Recognition: no theorem link
WSVD: Weighted Low-Rank Approximation for Fast and Efficient Execution of Low-Precision Vision-Language Models
Pith reviewed 2026-05-13 21:01 UTC · model grok-4.3
The pith
Weighted SVD at finer granularity with adaptive element weighting delivers over 1.8 times faster decoding in low-precision vision-language models while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that Weighted SVD (WSVD) outperforms prior SVD variants by applying singular value decomposition at finer granularity, adaptively allocating relative importance to weight elements to preserve accuracy, and combining the result with quantization of weights and activations, thereby achieving over 1.8 times decoding speedup in vision-language models while maintaining accuracy.
What carries the argument
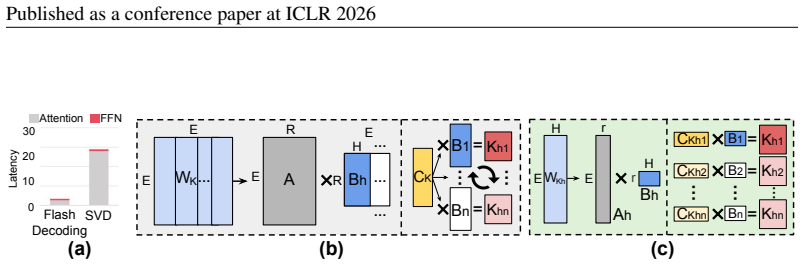
Weighted SVD, which performs low-rank approximation by applying singular value decomposition at finer granularity and adaptively weighting elements by importance before quantization.
If this is right
- Low-precision VLMs can run with substantially lower latency during decoding while retaining accuracy on image captioning and visual question answering.
- The combination of finer-grained decomposition and adaptive weighting outperforms standard low-rank methods in practical execution time.
- Quantization applied after the weighted approximation further improves efficiency without requiring post-hoc accuracy recovery steps.
- The resulting models become more suitable for deployment where computational resources are limited.
Where Pith is reading between the lines
- The same finer-granularity weighting pattern could be tested on other transformer-based architectures beyond vision-language models to check for similar speed gains.
- If the latency reductions hold across hardware platforms, this would lower energy use for mobile or embedded AI applications that rely on VLMs.
- Exploring whether the adaptive weighting can be learned jointly with the model rather than applied post-training might yield additional improvements.
Load-bearing premise
That applying SVD at finer granularity together with adaptive per-element weighting will produce measurable real-world latency reductions in VLM execution without causing accuracy degradation.
What would settle it
Measure decoding latency and task accuracy of a standard VLM before and after replacing its linear layers with WSVD plus quantization on a benchmark such as visual question answering; if latency does not drop by at least 1.5 times or accuracy falls noticeably, the central claim is false.
Figures




read the original abstract
Singular Value Decomposition (SVD) has become an important technique for reducing the computational burden of Vision Language Models (VLMs), which play a central role in tasks such as image captioning and visual question answering. Although multiple prior works have proposed efficient SVD variants to enable low-rank operations, we find that in practice it remains difficult to achieve substantial latency reduction during model execution. To address this limitation, we introduce a new computational pattern and apply SVD at a finer granularity, enabling real and measurable improvements in execution latency. Furthermore, recognizing that weight elements differ in their relative importance, we adaptively allocate relative importance to each element during SVD process to better preserve accuracy, then extend this framework with quantization applied to both weights and activations, resulting in a highly efficient VLM. Collectively, we introduce~\textit{Weighted SVD} (WSVD), which outperforms other approaches by achieving over $1.8\times$ decoding speedup while preserving accuracy. We open source our code at: \href{https://github.com/SAI-Lab-NYU/WSVD}{\texttt{https://github.com/SAI-Lab-NYU/WSVD}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Weighted SVD (WSVD) as a new computational pattern for low-rank approximation in Vision-Language Models. It applies SVD at finer granularity, adaptively weights elements according to their relative importance to preserve accuracy, and combines the approach with quantization of both weights and activations, claiming over 1.8× decoding speedup while maintaining accuracy.
Significance. If the speedup claim is substantiated with wall-clock measurements that survive kernel-launch and memory-access overheads, the result would be significant for practical low-precision VLM deployment. The open-sourcing of code supports reproducibility and is a positive contribution.
major comments (2)
- [Abstract] Abstract: the central claim of over 1.8× decoding speedup is stated without any experimental details, baselines, error bars, per-layer latency breakdowns, or comparison of actual versus theoretical FLOPs, preventing assessment of whether the speedup survives the overheads of finer-granularity decomposition.
- [Method] Method description (finer-granularity SVD): the paper asserts that applying SVD at finer granularity produces measurable real-world latency reductions, yet provides no analysis of the resulting increase in GEMM kernel launches and fragmented memory accesses on GPUs, which can dominate arithmetic savings once low-precision kernels are introduced.
minor comments (1)
- [Abstract] Abstract: the GitHub link is useful, but the abstract would be clearer if it briefly named the VLMs, datasets, and hardware used for the reported speedup.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the major comments point by point in the following responses. Revisions have been made to the manuscript to provide the requested details and analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of over 1.8× decoding speedup is stated without any experimental details, baselines, error bars, per-layer latency breakdowns, or comparison of actual versus theoretical FLOPs, preventing assessment of whether the speedup survives the overheads of finer-granularity decomposition.
Authors: We agree that the abstract lacks sufficient experimental context. In the revised manuscript, we have updated the abstract to include key experimental details such as the VLM models used, comparison baselines, and confirmation that the speedup is measured via wall-clock time with reported variability. Detailed per-layer latency breakdowns and actual versus theoretical FLOPs comparisons are already present in the experimental section and are now referenced in the abstract for better accessibility. revision: yes
-
Referee: [Method] Method description (finer-granularity SVD): the paper asserts that applying SVD at finer granularity produces measurable real-world latency reductions, yet provides no analysis of the resulting increase in GEMM kernel launches and fragmented memory accesses on GPUs, which can dominate arithmetic savings once low-precision kernels are introduced.
Authors: This is a valid point. The original manuscript emphasized empirical results but did not explicitly analyze the overheads from additional kernel launches and memory fragmentation. We have added a new analysis subsection to the Method section that quantifies these overheads using GPU profiling tools. The analysis shows that while there is an increase in launches, the finer granularity combined with our weighting scheme results in net latency reductions that survive these overheads, as validated by the wall-clock measurements. revision: yes
Circularity Check
No circularity: method introduced as empirical pattern without self-referential reduction
full rationale
The provided abstract and context describe WSVD as a new computational pattern: applying SVD at finer granularity, adaptively weighting elements by importance, and combining with quantization. No equations, derivations, or fitted parameters are shown that reduce the 1.8× speedup claim to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is presented. The central claim rests on experimental outcomes rather than tautological definitions or fitted-input predictions, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marco Ancona, Enea Ceolini, Cengiz ¨Oztireli, and Markus Gross. Towards better understanding of gradient-based attribution methods for deep neural networks.arXiv preprint arXiv:1711.06104,
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, local- ization, text reading, and beyond.arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu-Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Mohamed S Abdelfattah, and Kai-Chiang Wu. Palu: Compressing kv-cache with low-rank projection.arXiv preprint arXiv:2407.21118,
-
[4]
Accessed: 2025-09-22. Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Moham- madreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pp. 91–104,
work page 2025
-
[5]
Maksim Dzabraev, Alexander Kunitsyn, and Andrei Ivaniuta. Vlrm: Vision-language models act as reward models for image captioning.arXiv preprint arXiv:2404.01911,
-
[6]
12 Published as a conference paper at ICLR 2026 Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Language model compression with weighted low-rank factorization.arXiv preprint arXiv:2207.00112,
Yen-Chang Hsu, Ting Hua, Sungen Chang, Qian Lou, Yilin Shen, and Hongxia Jin. Language model compression with weighted low-rank factorization.arXiv preprint arXiv:2207.00112,
-
[8]
Principal component analysis: a review and recent developments
Ian T Jolliffe and Jorge Cadima. Principal component analysis: a review and recent developments. Philosophical transactions of the royal society A: Mathematical, Physical and Engineering Sci- ences, 374(2065):20150202,
work page 2065
-
[9]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Seed-bench: Benchmarking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Benchmarking multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13299–13308, 2024a. Chuanhao Li, Zhen Li, Chenchen Jing, Shuo Liu, Wenqi Shao, Yuwei Wu, Ping Luo, Yu Qiao, and Kaipeng Zha...
-
[11]
Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Xiuyu Li, Junxian Guo, Enze Xie, Chenlin Meng, Jun-Yan Zhu, and Song Han. Svdqunat: Absorbing outliers by low-rank components for 4-bit diffusion models.arXiv preprint arXiv:2411.05007, 2024c. Zhiteng Li, Mingyuan Xia, Jingyuan Zhang, Zheng Hui, Linghe Kong, Yulun Zhang, and Xiaokang Yang. Adasvd: Adaptive s...
-
[12]
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucination in large vision-language models.arXiv preprint arXiv:2402.00253, 2024a. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916,
work page internal anchor Pith review arXiv
-
[13]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 26296–26306, 2024b. 13 Published as a conference paper at ICLR 2026 Liyang Liu, Shilong Zhang, Zhanghui Kuang, Aojun Zhou, Jing-Hao Xue, Xinjiang Wang, Yimin Chen...
work page 2026
-
[14]
SmolVLM: Redefining small and efficient multimodal models
Andr´es Marafioti, Orr Zohar, Miquel Farr ´e, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Za- kka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, et al. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Changyuan Wang, Ziwei Wang, Xiuwei Xu, Yansong Tang, Jie Zhou, and Jiwen Lu. Q-vlm: Post- training quantization for large vision-language models.arXiv preprint arXiv:2410.08119, 2024a. Guankun Wang, Long Bai, Wan Jun Nah, Jie Wang, Zhaoxi Zhang, Zhen Chen, Jinlin Wu, Mo- barakol Islam, Hongbin Liu, and Hongliang Ren. Surgical-lvlm: Learning to adapt large...
-
[16]
Jingyang Xiang and Sai Qian Zhang. Dfrot: Achieving outlier-free and massive activation-free for rotated llms with refined rotation.arXiv preprint arXiv:2412.00648,
-
[17]
Effectively compress kv heads for llm
Hao Yu, Zelan Yang, Shen Li, Yong Li, and Jianxin Wu. Effectively compress kv heads for llm. arXiv preprint arXiv:2406.07056, 2024a. Mengxia Yu, De Wang, Qi Shan, Colorado J Reed, and Alvin Wan. The super weight in large language models.arXiv preprint arXiv:2411.07191, 2024b. Zhengqing Yuan, Zhaoxu Li, Weiran Huang, Yanfang Ye, and Lichao Sun. Tinygpt-v: ...
-
[18]
15 Published as a conference paper at ICLR 2026 A APPENDIX A.1 THEUSE OFLLMS Large language models (LLMs), such as ChatGPT, were used exclusively for language polishing and minor stylistic editing of the manuscript. All technical ideas, analyses, and experimental results were conceived, implemented, and verified by the authors. The authors carefully revie...
work page 2026
-
[19]
Table 9: Accuracy evaluation of different methods under FP16. Acc. Method ScienceQA-IMG↑ SEED-Bench↑ Avg.↑ρ1: 90%ρ1: 80%ρ1: 70%ρ1: 60% ρ1: 50% ρ1: 90%ρ1: 80%ρ1: 70%ρ1: 60% ρ1: 50% LLaV A-v1.57B ASVD 49.93%50.12%47.10%36.69% 19.19% 54.27%53.53%48.35%37.17% 24.17% 42.05%SVD-LLM65.44%63.71%61.92%57.41% 55.53% 57.89%57.50%55.33%54.64% 55.31% 58.47%QSVD-noQ67....
work page 2026
-
[20]
As summarized in Table 12, WSVD-noQ consistently matches or outperforms all baselines across nearly all ratios on these datasets, despite being cali- brated only once on the ScienceQA training set. These results indicate that WSVD generalizes well across tasks and datasets. Moreover, WSVD’s decoding speedup is independent of the evaluation dataset: once t...
work page 2026
-
[21]
On RTX 4090, the speedup ranges from14.9×to18.1×, while on RTX 5090 it further increases to 17.2×–21.6×. These results confirm that per-head SVD substantially reduces reconstruction over- head and I/O traffic, enabling efficient decoding. A.8 TRAININGCOST OFWSVD WSVD first applies SVDLLM’s whitening method (Wang et al., 2024d) to per-head weight matri- ce...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.