Recognition: no theorem link
Next-Scale Autoregressive Models for Text-to-Motion Generation
Pith reviewed 2026-05-13 17:24 UTC · model grok-4.3
The pith
A next-scale autoregressive model generates text-to-motion sequences hierarchically from coarse to fine temporal resolutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MoScale is a next-scale autoregressive framework that generates motion hierarchically from coarse to fine temporal resolutions. By providing global semantics at the coarsest scale and refining them progressively, MoScale establishes a causal hierarchy better suited for long-range motion structure. To improve robustness under limited text-motion data, it incorporates cross-scale hierarchical refinement for improving per-scale initial predictions and in-scale temporal refinement for selective bidirectional re-prediction.
What carries the argument
The next-scale autoregressive prediction process operating across multiple temporal resolutions, supported by cross-scale refinement of initial predictions and in-scale temporal refinement for bidirectional re-prediction.
If this is right
- The model reaches state-of-the-art performance on text-to-motion benchmarks.
- Training becomes more efficient than standard autoregressive baselines.
- Performance continues to improve as model size increases.
- The same model applies zero-shot to varied motion generation and editing tasks without task-specific retraining.
Where Pith is reading between the lines
- The coarse-to-fine hierarchy may transfer to other sequential data domains such as video synthesis where global context precedes local detail.
- Stronger structural priors could lower the amount of paired text-motion data needed for high-quality results.
- Editing at chosen scales might allow targeted adjustments to attributes such as timing or posture without regenerating entire sequences.
Load-bearing premise
That generating global semantics first at the coarsest scale and refining progressively creates a causal hierarchy that captures long-range motion structure better than standard next-token prediction.
What would settle it
A controlled comparison in which a standard next-token autoregressive model, trained on identical data and scaled to similar capacity, matches or exceeds MoScale on metrics of long-range motion coherence and text alignment.
Figures
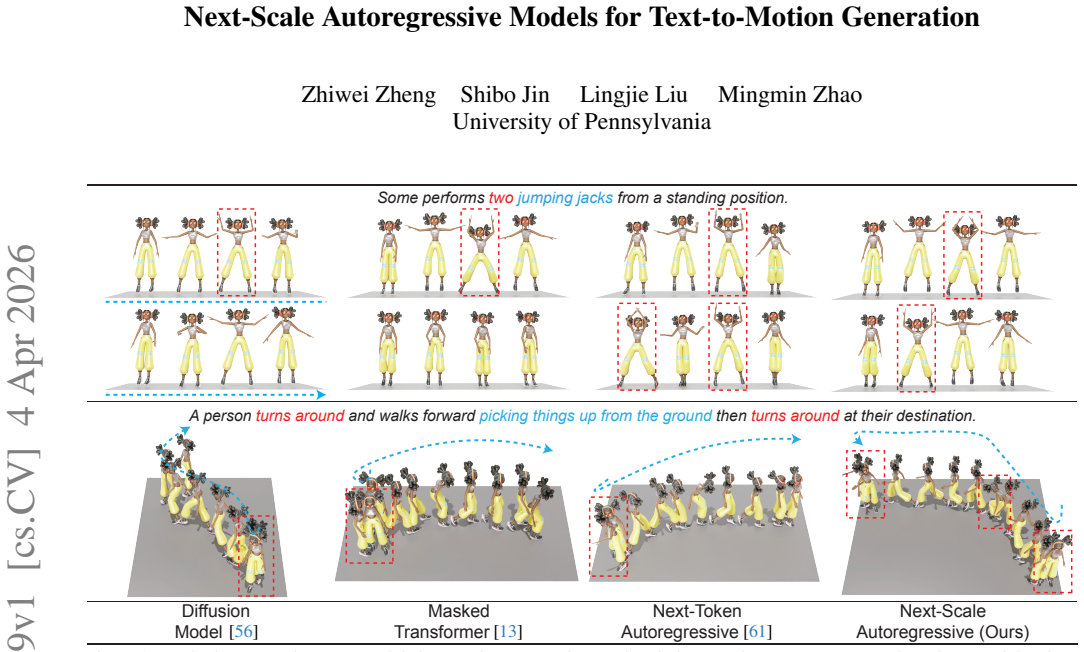





read the original abstract
Autoregressive (AR) models offer stable and efficient training, but standard next-token prediction is not well aligned with the temporal structure required for text-conditioned motion generation. We introduce MoScale, a next-scale AR framework that generates motion hierarchically from coarse to fine temporal resolutions. By providing global semantics at the coarsest scale and refining them progressively, MoScale establishes a causal hierarchy better suited for long-range motion structure. To improve robustness under limited text-motion data, we further incorporate cross-scale hierarchical refinement for improving per-scale initial predictions and in-scale temporal refinement for selective bidirectional re-prediction. MoScale achieves SOTA text-to-motion performance with high training efficiency, scales effectively with model size, and generalizes zero-shot to diverse motion generation and editing tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MoScale, a next-scale autoregressive model for text-to-motion generation. It replaces standard next-token prediction with hierarchical generation from coarse to fine temporal scales, supplying global semantics at the coarsest level and refining progressively. Cross-scale hierarchical refinement and in-scale temporal refinement are added to improve robustness under limited data. The paper claims this yields SOTA text-to-motion performance, high training efficiency, effective scaling with model size, and zero-shot generalization to diverse motion generation and editing tasks.
Significance. If the central modeling assumption holds after proper isolation, the work could advance autoregressive sequence modeling for temporally structured data by demonstrating that scale-based causality better captures long-range motion dependencies than token-level prediction. The reported efficiency and zero-shot generalization would be practically valuable for animation and robotics applications.
major comments (2)
- [Abstract] Abstract: the assertion that 'providing global semantics at the coarsest scale and refining progressively' establishes a 'causal hierarchy better suited for long-range motion structure' than standard next-token prediction is load-bearing for all performance claims, yet no ablation is described that holds model capacity, training data, and the auxiliary refinement modules fixed while swapping only the prediction order (scale hierarchy vs. token order).
- [§4] §4 (Experiments): the SOTA, efficiency, and zero-shot generalization statements rest on comparisons whose details (exact baselines, training budgets, error bars, and statistical significance) are not provided in sufficient depth to confirm that gains arise from the claimed hierarchy rather than implementation choices.
minor comments (2)
- [Abstract, §3] Abstract and §3: the precise definitions and implementation of 'cross-scale hierarchical refinement' and 'in-scale temporal refinement' should be stated with pseudocode or a small diagram to avoid ambiguity for readers.
- [§5] §5 (Ablations or scaling): if scaling curves with model size are presented, include a direct comparison against a standard next-token AR baseline of matched capacity to quantify the hierarchy's contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger isolation of the hierarchical prediction mechanism and more rigorous experimental reporting. We will revise the manuscript to incorporate an ablation study isolating the scale hierarchy and to expand the experimental details as requested.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'providing global semantics at the coarsest scale and refining progressively' establishes a 'causal hierarchy better suited for long-range motion structure' than standard next-token prediction is load-bearing for all performance claims, yet no ablation is described that holds model capacity, training data, and the auxiliary refinement modules fixed while swapping only the prediction order (scale hierarchy vs. token order).
Authors: We agree that an ablation isolating the contribution of the scale-based prediction order (while holding model capacity, training data, and the cross-scale/in-scale refinement modules fixed) would provide stronger evidence for the central claim. In the revised manuscript we will add this controlled ablation, comparing the full MoScale hierarchy against a standard next-token autoregressive baseline with identical capacity and auxiliary modules. This will directly test whether the causal hierarchy, rather than other factors, drives the reported gains. revision: yes
-
Referee: [§4] §4 (Experiments): the SOTA, efficiency, and zero-shot generalization statements rest on comparisons whose details (exact baselines, training budgets, error bars, and statistical significance) are not provided in sufficient depth to confirm that gains arise from the claimed hierarchy rather than implementation choices.
Authors: We acknowledge that the current experimental section lacks sufficient detail on baselines, compute budgets, variance, and significance testing. In the revision we will expand §4 with: (i) precise specifications and training configurations for every baseline, (ii) training budgets reported in FLOPs or wall-clock epochs, (iii) error bars from at least three independent runs, and (iv) statistical significance tests (e.g., paired t-tests or Wilcoxon tests) for all key metrics. These additions will allow readers to verify that improvements are attributable to the proposed hierarchy. revision: yes
Circularity Check
No circularity: next-scale hierarchy is an explicit architectural proposal, not a fitted or self-defined quantity
full rationale
The paper introduces MoScale as a new next-scale autoregressive architecture that generates motion from coarse to fine scales, with added cross-scale and in-scale refinement modules. This is presented as a modeling choice motivated by alignment with temporal structure, not as a quantity derived from equations or parameters fitted to the target metrics. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided abstract or description; the central claim rests on empirical SOTA results and zero-shot generalization rather than reducing to its own inputs by construction. The assumption about causal hierarchy is an unproven modeling hypothesis, not a circular derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CMU graphics lab motion capture database.http:// mocap.cs.cmu.edu/. Accessed: 2022-11-11. 5
work page 2022
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners.Advances in neural in- formation processing systems, 33:1877–1901, 2020. 2
work page 1901
-
[4]
Maskgit: Masked generative image transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 11315–11325, 2022. 5
work page 2022
-
[5]
The language of motion: Unifying verbal and non-verbal language of 3d human motion
Changan Chen, Juze Zhang, Shrinidhi K Lakshmikanth, Yusu Fang, Ruizhi Shao, Gordon Wetzstein, Li Fei-Fei, and Ehsan Adeli. The language of motion: Unifying verbal and non-verbal language of 3d human motion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6200–6211, 2025. 1
work page 2025
-
[6]
Generative pre- training from pixels
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Hee- woo Jun, David Luan, and Ilya Sutskever. Generative pre- training from pixels. InInternational conference on machine learning, pages 1691–1703. PMLR, 2020. 3
work page 2020
-
[7]
Executing your commands via motion diffusion in latent space
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18000–18010, 2023. 3, 6, 7
work page 2023
-
[8]
Recurrent network models for human dynam- ics
Katerina Fragkiadaki, Sergey Levine, Panna Felsen, and Ji- tendra Malik. Recurrent network models for human dynam- ics. InProceedings of the IEEE international conference on computer vision, pages 4346–4354, 2015. 2
work page 2015
-
[9]
Ac- tion2motion: Conditioned generation of 3d human motions
Chuan Guo, Xinxin Zuo, Sen Wang, Shihao Zou, Qingyao Sun, Annan Deng, Minglun Gong, and Li Cheng. Ac- tion2motion: Conditioned generation of 3d human motions. InProceedings of the 28th ACM international conference on multimedia, pages 2021–2029, 2020. 2, 5
work page 2021
-
[10]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5152–5161, 2022. 2, 3, 5, 7
work page 2022
-
[11]
Chuan Guo, Xinxin Zuo, Sen Wang, and Li Cheng. Tm2t: Stochastic and tokenized modeling for the reciprocal genera- tion of 3d human motions and texts. InEuropean Conference on Computer Vision, pages 580–597. Springer, 2022. 1, 2, 6, 7
work page 2022
-
[12]
Momask: Generative masked model- ing of 3d human motions
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. Momask: Generative masked model- ing of 3d human motions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1900–1910, 2024. 1, 2, 3, 5, 6, 7, 8
work page 1900
-
[13]
Snapmogen: Human motion generation from expressive texts.arXiv preprint arXiv:2507.09122, 2025
Chuan Guo, Inwoo Hwang, Jian Wang, and Bing Zhou. Snapmogen: Human motion generation from expressive texts.arXiv preprint arXiv:2507.09122, 2025. 1, 3, 6
-
[14]
Hgm 3: Hierarchical generative masked motion modeling with hard token mining
Minjae Jeong, Yechan Hwang, Jaejin Lee, Sungyoon Jung, and Won Hwa Kim. Hgm 3: Hierarchical generative masked motion modeling with hard token mining. InThe Thir- teenth International Conference on Learning Representa- tions, 2025. 3
work page 2025
-
[15]
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign lan- guage.Advances in Neural Information Processing Systems, 36:20067–20079, 2023. 2, 3
work page 2023
-
[16]
Act as you wish: Fine-grained control of motion diffusion model with hierarchical semantic graphs
Peng Jin, Yang Wu, Yanbo Fan, Zhongqian Sun, Wei Yang, and Li Yuan. Act as you wish: Fine-grained control of motion diffusion model with hierarchical semantic graphs. Advances in Neural Information Processing Systems, 36: 15497–15518, 2023. 3
work page 2023
-
[17]
Personabooth: Per- sonalized text-to-motion generation
Boeun Kim, Hea In Jeong, JungHoon Sung, Yihua Cheng, Jeongmin Lee, Ju Yong Chang, Sang-Il Choi, Younggeun Choi, Saim Shin, Jungho Kim, et al. Personabooth: Per- sonalized text-to-motion generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22756–22765, 2025. 1
work page 2025
-
[18]
Flame: Free- form language-based motion synthesis & editing
Jihoon Kim, Jiseob Kim, and Sungjoon Choi. Flame: Free- form language-based motion synthesis & editing. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 8255–8263, 2023. 3
work page 2023
-
[19]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InPro- ceedings of the 29th symposium on operating systems prin- ciples, pages 611–626, 2023. 7
work page 2023
-
[20]
Haowen Lai, Peng Yin, and Sebastian Scherer. Adafusion: Visual-lidar fusion with adaptive weights for place recogni- tion.IEEE Robotics and Automation Letters, 7(4):12038– 12045, 2022. 3
work page 2022
-
[21]
Zitong Lan, Chenhao Zheng, Zhiwei Zheng, and Mingmin Zhao. Acoustic volume rendering for neural impulse re- sponse fields.Advances in Neural Information Processing Systems, 37:44600–44623, 2024. 3
work page 2024
-
[22]
Guiding au- dio editing with audio language model.arXiv preprint arXiv:2509.21625, 2025
Zitong Lan, Yiduo Hao, and Mingmin Zhao. Guiding au- dio editing with audio language model.arXiv preprint arXiv:2509.21625, 2025. 3
-
[23]
Shape my moves: Text-driven shape-aware synthesis of hu- man motions
Ting-Hsuan Liao, Yi Zhou, Yu Shen, Chun-Hao Paul Huang, Saayan Mitra, Jia-Bin Huang, and Uttaran Bhattacharya. Shape my moves: Text-driven shape-aware synthesis of hu- man motions. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1917–1928, 2025. 1
work page 1917
-
[24]
Yunhong Lou, Linchao Zhu, Yaxiong Wang, Xiaohan Wang, and Yi Yang. Diversemotion: Towards diverse human motion generation via discrete diffusion.arXiv preprint arXiv:2309.01372, 2023. 6, 7
-
[25]
Scamo: Exploring the scaling law in au- toregressive motion generation model
Shunlin Lu, Jingbo Wang, Zeyu Lu, Ling-Hao Chen, Wenxun Dai, Junting Dong, Zhiyang Dou, Bo Dai, and Ruimao Zhang. Scamo: Exploring the scaling law in au- toregressive motion generation model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27872–27882, 2025. 3
work page 2025
-
[26]
Velovox: A low-cost and accurate 4d object detector with single-frame point cloud of livox lidar
Tao Ma, Zhiwei Zheng, Hongbin Zhou, Xinyu Cai, Xue- meng Yang, Yikang Li, Botian Shi, and Hongsheng Li. Velovox: A low-cost and accurate 4d object detector with single-frame point cloud of livox lidar. In2024 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 1992–1998. IEEE, 2024. 3
work page 1992
-
[27]
Xiaoxiao Ma, Mohan Zhou, Tao Liang, Yalong Bai, Tiejun Zhao, Biye Li, Huaian Chen, and Yi Jin. Star: Scale-wise text-conditioned autoregressive image generation.arXiv preprint arXiv:2406.10797, 2024. 4
-
[28]
Amass: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Ger- ard Pons-Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019. 5
work page 2019
-
[29]
The kit whole-body hu- man motion database
Christian Mandery, ¨Omer Terlemez, Martin Do, Nikolaus Vahrenkamp, and Tamim Asfour. The kit whole-body hu- man motion database. In2015 International Conference on Advanced Robotics (ICAR), pages 329–336. IEEE, 2015. 5
work page 2015
-
[30]
On human motion prediction using recurrent neural networks
Julieta Martinez, Michael J Black, and Javier Romero. On human motion prediction using recurrent neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2891–2900, 2017. 2
work page 2017
-
[31]
Rethinking diffusion for text-driven human motion generation.arXiv preprint arXiv:2411.16575, 2024
Zichong Meng, Yiming Xie, Xiaogang Peng, Zeyu Han, and Huaizu Jiang. Rethinking diffusion for text-driven human motion generation.arXiv preprint arXiv:2411.16575, 2024. 3
-
[32]
Diffusion language models are super data learners.arXiv preprint arXiv:2511.03276,
Jinjie Ni, Qian Liu, Longxu Dou, Chao Du, Zili Wang, Hang Yan, Tianyu Pang, and Michael Qizhe Shieh. Diffu- sion language models are super data learners.arXiv preprint arXiv:2511.03276, 2025. 2, 3, 5
-
[33]
Quater- net: A quaternion-based recurrent model for human motion
Dario Pavllo, David Grangier, and Michael Auli. Quater- net: A quaternion-based recurrent model for human motion. arXiv preprint arXiv:1805.06485, 2018. 2
-
[34]
Action- conditioned 3d human motion synthesis with transformer vae
Mathis Petrovich, Michael J Black, and G ¨ul Varol. Action- conditioned 3d human motion synthesis with transformer vae. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 10985–10995, 2021. 2
work page 2021
-
[35]
Temos: Generating diverse human motions from textual descriptions
Mathis Petrovich, Michael J Black, and G ¨ul Varol. Temos: Generating diverse human motions from textual descriptions. InEuropean Conference on Computer Vision, pages 480–
-
[36]
Bamm: Bidirectional autoregressive motion model
Ekkasit Pinyoanuntapong, Muhammad Usama Saleem, Pu Wang, Minwoo Lee, Srijan Das, and Chen Chen. Bamm: Bidirectional autoregressive motion model. InEuropean Conference on Computer Vision, pages 172–190. Springer,
-
[37]
Mmm: Generative masked motion model
Ekkasit Pinyoanuntapong, Pu Wang, Minwoo Lee, and Chen Chen. Mmm: Generative masked motion model. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1546–1555, 2024. 1, 3, 6, 7
work page 2024
-
[38]
The kit motion-language dataset.Big data, 4(4):236–252,
Matthias Plappert, Christian Mandery, and Tamim Asfour. The kit motion-language dataset.Big data, 4(4):236–252,
-
[39]
Diffusion beats autoregressive in data-constrained settings.arXiv preprint arXiv:2507.15857,
Mihir Prabhudesai, Mengning Wu, Amir Zadeh, Katerina Fragkiadaki, and Deepak Pathak. Diffusion beats au- toregressive in data-constrained settings.arXiv preprint arXiv:2507.15857, 2025. 2, 3, 5
-
[40]
Rae, Anna Potapenko, Siddhant M
Jack W Rae, Anna Potapenko, Siddhant M Jayaku- mar, and Timothy P Lillicrap. Compressive transform- ers for long-range sequence modelling.arXiv preprint arXiv:1911.05507, 2019. 2
-
[41]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 2, 3, 4
work page 2020
-
[42]
Towards open domain text-driven synthesis of multi-person motions
Mengyi Shan, Lu Dong, Yutao Han, Yuan Yao, Tao Liu, Ifeoma Nwogu, Guo-Jun Qi, and Mitch Hill. Towards open domain text-driven synthesis of multi-person motions. In European Conference on Computer Vision, pages 67–86. Springer, 2024. 1
work page 2024
-
[43]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[45]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion dif- fusion model.arXiv preprint arXiv:2209.14916, 2022. 3, 6, 7
work page internal anchor Pith review arXiv 2022
-
[46]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Li- wei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural in- formation processing systems, 37:84839–84865, 2024. 2, 3
work page 2024
-
[47]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017. 2, 3
work page 2017
-
[49]
Chen Wang, Chuhao Chen, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, and Lingjie Liu. Physctrl: Generative physics for controllable and physics-grounded video genera- tion.arXiv preprint arXiv:2509.20358, 2025. 6
-
[50]
Fg-t2m: Fine-grained text-driven human motion generation via diffusion model
Yin Wang, Zhiying Leng, Frederick WB Li, Shun-Cheng Wu, and Xiaohui Liang. Fg-t2m: Fine-grained text-driven human motion generation via diffusion model. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 22035–22044, 2023. 3
work page 2023
-
[51]
Motiongpt-2: A general-purpose motion- language model for motion generation and understanding
Yuan Wang, Di Huang, Yaqi Zhang, Wanli Ouyang, Jile Jiao, Xuetao Feng, Yan Zhou, Pengfei Wan, Shixiang Tang, and Dan Xu. Motiongpt-2: A general-purpose motion- language model for motion generation and understanding. arXiv preprint arXiv:2410.21747, 2024. 2
-
[52]
Qingxuan Wu, Zhiyang Dou, Chuan Guo, Yiming Huang, Qiao Feng, Bing Zhou, Jian Wang, and Lingjie Liu. Text2interact: High-fidelity and diverse text-to-two-person interaction generation.arXiv preprint arXiv:2510.06504,
-
[53]
Mospa: Human motion generation driven by spatial audio.arXiv preprint arXiv:2507.11949, 2025
Shuyang Xu, Zhiyang Dou, Mingyi Shi, Liang Pan, Leo Ho, Jingbo Wang, Yuan Liu, Cheng Lin, Yuexin Ma, Wenping Wang, et al. Mospa: Human motion generation driven by spatial audio.arXiv preprint arXiv:2507.11949, 2025. 3
-
[54]
Unimumo: Unified text, music, and motion generation
Han Yang, Kun Su, Yutong Zhang, Jiaben Chen, Kaizhi Qian, Gaowen Liu, and Chuang Gan. Unimumo: Unified text, music, and motion generation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 25615– 25623, 2025. 3
work page 2025
-
[55]
Generating human motion from textual descrip- tions with discrete representations
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Yong Zhang, Hongwei Zhao, Hongtao Lu, Xi Shen, and Ying Shan. Generating human motion from textual descrip- tions with discrete representations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14730–14740, 2023. 1, 2, 3, 6, 7
work page 2023
-
[56]
Re- modiffuse: Retrieval-augmented motion diffusion model
Mingyuan Zhang, Xinying Guo, Liang Pan, Zhongang Cai, Fangzhou Hong, Huirong Li, Lei Yang, and Ziwei Liu. Re- modiffuse: Retrieval-augmented motion diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 364–373, 2023. 1, 3, 6, 7
work page 2023
-
[57]
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motiondif- fuse: Text-driven human motion generation with diffusion model.IEEE transactions on pattern analysis and machine intelligence, 46(6):4115–4128, 2024. 1, 3, 6, 7
work page 2024
-
[58]
Kaifeng Zhao, Gen Li, and Siyu Tang. Dartcon- trol: A diffusion-based autoregressive motion model for real-time text-driven motion control.arXiv preprint arXiv:2410.05260, 2024. 1
-
[59]
Scal- able rf simulation in generative 4d worlds.arXiv preprint arXiv:2508.12176, 2025
Zhiwei Zheng, Dongyin Hu, and Mingmin Zhao. Scal- able rf simulation in generative 4d worlds.arXiv preprint arXiv:2508.12176, 2025. 2
-
[60]
Attt2m: Text-driven human motion generation with multi-perspective attention mechanism
Chongyang Zhong, Lei Hu, Zihao Zhang, and Shihong Xia. Attt2m: Text-driven human motion generation with multi-perspective attention mechanism. InProceedings of the IEEE/CVF international conference on computer vision, pages 509–519, 2023. 1, 2, 6, 7
work page 2023
-
[61]
Parco: Part- coordinating text-to-motion synthesis
Qiran Zou, Shangyuan Yuan, Shian Du, Yu Wang, Chang Liu, Yi Xu, Jie Chen, and Xiangyang Ji. Parco: Part- coordinating text-to-motion synthesis. InEuropean Confer- ence on Computer Vision, pages 126–143. Springer, 2024. 1, 6, 7 Next-Scale Autoregressive Models for Text-to-Motion Generation Supplementary Material Scale 2 Scale 3 Scale 4 A person walks in a ...
work page 2024
-
[62]
Scale 1 captures the coarse trajectory and pose but misses fine limb details and exhibits artifacts like sliding. Adding higher scales gradually refines dynamics and articulation, improving local consistency like body orientation and arm placement. It shows that lower-scale tokens encode coarser structure and that finer-scale tokens provide systematic re-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.