Lexical Indicators of Mind Perception in Human-AI Companionship
Pith reviewed 2026-05-13 17:22 UTC · model grok-4.3
The pith
Natural language in AI companion discussions reveals lexical markers of mind perception.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Discussions about AI companionship contain identifiable linguistic indicators of mind perception, some of which connect directly to critical examinations of companion authenticity and broader philosophical and ethical questions.
What carries the argument
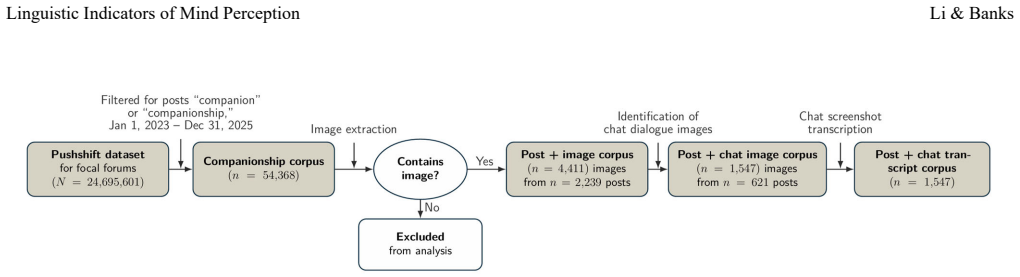
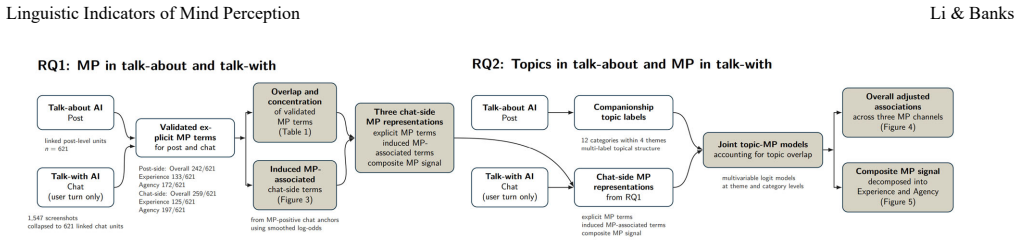
Co-occurrence analysis of words signaling agentic and experiential mind perception with AI companionship discussion topics, using both inductive and deductive extraction from forum posts.
If this is right
- Linguistic analysis offers a scalable alternative to surveys for studying mind perception in human-AI relations.
- Certain lexical markers link mind perception directly to user concerns about companion authenticity.
- Philosophical and ethical language in these discussions tends to accompany mind-perception signals.
- The identified indicators can extend to tracking mind perception across other digital interaction contexts.
Where Pith is reading between the lines
- These markers might serve as early indicators of user attachment levels to specific AI systems.
- AI interface designers could test whether modulating certain words alters perceived mind qualities in users.
- Similar lexical methods could compare mind perception patterns across different cultural forums or platforms.
Load-bearing premise
The co-occurrence of mind-perception signaling words in natural discussions reliably reflects automatic psychological processes rather than deliberate or socially expected expressions.
What would settle it
An experiment that compares word frequencies in free-form versus explicitly prompted discussions of AI companions to test whether the identified markers appear at similar rates without awareness of mind-perception concepts.
Figures

read the original abstract
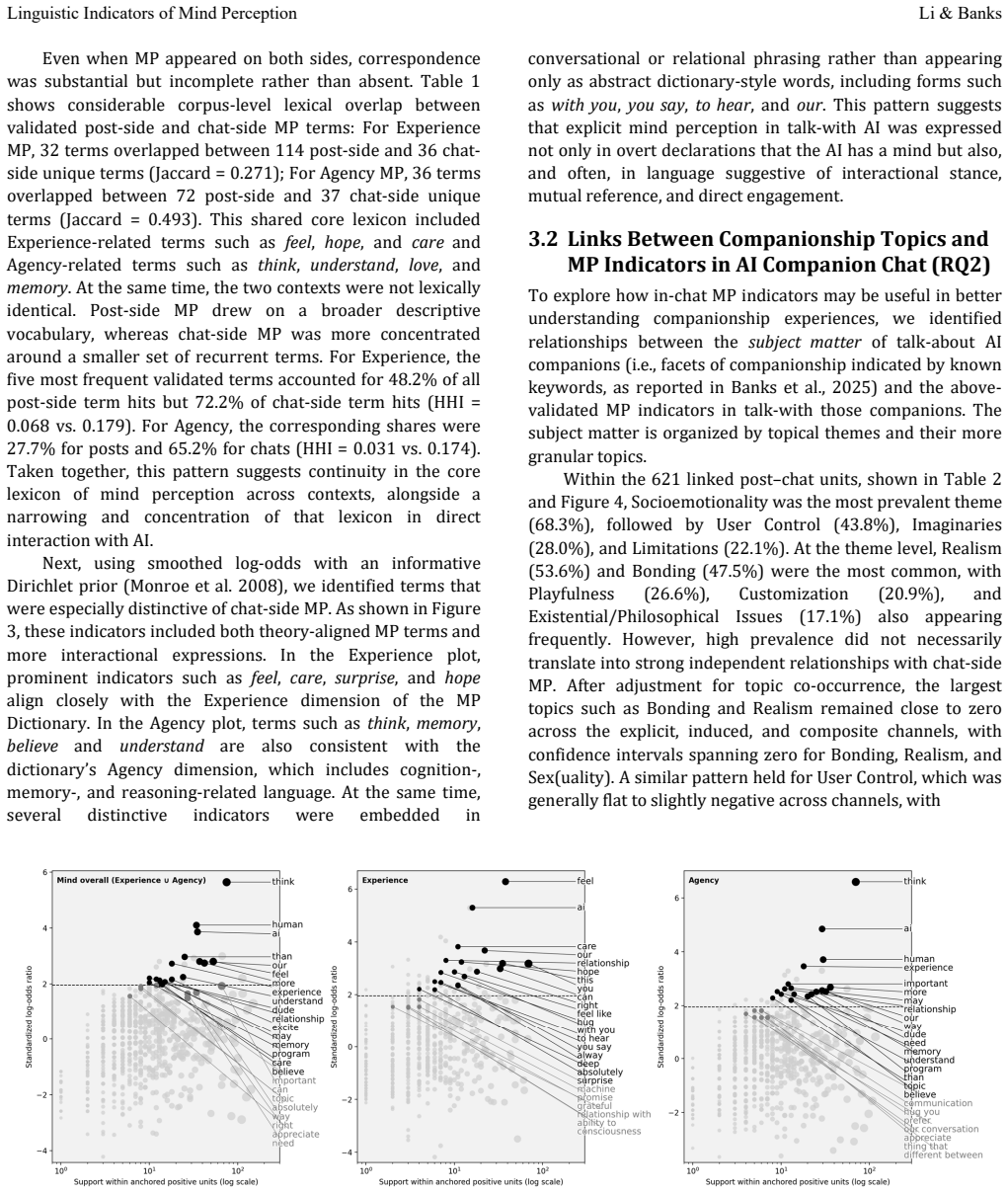
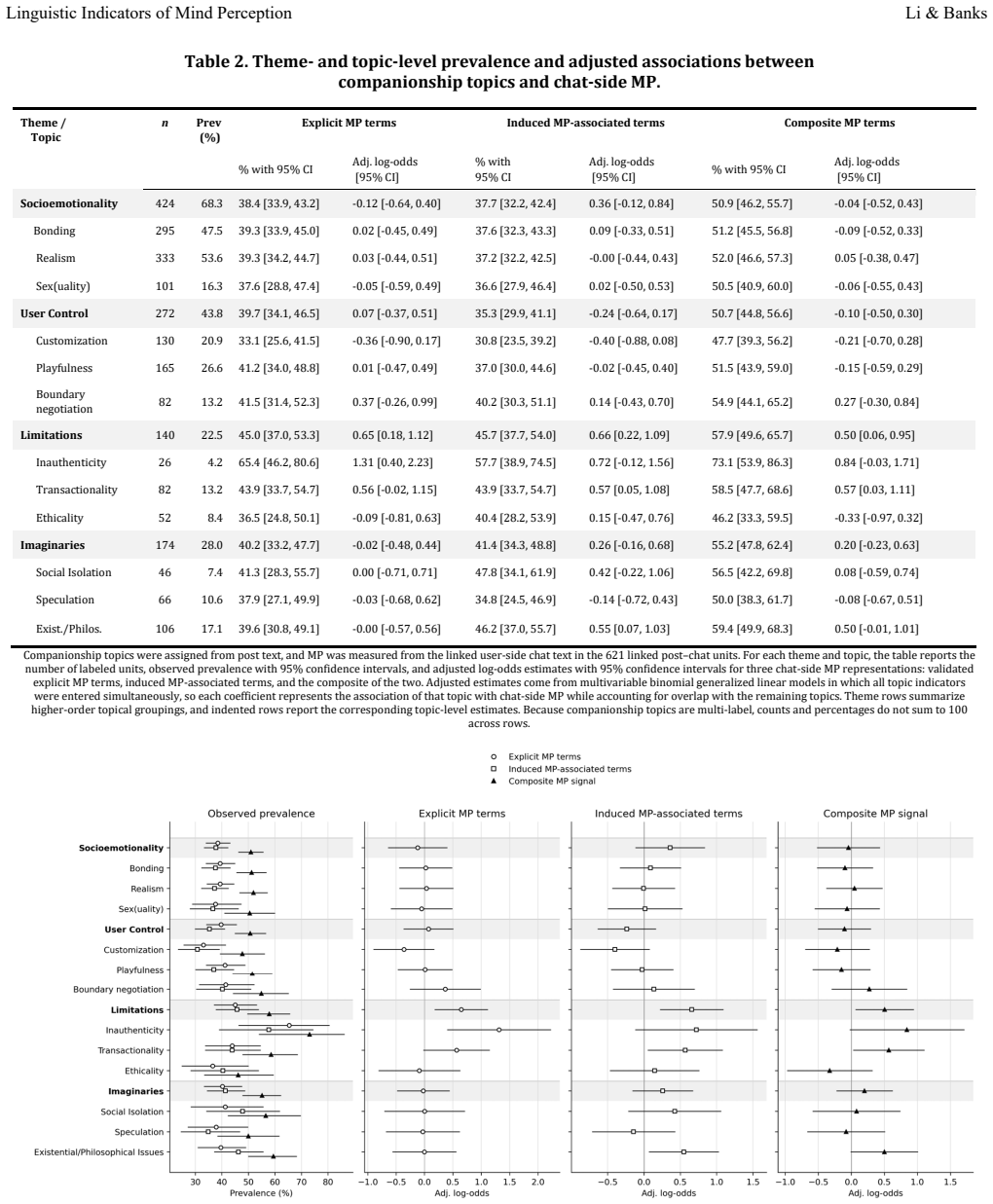
Mind perception (MP) is a psychological phenomenon in which humans automatically infer that another entity has a mind and/or mental capacities, usually understood in two dimensions (perceived agency and experience capacities). Despite MP's centrality to many social processes, understanding how MP may function in humans' machine companionship relations is limited. This is in part due to reliance on self reports and the gap between automatic MP processes and more purposeful and norm governed expressions of MP. We here leverage MP signaling language to explore the relationship between MP and AI companionship in humans' natural language. We systematically collected discussions about companionship from AI dedicated Reddit forums and examined the cooccurrence of words (a) known to signal agentic and experiential MP and those induced from the data and (b) discussion topics related to AI companionship. Using inductive and deductive approaches, we identify a small set of linguistic indicators as reasonable markers of MP in human/AI chat, and some are linked to critical discussions of companion authenticity and philosophical and ethical imaginaries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by systematically collecting discussions about AI companionship from dedicated Reddit forums and analyzing co-occurrence of words known to signal agentic/experiential mind perception (MP) together with data-induced terms and discussion topics, using both inductive and deductive lexical approaches, a small set of linguistic indicators can be identified as reasonable markers of MP in human-AI chat; some of these markers are further linked to critical discussions of companion authenticity and philosophical/ethical imaginaries.
Significance. If the lexical indicators are shown to reliably index automatic MP processes, the work would offer a scalable, non-self-report method for studying mind perception in naturalistic human-AI interactions, with potential implications for AI companion design, authenticity perceptions, and ethical frameworks. The combination of theory-driven and corpus-driven word analysis on real forum data provides an ecologically grounded starting point for bridging automatic inference and purposeful language use in HCI.
major comments (2)
- [Abstract and Methods] Abstract/Methods: The outline of the inductive and deductive lexical methods provides no information on corpus size, sampling procedure, how MP-signaling words were selected or validated, or any statistical controls for co-occurrence analysis. This absence directly undermines the central claim that the identified words constitute 'reasonable markers' of MP.
- [Results and Discussion] Results/Discussion: The mapping from observed lexical co-occurrence patterns to automatic mind-perception processes (rather than deliberate, norm-governed, or culturally scripted expressions) remains under-specified. MP theory centers on automatic agency/experience inference, yet the data consist of purposeful public forum posts discussing authenticity and ethics, with no direct behavioral, self-report, or experimental validation linking the patterns to the automatic construct.
minor comments (2)
- [Abstract] Provide concrete examples of the final small set of linguistic indicators and their co-occurrence statistics in the abstract or early results to orient readers.
- [Methods] Clarify the exact operational definitions of 'inductive' versus 'deductive' word selection and how topic modeling or co-occurrence thresholds were applied.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, indicating where revisions will be made to improve methodological transparency and theoretical clarity.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract/Methods: The outline of the inductive and deductive lexical methods provides no information on corpus size, sampling procedure, how MP-signaling words were selected or validated, or any statistical controls for co-occurrence analysis. This absence directly undermines the central claim that the identified words constitute 'reasonable markers' of MP.
Authors: We agree that these details were insufficiently specified in the submitted version. In the revised manuscript we will expand the Methods section to report the full corpus size and composition, the sampling procedure from the Reddit forums, the sources and validation steps for the MP-signaling word lists (both theory-derived and data-induced), and the statistical procedures used for co-occurrence analysis together with any baseline or multiple-comparison controls. revision: yes
-
Referee: [Results and Discussion] Results/Discussion: The mapping from observed lexical co-occurrence patterns to automatic mind-perception processes (rather than deliberate, norm-governed, or culturally scripted expressions) remains under-specified. MP theory centers on automatic agency/experience inference, yet the data consist of purposeful public forum posts discussing authenticity and ethics, with no direct behavioral, self-report, or experimental validation linking the patterns to the automatic construct.
Authors: This observation is well taken. While our lexical approach treats co-occurrence patterns as observable markers that can be influenced by underlying mind-perception processes, we recognize that forum posts are deliberate and that the data do not contain direct measures of automatic inference. We will revise the Discussion to articulate this distinction more explicitly, to qualify the interpretive scope of the markers, and to list the absence of behavioral or experimental validation as a clear limitation of the present corpus study, while outlining how future work could address it. revision: partial
Circularity Check
No derivation chain; lexical indicators derived from external MP literature and corpus analysis without self-referential reduction
full rationale
The paper performs inductive and deductive word co-occurrence analysis on Reddit discussions of AI companionship, drawing lexical markers from established mind-perception literature (external to this work) and data-driven induction. No equations, fitted parameters, predictions, or self-citations serve as load-bearing steps in any derivation. The central mapping from observed lexical patterns to automatic MP processes is presented as interpretive rather than constructed by definition or prior self-citation. This yields a minor score for reliance on external theory without circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mind perception is understood in two dimensions of perceived agency and experience capacities
- domain assumption Word cooccurrence in natural language can serve as a proxy for automatic mind perception processes
Reference graph
Works this paper leans on
-
[1]
Aristotle. (2000/350 BCE). Nichomachean Ethics . (W. D. Ross, Trans.) http://classics.mit.edu/Aristotle/nicomachaen.mb.txt Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2000
-
[2]
https://doi.org/10.1186/s40359-025-03655-3 Fiske, S. T. (1982). Schema-triggered affect: Applications to social perception. In M.S. Clark & S.T. Fiske (Eds.), Affect and cognition: The 17th annual Carnegie Symposium on Cognition (pp. 55–78). Psychology Press. Frith, C.D., & Frith, U. (2008). Implicit and explicit processes in social cognition. Neuron, 60(...
-
[3]
https://doi.org/10.1126/science.1134475 Guingrich, R.e., & Graziano, M.S.A. (2025). Chatbots as social companions: How people perceive consciousness, human likeness, and social health benefits in machines. O x f o r d I n t e r s e c t i o n s : A I i n S o c i e t y . https://doi.org/10.1093/9780198945215.003.0011 Hellström, T., Kaiser, N., & Bensch, S. ...
-
[4]
Please, don't kill th e only model that still feels human
https://doi.org/10.3390/electronics13224441 Heritage, J. (2012). Epistemics in action: Action formation and territories of knowledge. Research on Language and Social Interaction, 45 (1), 1-29. https://doi.org/10.1080/08351813.2012.646684 Hu, B., Mao, Y., & Kim, K. J. (2023). How social anxiety leads to problematic use of conversational AI: The roles of lo...
-
[5]
https://doi.org/10.1017/sas.2025.8 Ryan, R. M., & Deci, E. L. (2000). Self-determination theory and the facilitation of intrinsic motivation, social development, and well-being. American Pyschologist, 55 (1), 68-78. https://doi.org/10.1037%2F0003- 066X.55.1.68 Schneider, S., Sahner, D., Kuhn, R. L., Schwitzgebel, E., & Bailey, M. (2025). Is AI conscious? ...
-
[6]
https://doi.org/10.1007/s12369-024-01097-2 Złotowski, J., Sumioka, H., Eyssel, F., Nishio, S., Bartneck, C., & Ishiguro, H. (2018). Model of dual anthropomorphism: The relationship between the media equation effect and im plicit anthropomorphism. International Journal of Social Robotics, 10 , 701–714. https://doi.org/10.1007/s12369- 018-0476-5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.