Recognition: 2 theorem links
· Lean TheoremMulti-Aspect Knowledge Distillation for Language Model with Low-rank Factorization
Pith reviewed 2026-05-13 20:31 UTC · model grok-4.3
The pith
Multi-aspect knowledge distillation with low-rank factorization compresses language models while matching strong baselines by mimicking attention and feed-forward modules in detail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
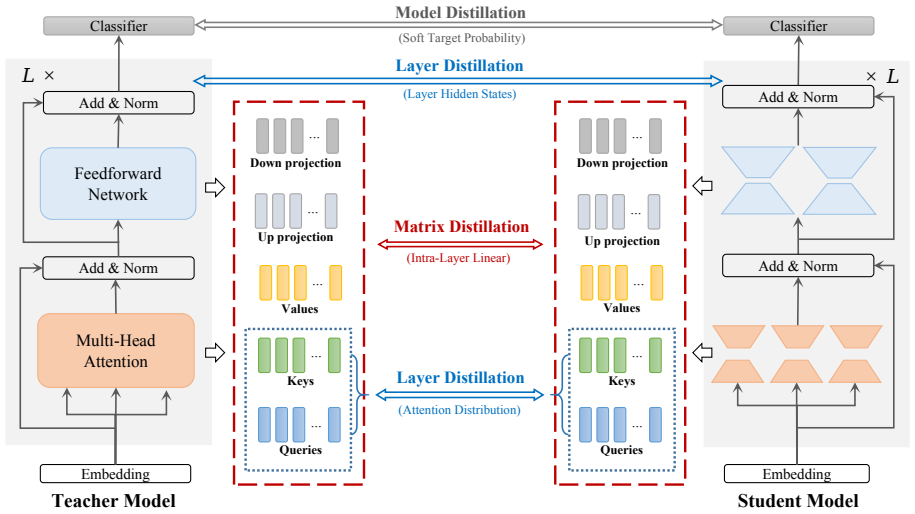
MaKD mimics the self-attention and feed-forward modules in greater depth to capture rich language knowledge information at different aspects. Experimental results demonstrate that MaKD can achieve competitive performance compared with various strong baselines with the same storage parameter budget. In addition, the method also performs well in distilling auto-regressive architecture models.
What carries the argument
The Multi-aspect Knowledge Distillation (MaKD) method, which separately mimics self-attention and feed-forward modules at multiple aspects and applies low-rank factorization for size control.
Where Pith is reading between the lines
- The multi-aspect mimicking could extend to other transformer variants that share similar internal module structures.
- This form of distillation might reduce the accuracy gap when compressing models for tasks requiring precise generation or reasoning.
- Combining MaKD with additional compression steps like quantization could further shrink model size while preserving the reported gains.
Load-bearing premise
Separately mimicking self-attention and feed-forward modules at multiple aspects with low-rank factorization transfers fine-grained language knowledge without introducing distortions beyond those already present in standard layer-wise methods.
What would settle it
A side-by-side test on the same teacher-student pair where MaKD at fixed parameter count shows clearly lower accuracy than a standard layer-wise distillation baseline on a held-out benchmark would falsify the central claim.
Figures

read the original abstract
Knowledge distillation is an effective technique for pre-trained language model compression. However, existing methods only focus on the knowledge distribution among layers, which may cause the loss of fine-grained information in the alignment process. To address this issue, we introduce the Multi-aspect Knowledge Distillation (MaKD) method, which mimics the self-attention and feed-forward modules in greater depth to capture rich language knowledge information at different aspects. Experimental results demonstrate that MaKD can achieve competitive performance compared with various strong baselines with the same storage parameter budget. In addition, our method also performs well in distilling auto-regressive architecture models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi-Aspect Knowledge Distillation (MaKD) to compress pre-trained language models. Standard layer-wise distillation is extended by separately mimicking self-attention and feed-forward modules at multiple aspects to retain fine-grained knowledge; low-rank factorization is applied to meet a fixed storage budget. The central empirical claim is that MaKD matches or exceeds strong baselines under identical parameter constraints and also succeeds when distilling auto-regressive architectures.
Significance. If the reported gains are reproducible and the multi-aspect component is shown to be additive rather than redundant with low-rank compression, the method would supply a practical refinement to existing distillation pipelines, particularly for resource-constrained deployment of both encoder-only and decoder-only models.
major comments (2)
- [§3] §3 (Method): low-rank factorization is applied to the student modules whose outputs are mimicked, yet no operator-norm bound, residual analysis, or ablation isolates the factorization error from the multi-aspect distillation losses; without this, it remains possible that observed improvements stem from compression alone rather than the added mimicking aspects.
- [Experiments] Experimental section: the abstract asserts competitive results with the same storage budget, but no concrete metrics, datasets (GLUE, SQuAD, etc.), baselines, or ablation tables are referenced; the contribution of the multi-aspect losses versus the low-rank component therefore cannot be verified.
minor comments (1)
- [Abstract] The abstract omits any mention of low-rank factorization even though the title highlights it; a single sentence clarifying its role would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, clarifying how the multi-aspect component adds value beyond low-rank compression and committing to revisions that improve verifiability.
read point-by-point responses
-
Referee: [§3] §3 (Method): low-rank factorization is applied to the student modules whose outputs are mimicked, yet no operator-norm bound, residual analysis, or ablation isolates the factorization error from the multi-aspect distillation losses; without this, it remains possible that observed improvements stem from compression alone rather than the added mimicking aspects.
Authors: We agree that isolating the factorization error from the multi-aspect losses is valuable for clarity. In the revised manuscript we will add an explicit ablation that compares (i) low-rank factorization alone applied to the student modules against (ii) the full MaKD objective that includes the multi-aspect mimicking losses. This directly tests whether the observed gains are additive. We will also include a short residual analysis in the appendix that quantifies the per-module approximation error introduced by the low-rank factorization under the chosen rank budget. revision: yes
-
Referee: [Experiments] Experimental section: the abstract asserts competitive results with the same storage budget, but no concrete metrics, datasets (GLUE, SQuAD, etc.), baselines, or ablation tables are referenced; the contribution of the multi-aspect losses versus the low-rank component therefore cannot be verified.
Authors: The full paper already reports results on GLUE and SQuAD with concrete metrics, strong baselines (DistilBERT, TinyBERT, and standard layer-wise distillation), and ablation tables that separate the multi-aspect losses from the low-rank component. We will revise the abstract to explicitly cite these sections and include a one-sentence summary of the key numbers so that the contribution is immediately verifiable from the abstract alone. revision: partial
Circularity Check
No significant circularity in MaKD derivation
full rationale
The paper defines MaKD as an empirical procedure: standard layer-wise distillation losses are applied separately to self-attention and FFN modules at multiple aspects, with low-rank factorization used for compression. Performance is evaluated against external baselines under fixed parameter budgets, not against quantities defined from the same fitted values. No equation reduces by construction to its inputs, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled via prior work. The derivation chain is self-contained and externally falsifiable via the reported experiments.
Axiom & Free-Parameter Ledger
free parameters (1)
- low-rank dimension
axioms (1)
- domain assumption Self-attention and feed-forward modules contain independent, transferable language knowledge that can be aligned separately without interference.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We first use singular value decomposition (SVD) to obtain an equivalent form of W... low-rank approximation... Matrix Distillation... Layer Distillation... Model Distillation
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lmatrix = LMHA + LFNN; Llayer = Lattn + Lhidn; hierarchical assignment to shallow/deep layers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics
What does BERT learn about the structure of language? InProceedings of the 57th Annual Meet- ing of the Association for Computational Linguistics, pages 3651–3657, Florence, Italy. Association for Computational Linguistics. Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. TinyBERT: Distilling BERT for n...
work page 2020
-
[2]
Bioinformatics, 36(4):1234–1240
Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240. Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation,...
-
[3]
Mixkd: Towards efficient distillation of large- scale language models.Preprint, arXiv:2011.00593. Chin-Yew Lin. 2004. ROUGE: A package for auto- matic evaluation of summaries. InText Summariza- tion Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man- dar Joshi, Danqi C...
-
[4]
A broad-coverage challenge corpus for sen- tence understanding through inference. InProceed- ings of the 2018 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122, New Orleans, Louisiana. Association for Computational Linguis- tics. Bi-Cheng Yan, J...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.