Recognition: 1 theorem link
· Lean TheoremBibTeX Citation Hallucinations in Scientific Publishing Agents: Evaluation and Mitigation
Pith reviewed 2026-05-13 18:11 UTC · model grok-4.3
The pith
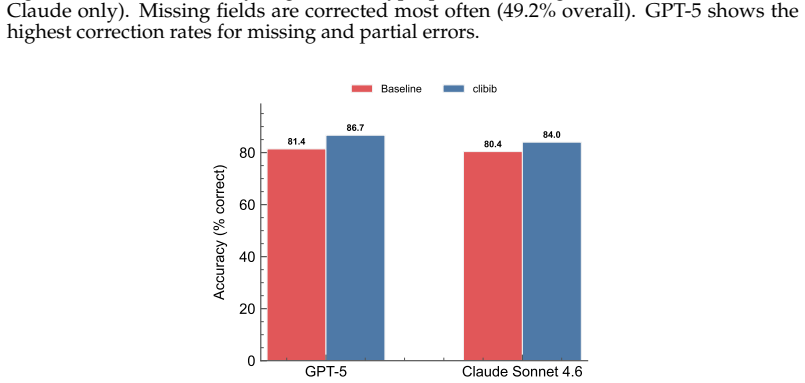
Two-stage integration of LLM BibTeX outputs with Zotero and CrossRef records raises field accuracy to 91.5 percent and fully correct entries to 78.3 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Frontier models generate BibTeX entries with 83.6 percent field accuracy across nine fields yet only 50.9 percent of entries are fully correct; a two-stage integration that revises these outputs against deterministic retrieval from the Zotero Translation Server and CrossRef raises field accuracy to 91.5 percent and fully correct entries to 78.3 percent with 0.8 percent regression, while separating search from revision produces larger gains and lower regression than combined single-stage processing.
What carries the argument
clibib, a deterministic BibTeX retrieval tool from the Zotero Translation Server with CrossRef fallback, used to revise baseline LLM-generated entries in a two-stage integration against version-aware ground truth.
If this is right
- Accuracy improves eight percentage points when baseline LLM entries are revised against authoritative records.
- Fully correct entries rise from 50.9 percent to 78.3 percent with only 0.8 percent regression.
- Separating search from revision yields larger gains and lower regression than single-stage integration.
- Field-error co-occurrence reveals two distinct failure modes: wholesale entry substitution and isolated field errors.
- Accuracy drops 27.7 points for recent post-cutoff papers, showing continued heavy reliance on parametric memory.
Where Pith is reading between the lines
- The two-stage revision pattern could apply to other structured outputs such as reference lists or data tables in scientific writing.
- Writing-assistant tools and journal submission systems could embed similar retrieval steps to reduce citation errors at scale.
- The released benchmark enables direct comparison of future models and mitigation techniques on the same 931-paper set.
- Extending the benchmark to additional languages or citation styles would test whether the observed failure modes and mitigation gains generalize.
Load-bearing premise
The version-aware ground truth built from Zotero and CrossRef is accurate and complete for the 931 papers and the nine-field scoring plus six-way error taxonomy captures real citation quality needs.
What would settle it
Independent manual inspection of a random sample of the constructed ground truth entries against original paper sources that finds any mismatches among the nine scored fields.
Figures




















read the original abstract
Large language models with web search are increasingly used in scientific publishing agents, yet they still produce BibTeX entries with pervasive field-level errors. Prior evaluations tested base models without search, which does not reflect current practice. We construct a benchmark of 931 papers across four scientific domains and three citation tiers -- popular, low-citation, and recent post-cutoff -- designed to disentangle parametric memory from search dependence, with version-aware ground truth accounting for multiple citable versions of the same paper. Three search-enabled frontier models (GPT-5, Claude Sonnet-4.6, Gemini-3 Flash) generate BibTeX entries scored on nine fields and a six-way error taxonomy, producing ~23,000 field-level observations. Overall accuracy is 83.6%, but only 50.9% of entries are fully correct; accuracy drops 27.7pp from popular to recent papers, revealing heavy reliance on parametric memory even when search is available. Field-error co-occurrence analysis identifies two failure modes: wholesale entry substitution (identity fields fail together) and isolated field error. We evaluate clibib, an open-source tool for deterministic BibTeX retrieval from the Zotero Translation Server with CrossRef fallback, as a mitigation mechanism. In a two-stage integration where baseline entries are revised against authoritative records, accuracy rises +8.0pp to 91.5%, fully correct entries rise from 50.9% to 78.3%, and regression rate is only 0.8%. An ablation comparing single-stage and two-stage integration shows that separating search from revision yields larger gains and lower regression (0.8% vs. 4.8%), demonstrating that integration architecture matters independently of model capability. We release the benchmark, error taxonomy, and clibib tool to support evaluation and mitigation of citation hallucinations in LLM-based scientific writing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates BibTeX entry generation by three search-enabled frontier LLMs on a new benchmark of 931 papers spanning four domains and three citation tiers (popular, low-citation, recent post-cutoff). It reports 83.6% field-level accuracy but only 50.9% fully correct entries, with a 27.7pp accuracy drop for recent papers, and introduces the clibib tool for deterministic retrieval from Zotero Translation Server with CrossRef fallback. A two-stage integration of baseline LLM output with clibib revision raises accuracy to 91.5%, fully correct entries to 78.3%, and keeps regression at 0.8%; an ablation shows separating search from revision outperforms single-stage integration.
Significance. If the evaluation holds, the work supplies a concrete, released benchmark and error taxonomy for citation hallucinations in publishing agents, plus an open-source mitigation whose +8.0pp gain and low regression are tied to integration architecture rather than model scale. The ~23,000 field observations and tiered design that isolates parametric memory from search are useful contributions for the field.
major comments (2)
- [Benchmark Construction] Benchmark Construction section: The version-aware ground truth is built exclusively from Zotero Translation Server + CrossRef; no independent cross-check against other databases or manual verification is reported for the recent post-cutoff tier, where the largest accuracy drop (27.7pp) occurs. This leaves open the possibility that database lag or missing versions inflate the reported gains and understate regression.
- [Error Taxonomy and Scoring] Error Taxonomy and Scoring section: The six-way taxonomy and nine-field scoring contain no explicit category for version-selection or database-lag mismatches. Because clibib retrieves from the identical sources used to construct ground truth, this omission means the evaluation cannot distinguish retrieval fidelity from ground-truth incompleteness.
minor comments (2)
- [Abstract] Abstract: The derivation of the ~23,000 field-level observations (931 papers × 9 fields × 3 models) should be stated explicitly so readers can verify the count.
- [Results] Table or figure presenting per-tier results: Add confidence intervals or per-model breakdowns to the accuracy and regression numbers to support the cross-tier claims.
Simulated Author's Rebuttal
We thank the referee for these targeted comments on benchmark construction and error taxonomy. Both points highlight important considerations for the reliability of our evaluation, particularly for the recent post-cutoff tier. We address each below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: The version-aware ground truth is built exclusively from Zotero Translation Server + CrossRef; no independent cross-check against other databases or manual verification is reported for the recent post-cutoff tier, where the largest accuracy drop (27.7pp) occurs. This leaves open the possibility that database lag or missing versions inflate the reported gains and understate regression.
Authors: We acknowledge that exclusive reliance on Zotero Translation Server and CrossRef without reported independent verification for the recent tier represents a limitation, as database lag could affect the measured accuracy drop. These sources were selected for their direct provision of structured, version-aware BibTeX records that align with our evaluation needs. In the revised manuscript we will add a limitations paragraph discussing potential coverage gaps for post-cutoff papers and include results from a manual cross-check of a random sample of 50 recent papers against publisher sites and Google Scholar to quantify any discrepancies. revision: partial
-
Referee: [Error Taxonomy and Scoring] Error Taxonomy and Scoring section: The six-way taxonomy and nine-field scoring contain no explicit category for version-selection or database-lag mismatches. Because clibib retrieves from the identical sources used to construct ground truth, this omission means the evaluation cannot distinguish retrieval fidelity from ground-truth incompleteness.
Authors: We agree this is a substantive gap: the taxonomy does not isolate version-selection or lag mismatches, and shared sources between clibib and ground truth mean retrieval success cannot be fully separated from source completeness. We will revise the taxonomy section to introduce an explicit 'version mismatch' error category and add a short discussion clarifying that clibib performance is measured relative to the chosen authoritative sources rather than an absolute ground truth. This change will not alter the reported accuracy numbers but will improve interpretability. revision: yes
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper is a direct empirical evaluation that constructs a benchmark of 931 papers using external Zotero and CrossRef sources, scores model-generated BibTeX entries on nine fields, and measures accuracy gains from integrating the clibib retrieval tool. No load-bearing steps involve mathematical derivations, fitted parameters renamed as predictions, self-definitional claims, or self-citations that justify uniqueness or ansatzes. The reported +8.0pp accuracy lift and 0.8% regression are measured experimental outcomes against an independently sourced ground truth, not reductions by construction. This matches the default expectation for non-circular empirical work with released artifacts.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models with web search are increasingly used in scientific publishing agents
Reference graph
Works this paper leans on
-
[1]
URL http://arxiv.org/abs/2602.15871. arXiv:2602.15871. Ayush Agrawal, Mirac Suzgun, Lester Mackey, and Adam Tauman Kalai. Do Language Models Know When They’re Hallucinating References?, March
-
[2]
URL http://arxiv. org/abs/2305.18248. arXiv:2305.18248. Andres Algaba, Carmen Mazijn, Vincent Holst, Floriano Tori, Sylvia Wenmackers, and Vin- cent Ginis. Large Language Models Reflect Human Citation Patterns with a Heightened Citation Bias, August
-
[3]
URLhttp://arxiv.org/abs/2405.15739. arXiv:2405.15739. Fadi Aljamaan, Mohamad-Hani Temsah, Ibraheem Altamimi, Ayman Al-Eyadhy, Amr Jamal, Khalid Alhasan, Tamer A Mesallam, Mohamed Farahat, and Khalid H Malki. Reference Hallucination Score for Medical Artificial Intelligence Chatbots: Development and Usability Study.JMIR Medical Informatics, 12:e54345, July
-
[4]
ISSN 2291-9694. doi: 10.2196/54345. URLhttps://medinform.jmir.org/2024/1/e54345. Hussam Alkaissi and Samy I McFarlane. Artificial Hallucinations in ChatGPT: Implications in Scientific Writing.Cureus, February
-
[5]
doi: 10.7759/cureus.35179. URL https://www.cureus.com/articles/ 138667-artificial-hallucinations-in-chatgpt-implications-in-scientific-writing . Samar Ansari. Compound Deception in Elite Peer Review: A Failure Mode Taxonomy of 100 Fabricated Citations at NeurIPS 2025, February
-
[6]
URL http://arxiv.org/abs/ 2602.05930. arXiv:2602.05930. Moses Boudourides. Structural Hallucination in Large Language Models: A Network- Based Evaluation of Knowledge Organization and Citation Integrity,
-
[7]
URL https: //arxiv.org/abs/2603.01341. Mika¨el Chelli, Jules Descamps, Vincent Lavou´e, Christophe Trojani, Michel Azar, Marcel Deckert, Jean-Luc Raynier, Gilles Clowez, Pascal Boileau, and Caroline Ruetsch-Chelli. Hallucination Rates and Reference Accuracy of ChatGPT and Bard for Systematic Reviews: Comparative Analysis.Journal of Medical Internet Resear...
-
[8]
URLhttps://www.jmir.org/2024/1/e53164
doi: 10.2196/53164. URLhttps://www.jmir.org/2024/1/e53164. I.-Chun Chern, Steffi Chern, Shiqi Chen, Weizhe Yuan, Kehua Feng, Chunting Zhou, Junxian He, Graham Neubig, and Pengfei Liu. FacTool: Factuality Detection in Generative AI – A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios, July
-
[9]
arXiv preprint arXiv:2307.13528 , year =
URL http://arxiv.org/abs/2307.13528. arXiv:2307.13528. 35 Preprint. Under review. Yee Man Choi, Xuehang Guo, Yi R. Fung, and Qingyun Wang. CiteGuard: Faithful Citation Attribution for LLMs via Retrieval-Augmented Validation, January
-
[10]
CiteGuard: Faithful Citation Attribution for LLMs via Retrieval-Augmented Validation
URL http: //arxiv.org/abs/2510.17853. arXiv:2510.17853. Mourad Gridach, Jay Nanavati, Christina Mack, Khaldoun Zine El Abidine, and Lenon Mendes. Agentic AI for Scientific Discovery: A Survey of Progress, Challenges, and Future Directions. InProceedings of the Thirteenth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URLhttp://arxiv.org/abs/2602.23075. arXiv:2602.23075. Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, November
-
[12]
URLhttp://arxiv.org/abs/2311.05232. arXiv:2311.05232. Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of Hallucination in Natural Language Generation.ACM Computing Surveys, 55(12):1–38, December
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
doi: 10.1145/3571730. URLhttps://dl.acm.org/doi/10.1145/3571730. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K ¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨aschel, Sebastian Riedel, and Douwe Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, April
-
[14]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
URLhttp://arxiv.org/abs/2005.11401. arXiv:2005.11401. Peiran Li, Fangzhou Lin, Shuo Xing, Xiang Zheng, Xi Hong, Siyuan Yang, Jiashuo Sun, Zhengzhong Tu, and Chaoqun Ni. BibAgent: An Agentic Framework for Traceable Miscitation Detection in Scientific Literature, January
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[15]
URL http://arxiv.org/abs/ 2601.16993. arXiv:2601.16993. Delip Rao Nair. autorubric: LLM-as-a-judge with weighted rubric criteria.arXiv preprint arXiv:2603.00077,
-
[16]
WebGPT: Browser-assisted question-answering with human feedback
URLhttp://arxiv.org/abs/2112.09332. arXiv:2112.09332. Junichiro Niimi. Hallucinations in Bibliographic Recommendation: Citation Frequency as a Proxy for Training Data Redundancy,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Yusuke Sakai, Hidetaka Kamigaito, and Taro Watanabe
URLhttps://arxiv.org/abs/2510.25378. Yusuke Sakai, Hidetaka Kamigaito, and Taro Watanabe. HalluCitation Matters: Revealing the Impact of Hallucinated References with 300 Hallucinated Papers in ACL Conferences, January
-
[18]
URLhttp://arxiv.org/abs/2601.18724. arXiv:2601.18724. Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent Laboratory: Using LLM Agents as Research Assistants. InFindings of the Association for Computational Linguistics: EMNLP 2025, pp. 5977–6043, Suzhou, China,
-
[19]
doi: 10.18653/v1/2025.findings-emnlp.320
Association for Computational Lin- guistics. doi: 10.18653/v1/2025.findings-emnlp.320. URL https://aclanthology.org/ 2025.findings-emnlp.320. Stefan Szeider. Unmediated AI-Assisted Scholarly Citations, February
-
[20]
URL http: //arxiv.org/abs/2602.01686. arXiv:2602.01686. William H. Walters and Esther Isabelle Wilder. Fabrication and errors in the bibliographic ci- tations generated by ChatGPT.Scientific Reports, 13(1):14045, September
-
[21]
URL http://arxiv.org/abs/2602.06718. arXiv:2602.06718. Zhengqing Yuan, Kaiwen Shi, Zheyuan Zhang, Lichao Sun, Nitesh V . Chawla, and Yanfang Ye. CiteAudit: You Cited It, But Did You Read It? A Benchmark for Verifying Scientific References in the LLM Era, February
work page internal anchor Pith review arXiv
-
[22]
URL http://arxiv.org/abs/2602.23452. arXiv:2602.23452. 37
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.