Recognition: 2 theorem links
· Lean TheoremHomophily-aware Supervised Contrastive Counterfactual Augmented Fair Graph Neural Network
Pith reviewed 2026-05-16 05:45 UTC · model grok-4.3
The pith
Editing graph homophily to boost class labels while cutting sensitive ones improves both accuracy and fairness in GNN training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
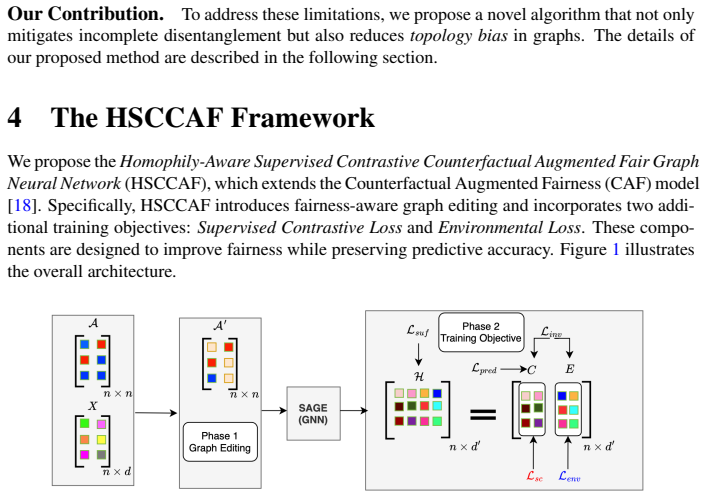
By first editing the graph to increase class-label homophily while reducing sensitive-attribute homophily and then training with a modified supervised contrastive loss plus environmental loss, the resulting model jointly raises node classification accuracy and fairness metrics beyond those achieved by CAF and prior state-of-the-art graph methods.
What carries the argument
The two-phase procedure that first rewrites graph edges to control separate homophily ratios for labels and sensitive attributes, then optimizes with supervised contrastive and environmental losses.
If this is right
- Fair GNN training can be strengthened by explicitly separating class and sensitive homophily through graph editing before contrastive optimization.
- Node classification on graphs with protected attributes can achieve tighter accuracy-fairness trade-offs than previous counterfactual methods.
- Supervised contrastive losses become more effective for fairness once the input graph has been adjusted for homophily ratios.
- The same editing-plus-contrastive pattern could be applied to other graph tasks that suffer from structural bias.
Where Pith is reading between the lines
- The homophily-editing step might transfer to bias reduction in link prediction or community detection on similar networks.
- Lowering sensitive homophily could reduce unwanted correlations even in settings where fairness definitions differ from those used here.
- Applying the edit step at multiple scales or with different edit budgets could test how much structural change is needed before performance plateaus.
- Similar two-phase editing-plus-loss designs may prove useful for fairness in non-graph contrastive learning.
Load-bearing premise
That deliberately increasing class-label homophily while decreasing sensitive-attribute homophily preserves enough structural signal for accurate node classification without creating new unintended biases.
What would settle it
Running the two-phase procedure on one of the five datasets and finding that accuracy or fairness drops below the CAF baseline would falsify the claim that the homophily edits reliably help.
Figures




read the original abstract
In recent years, Graph Neural Networks (GNNs) have achieved remarkable success in tasks such as node classification, link prediction, and graph representation learning. However, they remain susceptible to biases that can arise not only from node attributes but also from the graph structure itself. Addressing fairness in GNNs has therefore emerged as a critical research challenge. In this work, we propose a novel model for training fairness-aware GNNs by improving the counterfactual augmented fair graph neural network framework (CAF). Specifically, our approach introduces a two-phase training strategy: in the first phase, we edit the graph to increase homophily ratio with respect to class labels while reducing homophily ratio with respect to sensitive attribute labels; in the second phase, we integrate a modified supervised contrastive loss and environmental loss into the optimization process, enabling the model to jointly improve predictive performance and fairness. Experiments on five real-world datasets demonstrate that our model outperforms CAF and several state-of-the-art graph-based learning methods in both classification accuracy and fairness metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HSC-CAF, an extension of the CAF framework for fair GNN node classification. It introduces a two-phase procedure: (1) edit the input graph to increase the class-label homophily ratio while decreasing the sensitive-attribute homophily ratio, and (2) train with a modified supervised contrastive loss combined with an environmental loss. The central empirical claim is that this yields higher classification accuracy and better fairness metrics than CAF and several other graph-based methods on five real-world datasets.
Significance. If the reported gains are robust, the work would provide a practical, structure-aware route to mitigating both attribute and structural bias in GNNs by explicitly manipulating homophily ratios before contrastive training. The absence of any derivation or bound on how the edit operator affects diffusion or cut properties, however, limits the result to a dataset-specific heuristic whose generalizability remains unproven.
major comments (2)
- [§3.2] §3.2 (Graph Editing Phase): the manuscript supplies no analysis, bound, or ablation demonstrating that the homophily-adjustment operator preserves the minimum-cut or neighborhood diffusion properties required for accurate node classification. The edit could preferentially delete cross-class edges that carry label signal or add intra-class edges that amplify spurious correlations, rendering the subsequent supervised contrastive + environmental loss gains dataset-specific rather than general.
- [§4] §4 (Experiments): the abstract and experimental section report outperformance on five datasets but provide neither error bars across multiple runs, statistical significance tests, nor ablation studies isolating the contribution of the graph-edit step versus the modified contrastive loss. Without these, the central claim that the two-phase strategy jointly improves accuracy and fairness cannot be verified.
minor comments (2)
- [§3.1] Notation for the homophily ratios (class vs. sensitive) is introduced without a clear equation reference; add an explicit definition (e.g., Eq. (3)) before the editing algorithm.
- [§3.3] The environmental loss term is described only at a high level; include its precise formulation alongside the supervised contrastive loss for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the graph editing analysis and experimental validation. We will revise the manuscript to strengthen both aspects while preserving the core contributions of the two-phase HSC-CAF framework.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Graph Editing Phase): the manuscript supplies no analysis, bound, or ablation demonstrating that the homophily-adjustment operator preserves the minimum-cut or neighborhood diffusion properties required for accurate node classification. The edit could preferentially delete cross-class edges that carry label signal or add intra-class edges that amplify spurious correlations, rendering the subsequent supervised contrastive + environmental loss gains dataset-specific rather than general.
Authors: We agree that a theoretical bound on the edit operator would be desirable. Deriving general guarantees on min-cut preservation or diffusion is difficult without strong assumptions on the input graphs. In the revision we will add an empirical ablation that quantifies the change in random-walk diffusion distances and label-signal retention (measured by edge-label agreement) before and after editing. We will also report the fraction of cross-class edges removed versus added and discuss conditions under which spurious correlations could be amplified, thereby clarifying the scope of the heuristic. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract and experimental section report outperformance on five datasets but provide neither error bars across multiple runs, statistical significance tests, nor ablation studies isolating the contribution of the graph-edit step versus the modified contrastive loss. Without these, the central claim that the two-phase strategy jointly improves accuracy and fairness cannot be verified.
Authors: We accept that the current experimental section lacks sufficient statistical rigor. The revised manuscript will include (i) mean and standard deviation of accuracy and fairness metrics over 10 independent runs with error bars, (ii) paired t-tests against CAF and other baselines to establish significance, and (iii) component-wise ablations that separately disable the graph-editing phase and the modified supervised contrastive loss. These additions will isolate the contribution of each stage and substantiate the joint improvement claim. revision: yes
- Derivation of general bounds on how the edit operator affects diffusion or cut properties
Circularity Check
No significant circularity in the proposed empirical method
full rationale
The paper describes a two-phase procedure (graph editing to raise class-label homophily while lowering sensitive-attribute homophily, followed by training with a modified supervised contrastive loss plus environmental loss) and reports empirical gains on five datasets. No derivation chain, uniqueness theorem, fitted-parameter prediction, or self-citation load-bearing step is present; the central claims rest on experimental comparisons rather than any quantity that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we edit the graph to increase homophily ratio with respect to class labels while reducing homophily ratio with respect to sensitive attribute labels
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
modified supervised contrastive loss and environmental loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Beyond homophily in graph neural networks: Current limitations and effective designs
Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. Beyond homophily in graph neural networks: Current limitations and effective designs. Advances in neural information processing systems, 33:7793–7804, 2020
work page 2020
-
[2]
Survey on graph neural networks.IEEE Access, 12:128816–128832, 2024
Georgios Gkarmpounis, Christos Vranis, Nicholas Vretos, and Petros Daras. Survey on graph neural networks.IEEE Access, 12:128816–128832, 2024
work page 2024
-
[3]
Rossi, Namyong Park, Puja Trivedi, Yu Wang, Tong Yu, Sungchul Kim, Franck Dernoncourt, and Nesreen K
April Chen, Ryan A. Rossi, Namyong Park, Puja Trivedi, Yu Wang, Tong Yu, Sungchul Kim, Franck Dernoncourt, and Nesreen K. Ahmed. Fairness-aware graph neural networks: A survey.ACM Trans. Knowl. Discov. Data, 18(6), April 2024
work page 2024
-
[4]
Alexandra Chouldechova and Aaron Roth. A snapshot of the frontiers of fairness in ma- chine learning.Communications of the ACM, 63(5):82–89, 2020
work page 2020
-
[5]
Exploiting mmd and sinkhorn divergences for fair and transferable represen- tation learning
Luca Oneto, Michele Donini, Giulia Luise, Carlo Ciliberto, Andreas Maurer, and Massim- iliano Pontil. Exploiting mmd and sinkhorn divergences for fair and transferable represen- tation learning. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Red Hook, NY , USA, 2020. Curran Associates Inc
work page 2020
-
[6]
Fairness in machine learning.Nips tutorial, 1:2, 2017
Solon Barocas, Moritz Hardt, and Arvind Narayanan. Fairness in machine learning.Nips tutorial, 1:2, 2017
work page 2017
-
[7]
Philippe Besse, Céline Castets-Renard, Aurélien Garivier, and Jean-Michel Loubes. Can everyday ai be ethical? machine learning algorithm fairness.Machine Learning Algorithm Fairness (May 20, 2018). Statistiques et Société, 6(3), 2019
work page 2018
-
[8]
Philippe Besse, Eustasio del Barrio, Paula Gordaliza, Jean-Michel Loubes, and Laurent Risser. A survey of bias in machine learning through the prism of statistical parity.The American Statistician, pages 1–11, 2021
work page 2021
-
[9]
April Chen, Ryan A Rossi, Namyong Park, Puja Trivedi, Yu Wang, Tong Yu, Sungchul Kim, Franck Dernoncourt, and Nesreen K Ahmed. Fairness-aware graph neural networks: A survey.ACM Transactions on Knowledge Discovery from Data, 18(6):1–23, 2024
work page 2024
-
[10]
Indro Spinelli, Simone Scardapane, Amir Hussain, and Aurelio Uncini. Fairdrop: Biased edge dropout for enhancing fairness in graph representation learning.IEEE Transactions on Artificial Intelligence, 3(3):344–354, 2021
work page 2021
-
[11]
On generalized degree fairness in graph neural networks
Zemin Liu, Trung-Kien Nguyen, and Yuan Fang. On generalized degree fairness in graph neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 37, pages 4525–4533, 2023
work page 2023
-
[12]
Fairness-aware graph filter design
O Deniz Kose, Yanning Shen, and Gonzalo Mateos. Fairness-aware graph filter design. In2023 57th Asilomar Conference on Signals, Systems, and Computers, pages 330–334. IEEE, 2023
work page 2023
-
[13]
Matt J Kusner, Joshua Loftus, Chris Russell, and Ricardo Silva. Counterfactual fairness. In Advances in Neural Information Processing Systems, volume 30, pages 4066–4076. Curran Associates, Inc., 2017
work page 2017
-
[14]
Transport-based counterfactual models.arXiv preprint arXiv:2108.13025, 2021
Lucas De Lara, Alberto González-Sanz, Nicholas Asher, and Jean-Michel Loubes. Transport-based counterfactual models.arXiv preprint arXiv:2108.13025, 2021
-
[15]
Inform: Individual fairness on graph mining
Jian Kang, Jingrui He, Ross Maciejewski, and Hanghang Tong. Inform: Individual fairness on graph mining. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 379–389, 2020. 21
work page 2020
-
[16]
Towards a unified framework for fair and stable graph representation learning
Chirag Agarwal, Himabindu Lakkaraju, and Marinka Zitnik. Towards a unified framework for fair and stable graph representation learning. InUncertainty in Artificial Intelligence, pages 2114–2124. PMLR, 2021
work page 2021
-
[17]
Learning fair node representations with graph counterfactual fairness
Jing Ma, Ruocheng Guo, Mengting Wan, Longqi Yang, Aidong Zhang, and Jundong Li. Learning fair node representations with graph counterfactual fairness. InProceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, pages 695–703, 2022
work page 2022
-
[18]
Towards fair graph neural networks via graph counterfactual
Zhimeng Guo, Jialiang Li, Teng Xiao, Yao Ma, and Suhang Wang. Towards fair graph neural networks via graph counterfactual. InProceedings of the 32nd ACM international conference on information and knowledge management, pages 669–678, 2023
work page 2023
-
[19]
Rethinking fair graph neural networks from re-balancing
Zhixun Li, Yushun Dong, Qiang Liu, and Jeffrey Xu Yu. Rethinking fair graph neural networks from re-balancing. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pages 1736–1745, 2024
work page 2024
-
[20]
Topology matters in fair graph learning: a theoretical pilot study.(2022), 2022
Zhimeng Jiang, Xiaotian Han, Chao Fan, Zirui Liu, Xiao Huang, Na Zou, Ali Mostafavi, and Xia Hu. Topology matters in fair graph learning: a theoretical pilot study.(2022), 2022
work page 2022
-
[21]
Birds of a feather: Homophily in social networks.Annual review of sociology, 27(1):415–444, 2001
Miller McPherson, Lynn Smith-Lovin, and James M Cook. Birds of a feather: Homophily in social networks.Annual review of sociology, 27(1):415–444, 2001
work page 2001
-
[22]
Homophily and missing links in citation networks.EPJ Data Science, 5(1):7, 2016
Valerio Ciotti, Moreno Bonaventura, Vincenzo Nicosia, Pietro Panzarasa, and Vito Latora. Homophily and missing links in citation networks.EPJ Data Science, 5(1):7, 2016
work page 2016
-
[23]
Unveiling the impact of local homophily on gnn fairness: In-depth analysis and new benchmarks
Donald Loveland and Danai Koutra. Unveiling the impact of local homophily on gnn fairness: In-depth analysis and new benchmarks. InProceedings of the 2025 SIAM Inter- national Conference on Data Mining (SDM), pages 608–617. SIAM, 2025
work page 2025
-
[24]
A survey on fairness for machine learning on graphs.arXiv preprint arXiv:2205.05396, 2022
Charlotte Laclau, Christine Largeron, and Manvi Choudhary. A survey on fairness for machine learning on graphs.arXiv preprint arXiv:2205.05396, 2022
-
[25]
Enyan Dai and Suhang Wang. Say no to the discrimination: Learning fair graph neural networks with limited sensitive attribute information. InProceedings of the 14th ACM International Conference on Web Search and Data Mining, pages 680–688, 2021
work page 2021
-
[26]
Im- proving fairness in graph neural networks via mitigating sensitive attribute leakage
Yu Wang, Yuying Zhao, Yushun Dong, Huiyuan Chen, Jundong Li, and Tyler Derr. Im- proving fairness in graph neural networks via mitigating sensitive attribute leakage. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data min- ing, pages 1938–1948, 2022
work page 1938
-
[27]
Fairwalk: Towards fair graph embedding
Tahleen Rahman, Bartlomiej Surma, Michael Backes, and Yang Zhang. Fairwalk: Towards fair graph embedding. InProceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, pages 3289–3295. IJCAI, 2019
work page 2019
-
[28]
Edits: Modeling and mitigating data bias for graph neural networks
Yushun Dong, Ninghao Liu, Brian Jalaian, and Jundong Li. Edits: Modeling and mitigating data bias for graph neural networks. InProceedings of the ACM Web Conference 2022, pages 1259–1269, 2022
work page 2022
-
[29]
Ob- taining fairness using optimal transport theory
Paula Gordaliza, Eustasio Del Barrio, Gamboa Fabrice, and Jean-Michel Loubes. Ob- taining fairness using optimal transport theory. InInternational conference on machine learning, pages 2357–2365. PMLR, 2019
work page 2019
-
[30]
All of the fair- ness for edge prediction with optimal transport
Charlotte Laclau, Ievgen Redko, Manvi Choudhary, and Christine Largeron. All of the fair- ness for edge prediction with optimal transport. InInternational Conference on Artificial Intelligence and Statistics, pages 1774–1782. PMLR, 2021
work page 2021
-
[31]
Fair graph representation learning via sensitive attribute disentanglement
Yuchang Zhu, Jintang Li, Zibin Zheng, and Liang Chen. Fair graph representation learning via sensitive attribute disentanglement. InProceedings of the ACM Web Conference 2024, pages 1182–1192, 2024. 22
work page 2024
-
[32]
Chuxun Liu, Debo Cheng, Qingfeng Chen, Jiuyong Li, Lin Liu, and Rongyao Hu. Re- thinking fair graph representation learning via structural rebalancing.Available at SSRN 5320563, 2025
work page 2025
-
[33]
Springer Pub- lishing Company, Incorporated, 2008
John Adrian Bondy and Uppaluri Siva Ramachandra Murty.Graph theory. Springer Pub- lishing Company, Incorporated, 2008
work page 2008
-
[34]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
work page 2017
-
[36]
April Chen, Ryan A Rossi, Namyong Park, Puja Trivedi, Yu Wang, Tong Yu, Sungchul Kim, Franck Dernoncourt, and Nesreen K Ahmed. Fairness-aware graph neural networks: A survey.ACM Transactions on Knowledge Discovery from Data, 2023
work page 2023
-
[37]
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020
work page 2020
-
[38]
T-vmf similarity for regularizing intra-class feature distribution
Takumi Kobayashi. T-vmf similarity for regularizing intra-class feature distribution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6616–6625, 2021
work page 2021
-
[39]
Uci machine learning repository, 2007
Arthur Asuncion and David Newman. Uci machine learning repository, 2007
work page 2007
-
[40]
Kareem L Jordan and Tina L Freiburger. The effect of race/ethnicity on sentencing: Exam- ining sentence type, jail length, and prison length.Journal of Ethnicity in Criminal Justice, 13(3):179–196, 2015
work page 2015
-
[41]
I-Cheng Yeh and Che-hui Lien. The comparisons of data mining techniques for the predic- tive accuracy of probability of default of credit card clients.Expert systems with applica- tions, 36(2):2473–2480, 2009
work page 2009
-
[42]
Data analysis in public social networks
Lubos Takac and Michal Zabovsky. Data analysis in public social networks. InInterna- tional scientific conference and international workshop present day trends of innovations, volume 1, 2012
work page 2012
-
[43]
How powerful are graph neural networks?, 2019
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks?, 2019
work page 2019
-
[44]
Enyan Dai and Suhang Wang. Say no to the discrimination: Learning fair graph neural networks with limited sensitive attribute information. InProceedings of the 14th ACM International Conference on Web Search and Data Mining, WSDM ’21, page 680–688, New York, NY , USA, 2021. Association for Computing Machinery. A Proof of Properties of Fairness-Aware Graph...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.