Recognition: 2 theorem links
· Lean TheoremESL-Bench: An Event-Driven Synthetic Longitudinal Benchmark for Health Agents
Pith reviewed 2026-05-13 19:57 UTC · model grok-4.3
The pith
Database-native agents achieve 48-58% accuracy on longitudinal health queries, outperforming memory RAG baselines at 30-38%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
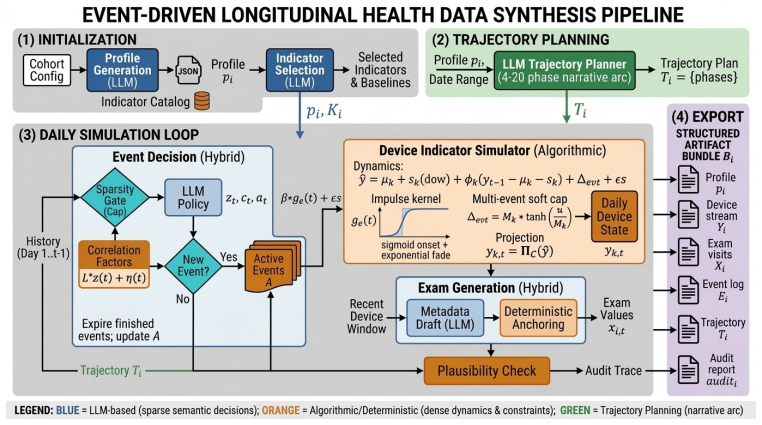
ESL-Bench creates synthetic longitudinal trajectories via an event-driven framework where each indicator follows a baseline stochastic process modified by discrete events through sigmoid-onset exponential-decay kernels under saturation constraints. The hybrid pipeline assigns sparse semantic elements to LLM planning and dense dynamics to algorithmic simulation with physiological bounds, producing 100 users paired with 100 queries across Lookup, Trend, Comparison, Anomaly, and Explanation categories. Evaluation shows database-native agents reach 48-58% accuracy while memory RAG baselines reach 30-38%, with the gap widest on queries needing evidence chaining and causal attribution.
What carries the argument
The event-driven synthesis pipeline that links discrete events to continuous indicator changes through explicit per-indicator impact parameters and kernel-based response functions, enabling programmatic ground-truth answers for all queries.
If this is right
- Database access provides a clear advantage for multi-hop reasoning and attribution in health trajectory tasks.
- The performance difference concentrates in Comparison and Explanation query types.
- Programmatic ground truth in synthetic data enables reproducible evaluation at scale where real data cannot be released.
- Hybrid tool-using agents that incorporate structured storage outperform pure retrieval-augmented generation for longitudinal domains.
Where Pith is reading between the lines
- If transfer to real data holds, development priorities should shift toward database integration rather than expanding memory buffers alone.
- The same synthesis approach could generate benchmarks for other sequential domains such as financial transaction histories or environmental sensor streams.
- Hybrid systems that route simple lookups to retrieval and complex reasoning to database queries might close the remaining accuracy gap without full architectural replacement.
Load-bearing premise
The synthetic trajectories accurately reproduce the statistical distributions and causal event-indicator relationships present in real longitudinal health records.
What would settle it
Re-running the 13 methods on a small collection of real de-identified patient trajectories and verifying whether the accuracy ordering and size of the gap between database agents and memory RAG stay consistent.
Figures



read the original abstract
Longitudinal health agents must reason across multi-source trajectories that combine continuous device streams, sparse clinical exams, and episodic life events - yet evaluating them is hard: real-world data cannot be released at scale, and temporally grounded attribution questions seldom admit definitive answers without structured ground truth. We present ESL-Bench, an event-driven synthesis framework and benchmark providing 100 synthetic users, each with a 1-5 year trajectory comprising a health profile, a multi-phase narrative plan, daily device measurements, periodic exam records, and an event log with explicit per-indicator impact parameters. Each indicator follows a baseline stochastic process driven by discrete events with sigmoid-onset, exponential-decay kernels under saturation and projection constraints; a hybrid pipeline delegates sparse semantic artifacts to LLM-based planning and dense indicator dynamics to algorithmic simulation with hard physiological bounds. Users are each paired with 100 evaluation queries across five dimensions - Lookup, Trend, Comparison, Anomaly, Explanation - stratified into Easy, Medium, and Hard tiers, with all ground-truth answers programmatically computable from the recorded event-indicator relationships. Evaluating 13 methods spanning LLMs with tools, DB-native agents, and memory-augmented RAG, we find that DB agents (48-58%) substantially outperform memory RAG baselines (30-38%), with the gap concentrated on Comparison and Explanation queries where multi-hop reasoning and evidence attribution are required.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ESL-Bench, an event-driven synthetic longitudinal benchmark for health agents. It generates 100 synthetic user trajectories (1-5 years each) via a hybrid LLM-planning plus algorithmic simulation pipeline that produces multi-source data (device streams, exams, event logs) with explicit per-indicator impact parameters and programmatically computable ground truth. The benchmark includes 100 queries per user across Lookup, Trend, Comparison, Anomaly, and Explanation dimensions (stratified Easy/Medium/Hard). Evaluation of 13 methods (LLMs with tools, DB-native agents, memory-augmented RAG) reports DB agents achieving 48-58% accuracy versus 30-38% for RAG baselines, with the largest gaps on Comparison and Explanation queries requiring multi-hop reasoning.
Significance. If the synthetic trajectories are shown to reproduce key statistical and causal properties of real longitudinal health data, ESL-Bench would supply a much-needed controlled testbed with verifiable attribution for multi-source reasoning tasks that are otherwise intractable due to privacy constraints and lack of ground truth. The reported performance gap favoring structured DB access over retrieval-based methods on complex queries would then offer actionable guidance for health-agent design.
major comments (3)
- [Data Generation] Data Generation section: The hybrid pipeline (LLM narratives + algorithmic simulation with sigmoid-onset, exponential-decay kernels, saturation, and physiological bounds) is presented as capturing real causal event-indicator relationships, yet no quantitative validation (Kolmogorov-Smirnov tests on indicator variances, event frequencies, autocorrelation, or multi-hop chain statistics) against any real de-identified cohort is reported. This directly undermines transferability of the central claim that DB agents (48-58%) substantially outperform memory RAG (30-38%).
- [Experimental Results] Experimental Results section: Accuracy figures are given only as ranges (48-58%, 30-38%) with no error bars, per-user or per-tier standard deviations, or statistical significance tests (e.g., Wilcoxon or paired t-tests) across the 100 users and 100 queries each. This leaves the reported gap on Comparison and Explanation queries without a clear measure of robustness.
- [Methods] Methods section: No implementation details, hyperparameters, or pseudocode are supplied for the 13 evaluated systems (LLM-tool agents, DB-native agents, memory RAG variants). Reproducibility of the benchmark results therefore cannot be assessed from the manuscript alone.
minor comments (2)
- [Benchmark Construction] The query-generation procedure for the five dimensions and three difficulty tiers is described at a high level; explicit decision rules or examples for assigning a query to Easy/Medium/Hard would improve clarity.
- [Results] Table or figure captions for the accuracy results should explicitly state the number of runs or seeds used to produce the reported ranges.
Simulated Author's Rebuttal
Thank you for the thorough review and valuable suggestions. We appreciate the opportunity to clarify and strengthen our work on ESL-Bench. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Data Generation] Data Generation section: The hybrid pipeline (LLM narratives + algorithmic simulation with sigmoid-onset, exponential-decay kernels, saturation, and physiological bounds) is presented as capturing real causal event-indicator relationships, yet no quantitative validation (Kolmogorov-Smirnov tests on indicator variances, event frequencies, autocorrelation, or multi-hop chain statistics) against any real de-identified cohort is reported. This directly undermines transferability of the central claim that DB agents (48-58%) substantially outperform memory RAG (30-38%).
Authors: We agree that quantitative validation against real data would enhance the credibility of the synthetic trajectories. Although the pipeline is designed with explicit physiological constraints and event-impact parameters based on medical literature, we did not include direct statistical comparisons in the original submission. In the revised manuscript, we will incorporate Kolmogorov-Smirnov tests and autocorrelation analyses comparing synthetic indicator distributions to those from publicly available de-identified datasets such as MIMIC-III summaries and NHANES. This will support the transferability of the benchmark results. revision: yes
-
Referee: [Experimental Results] Experimental Results section: Accuracy figures are given only as ranges (48-58%, 30-38%) with no error bars, per-user or per-tier standard deviations, or statistical significance tests (e.g., Wilcoxon or paired t-tests) across the 100 users and 100 queries each. This leaves the reported gap on Comparison and Explanation queries without a clear measure of robustness.
Authors: We acknowledge the need for more rigorous statistical reporting. The original manuscript presented aggregated ranges to highlight the overall trends. In the revision, we will provide mean accuracy scores with standard deviations across users and query tiers, along with statistical significance tests such as paired t-tests or Wilcoxon signed-rank tests to quantify the robustness of the performance gaps, especially for multi-hop queries. revision: yes
-
Referee: [Methods] Methods section: No implementation details, hyperparameters, or pseudocode are supplied for the 13 evaluated systems (LLM-tool agents, DB-native agents, memory RAG variants). Reproducibility of the benchmark results therefore cannot be assessed from the manuscript alone.
Authors: We regret the lack of reproducibility details in the initial version. The revised manuscript will include comprehensive implementation specifics for all 13 methods, including the LLMs used (e.g., model versions and temperatures), tool configurations, database schemas, RAG hyperparameters (chunk size, embedding models, retrieval k), and pseudocode for the agent workflows. Additionally, we will provide a link to an open-source repository containing the evaluation code. revision: yes
Circularity Check
No circularity: benchmark results are empirical measurements on independent synthetic ground truth
full rationale
The paper generates synthetic trajectories via a hybrid LLM-planning plus algorithmic simulation pipeline that explicitly records event-indicator impact parameters. Ground-truth answers for all 100 queries per user are then computed directly from those recorded relationships, independent of any agent performance. The reported accuracies (DB agents 48-58% vs. memory RAG 30-38%) are obtained by running the 13 methods on this fixed benchmark; no parameter is fitted to the evaluation outcomes, no prediction is renamed from a fit, and no self-citation chain supplies the central result. The assumption that the synthetic data matches real longitudinal distributions is a separate validity question, not a reduction of the derivation to its inputs by construction. No self-definitional, fitted-input, or ansatz-smuggling patterns appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-indicator impact parameters
axioms (1)
- domain assumption Health indicators follow baseline stochastic processes driven by discrete events with sigmoid-onset, exponential-decay kernels under saturation and projection constraints
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each indicator follows a baseline stochastic process driven by discrete events with sigmoid-onset, exponential-decay kernels under saturation and projection constraints
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DB agents (48-58%) substantially outperform memory RAG baselines (30-38%)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Charlotte Köhler, Alexander Bartschke, Daniel Fürstenau, Thorsten Schaaf, and Eduardo Salgado-Baez. The value of smartwatches in the health care sector for monitoring, nudging, and predicting: Viewpoint on 25 years of research.Journal of Medical Internet Research, 26(1):e58936, 2024. 25
work page 2024
-
[2]
Ellis, Sally Andrews, and Adam Joinson
Lukasz Piwek, David A. Ellis, Sally Andrews, and Adam Joinson. The rise of consumer health wearables: Promises and barriers.PLOS Medicine, 13(2):e1001953, 2016
work page 2016
-
[3]
Steven R. Steinhubl, Evan D. Muse, and Eric J. Topol. The emerging field of mobile health. Science Translational Medicine, 7(283):283rv3, 2015
work page 2015
-
[4]
Michael Wornow, Rahul Thapa, Ethan Steinberg, Jason A. Fries, and Nigam H. Shah. Ehrshot: An ehr benchmark for few-shot evaluation of foundation models, 2023
work page 2023
-
[5]
emrqa: A large corpus for question answering on electronic medical records, 2018
Anusri Pampari, Preethi Raghavan, Jennifer Liang, and Jian Peng. emrqa: A large corpus for question answering on electronic medical records, 2018
work page 2018
-
[6]
Ehrsql: A practical text-to-sql benchmark for electronic health records
Gyubok Lee, Hyeonji Hwang, Seongsu Bae, Yeonsu Kwon, Woncheol Shin, Seongjun Yang, Minjoon Seo, Jong-Yeup Kim, and Edward Choi. Ehrsql: A practical text-to-sql benchmark for electronic health records. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 15589–1560...
work page 2022
-
[7]
Black, Gloria Geng, Danny Park, James Zou, Andrew Y
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y. Ng, and Jonathan H. Chen. Medagentbench: A realistic virtual ehr environment to benchmark medical llm agents, 2025
work page 2025
-
[8]
Alistair E. W. Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J. Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, Li-wei H. Lehman, Leo A. Celi, and Roger G. Mark. Mimic-iv, a freely accessible electronic health record dataset.Scientific Data, 10(1):1, 2023
work page 2023
-
[9]
Hejie Cui, Alyssa Unell, Bowen Chen, Jason Alan Fries, Emily Alsentzer, Sanmi Koyejo, and Nigam H. Shah. Timer: temporal instruction modeling and evaluation for longitudinal clinical records.npj Digital Medicine, 8(1):577, 2025
work page 2025
-
[10]
Med- journey: Benchmark and evaluation of large language models over patient clinical journey
Xian Wu, Yutian Zhao, Yunyan Zhang, Jiageng Wu, Zhihong Zhu, Yingying Zhang, Yi Ouyang, Ziheng Zhang, Huimin Wang, Zhenxi Lin, Jie Yang, Shuang Zhao, and Yefeng Zheng. Med- journey: Benchmark and evaluation of large language models over patient clinical journey. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,...
work page 2024
-
[11]
Agentehr: Advancing autonomous clinical decision-making via retrospective summarization, 2026
Yusheng Liao, Chuan Xuan, Yutong Cai, Lina Yang, Zhe Chen, Yanfeng Wang, and Yu Wang. Agentehr: Advancing autonomous clinical decision-making via retrospective summarization, 2026
work page 2026
-
[12]
Jonas Van Der Donckt, Nicolas Vandenbussche, Jeroen Van Der Donckt, Stephanie Chen, Marija Stojchevska, Mathias De Brouwer, Bram Steenwinckel, Koen Paemeleire, Femke Ongenae, and Sofie Van Hoecke. Mitigating data quality challenges in ambulatory wrist-worn wearable monitoring through analytical and practical approaches.Scientific Reports, 14:17545, 2024
work page 2024
-
[13]
Sylvia Cho, Ipek Ensari, Chunhua Weng, Michael G. Kahn, and Karthik Natarajan. Factors affecting the quality of person-generated wearable device data and associated challenges: Rapid systematic review.JMIR mHealth and uHealth, 9(3):e20738, 2021. 26
work page 2021
-
[14]
Jason Walonoski, Mark Kramer, Joseph Nichols, Andre Quina, Chris Moesel, Dylan Hall, Carlton Duffett, Kudakwashe Dube, Thomas Gallagher, and Scott McLachlan. Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record.Journal of the American Medical Informatics Association, 25(3):2...
work page 2018
-
[15]
Time-series generative adversarial networks
Jinsung Yoon, Daniel Jarrett, and Mihaela van der Schaar. Time-series generative adversarial networks. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[16]
Ziqi Zhang, Chao Yan, Youngjun Park, Stephen Nyemba, and Bradley A. Malin. Synteg: a framework for temporal structured electronic health data simulation.Journal of the American Medical Informatics Association, 28(3):596–604, 2021
work page 2021
-
[17]
Chao Yan, Yao Yan, Zhiyu Wan, Ziqi Zhang, Larsson Omberg, Justin Guinney, Sean D. Mooney, and Bradley A. Malin. A multifaceted benchmarking of synthetic electronic health record generation models.Nature Communications, 13(1):7609, 2022
work page 2022
-
[18]
Daniel Smolyak, Margrét V Bjarnadóttir, Kenyon Crowley, and Ritu Agarwal. Large language models and synthetic health data: progress and prospects.JAMIA Open, 7(4):ooae114, 2024
work page 2024
-
[19]
Mohammad Loni, Fatemeh Poursalim, Mehdi Asadi, and Arash Gharehbaghi. A review on generative ai models for synthetic medical text, time series, and longitudinal data.npj Digital Medicine, 8:281, 2025
work page 2025
-
[20]
Miguel A. Hernán and James M. Robins.Causal Inference: What If. Chapman & Hall/CRC, Boca Raton, 2020
work page 2020
-
[21]
Edward Choi, Siddharth Biswal, Bradley Malin, Jon Duke, Walter F. Stewart, and Jimeng Sun. Generating multi-label discrete patient records using generative adversarial networks. In Proceedings of the 2nd Machine Learning for Healthcare Conference, volume 68 ofProceedings of Machine Learning Research, pages 286–305. PMLR, 2017
work page 2017
-
[22]
Chang Li, Jessica Cairns, Jing Li, and Tingting Zhu. Generating synthetic mixed-type longitudinal electronic health records for artificial intelligent applications.npj Digital Medicine, 6:98, 2023
work page 2023
-
[23]
Yijie Hao, Huan He, and Joyce C. Ho. LLMSYN: Generating synthetic electronic health records without patient-level data. InProceedings of the 9th Machine Learning for Healthcare Conference, volume 252 ofProceedings of Machine Learning Research. PMLR, 2024
work page 2024
-
[24]
Ziqi Zhang, Chao Yan, David Mesa, Jimeng Sun, and Bradley A. Malin. Membership inference attacks against synthetic health data.Journal of Biomedical Informatics, 125:103956, 2022
work page 2022
-
[25]
SemEval-2016 task 12: Clinical TempEval
Steven Bethard, Guergana Savova, Wei-Te Chen, Leon Derczynski, James Pustejovsky, and Marc Verhagen. SemEval-2016 task 12: Clinical TempEval. InProceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), pages 1052–1062, San Diego, California, June 2016. Association for Computational Linguistics
work page 2016
-
[26]
Yinghao Zhu, Ziyi He, Haoran Hu, Xiaochen Zheng, Xichen Zhang, Zixiang Wang, Junyi Gao, Liantao Ma, and Lequan Yu. Medagentboard: Benchmarking multi-agent collaboration with conventional methods for diverse medical tasks, 2025. 27
work page 2025
-
[27]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, 2020
work page 2020
-
[28]
From local to global: A graph RAG approach to query-focused summarization, 2024
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph RAG approach to query-focused summarization, 2024
work page 2024
-
[29]
Hipporag: Neurobiologically inspired long-term memory for large language models, 2024
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobiologically inspired long-term memory for large language models, 2024
work page 2024
-
[30]
Lightrag: Simple and fast retrieval-augmented generation, 2024
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented generation, 2024
work page 2024
-
[31]
Qingyun Sun, Jiaqi Yuan, Shan He, Xiao Guan, Haonan Yuan, Xingcheng Fu, Jianxin Li, and Philip S. Yu. Dyg-rag: Dynamic graph retrieval-augmented generation with event-centric reasoning, 2025
work page 2025
-
[32]
A survey of graph retrieval-augmented generation for customized large language models, 2025
Qinggang Zhang, Shengyuan Chen, Yuanchen Bei, Zheng Yuan, Huachi Zhou, Zijin Hong, Hao Chen, Yilin Xiao, Chuang Zhou, Junnan Dong, Yi Chang, and Xiao Huang. A survey of graph retrieval-augmented generation for customized large language models, 2025
work page 2025
-
[33]
Michael G. Kahn, Tiffany J. Callahan, Juliana Barnard, Alan E. Bauck, Jeff Brown, Bruce N. Davidson, Hossein Estiri, Carl Goerg, Erin Holve, Steven G. Johnson, et al. A harmonized data quality assessment terminology and framework for the secondary use of electronic health record data.eGEMs, 4(1), 2016
work page 2016
-
[34]
Codesystem: Unified code for units of measure (ucum)
HL7 International. Codesystem: Unified code for units of measure (ucum). HL7 Terminology (THO), 2025. Accessed 2026-02-04
work page 2025
-
[35]
HL7 International. Codesystem: Dataabsentreason. HL7 Terminology (THO), 2025. Accessed 2026-02-04
work page 2025
-
[36]
Anne Kerstin Reimers, Guido Knapp, and Carl-Detlev Reimers. Effects of exercise on the resting heart rate: A systematic review and meta-analysis of interventional studies.Journal of Clinical Medicine, 7(12):503, 2018
work page 2018
-
[37]
Jiong Soon Lai, Yin Nwe Aung, Yusoff Khalid, and Shiau-Chuen Cheah. Impact of different dietary sodium reduction strategies on blood pressure: a systematic review.Hypertension Research, 45(11):1701–1712, 2022
work page 2022
-
[38]
Suling Zhang, Xiaodan Niu, Jinke Ma, Xin Wei, Jun Zhang, and Weiping Du. Effects of sleep deprivation on heart rate variability: a systematic review and meta-analysis.Frontiers in Neurology, 16:1556784, 2025
work page 2025
-
[39]
C. G. Fraser and E. K. Harris. Generation and application of data on biological variation in clinical chemistry.Critical Reviews in Clinical Laboratory Sciences, 27(5):409–437, 1989
work page 1989
-
[40]
Sverre Sandberg, Abdurrahman Coskun, Anna Carobene, Pilar Fernandez-Calle, Jorge Diaz- Garzon, William A. Bartlett, Niels Jonker, Kornelia Galior, Elisabet Gonzales-Lao, Isabel Moreno-Parro, Berta Sufrate-Vergara, Craig Webster, and Aasne K. Aarsand. Analytical 28 performance specifications based on biological variation data – considerations, strengths an...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.