Recognition: 2 theorem links
· Lean TheoremGENSERVE: Efficient Co-Serving of Heterogeneous Diffusion Model Workloads
Pith reviewed 2026-05-10 20:17 UTC · model grok-4.3
The pith
By exploiting the preemptible steps in diffusion inference, a co-serving system improves SLO attainment for mixed text-to-image and text-to-video workloads by up to 44 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Diffusion inference advances through a fixed sequence of denoising steps that remain interruptible at each boundary. GENSERVE uses this property to coordinate three mechanisms: it preempts longer video generations at step boundaries when shorter image requests need resources, it adjusts sequence parallelism and batch sizes on the fly to match current workload mix, and it runs an SLO-aware scheduler that jointly decides allocation for every concurrent request. The result is a measurable rise in the fraction of requests that meet their latency targets, reaching gains of up to 44 percent over the strongest baseline across tested configurations.
What carries the argument
step-level resource adaptation, which treats each diffusion denoising step as a natural preemption point and uses that granularity to drive intelligent video preemption, elastic sequence parallelism with dynamic batching, and joint SLO-aware scheduling across heterogeneous requests.
If this is right
- Shared GPU clusters can host both text-to-image and text-to-video requests without dedicated partitions for each modality.
- The fraction of requests meeting latency SLOs rises by up to 44 percent relative to prior co-serving baselines.
- Resource allocation across concurrent requests becomes jointly optimized rather than handled independently per modality.
- Dynamic adjustments to parallelism and batch size can track changes in the mix of short and long requests in real time.
Where Pith is reading between the lines
- The same step-boundary preemption idea could extend to other iterative generative models that also advance in fixed, interruptible stages.
- Cluster operators might reduce total GPU count needed to support both modalities at a given SLO target.
- Further scheduling policies could incorporate additional signals such as remaining step count or user priority once the basic preemptibility is established.
Load-bearing premise
The diffusion process can be stopped and resumed at step boundaries with no hidden overheads or quality penalties that would cancel the gains from the three mechanisms.
What would settle it
Measure SLO attainment rates on a mixed T2I and T2V workload while forcing all preemption to occur only at full generation completion instead of at step boundaries; if the 44 percent gain vanishes, the central claim does not hold.
Figures





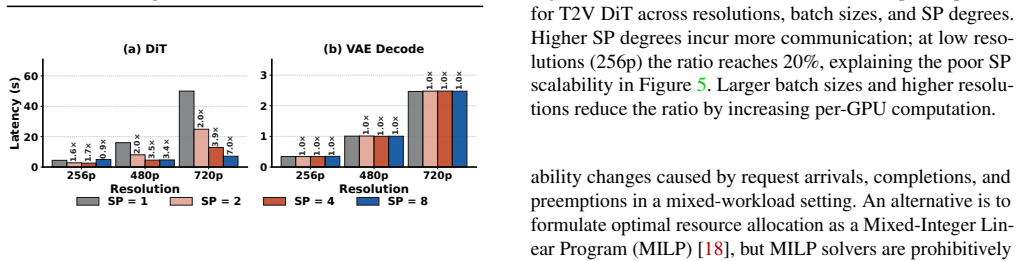







read the original abstract
Diffusion models have emerged as the prevailing approach for text-to-image (T2I) and text-to-video (T2V) generation, yet production platforms must increasingly serve both modalities on shared GPU clusters while meeting stringent latency SLOs. Co-serving such heterogeneous workloads is challenging: T2I and T2V requests exhibit vastly different compute demands, parallelism characteristics, and latency requirements, leading to significant SLO violations in existing serving systems. We present GENSERVE, a co-serving system that leverages the inherent predictability of the diffusion process to optimize serving efficiency. A central insight is that diffusion inference proceeds in discrete, predictable steps and is naturally preemptible at step boundaries, opening a new design space for heterogeneity-aware resource management. GENSERVE introduces step-level resource adaptation through three coordinated mechanisms: intelligent video preemption, elastic sequence parallelism with dynamic batching, and an SLO-aware scheduler that jointly optimizes resource allocation across all concurrent requests. Experimental results show that GENSERVE improves the SLO attainment rate by up to 44% over the strongest baseline across diverse configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GENSERVE, a co-serving system for heterogeneous diffusion model workloads on shared GPU clusters, focusing on text-to-image (T2I) and text-to-video (T2V) generation. It exploits the discrete and naturally preemptible steps of diffusion inference to enable step-level resource adaptation via three mechanisms: intelligent video preemption, elastic sequence parallelism with dynamic batching, and an SLO-aware scheduler that jointly optimizes allocations. The central experimental claim is an improvement of up to 44% in SLO attainment rate over the strongest baseline across diverse configurations.
Significance. If the performance claims hold under detailed scrutiny, the work would represent a practical contribution to systems for serving generative AI models. Handling mixed T2I/T2V workloads with strict latency SLOs is a timely problem as production platforms scale these models together; the step-boundary preemption insight and coordinated mechanisms offer a concrete design that could inform future heterogeneity-aware serving frameworks. The paper ships a systems artifact with measured outcomes rather than purely theoretical analysis, which strengthens its utility.
major comments (2)
- Abstract: the claim of up to 44% SLO improvement is presented without any information on the baselines compared against, the workload traces or request mixes used, the hardware platform, or statistical significance of the results. This absence directly undermines assessment of whether the central performance claim is load-bearing or reproducible.
- Description of video preemption mechanism: the assumption that diffusion steps are low-overhead preemption points is load-bearing for the 44% gain, yet no measurements are provided of state-save/restore costs (activation tensors, KV-cache, noise state) for T2V requests, which have substantially larger memory footprints than T2I. Without bounding these costs under mixed workloads, it remains unclear whether the scheduler's joint optimization delivers net positive SLO gains or if bandwidth and context-switch overheads erode them.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying areas where additional context and quantification would strengthen the manuscript. We address both major comments below and will incorporate revisions to improve clarity and completeness of the performance claims.
read point-by-point responses
-
Referee: Abstract: the claim of up to 44% SLO improvement is presented without any information on the baselines compared against, the workload traces or request mixes used, the hardware platform, or statistical significance of the results. This absence directly undermines assessment of whether the central performance claim is load-bearing or reproducible.
Authors: We agree that the abstract would benefit from additional context to make the central claim more transparent. In the revised manuscript we will expand the abstract to briefly specify the baselines (static allocation and prior diffusion serving systems), the workload traces (synthetic and real heterogeneous T2I/T2V mixes with varying request ratios and arrival rates), the hardware platform (NVIDIA A100 GPU cluster), and note that the 44% figure represents the maximum improvement observed across configurations with results averaged over multiple runs. revision: yes
-
Referee: Description of video preemption mechanism: the assumption that diffusion steps are low-overhead preemption points is load-bearing for the 44% gain, yet no measurements are provided of state-save/restore costs (activation tensors, KV-cache, noise state) for T2V requests, which have substantially larger memory footprints than T2I. Without bounding these costs under mixed workloads, it remains unclear whether the scheduler's joint optimization delivers net positive SLO gains or if bandwidth and context-switch overheads erode them.
Authors: This is a valid point; the net benefit of step-level preemption depends on the overhead being small relative to per-step compute. The current manuscript does not include quantitative microbenchmarks of save/restore latency or bandwidth for T2V state under mixed workloads. We will add these measurements in the revised version (new subsection in Evaluation or Appendix), reporting the time to checkpoint and restore noise tensors plus activations for representative T2V sequence lengths, both in isolation and when co-located with T2I requests. We will then show that the overhead remains a small fraction of step execution time and does not erode the reported SLO gains, or adjust the claims and scheduler if the data indicate otherwise. revision: yes
Circularity Check
No circularity; empirical systems paper with measured results
full rationale
The paper presents GENSERVE as a systems artifact for co-serving T2I and T2V diffusion workloads. Its core claim (up to 44% SLO improvement) rests on experimental measurements of three mechanisms (video preemption, elastic sequence parallelism with dynamic batching, and SLO-aware scheduler) rather than any derivation, equation, or fitted parameter. The abstract and description state the preemptibility insight as a design premise but do not reduce any prediction or result to that premise by construction. No self-citations, uniqueness theorems, or ansatzes appear as load-bearing steps. The work is self-contained against external benchmarks via reported outcomes; no step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion inference proceeds in discrete, predictable steps and is naturally preemptible at step boundaries.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
diffusion inference proceeds in discrete, predictable steps and is naturally preemptible at step boundaries... per-step runtime remains highly stable across batch sizes and SP degrees (CV < 0.05%)
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
intelligent video preemption... SLO-aware DP scheduler that jointly optimizes resource allocation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Approximate caching for efficiently serving diffusion models.arXiv preprint arXiv:2312.04429, 2023
Shubham Agarwal, Subrata Mitra, Sarthak Chakraborty, Srikrishna Karanam, Koyel Mukherjee, and Shiv Saini. Approximate caching for efficiently serving diffusion models.arXiv preprint arXiv:2312.04429, 2023
-
[2]
Approximate caching for efficiently serving {Text-to-Image} diffusion models
Shubham Agarwal, Subrata Mitra, Sarthak Chakraborty, Srikrishna Karanam, Koyel Mukherjee, and Shiv Ku- mar Saini. Approximate caching for efficiently serving {Text-to-Image} diffusion models. In21st USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 24), pages 1173–1189, 2024
2024
-
[3]
Diffserve: Efficiently serving text-to-image diffusion models with query-aware model scaling.Proceedings of Machine Learning and Systems, 7, 2025
Sohaib Ahmad, Qizheng Yang, Haoliang Wang, Ramesh K Sitaraman, and Hui Guan. Diffserve: Efficiently serving text-to-image diffusion models with query-aware model scaling.Proceedings of Machine Learning and Systems, 7, 2025
2025
-
[4]
Epd-serve: A flexible multimodal epd disaggregation inference serving system on ascend
Fan Bai, Pai Peng, Zhengzhi Tang, Zhe Wang, Gong Chen, Xiang Lu, Yinuo Li, Huan Lin, Weizhe Lin, Yaoyuan Wang, et al. Epd-serve: A flexible multimodal epd disaggregation inference serving system on ascend. arXiv preprint arXiv:2601.11590, 2026
-
[5]
All are worth words: A vit backbone for diffusion models
Fan Bao, Shen Nie, Kaiwen Xue, Yue Cao, Chongxuan Li, Hang Su, and Jun Zhu. All are worth words: A vit backbone for diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22669–22679, 2023
2023
-
[6]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review arXiv 2023
-
[7]
Cornserve: A Distributed Serving System for Any-to-Any Multimodal Models
Jae-Won Chung, Jeff J Ma, Jisang Ahn, Yizhuo Liang, Akshay Jajoo, Myungjin Lee, and Mosharaf Chowdhury. Cornserve: A distributed serving system for any-to-any multimodal models.arXiv preprint arXiv:2603.12118, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Clipper: A {Low-Latency} online prediction serving system
Daniel Crankshaw, Xin Wang, Guilio Zhou, Michael J Franklin, Joseph E Gonzalez, and Ion Stoica. Clipper: A {Low-Latency} online prediction serving system. In 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), pages 613–627, 2017
2017
-
[9]
Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[10]
Scaling recti- fied flow transformers for high-resolution image synthe- sis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthe- sis. InForty-first international conference on machine learning, 2024
2024
-
[11]
PipeFusion: Patch-level Pipeline Parallelism for Diffusion Transformers Inference
Jiarui Fang, Jinzhe Pan, Aoyu Li, Xibo Sun, and Jian- nan Wang. Pipefusion: Patch-level pipeline parallelism for diffusion transformers inference.arXiv preprint arXiv:2405.14430, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
xdit: an inference engine for diffusion transformers (dits) with massive parallelism,
Jiarui Fang, Jinzhe Pan, Xibo Sun, Aoyu Li, and Jiannan Wang. xdit: an inference engine for diffusion trans- formers (dits) with massive parallelism.arXiv preprint arXiv:2411.01738, 2024
-
[13]
Denois- ing diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denois- ing diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[14]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text- to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
work page internal anchor Pith review arXiv 2022
-
[15]
Heyang Huang, Cunchen Hu, Jiaqi Zhu, Ziyuan Gao, Liangliang Xu, Yizhou Shan, Yungang Bao, Sun Ninghui, Tianwei Zhang, and Sa Wang. Ddit: Dynamic resource allocation for diffusion transformer model serv- ing.arXiv preprint arXiv:2506.13497, 2025
-
[16]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on 13 Computer Vision and Pattern Recognition, pages 21807– 21818, 2024
2024
-
[17]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajb- handari, and Yuxiong He. Deepspeed ulysses: Sys- tem optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509, 2023
work page internal anchor Pith review arXiv 2023
-
[18]
Algorithms for hybrid milp/cp models for a class of optimization prob- lems.INFORMS Journal on computing, 13(4):258–276, 2001
Vipul Jain and Ignacio E Grossmann. Algorithms for hybrid milp/cp models for a class of optimization prob- lems.INFORMS Journal on computing, 13(4):258–276, 2001
2001
-
[19]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jian- wei Zhang, et al. Hunyuanvideo: A systematic frame- work for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Efficient memory manage- ment for large language model serving with pagedatten- tion
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory manage- ment for large language model serving with pagedatten- tion. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[21]
Distrifusion: Distributed parallel inference for high-resolution diffusion models
Muyang Li, Tianle Cai, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Kai Li, and Song Han. Distrifusion: Distributed parallel inference for high-resolution diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7183–7193, 2024
2024
-
[22]
{AlpaServe}: Sta- tistical multiplexing with model parallelism for deep learning serving
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E Gonzalez, et al. {AlpaServe}: Sta- tistical multiplexing with model parallelism for deep learning serving. In17th USENIX Symposium on Oper- ating Systems Design and Implementation (OSDI 23), pages 663–679, 2023
2023
-
[23]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring at- tention with blockwise transformers for near-infinite context.arXiv preprint arXiv:2310.01889, 2023
work page internal anchor Pith review arXiv 2023
-
[24]
Tetriserve: Efficiently serving mixed dit work- loads
Runyu Lu, Shiqi He, Wenxuan Tan, Shenggui Li, Ruo- fan Wu, Jeff J Ma, Ang Chen, and Mosharaf Chowd- hury. Tetriserve: Efficiently serving mixed dit work- loads. 2026
2026
-
[25]
Cornfigurator: Automated Planning for Any-to-Any Multimodal Model Serving
Jeff J Ma, Jae-Won Chung, Jisang Ahn, Yizhuo Liang, Akshay Jajoo, Myungjin Lee, and Mosharaf Chowdhury. Cornserve: Efficiently serving any-to-any multimodal models.arXiv preprint arXiv:2512.14098, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Scalable diffu- sion models with transformers
William Peebles and Saining Xie. Scalable diffu- sion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[27]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Modserve: Modality-and stage-aware resource disaggregation for scalable multimodal model serving
Haoran Qiu, Anish Biswas, Zihan Zhao, Jayashree Mo- han, Alind Khare, Esha Choukse, Íñigo Goiri, Zeyu Zhang, Haiying Shen, Chetan Bansal, et al. Modserve: Modality-and stage-aware resource disaggregation for scalable multimodal model serving. InProceedings of the 2025 ACM Symposium on Cloud Computing, pages 817–830, 2025
2025
-
[29]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[31]
Photorealistic text-to-image diffusion mod- els with deep language understanding.Advances in neu- ral information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Sali- mans, et al. Photorealistic text-to-image diffusion mod- els with deep language understanding.Advances in neu- ral information processing systems, 35:36479–36494, 2022
2022
-
[32]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792, 2022
work page internal anchor Pith review arXiv 2022
-
[33]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. De- noising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[34]
Desen Sun, Henry Tian, Tim Lu, and Sihang Liu. Flex- cache: Flexible approximate cache system for video diffusion.arXiv preprint arXiv:2501.04012, 2024
-
[35]
Mixfusion: A patch-level parallel serving system for mixed-resolution diffusion models
Desen Sun, Zepeng Zhao, and Yuke Wang. Mixfusion: A patch-level parallel serving system for mixed-resolution diffusion models. InProceedings of the 31st ACM SIG- PLAN Annual Symposium on Principles and Practice of Parallel Programming, pages 522–536, 2026. 14
2026
-
[36]
Diffusers: State- of-the-art diffusion models
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pe- dro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, Dhruv Nair, Sayak Paul, William Berman, Yiyi Xu, Steven Liu, and Thomas Wolf. Diffusers: State- of-the-art diffusion models. https://github.com/ huggingface/diffusers, 2022
2022
-
[37]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Diffusiondb: A large-scale prompt gallery dataset for text-to-image generative models
Zijie J Wang, Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau. Diffusiondb: A large-scale prompt gallery dataset for text-to-image generative models. InProceedings of the 61st annual meeting of the association for com- putational linguistics (volume 1: Long papers), pages 893–911, 2023
2023
-
[39]
Yifei Xia, Fangcheng Fu, Hao Yuan, Hanke Zhang, Xu- peng Miao, Yijun Liu, Suhan Ling, Jie Jiang, and Bin Cui. Tridentserve: A stage-level serving system for diffusion pipelines.arXiv preprint arXiv:2510.02838, 2025
-
[40]
Modm: Efficient serving for image generation via m ixture-o f-d iffusion m odels
Yuchen Xia, Divyam Sharma, Yichao Yuan, Souvik Kundu, and Nishil Talati. Modm: Efficient serving for image generation via m ixture-o f-d iffusion m odels. In Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, pages 163–182, 2026
2026
-
[41]
Jiacheng Yang, Jun Wu, Yaoyao Ding, Zhiying Xu, Yida Wang, and Gennady Pekhimenko. Streamfusion: Scalable sequence parallelism for distributed inference of diffusion transformers on gpus.arXiv preprint arXiv:2601.20273, 2026
-
[42]
Supergen: An efficient ultra-high-resolution video generation system with sketching and tiling,
Fanjiang Ye, Zepeng Zhao, Yi Mu, Jucheng Shen, Ren- jie Li, Kaijian Wang, Saurabh Agarwal, Myungjin Lee, Triston Cao, Aditya Akella, et al. Supergen: An effi- cient ultra-high-resolution video generation system with sketching and tiling.arXiv preprint arXiv:2508.17756, 2025
-
[43]
Peiqi Yin, Jiangyun Zhu, Han Gao, Chenguang Zheng, Yongxiang Huang, Taichang Zhou, Ruirui Yang, Weizhi Liu, Weiqing Chen, Canlin Guo, et al. vllm-omni: Fully disaggregated serving for any-to-any multimodal mod- els.arXiv preprint arXiv:2602.02204, 2026
-
[44]
Orca: A distributed serving system for {Transformer-Based} generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soo- jeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX symposium on operating sys- tems design and implementation (OSDI 22), pages 521– 538, 2022
2022
-
[45]
Open-sora 2.0: Training a commercial-level video generation model in $200 k
Zangwei Zheng, Xiangyu Peng, Yuxuan Lou, Chenhui Shen, Tom Young, Xinying Guo, Binluo Wang, Hang Xu, Hongxin Liu, Mingyan Jiang, et al. Open-sora 2.0: Training a commercial-level video generation model in $200 k.arXiv preprint arXiv:2503.09642, 2025
-
[46]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chen- hui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratiz- ing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024. 15
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.