Recognition: 2 theorem links
· Lean TheoremEvaNet: Towards More Efficient and Consistent Infrared and Visible Image Fusion Assessment
Pith reviewed 2026-05-13 20:26 UTC · model grok-4.3
The pith
A lightweight network evaluates infrared-visible image fusion up to 1000 times faster while aligning better with human perception.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
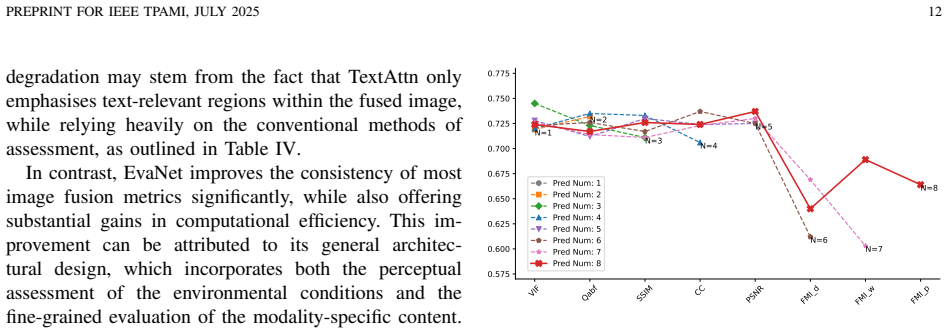
Core claim
EvaNet approximates widely used fusion metrics by decomposing the fused result into infrared and visible components, then using a lightweight network to measure information preservation in each component separately; the network is trained via contrastive learning informed by LLM-provided perceptual assessments, and the method includes a new consistency evaluation framework that references no-reference scores and task performance.
What carries the argument
Lightweight evaluation network that decomposes fused images into infrared and visible components before assessing modality-specific information preservation, trained with contrastive learning and LLM perceptual input.
If this is right
- Evaluation becomes fast enough to apply to large-scale fusion datasets and repeated experiments.
- The consistency framework supplies objective references for checking how any metric aligns with perception and tasks.
- Separate scoring of infrared and visible preservation allows targeted diagnosis of modality-specific weaknesses in a fusion method.
- Overall iteration cycles in fusion research shorten because reliable quality checks no longer require heavy computation.
Where Pith is reading between the lines
- The decomposition-plus-lightweight-model pattern could transfer to quality assessment in other multi-modal fusion settings such as medical or remote-sensing images.
- Real-time fusion pipelines in surveillance or autonomous systems could incorporate instant EvaNet-style checks for ongoing quality monitoring.
- Replacing complex image transformations with learned approximations opens a route to parameter-free or low-cost evaluation pipelines in related vision tasks.
Load-bearing premise
The decomposition step separates information without introducing new biases and the trained lightweight network can faithfully approximate complex traditional metrics.
What would settle it
On a new set of fused images, compute both EvaNet scores and traditional metric scores; if the two sets of scores systematically disagree on images where human observers clearly prefer one result over another, the approximation claim fails.
Figures
















read the original abstract
Evaluation is essential in image fusion research, yet most existing metrics are directly borrowed from other vision tasks without proper adaptation. These traditional metrics, often based on complex image transformations, not only fail to capture the true quality of the fusion results but also are computationally demanding. To address these issues, we propose a unified evaluation framework specifically tailored for image fusion. At its core is a lightweight network designed efficiently to approximate widely used metrics, following a divide-and-conquer strategy. Unlike conventional approaches that directly assess similarity between fused and source images, we first decompose the fusion result into infrared and visible components. The evaluation model is then used to measure the degree of information preservation in these separated components, effectively disentangling the fusion evaluation process. During training, we incorporate a contrastive learning strategy and inform our evaluation model by perceptual scene assessment provided by a large language model. Last, we propose the first consistency evaluation framework, which measures the alignment between image fusion metrics and human visual perception, using both independent no-reference scores and downstream tasks performance as objective references. Extensive experiments show that our learning-based evaluation paradigm delivers both superior efficiency (up to 1,000 times faster) and greater consistency across a range of standard image fusion benchmarks. Our code will be publicly available at https://github.com/AWCXV/EvaNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EvaNet, a lightweight network for efficient evaluation of infrared-visible image fusion. It uses a divide-and-conquer pipeline that first decomposes the fused image into separate infrared and visible components, then applies the network (trained via contrastive learning and LLM-provided perceptual assessments) to measure information preservation in each. The work also introduces a consistency evaluation framework that aligns metrics with human perception using independent no-reference scores and downstream task performance. The central claims are up to 1000x speedup over traditional metrics and improved consistency on standard fusion benchmarks, with code to be released publicly.
Significance. If the decomposition fidelity and approximation accuracy hold, the framework could substantially accelerate iteration in image fusion research by replacing slow, unadapted traditional metrics with a fast, tailored alternative. The consistency framework addresses a recognized gap by grounding evaluation in human-aligned and task-based references, potentially improving reliability of fusion algorithm comparisons. Public code availability supports reproducibility.
major comments (3)
- [Decomposition approach] Decomposition module: The divide-and-conquer claim that decomposition 'disentangles' evaluation without new biases is load-bearing for both the approximation fidelity and the 1000x efficiency assertion. The manuscript provides no quantitative validation of decomposition fidelity (e.g., cross-modal leakage metrics, statistical preservation tests, or ablation on separation artifacts), leaving open the possibility that reported gains reflect decomposition artifacts rather than true metric approximation.
- [Experiments] Experimental results: The abstract states that 'extensive experiments' demonstrate superior efficiency and consistency, yet the provided text supplies no specific numbers, baselines, error analysis, or ablation tables for the contrastive+LLM training components. This absence makes it impossible to assess whether the lightweight network faithfully approximates complex traditional metrics or whether consistency improvements are statistically significant.
- [Consistency evaluation framework] Consistency framework: The new framework relies on independent no-reference scores and downstream tasks as objective references. The manuscript should explicitly demonstrate (via correlation analysis or controlled tests) that these references remain independent of the approximated metrics; otherwise the consistency claim risks moderate circularity.
minor comments (3)
- [Abstract] Abstract: The 'up to 1,000 times faster' claim should specify the exact traditional metrics used as baseline, the hardware platform, and whether the speedup includes decomposition overhead.
- [Methods] Notation and terminology: Ensure consistent definition of 'information preservation' when applied to the decomposed components versus the original fused image; minor inconsistencies appear in the high-level description.
- [Related work] References: Add citations to recent LLM-based perceptual evaluation works in vision to better situate the training strategy.
Simulated Author's Rebuttal
Thank you for the referee's thorough review and valuable suggestions. We address each major comment below and plan to incorporate revisions to improve the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: Decomposition module: The divide-and-conquer claim that decomposition 'disentangles' evaluation without new biases is load-bearing for both the approximation fidelity and the 1000x efficiency assertion. The manuscript provides no quantitative validation of decomposition fidelity (e.g., cross-modal leakage metrics, statistical preservation tests, or ablation on separation artifacts), leaving open the possibility that reported gains reflect decomposition artifacts rather than true metric approximation.
Authors: We agree that quantitative validation of the decomposition fidelity is crucial to substantiate our claims. The current manuscript includes some qualitative examples of decomposition, but lacks the specific metrics suggested. In the revised manuscript, we will add quantitative evaluations such as cross-modal leakage using metrics like mutual information between components, statistical preservation tests, and ablations on separation artifacts. This will confirm that the decomposition does not introduce biases and that the efficiency gains are genuine. revision: yes
-
Referee: Experimental results: The abstract states that 'extensive experiments' demonstrate superior efficiency and consistency, yet the provided text supplies no specific numbers, baselines, error analysis, or ablation tables for the contrastive+LLM training components. This absence makes it impossible to assess whether the lightweight network faithfully approximates complex traditional metrics or whether consistency improvements are statistically significant.
Authors: We acknowledge that the abstract and initial presentation could benefit from more concrete details. The full paper contains tables and figures with specific results, including speedup comparisons and consistency scores. To address this, we will revise the manuscript to include explicit numerical values, baseline comparisons, error bars, and ablation studies for the training components in the main text and abstract. We will also add statistical analysis to demonstrate significance. revision: yes
-
Referee: Consistency framework: The new framework relies on independent no-reference scores and downstream tasks as objective references. The manuscript should explicitly demonstrate (via correlation analysis or controlled tests) that these references remain independent of the approximated metrics; otherwise the consistency claim risks moderate circularity.
Authors: This is a valid concern. The references were selected to be independent, as no-reference scores (e.g., BRISQUE, NIQE) and task performances (e.g., detection accuracy) do not directly depend on the fusion metrics being approximated. However, to strengthen this, we will include in the revision correlation analyses and controlled experiments showing low correlation between the references and EvaNet predictions, thereby mitigating any risk of circularity. revision: yes
Circularity Check
Network trained to approximate traditional metrics creates moderate fitted-input circularity in consistency claims
specific steps
-
fitted input called prediction
[Abstract]
"At its core is a lightweight network designed efficiently to approximate widely used metrics, following a divide-and-conquer strategy. ... During training, we incorporate a contrastive learning strategy and inform our evaluation model by perceptual scene assessment provided by a large language model."
The network is trained to reproduce the very traditional metrics it is later used to replace. Consequently, any measured consistency or efficiency gain that flows through the network's outputs is statistically constrained by the supervised approximation objective rather than constituting an independent first-principles result.
full rationale
The paper's core claim is that a lightweight network, trained via contrastive learning plus LLM perceptual labels, approximates complex traditional metrics under a decomposition strategy and thereby delivers superior efficiency and consistency. This approximation is explicitly supervised on the target metrics, so downstream consistency scores that rely on the network's outputs inherit dependence on the fitted quantities. The added consistency framework references independent no-reference scores and downstream task performance, which supplies some external anchoring and prevents full circularity. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the provided text; the decomposition step is presented as a design choice rather than a derived result. Overall score reflects partial reduction of the evaluation outputs to the training targets without the entire derivation collapsing.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we first decompose the fusion result into infrared and visible components... contrastive learning strategy and inform our evaluation model by perceptual scene assessment provided by a large language model
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
lightweight multi-head architecture... 1000× acceleration
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Visible and infrared image fusion using deep learning,
X. Zhang and Y . Demiris, “Visible and infrared image fusion using deep learning,”IEEE TPAMI, 2023
work page 2023
-
[2]
Current advances and future perspectives of image fusion: A comprehensive review,
S. Karim, G. Tong, J. Li, A. Qadir, U. Farooq, and Y . Yu, “Current advances and future perspectives of image fusion: A comprehensive review,”Information Fusion, vol. 90, pp. 185– 217, 2023
work page 2023
-
[3]
H. Li, Z. Yang, Y . Zhang, W. Jia, Z. Yu, and Y . Liu, “Mulfs-cap: Multimodal fusion-supervised cross-modality alignment percep- tion for unregistered infrared-visible image fusion,”IEEE TPAMI, 2025
work page 2025
-
[4]
Mmdrfuse: Distilled mini-model with dynamic refresh for multi-modality image fusion,
Y . Deng, T. Xu, C. Cheng, X.-J. Wu, and J. Kittler, “Mmdrfuse: Distilled mini-model with dynamic refresh for multi-modality image fusion,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 7326–7335
work page 2024
-
[5]
S4fusion: Saliency-aware selective state space model for in- frared and visible image fusion,
H. Ma, H. Li, C. Cheng, G. Wang, X. Song, and X.-J. Wu, “S4fusion: Saliency-aware selective state space model for in- frared and visible image fusion,”IEEE Transactions on Image Processing, 2025
work page 2025
-
[6]
Learning a graph neural network with cross modality interaction for image fusion,
J. Li, J. Chen, J. Liu, and H. Ma, “Learning a graph neural network with cross modality interaction for image fusion,” in ACM MM, 2023, pp. 4471–4479
work page 2023
-
[7]
J. Liu, X. Fan, Z. Huang, G. Wu, R. Liu, W. Zhong, and Z. Luo, “Target-aware dual adversarial learning and a multi- scenario multi-modality benchmark to fuse infrared and visible for object detection,” inCVPR, 2022, pp. 5802–5811
work page 2022
-
[8]
One model for all: Low-level task interaction is a key to task-agnostic image fusion,
C. Cheng, T. Xu, Z. Feng, X. Wu, Z. Tang, H. Li, Z. Zhang, S. Atito, M. Awais, and J. Kittler, “One model for all: Low-level task interaction is a key to task-agnostic image fusion,” inCVPR, 2025, pp. 28 102–28 112
work page 2025
-
[9]
Fusionmamba: Dynamic feature enhancement for multimodal image fusion with mamba,
X. Xie, Y . Cui, T. Tan, X. Zheng, and Z. Yu, “Fusionmamba: Dynamic feature enhancement for multimodal image fusion with mamba,”Visual Intelligence, vol. 2, no. 1, p. 37, 2024
work page 2024
-
[10]
J. Zhu, H. Wang, Y . Xu, Z. Wu, and Z. Wei, “Self-learning hyperspectral and multispectral image fusion via adaptive resid- ual guided subspace diffusion model,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 862–17 871
work page 2025
-
[11]
Fu- sionbooster: A unified image fusion boosting paradigm,
C. Cheng, T. Xu, X.-J. Wu, H. Li, X. Li, and J. Kittler, “Fu- sionbooster: A unified image fusion boosting paradigm,”IJCV, 2025
work page 2025
-
[12]
Omnifuse: Composite degradation-robust image fusion with language-driven semantics,
H. Zhang, L. Cao, X. Zuo, Z. Shao, and J. Ma, “Omnifuse: Composite degradation-robust image fusion with language-driven semantics,”IEEE TPAMI, 2025
work page 2025
-
[13]
Freefusion: In- frared and visible image fusion via cross reconstruction learning,
W. Zhao, H. Cui, H. Wang, Y . He, and H. Lu, “Freefusion: In- frared and visible image fusion via cross reconstruction learning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 9, pp. 8040–8056, 2025
work page 2025
-
[14]
Generative- based fusion mechanism for multi-modal tracking,
Z. Tang, T. Xu, X. Wu, X.-F. Zhu, and J. Kittler, “Generative- based fusion mechanism for multi-modal tracking,” inAAAI, vol. 38, no. 6, 2024, pp. 5189–5197
work page 2024
-
[15]
Coconut: Modernizing coco segmentation,
X. Deng, Q. Yu, P. Wang, X. Shen, and L.-C. Chen, “Coconut: Modernizing coco segmentation,” inCVPR, 2024, pp. 21 863– 21 873
work page 2024
-
[16]
Learning feature restoration transformer for robust dehazing visual object tracking,
T. Xu, Y . Pan, Z. Feng, X. Zhu, C. Cheng, X.-J. Wu, and J. Kittler, “Learning feature restoration transformer for robust dehazing visual object tracking,”IJCV, vol. 132, no. 12, pp. 6021–6038, 2024
work page 2024
-
[17]
Llvip: A visible- infrared paired dataset for low-light vision,
X. Jia, C. Zhu, M. Li, W. Tang, and W. Zhou, “Llvip: A visible- infrared paired dataset for low-light vision,” inICCV, 2021, pp. 3496–3504. PREPRINT FOR IEEE TPAMI, JULY 2025 17
work page 2021
-
[18]
Y . Liu, Z. Qi, J. Cheng, and X. Chen, “Rethinking the effective- ness of objective evaluation metrics in multi-focus image fusion: A statistic-based approach,”IEEE TPAMI, 2024
work page 2024
-
[19]
Lrrnet: A novel representation learning guided fusion network for infrared and visible images,
H. Li, T. Xu, X.-J. Wu, J. Lu, and J. Kittler, “Lrrnet: A novel representation learning guided fusion network for infrared and visible images,”IEEE TPAMI, 2023
work page 2023
-
[20]
Mdlatlrr: A novel decomposition method for infrared and visible image fusion,
H. Li, X.-J. Wu, and J. Kittler, “Mdlatlrr: A novel decomposition method for infrared and visible image fusion,”IEEE TIP, vol. 29, pp. 4733–4746, 2020
work page 2020
-
[21]
L. Wang, B. Li, and L.-f. Tian, “Eggdd: An explicit dependency model for multi-modal medical image fusion in shift-invariant shearlet transform domain,”Information fusion, vol. 19, pp. 29– 37, 2014
work page 2014
-
[22]
Textfusion: Unveiling the power of textual semantics for con- trollable image fusion,
C. Cheng, T. Xu, X.-J. Wu, H. Li, X. Li, Z. Tang, and J. Kittler, “Textfusion: Unveiling the power of textual semantics for con- trollable image fusion,”arXiv preprint arXiv:2312.14209, 2023
-
[23]
Mrfs: Mutually reinforcing image fusion and segmentation,
H. Zhang, X. Zuo, J. Jiang, C. Guo, and J. Ma, “Mrfs: Mutually reinforcing image fusion and segmentation,” inCVPR, 2024, pp. 26 974–26 983
work page 2024
-
[24]
Densefuse: A fusion approach to infrared and visible images,
H. Li and X.-J. Wu, “Densefuse: A fusion approach to infrared and visible images,”IEEE TIP, vol. 28, no. 5, pp. 2614–2623, 2018
work page 2018
-
[25]
Task-driven image fusion with learnable fusion loss,
H. Bai, J. Zhang, Z. Zhao, Y . Wu, L. Deng, Y . Cui, T. Feng, and S. Xu, “Task-driven image fusion with learnable fusion loss,” in CVPR, June 2025, pp. 7457–7468
work page 2025
-
[26]
Every sam drop counts: Embracing semantic priors for multi- modality image fusion and beyond,
G. Wu, H. Liu, H. Fu, Y . Peng, J. Liu, X. Fan, and R. Liu, “Every sam drop counts: Embracing semantic priors for multi- modality image fusion and beyond,” inCVPR, June 2025, pp. 17 882–17 891
work page 2025
-
[27]
Dcevo: Discriminative cross-dimensional evolutionary learning for infrared and visible image fusion,
J. Liu, B. Zhang, Q. Mei, X. Li, Y . Zou, Z. Jiang, L. Ma, R. Liu, and X. Fan, “Dcevo: Discriminative cross-dimensional evolutionary learning for infrared and visible image fusion,” in CVPR, 2025, pp. 2226–2235
work page 2025
-
[28]
Mambadfuse: A mamba-based dual-phase model for multi-modality image fusion,
Z. Li, H. Pan, K. Zhang, Y . Wang, and F. Yu, “Mambadfuse: A mamba-based dual-phase model for multi-modality image fusion,”arXiv preprint arXiv:2404.08406, 2024
-
[29]
Ddfm: Denoising diffusion model for multi-modality image fusion,
Z. Zhao, H. Bai, Y . Zhu, J. Zhang, S. Xu, Y . Zhang, K. Zhang, D. Meng, R. Timofte, and L. Van Gool, “Ddfm: Denoising diffusion model for multi-modality image fusion,” inICCV, October 2023, pp. 8082–8093
work page 2023
-
[30]
Diff-if: Multi- modality image fusion via diffusion model with fusion knowledge prior,
X. Yi, L. Tang, H. Zhang, H. Xu, and J. Ma, “Diff-if: Multi- modality image fusion via diffusion model with fusion knowledge prior,”Information Fusion, vol. 110, p. 102450, 2024
work page 2024
-
[31]
U2fusion: A unified unsupervised image fusion network,
H. Xu, J. Ma, J. Jiang, X. Guo, and H. Ling, “U2fusion: A unified unsupervised image fusion network,”IEEE TPAMI, 2020
work page 2020
-
[32]
Mufusion: A general unsuper- vised image fusion network based on memory unit,
C. Cheng, T. Xu, and X.-J. Wu, “Mufusion: A general unsuper- vised image fusion network based on memory unit,”Information Fusion, vol. 92, pp. 80–92, 2023
work page 2023
-
[33]
Metafusion: Infrared and visible image fusion via meta-feature embedding from object detection,
W. Zhao, S. Xie, F. Zhao, Y . He, and H. Lu, “Metafusion: Infrared and visible image fusion via meta-feature embedding from object detection,” inCVPR, June 2023, pp. 13 955–13 965
work page 2023
-
[34]
D. Rao, T. Xu, and X.-J. Wu, “Tgfuse: An infrared and visible image fusion approach based on transformer and generative adversarial network,”IEEE TIP, 2023
work page 2023
-
[35]
Swinfusion: Cross-domain long-range learning for general image fusion via swin transformer,
J. Ma, L. Tang, F. Fan, J. Huang, X. Mei, and Y . Ma, “Swinfusion: Cross-domain long-range learning for general image fusion via swin transformer,”IEEE/CAA Journal of Automatica Sinica, vol. 9, no. 7, pp. 1200–1217, 2022
work page 2022
-
[36]
Cddfuse: Correlation-driven dual-branch fea- ture decomposition for multi-modality image fusion,
Z. Zhao, H. Bai, J. Zhang, Y . Zhang, S. Xu, Z. Lin, R. Timofte, and L. Van Gool, “Cddfuse: Correlation-driven dual-branch fea- ture decomposition for multi-modality image fusion,” inCVPR, 2023, pp. 5906–5916
work page 2023
-
[37]
Restormer: Efficient transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.- H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” inCVPR, 2022, pp. 5728–5739
work page 2022
-
[38]
J. Liu, Z. Liu, G. Wu, L. Ma, R. Liu, W. Zhong, Z. Luo, and X. Fan, “Multi-interactive feature learning and a full-time multi-modality benchmark for image fusion and segmentation,” inICCV, 2023, pp. 8115–8124
work page 2023
-
[39]
A novel state space model with local enhancement and state sharing for image fusion,
Z. Cao, X. Wu, L.-J. Deng, and Y . Zhong, “A novel state space model with local enhancement and state sharing for image fusion,” inACM MM, 2024, pp. 1235–1244
work page 2024
-
[40]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
work page 2020
-
[41]
Perceptual quality assessment for multi-exposure image fusion,
K. Ma, K. Zeng, and Z. Wang, “Perceptual quality assessment for multi-exposure image fusion,”IEEE TIP, vol. 24, no. 11, pp. 3345–3356, 2015
work page 2015
-
[42]
A non-reference image fusion metric based on mutual information of image features,
M. B. A. Haghighat, A. Aghagolzadeh, and H. Seyedarabi, “A non-reference image fusion metric based on mutual information of image features,”Computers & Electrical Engineering, vol. 37, no. 5, pp. 744–756, 2011
work page 2011
-
[43]
Image information and visual quality,
H. R. Sheikh and A. C. Bovik, “Image information and visual quality,”IEEE TIP, vol. 15, no. 2, pp. 430–444, 2006
work page 2006
-
[44]
Very deep convolutional net- works for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional net- works for large-scale image recognition,” inInternational Con- ference on Learning Representations, May 2015
work page 2015
-
[45]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Ifcnn: A general image fusion framework based on convolutional neural network,
Y . Zhang, Y . Liu, P. Sun, H. Yan, X. Zhao, and L. Zhang, “Ifcnn: A general image fusion framework based on convolutional neural network,”Information Fusion, vol. 54, pp. 99–118, 2020
work page 2020
-
[47]
Sdnet: A versatile squeeze-and- decomposition network for real-time image fusion,
H. Zhang and J. Ma, “Sdnet: A versatile squeeze-and- decomposition network for real-time image fusion,”IJCV, pp. 1–25, 2021
work page 2021
-
[48]
Rfn-nest: An end-to-end residual fusion network for infrared and visible images,
H. Li, X.-J. Wu, and J. Kittler, “Rfn-nest: An end-to-end residual fusion network for infrared and visible images,”Information Fusion, vol. 73, pp. 72–86, 2021
work page 2021
-
[49]
Ydtr: infrared and visible image fusion via y-shape dynamic transformer,
W. Tang, F. He, and Y . Liu, “Ydtr: infrared and visible image fusion via y-shape dynamic transformer,”IEEE Transactions on Multimedia, 2022
work page 2022
-
[50]
Reconet: Recurrent correction network for fast and efficient multi-modality image fusion,
Z. Huang, J. Liu, X. Fan, R. Liu, W. Zhong, and Z. Luo, “Reconet: Recurrent correction network for fast and efficient multi-modality image fusion,” inECCV. Springer, 2022, pp. 539–555
work page 2022
-
[51]
Text-if: Leveraging semantic text guidance for degradation-aware and interactive image fusion,
X. Yi, H. Xu, H. Zhang, L. Tang, and J. Ma, “Text-if: Leveraging semantic text guidance for degradation-aware and interactive image fusion,” inCVPR, 2024, pp. 27 026–27 035
work page 2024
-
[52]
Equivariant multi-modality image fusion,
Z. Zhao, H. Bai, J. Zhang, Y . Zhang, K. Zhang, S. Xu, D. Chen, R. Timofte, and L. Van Gool, “Equivariant multi-modality image fusion,” inCVPR, 2024, pp. 25 912–25 921
work page 2024
-
[53]
J. Liu, R. Lin, G. Wu, R. Liu, Z. Luo, and X. Fan, “Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion,”IJCV, vol. 132, no. 5, pp. 1748–1775, 2024
work page 2024
-
[54]
Deep neural networks for no-reference and full-reference image quality assessment,
S. Bosse, D. Maniry, K.-R. M ¨uller, T. Wiegand, and W. Samek, “Deep neural networks for no-reference and full-reference image quality assessment,”IEEE TIP, vol. 27, no. 1, pp. 206–219, 2017
work page 2017
-
[55]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huanget al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inCVPR, 2016, pp. 779–788
work page 2016
-
[58]
Pidnet: A real-time semantic segmentation network inspired by pid controllers,
J. Xu, Z. Xiong, and S. P. Bhattacharyya, “Pidnet: A real-time semantic segmentation network inspired by pid controllers,” in CVPR, 2023, pp. 19 529–19 539
work page 2023
-
[59]
Exploring clip for assessing the look and feel of images,
J. Wang, K. C. Chan, and C. C. Loy, “Exploring clip for assessing the look and feel of images,” inAAAI, vol. 37, no. 2, 2023, pp. 2555–2563
work page 2023
-
[60]
U2fusion: A unified unsupervised image fusion network,
H. Xu, J. Ma, J. Jiang, X. Guo, and H. Ling, “U2fusion: A unified unsupervised image fusion network,”IEEE TPAMI, vol. 44, no. 1, pp. 502–518, 2022. PREPRINT FOR IEEE TPAMI, JULY 2025 18 Chunyang Chengreceived the Ph.D. degree in Artificial Intelligence and Computer Sci- ence from Jiangnan University, Wuxi, China, in 2025. He is currently a Postdoctoral Re...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.