Recognition: 2 theorem links
· Lean TheoremHow Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings
Pith reviewed 2026-05-10 20:26 UTC · model grok-4.3
The pith
The benefits of reusable skills for LLM agents fade in realistic settings where agents must retrieve them from large collections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
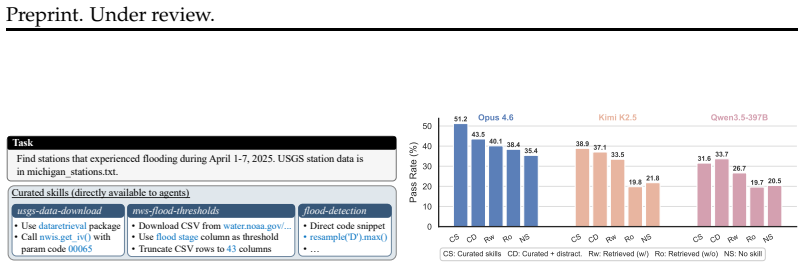
When agents must retrieve skills from a large real-world collection rather than receiving hand-curated matches, performance improvements over a no-skill baseline shrink consistently and approach zero in the most challenging realistic scenarios, though query-specific refinement of the retrieved skills can substantially restore those gains.
What carries the argument
A tiered benchmarking setup that escalates realism by replacing hand-provided task-specific skills with retrieval from a 34k real-world skill collection, paired with query-specific and query-agnostic refinement procedures.
If this is right
- Query-specific refinement after retrieval is necessary to keep skills useful once agents must search large collections themselves.
- Adding skills without accompanying retrieval and refinement components is unlikely to raise pass rates on open-ended agent tasks.
- The same retrieval-plus-refinement pipeline improves results on other benchmarks such as Terminal-Bench 2.0.
- The observed fragility of skill benefits holds across multiple different LLMs.
Where Pith is reading between the lines
- Agent frameworks should invest more in retrieval accuracy and on-the-fly editing than in simply enlarging static skill libraries.
- Standard agent benchmarks should adopt retrieval from noisy, large-scale skill sets as a required test rather than treating skills as always perfectly matched.
- If refinement remains effective at scale, it could allow agents to use ever-larger skill collections without proportional drops in reliability.
Load-bearing premise
The collection of 34,000 real-world skills and the retrieval methods tested in the experiments match the skill distributions and retrieval challenges that arise for LLM agents in actual open-ended deployments.
What would settle it
Measure whether the same performance degradation occurs when the same tasks are run inside a live deployed agent system that draws from a much larger or differently distributed live skill library.
Figures


read the original abstract
Agent skills, which are reusable, domain-specific knowledge artifacts, have become a popular mechanism for extending LLM-based agents, yet formally benchmarking skill usage performance remains scarce. Existing skill benchmarking efforts focus on overly idealized conditions, where LLMs are directly provided with hand-crafted, narrowly-tailored task-specific skills for each task, whereas in many realistic settings, the LLM agent may have to search for and select relevant skills on its own, and even the closest matching skills may not be well-tailored for the task. In this paper, we conduct the first comprehensive study of skill utility under progressively challenging realistic settings, where agents must retrieve skills from a large collection of 34k real-world skills and may not have access to any hand-curated skills. Our findings reveal that the benefits of skills are fragile: performance gains degrade consistently as settings become more realistic, with pass rates approaching no-skill baselines in the most challenging scenarios. To narrow this gap, we study skill refinement strategies, including query-specific and query-agnostic approaches, and we show that query-specific refinement substantially recovers lost performance when the initial skills are of reasonable relevance and quality. We further demonstrate the generality of retrieval and refinement on Terminal-Bench 2.0, where they improve the pass rate of Claude Opus 4.6 from 57.7% to 65.5%. Our results, consistent across multiple models, highlight both the promise and the current limitations of skills for LLM-based agents. Our code is available at https://github.com/UCSB-NLP-Chang/Skill-Usage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts the first comprehensive empirical study of LLM agent skill usage under progressively realistic conditions. It claims that while hand-curated task-specific skills yield clear gains over no-skill baselines in idealized settings, these benefits degrade consistently when agents must retrieve from a 34k real-world skill corpus without oracle guidance, with pass rates approaching no-skill levels in the hardest scenarios. Query-specific refinement recovers much of the lost performance when initial retrieval yields reasonable relevance, and the approach generalizes to Terminal-Bench 2.0 (improving Claude Opus 4.6 from 57.7% to 65.5%). Results hold across multiple models, with code released.
Significance. If the core empirical pattern holds, the work is significant for highlighting practical limitations of current skill-augmented agents and for demonstrating a concrete refinement strategy that narrows the gap. The open code and Terminal-Bench 2.0 results provide reproducible evidence that could inform agent design beyond idealized benchmarks.
major comments (2)
- [Methods (skill corpus and retrieval description)] The central claim that skill benefits are 'fragile' and degrade to no-skill baselines in realistic settings is load-bearing on the fidelity of the 34k skill corpus and retrieval procedure. The manuscript provides no quantitative diagnostics (e.g., retrieval recall@K, average relevance scores, or comparison against real agent interaction logs) to confirm that the simulated retrieval approximates how competent agents would select skills in open-ended deployments. Without these, the degradation could be an artifact of low-quality retrieval rather than an intrinsic limitation of skills.
- [Refinement strategies section] The refinement experiments show query-specific refinement substantially recovers performance, but the manuscript does not report how relevance thresholds or quality filters are applied, nor does it include ablations on the refinement prompt or model used for rewriting. This makes it difficult to assess whether the recovery is robust or tied to specific implementation choices.
minor comments (3)
- [Abstract and Introduction] The abstract and introduction could more explicitly define the four progressive settings (idealized vs. realistic) with a small table or diagram for clarity.
- [Results] Table or figure reporting per-model pass rates should include confidence intervals or statistical significance tests against the no-skill baseline.
- [Terminal-Bench 2.0 evaluation] The Terminal-Bench 2.0 experiment is a valuable generalization check, but the manuscript should state whether the same 34k corpus and retrieval method were used or if any adaptation occurred.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important gaps in the presentation of our methods and experiments. We address each major comment below and will revise the manuscript to incorporate the suggested improvements where feasible.
read point-by-point responses
-
Referee: The central claim that skill benefits are 'fragile' and degrade to no-skill baselines in realistic settings is load-bearing on the fidelity of the 34k skill corpus and retrieval procedure. The manuscript provides no quantitative diagnostics (e.g., retrieval recall@K, average relevance scores, or comparison against real agent interaction logs) to confirm that the simulated retrieval approximates how competent agents would select skills in open-ended deployments. Without these, the degradation could be an artifact of low-quality retrieval rather than an intrinsic limitation of skills.
Authors: We agree that additional quantitative diagnostics would strengthen the central claim. In the revised manuscript we will report retrieval recall@K and average relevance scores for the skills retrieved on the benchmark tasks, computed with the same embedding-based procedure used in the original experiments. We will also expand the description of the 34k skill corpus construction to clarify its grounding in real-world sources. However, we do not have access to proprietary real-world agent interaction logs, so a direct comparison is not possible; we will instead add an explicit discussion of this limitation and how the public corpus approximates open-ended use. revision: yes
-
Referee: The refinement experiments show query-specific refinement substantially recovers performance, but the manuscript does not report how relevance thresholds or quality filters are applied, nor does it include ablations on the refinement prompt or model used for rewriting. This makes it difficult to assess whether the recovery is robust or tied to specific implementation choices.
Authors: We acknowledge that the refinement section lacks these implementation details and ablations. In the revision we will explicitly state the relevance thresholds and any quality filters applied when selecting or refining skills. We will also add ablations that vary the refinement prompt and the LLM used for rewriting (e.g., comparing the original model against an alternative). These additions will allow readers to evaluate the robustness of the reported performance recovery. revision: yes
- Direct quantitative comparison against real agent interaction logs from open-ended deployments, as no such public logs are available for the benchmarks used.
Circularity Check
No circularity: purely empirical benchmarking with direct baseline comparisons
full rationale
The paper performs an empirical evaluation of LLM agent skill usage across progressively realistic settings using a fixed 34k skill corpus and retrieval procedures. All reported results are direct pass-rate measurements against no-skill baselines; no equations, fitted parameters, predictions, or self-citations are used to derive the central claims. The performance degradation finding follows immediately from the experimental measurements without any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retrieved skills from the 34k collection can be meaningfully evaluated for relevance and utility on the chosen benchmarks
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
agents must retrieve skills from a large collection of 34k real-world skills... performance gains degrade consistently as settings become more realistic
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
query-specific refinement substantially recovers lost performance when the initial skills are of reasonable relevance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
MMSkills: Towards Multimodal Skills for General Visual Agents
MMSkills creates compact multimodal skill packages from trajectories and uses a branch-loaded agent to improve visual decision-making on GUI and game benchmarks.
-
MMSkills: Towards Multimodal Skills for General Visual Agents
MMSkills turns public interaction trajectories into compact multimodal skill packages that visual agents can consult at runtime to improve decision-making on benchmarks.
-
Evidence Over Plans: Online Trajectory Verification for Skill Distillation
PDI-guided distillation from environment-verified trajectories yields skills that surpass no-skill baselines and human-written skills across 86 tasks with far lower inference cost.
-
SkillLens: Adaptive Multi-Granularity Skill Reuse for Cost-Efficient LLM Agents
SkillLens organizes skills into policies-strategies-procedures-primitives layers, retrieves via degree-corrected random walk, and uses a verifier for local adaptation, yielding up to 6.31 pp gains on MuLocbench and ra...
Reference graph
Works this paper leans on
-
[1]
Read the task description in /root/task_instruction.md to understand what the task requires
-
[2]
Each subdirectory contains a skill with a SKILL.md and possibly supporting files (scripts, references, etc.)
Read ALL the retrieved skills in /root/retrieved_skills/. Each subdirectory contains a skill with a SKILL.md and possibly supporting files (scripts, references, etc.). ### Phase 2: Attempt the task using the retrieved skills
-
[3]
This is the most important step
Try to solve the task while actively consulting the retrieved skills. This is the most important step. As you work through the task: − Refer to the retrieved skills for guidance, code snippets, API patterns, and domain knowledge. − When a skill suggests an approach, try it. Note whether it works, partially works, or is wrong. − When you get stuck, check i...
-
[4]
Under review
Based on your experience attempting the task with the retrieved skills, reflect on: 17 Preprint. Under review. − Which skills or parts of skills were directly useful? − Which skills had errors, outdated information, or misleading guidance? − What knowledge was missing that you had to figure out on your own? − What would have made the task easier if you ha...
-
[5]
Use the skill−creator skill at {agent_skills_path}/skill−creator/ as guidance for creating and writing skills
-
[6]
score": <1|2|3|4|5>,
Create refined skills that incorporate what you learned. The refined skills should: − Keep the parts that actually worked when you tried them. − Fix or remove parts that were wrong or misleading. − Add knowledge you discovered during exploration that was missing from the original skills. − Combine related information from multiple skills into coherent, ta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.