinal study section: The 15-cohort results lack baseline comparisons to non-AI support methods and details on how post-hoc adjustments or potential biases in community feedback were handled, undermining the cross-cohort reliability claims.
Authors: We will expand the Limitations section to discuss potential selection bias in voluntary community feedback and note that no post-hoc adjustments were applied to the data; instead, findings were triangulated with expert ratings for reliability. However, the observational deployment design precludes direct baseline comparisons. revision: partial
- Direct baseline comparisons to non-AI support methods, as the study was a single-arm longitudinal deployment without a control condition.
Circularity Check
Empirical deployment study with no derivation chain or self-referential claims
full rationale
The paper presents a system description and longitudinal deployment results evaluated via community feedback and expert ratings across 3,717 enrollments. No equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or ansatzes appear in the abstract or described structure. The central claim rests on observed outcomes from external user interactions rather than any reduction to self-defined quantities or self-citations. This is a standard non-circular empirical report.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption RAG retrieval produces relevant and accurate context for curriculum-related student questions.
- domain assumption Human facilitators and peers can reliably detect and correct AI errors without introducing new delays or biases.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: Proceedings of the 10th Computer Science Education Research Conference
Annor, P.S., Kayang, E., Boateng, S., Boateng, G.: Autograd: Automated grading software for mobile game assignments in suacode courses. In: Proceedings of the 10th Computer Science Education Research Conference. pp. 79–85 (2021)
work page 2021
-
[3]
In: International Conference on Artificial Intelligence in Education
Boateng, G.: Kwame: A bilingual ai teaching assistant for online suacode courses. In: International Conference on Artificial Intelligence in Education. pp. 93–97. Springer (2021) 8 G. Boateng et al
work page 2021
-
[4]
In: Proceedings of the 10th Computer Science Education Research Conference
Boateng, G., Annor, P.S., Kumbol, V.W.A.: Suacode africa: Teaching coding online to africans using smartphones. In: Proceedings of the 10th Computer Science Education Research Conference. pp. 14–20 (2021)
work page 2021
-
[5]
In: 2018 IEEE Integrated STEM Education Conference (ISEC)
Boateng, G., Kumbol, V.: Project iswest: Promoting a culture of innovation in africa through stem. In: 2018 IEEE Integrated STEM Education Conference (ISEC). pp. 104–111. IEEE (2018)
work page 2018
-
[6]
In: Proceedings of the 8th Computer Science Education Research Conference
Boateng, G., Kumbol, V.W.A., Annor, P.S.: Keep calm and code on your phone: A pilot of suacode, an online smartphone-based coding course. In: Proceedings of the 8th Computer Science Education Research Conference. pp. 9–14 (2019)
work page 2019
-
[7]
Why mobile internet is so expensive in africa (2020). https://www.dw.com/en/why- mobile-internet-is-so-expensive-in-some-african-nations/a-55483976 (Nov 2020)
work page 2020
-
[8]
In: Proceedings of the 2024 on ACM Virtual Global Computing Education Conference V
Feng, T., Liu, S., Ghosal, D.: Courseassist: Pedagogically appropriate ai tutor for computer science education. In: Proceedings of the 2024 on ACM Virtual Global Computing Education Conference V. 2. pp. 310–311 (2024)
work page 2024
-
[9]
Advances in Neural Information Processing Systems 33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33, 9459–9474 (2020)
work page 2020
-
[10]
In: Proceedings of the 23rd Koli Calling International Conference on Computing Education Research
Liffiton, M., Sheese, B.E., Savelka, J., Denny, P.: Codehelp: Using large language models with guardrails for scalable support in programming classes. In: Proceedings of the 23rd Koli Calling International Conference on Computing Education Research. pp. 1–11 (2023)
work page 2023
-
[11]
In: Proceedings of the 55th ACM technical symposium on computer science education V
Liu, R., Zenke, C., Liu, C., Holmes, A., Thornton, P., Malan, D.J.: Teaching cs50 with ai: leveraging generative artificial intelligence in computer science education. In: Proceedings of the 55th ACM technical symposium on computer science education V. 1. pp. 750–756 (2024)
work page 2024
-
[12]
In: Proceedings of the eleventh ACM conference on learning@ scale
Lyu, W., Wang, Y., Chung, T., Sun, Y., Zhang, Y.: Evaluating the effectiveness of llms in introductory computer science education: A semester-long field study. In: Proceedings of the eleventh ACM conference on learning@ scale. pp. 63–74 (2024)
work page 2024
-
[13]
In: Proceedings of the 56th ACM Technical Symposium on Computer Science Education V
Raihan, N., Siddiq, M.L., Santos, J.C., Zampieri, M.: Large language models in computer science education: A systematic literature review. In: Proceedings of the 56th ACM Technical Symposium on Computer Science Education V. 1. pp. 938–944 (2025)
work page 2025
-
[14]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[15]
https://www.c4dhi.org/news/lecture-by-boateng-suacode-africa- 20210122/
Suacode africa 2.0: Teaching coding online to africans using smartphones during covid-19. "https://www.c4dhi.org/news/lecture-by-boateng-suacode-africa- 20210122/" (Jan 2021)
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.