How Annotation Trains Annotators: Competence Development in Social Influence Recognition
Pith reviewed 2026-05-13 19:45 UTC · model grok-4.3
The pith
Annotating dialogues for social influence techniques improves annotators' own competence and label quality over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Engaging in the annotation of 1,021 dialogues with 20 social influence techniques produces measurable competence gains: annotators return to the same 150-text comparison set with higher self-reported confidence, produce higher-quality labels, and generate data that trains LLMs to higher performance, with the competence lift more pronounced in expert groups than in non-experts.
What carries the argument
The before-and-after comparison on a fixed 150-text subset, paired with self-assessment surveys, semi-structured interviews, and LLM training/evaluation on the resulting labels.
If this is right
- Annotation functions as an active competence-building activity rather than passive data collection.
- Expert annotators exhibit larger competence gains than non-experts from the same process.
- LLM performance on social-influence tasks depends on the annotators' competence level at the time of labeling.
- Shifts in annotator judgments during a project visibly affect the quality of models trained on the collected data.
- Repeated annotation passes on the same material can capture and exploit this training effect.
Where Pith is reading between the lines
- Dataset pipelines could deliberately insert repeated annotation rounds on held-out subsets to harvest the competence gains.
- One-shot annotation may systematically underestimate the final competence level that annotators would reach after full exposure.
- The same training-through-annotation dynamic is likely to appear in other subjective labeling domains such as emotion or persuasion detection.
Load-bearing premise
Changes in label quality, self-reports, and LLM performance reflect genuine competence growth rather than task familiarity, fatigue, or other confounds in the before-after design.
What would settle it
A control group that annotates the 150-text comparison subset twice with no intervening main annotation task shows no significant rise in label quality or self-reported competence.
Figures
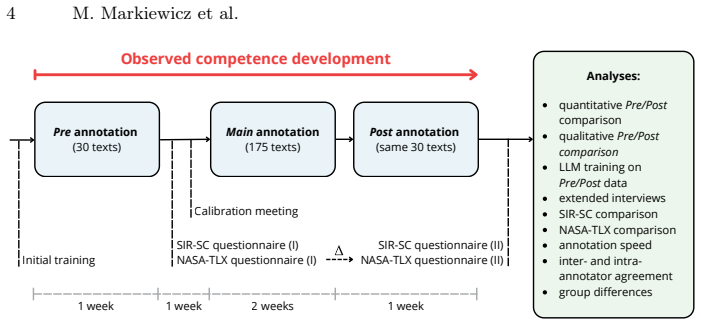
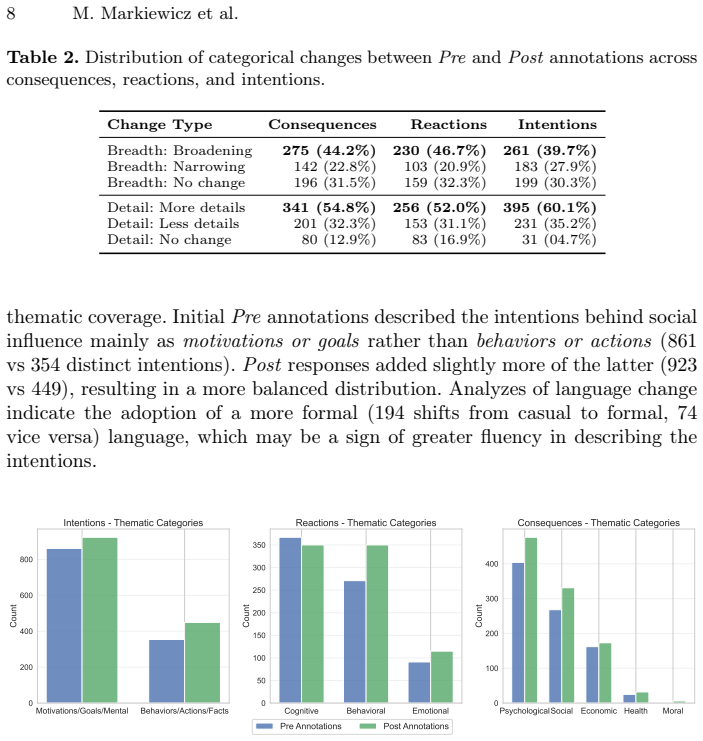

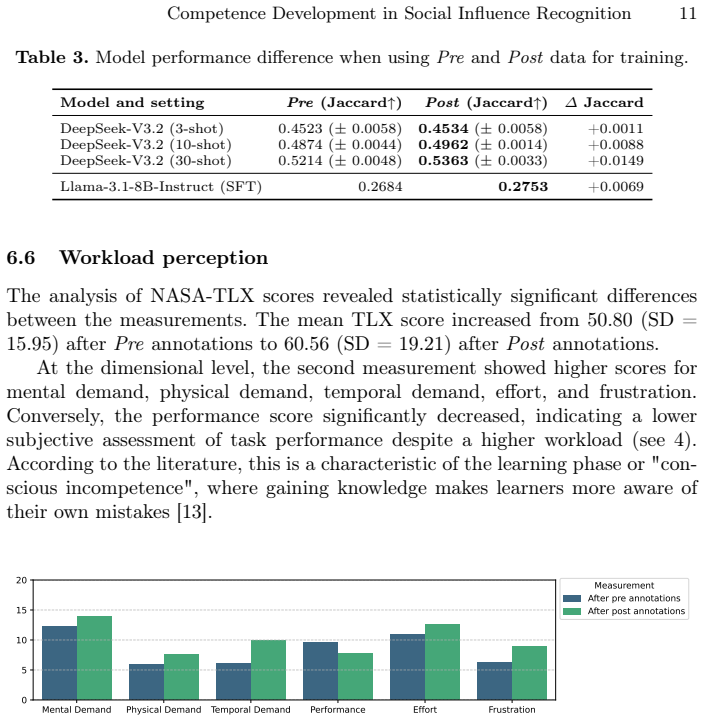

read the original abstract
Human data annotation, especially when involving experts, is often treated as an objective reference. However, many annotation tasks are inherently subjective, and annotators' judgments may evolve over time. This study investigates changes in the quality of annotators' work from a competence perspective during a process of social influence recognition. The study involved 25 annotators from five different groups, including both experts and non-experts, who annotated a dataset of 1,021 dialogues with 20 social influence techniques, along with intentions, reactions, and consequences. An initial subset of 150 texts was annotated twice - before and after the main annotation process - to enable comparison. To measure competence shifts, we combined qualitative and quantitative analyses of the annotated data, semi-structured interviews with annotators, self-assessment surveys, and Large Language Model training and evaluation on the comparison dataset. The results indicate a significant increase in annotators' self-perceived competence and confidence. Moreover, observed changes in data quality suggest that the annotation process may enhance annotator competence and that this effect is more pronounced in expert groups. The observed shifts in annotator competence have a visible impact on the performance of LLMs trained on their annotated data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that annotating 1,021 dialogues for 20 social influence techniques (plus intentions, reactions, and consequences) produces measurable competence development in 25 annotators drawn from expert and non-expert groups. Evidence is drawn from a before-after comparison on an initial 150-text subset, combined with self-assessment surveys, semi-structured interviews, quantitative label-quality metrics, and downstream LLM training/evaluation on the comparison set. The central results are reported increases in self-perceived competence and confidence, improvements in data quality that are stronger for experts, and visible gains in LLM performance when models are trained on the post-annotation data.
Significance. If the competence-development claim survives rigorous controls, the work would usefully demonstrate that annotation is not merely a data-collection step but an active learning process whose effects can be measured in label consistency, annotator self-reports, and downstream model quality. This would inform best practices for expert annotation pipelines and for using annotation tasks as implicit training mechanisms in subjective NLP domains.
major comments (3)
- [Methods] The before-after design on the 150-text comparison set (described in the Methods section on annotation procedure) contains no control arm, order counterbalancing, or isolation of learning mechanisms. Consequently, any observed shifts in agreement, confidence scores, or LLM F1 could arise from simple task familiarity, reduced initial uncertainty, or practice curves rather than genuine competence development. This directly weakens the stronger claims that the effect is 'more pronounced in expert groups' and that it 'has a visible impact' on trained models.
- [Results] The differential effect on expert versus non-expert groups is asserted without reported statistical interaction tests, subgroup effect sizes, or error bars on the quality and LLM metrics. The Results section therefore does not yet establish that the competence gains are reliably larger for experts.
- [Results] The LLM evaluation (final subsection of Results) reports performance differences on the comparison set but provides no baseline models trained on independent data, no details on training hyperparameters or data splits, and no ablation that isolates annotator-competence changes from other dataset properties. It is therefore unclear whether the reported 'visible impact' is attributable to the claimed competence shifts.
minor comments (2)
- [Abstract] The abstract states that results indicate a 'significant increase' in self-perceived competence; the corresponding Results section should report exact statistical tests, p-values, and effect sizes for all self-report and quality metrics.
- [Introduction] Clarify the exact operational definitions and inter-annotator agreement baselines for the 20 social-influence categories at the first mention in the Introduction or Methods.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important methodological and reporting issues that we will address to strengthen the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Methods] The before-after design on the 150-text comparison set (described in the Methods section on annotation procedure) contains no control arm, order counterbalancing, or isolation of learning mechanisms. Consequently, any observed shifts in agreement, confidence scores, or LLM F1 could arise from simple task familiarity, reduced initial uncertainty, or practice curves rather than genuine competence development. This directly weakens the stronger claims that the effect is 'more pronounced in expert groups' and that it 'has a visible impact' on trained models.
Authors: We agree that the within-subjects before-after design on the 150-text set lacks a separate control arm and counterbalancing, which prevents full isolation of competence development from practice or familiarity effects. Our interpretation relies on convergent evidence from self-reports, interviews, label-consistency metrics, and LLM performance rather than a single causal claim. In the revision we will add an explicit limitations paragraph that discusses these confounds, replace stronger causal phrasing with 'associated with' or 'suggests possible competence development,' and note that a controlled follow-up study would be needed to confirm mechanisms. revision: partial
-
Referee: [Results] The differential effect on expert versus non-expert groups is asserted without reported statistical interaction tests, subgroup effect sizes, or error bars on the quality and LLM metrics. The Results section therefore does not yet establish that the competence gains are reliably larger for experts.
Authors: We accept that the current Results section does not include formal tests for group-by-time interactions. In the revised version we will add mixed-effects models (or repeated-measures ANOVA) with group (expert/non-expert) × time (pre/post) interaction terms, report effect sizes, and include error bars or confidence intervals on all quality and LLM performance figures and tables. revision: yes
-
Referee: [Results] The LLM evaluation (final subsection of Results) reports performance differences on the comparison set but provides no baseline models trained on independent data, no details on training hyperparameters or data splits, and no ablation that isolates annotator-competence changes from other dataset properties. It is therefore unclear whether the reported 'visible impact' is attributable to the claimed competence shifts.
Authors: We will expand the LLM subsection with full details on hyperparameters, data splits, and training protocol. The core comparison is between models trained on the same 150 texts labeled before versus after the main annotation round by the same annotators; this design directly links performance change to shifts in the annotators' output. We did not include fully independent external baselines because the study focus was the within-annotator change rather than absolute performance. In revision we will clarify this rationale, add a short discussion of the limitation, and include a simple ablation (e.g., performance on label-shuffled versions of the post-annotation data). revision: partial
Circularity Check
No circularity: empirical before-after measurements are independent of inputs
full rationale
The paper is a purely empirical study relying on primary data collection from 25 annotators labeling 1,021 dialogues, with before-after comparisons on a 150-text subset, plus surveys, interviews, and downstream LLM training. No equations, fitted parameters, self-definitional constructs, or derivations appear in the provided text or abstract. Central claims rest on observed shifts in label quality, self-reported competence, and model performance metrics, which are measured outcomes rather than quantities defined in terms of themselves. Any self-citations (none load-bearing in the excerpt) would not reduce the results to inputs by construction. Methodological concerns about confounds exist but fall outside circularity criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abercrombie,G.,etal.:Temporalandsecondlanguageinfluenceonintra-annotator agreement and stability in hate speech labelling. In: Proc. 17th Linguistic An- notation Workshop (LAW-XVII). pp. 96–103. ACL, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.law-1.10
- [2]
-
[3]
Bassi, D., et al.: Annotating the annotators: Analysis, insights and modelling from an annotation campaign on persuasion techniques detection. In: Findings of ACL. pp. 17918–17929. ACL, Vienna, Austria (2025).https://doi.org/10.18653/v1/ 2025.findings-acl.922
-
[4]
Qualitative Research in Psychology3(2), 77–101 (2006)
Braun, V., Clarke, V.: Using thematic analysis in psychology. Qualitative Research in Psychology3(2), 77–101 (2006)
work page 2006
-
[5]
Family Medicine and Community Health7(2) (2019), e000057
DeJonckheere, M., Vaughn, L.M.: Semistructured interviewing in primary care research. Family Medicine and Community Health7(2) (2019), e000057
work page 2019
-
[6]
Doroudi, S., et al.: Toward a learning science for complex crowdsourcing tasks. In: Proc. CHI. p. 2623–2634. ACM, New York, NY, USA (2016).https://doi.org/ 10.1145/2858036.2858268
-
[7]
Fleisig, E., et al.: The perspectivist paradigm shift: Assumptions and challenges of capturing human labels. In: Proc. NAACL-HLT. pp. 2279–2292. ACL, Mexico City, Mexico (2024).https://doi.org/10.18653/v1/2024.naacl-long.126
-
[8]
Hart,S.G.,Staveland,L.E.:DevelopmentoftheNASA-TLX(TaskLoadIndex).In: Human Mental Workload. Advances in Psychology, vol. 52, pp. 139–183. Elsevier, Amsterdam (1988).https://doi.org/10.1016/S0166-4115(08)62386-9
-
[9]
Hata, K., et al.: A glimpse far into the future: Understanding long-term crowd worker quality. In: Proc. CSCW. pp. 889–901. ACM (2017).https://doi.org/ 10.1145/2998181.2998248
-
[10]
Hsieh, H.F., Shannon, S.: Three approaches to qualitative content analysis. Qual- itative Health Research15, 1277–1288 (11 2005).https://doi.org/10.1177/ 1049732305276687 Competence Development in Social Influence Recognition 15
work page 2005
-
[11]
Prentice-Hall, Englewood Cliffs, NJ (1984)
Kolb, D.A.: Experiential Learning: Experience as the Source of Learning and De- velopment. Prentice-Hall, Englewood Cliffs, NJ (1984)
work page 1984
-
[12]
Lee, J.U., et al.: Annotation curricula to implicitly train non-expert annotators. Comput. Linguist.48, 343–373 (2022).https://doi.org/10.1162/coli_a_00436
-
[13]
Mohamed, R., et al.: Validation of the NASA-TLX to evaluate the learning curve for endoscopy training. Can. J. Gastroenterol. Hepatol.28, 892476 (2014).https: //doi.org/10.1155/2014/892476
-
[14]
Mokhberian, N., et al.: Capturing perspectives of crowdsourced annotators in sub- jective learning tasks. In: Proc. NAACL-HLT. pp. 7337–7349. ACL, Mexico City, Mexico (2024).https://doi.org/10.18653/v1/2024.naacl-long.407
-
[15]
Renkl, A.: Toward an instructionally oriented theory of example-based learning. Cognit. Sci.38, 1–37 (2014).https://doi.org/10.1111/cogs.12086
-
[16]
Tai, R.H., et al.: An examination of the use of large language models to aid analysis of textual data. Int. J. Qual. Methods23, 16094069241231168 (2024).https:// doi.org/10.1177/16094069241231168
-
[17]
Cambridge University Press (2021)
Vitello, S., et al.: What is competence? A shared interpretation of competence to support teaching, learning and assessment. Cambridge University Press (2021). https://doi.org/10.17863/CAM.110829
-
[18]
Yoo, H., et al.: Rethinking annotation: Can language learners contribute? In: Proc. ACL. pp. 14714–14733. ACL, Toronto, Canada (2023).https://doi.org/ 10.18653/v1/2023.acl-long.822
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.