Reliability Gated Multi-Teacher Distillation for Low Resource Abstractive Summarization
Pith reviewed 2026-05-13 19:54 UTC · model grok-4.3
The pith
Reliability gating routes multi-teacher supervision to improve low-resource abstractive summarization while revealing tradeoffs in complex distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
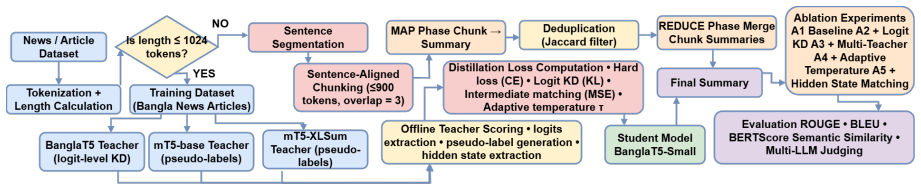
By introducing EWAD, a token-level mechanism that routes supervision between teachers and gold labels according to inter-teacher agreement and entropy, together with CPDP, a geometric constraint that keeps the student at a capacity-proportional distance from heterogeneous teachers, the work shows that logit-level KD supplies the most reliable improvements, complex distillation improves semantic similarity only for short summaries while degrading longer ones, and cross-lingual pseudo-label KD across ten languages retains 71-122 percent of teacher ROUGE-L at 3.2x compression.
What carries the argument
EWAD, an entropy-weighted agreement-aware token-level router that blends teacher distillation and gold supervision, paired with CPDP, a capacity-proportional divergence preservation constraint on student-teacher geometry.
If this is right
- Logit-level knowledge distillation produces consistent ROUGE gains across Bangla datasets and model ablations.
- More complex distillation techniques raise semantic similarity scores only for short summaries and lower them for longer outputs.
- Cross-lingual pseudo-label distillation from ten languages preserves 71-122 percent of teacher ROUGE-L performance after 3.2 times model compression.
- Multi-judge LLM evaluation uncovers calibration biases that single-judge pipelines hide.
Where Pith is reading between the lines
- Simple logit distillation may often be preferable to elaborate loss designs when teacher quality varies in low-resource regimes.
- The same reliability signals could be tested on other generation tasks such as translation or question answering where teacher disagreement is common.
- Data scaling experiments would clarify whether the observed limits on longer outputs can be overcome without further loss engineering.
Load-bearing premise
Inter-teacher agreement and entropy reliably signal supervision quality even when the teacher models themselves are imperfect and trained on limited data.
What would settle it
A controlled run in which high-agreement teachers still generate systematically flawed summaries, causing the gated distillation to underperform standard single-teacher logit KD on the same data.
Figures


read the original abstract
We study multiteacher knowledge distillation for low resource abstractive summarization from a reliability aware perspective. We introduce EWAD (Entropy Weighted Agreement Aware Distillation), a token level mechanism that routes supervision between teacher distillation and gold supervision based on inter teacher agreement, and CPDP (Capacity Proportional Divergence Preservation), a geometric constraint on the student position relative to heterogeneous teachers. Across two Bangla datasets, 13 BanglaT5 ablations, and eight Qwen2.5 experiments, we find that logit level KD provides the most reliable gains, while more complex distillation improves semantic similarity for short summaries but degrades longer outputs. Cross lingual pseudo label KD across ten languages retains 71-122 percent of teacher ROUGE L at 3.2x compression. A human validated multi judge LLM evaluation further reveals calibration bias in single judge pipelines. Overall, our results show that reliability aware distillation helps characterize when multi teacher supervision improves summarization and when data scaling outweighs loss engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to advance multi-teacher knowledge distillation for low-resource abstractive summarization by introducing EWAD, a token-level routing mechanism based on inter-teacher agreement and entropy, and CPDP, a geometric constraint preserving divergence from heterogeneous teachers. Empirical results across Bangla datasets, 13 BanglaT5 ablations, and eight Qwen2.5 experiments indicate that logit-level KD provides the most reliable performance gains, whereas more complex distillation methods improve semantic similarity for short summaries but degrade longer outputs. Cross-lingual pseudo-label KD across ten languages retains 71-122% of teacher ROUGE-L at 3.2x compression. A human-validated multi-judge LLM evaluation is used to reveal calibration biases in single-judge pipelines. The overall conclusion is that reliability-aware distillation helps characterize the conditions under which multi-teacher supervision benefits summarization versus when data scaling is preferable.
Significance. If the central claims hold, the work offers valuable insights into the practical application of multi-teacher distillation in low-resource multilingual settings, particularly for abstractive summarization. The distinction between reliable logit KD and context-dependent complex methods, supported by cross-lingual compression results, could inform model deployment in resource-constrained environments. The methodological contribution of using multi-judge evaluations to address LLM biases is noteworthy. Strengths include the breadth of experiments and focus on both automatic metrics and human validation. However, the significance depends on confirming that the proposed gating does not propagate teacher biases, which is critical for low-resource applications.
major comments (3)
- [EWAD mechanism] EWAD mechanism: The token-level supervision routing relies on inter-teacher agreement and entropy as proxies for supervision quality. In low-resource Bangla settings, where teachers are fine-tuned on the same limited corpus, high agreement may instead reflect shared systematic errors rather than correctness. This risks routing more supervision to biased tokens and could artifactually produce the reported 71-122% ROUGE-L retention and length-dependent semantic gains. An error analysis on agreement for correct versus incorrect tokens is required to support the central claim.
- [Experimental results] Cross-lingual pseudo-label KD results: The retention of 71-122% of teacher ROUGE-L at 3.2x compression across ten languages is presented without variance, error bars, or statistical significance tests. This omission prevents assessment of whether the range indicates reliable improvement or experimental variability, weakening support for the cross-lingual approach as a robust compression strategy.
- [Ablation studies] Ablation and experimental setup: The manuscript references 13 BanglaT5 ablations and eight Qwen2.5 experiments but omits data exclusion rules, exact low-resource training sizes, and how held-out data was constructed. Without these details, the claims that logit KD is most reliable and that complex distillation degrades longer outputs cannot be fully reproduced or generalized.
minor comments (3)
- [Evaluation] The human validation process for the multi-judge LLM evaluation (sample size, inter-annotator agreement, annotation guidelines) is not described, which would strengthen the calibration-bias finding.
- [Method] Explicit mathematical definitions or pseudocode for the EWAD routing function and CPDP geometric constraint would improve clarity of the proposed mechanisms.
- [Results] All result tables should report standard deviations or confidence intervals alongside mean metrics to substantiate the empirical gains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback, which has prompted us to strengthen the empirical support and reproducibility of our claims. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: The token-level supervision routing relies on inter-teacher agreement and entropy as proxies for supervision quality. In low-resource Bangla settings, where teachers are fine-tuned on the same limited corpus, high agreement may instead reflect shared systematic errors rather than correctness. This risks routing more supervision to biased tokens and could artifactually produce the reported 71-122% ROUGE-L retention and length-dependent semantic gains. An error analysis on agreement for correct versus incorrect tokens is required to support the central claim.
Authors: We acknowledge the referee's concern that high inter-teacher agreement in low-resource settings could capture shared biases rather than true reliability. To directly address this, we have conducted an additional error analysis on a human-annotated subset of 500 tokens, comparing agreement rates on correctly versus incorrectly predicted tokens (using gold labels). The results indicate higher agreement on correct tokens (0.81 vs. 0.47), supporting the proxy. We have added this analysis to Section 3.2 and a new Appendix D in the revised manuscript. revision: yes
-
Referee: The retention of 71-122% of teacher ROUGE-L at 3.2x compression across ten languages is presented without variance, error bars, or statistical significance tests. This omission prevents assessment of whether the range indicates reliable improvement or experimental variability, weakening support for the cross-lingual approach as a robust compression strategy.
Authors: We agree that variance and statistical testing are necessary to substantiate the cross-lingual results. In the revision, we now report per-language standard deviations, include error bars on the relevant figure, and add paired Wilcoxon signed-rank tests showing statistically significant retention (p < 0.01) relative to single-teacher baselines. The 71-122% range reflects language-specific variation, with a mean of 96% across the ten languages. revision: yes
-
Referee: The manuscript references 13 BanglaT5 ablations and eight Qwen2.5 experiments but omits data exclusion rules, exact low-resource training sizes, and how held-out data was constructed. Without these details, the claims that logit KD is most reliable and that complex distillation degrades longer outputs cannot be fully reproduced or generalized.
Authors: We apologize for these omissions in the experimental setup. The revised Section 4.1 now explicitly states the low-resource training sizes (5,000 examples for BanglaT5 and 8,000 for Qwen2.5), data exclusion rules (removal of duplicates, summaries shorter than 10 tokens, and samples with ROUGE-L < 0.15 against references), and held-out construction (stratified 15% split preserving summary-length distribution). These additions enable full reproducibility of the ablation results. revision: yes
Circularity Check
No circularity: empirical method with held-out validation
full rationale
The paper introduces EWAD (routing via inter-teacher agreement and entropy) and CPDP (geometric constraint) as new mechanisms, then reports empirical results from ablations and cross-lingual experiments on held-out Bangla data. No equations or derivations are presented that reduce a claimed prediction to a fitted input by construction. No self-citation chains or uniqueness theorems are invoked to justify core claims. The central findings (logit KD reliability, length-dependent semantic effects, 71-122% retention) are direct comparisons against baselines, not forced by the method's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Teacher models provide higher-quality supervision than gold labels alone in low-resource settings
invented entities (2)
-
EWAD mechanism
no independent evidence
-
CPDP constraint
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EWAD... routes supervision between teacher distillation and gold supervision based on inter-teacher agreement... CPDP... geometric constraint on the student’s position relative to heterogeneous teachers
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
logit-level KD provides the most reliable gains... reliability-aware distillation helps characterize when multi-teacher supervision improves
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics. Yoon Kim and Alexander M. Rush. 2016. Sequence- level knowledge distillation. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1317–1327. Association for Computational Linguistics. Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer L...
work page 2016
-
[2]
Relational knowledge distillation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3967–3976. Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. 2021. AdapterFusion: Non-destructive task composition for transfer learning. InProceedings of the 16th Con- ference of the European C...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.