BiST: A Gold Standard Bangla-English Bilingual Corpus for Sentence Structure and Tense Classification with Inter-Annotator Agreement
Pith reviewed 2026-05-10 19:18 UTC · model grok-4.3
The pith
BiST introduces a bilingual corpus of over 30,000 sentences labeled for syntactic structure and tense in Bangla and English.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
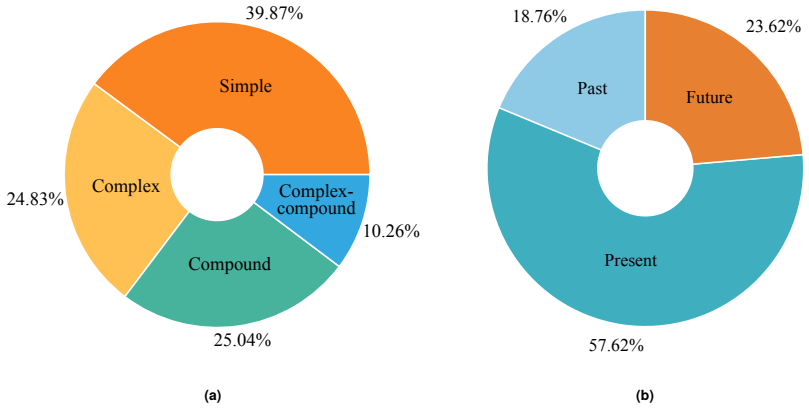
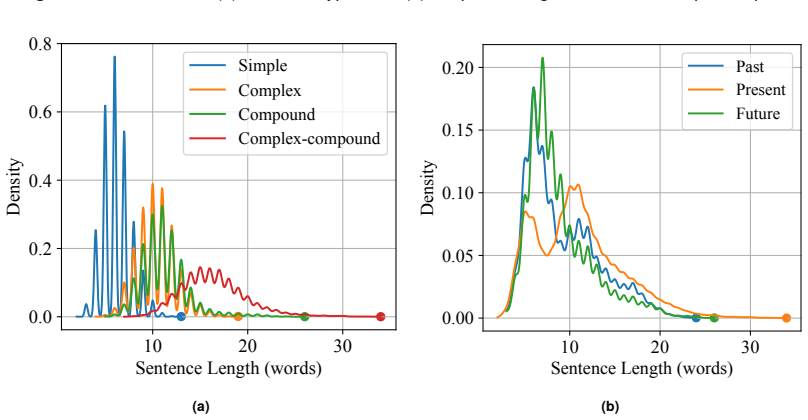
The central claim is that BiST constitutes a gold-standard bilingual resource by combining 17,465 English and 13,069 Bangla sentences, each annotated for structure (Simple, Complex, Compound, Complex-Compound) and tense (Present, Past, Future), with dimension-wise Fleiss kappa agreement of 0.82 and 0.88 confirming label reliability. The corpus is constructed through preprocessing and automated language identification from representative sources, and baseline experiments establish that dual-encoder architectures using complementary language-specific representations outperform strong multilingual encoders on the two classification tasks.
What carries the argument
The BiST corpus itself, created via multi-stage annotation by three independent annotators and evaluated with dimension-wise Fleiss kappa for structural and temporal labels.
If this is right
- Dual-encoder models that maintain separate language-specific representations achieve higher accuracy on structure and tense classification than single multilingual encoders.
- The explicit structural and tense labels enable supervised training for controlled text generation and automated grammatical feedback.
- The corpus supports cross-lingual representation learning by providing aligned bilingual supervision on the same grammatical dimensions.
- Statistical distributions of structures and tenses in the data match patterns expected in natural language use.
Where Pith is reading between the lines
- The annotation protocol could be reused with other language pairs to produce comparable gold-standard resources without starting from scratch.
- High agreement on the chosen categories indicates that sentence structure and tense distinctions are stable enough for consistent labeling across languages.
- Models trained with these labels may improve performance on downstream tasks that require explicit grammatical control, such as machine translation or summarization.
Load-bearing premise
The chosen encyclopedic and conversational sources supply representative samples of natural sentence structures and tenses in both languages without major domain bias or ambiguity in the annotation guidelines.
What would settle it
A replication in which new annotators following the published guidelines obtain Fleiss kappa scores below 0.7 on either dimension, or in which dual-encoder models no longer outperform multilingual baselines on a fresh test split drawn from the same sources.
Figures


read the original abstract
High-quality bilingual resources remain a critical bottleneck for advancing multilingual NLP in low-resource settings, particularly for Bangla. To mitigate this gap, we introduce BiST, a rigorously curated Bangla-English corpus for sentence-level grammatical classification, annotated across two fundamental dimensions: syntactic structure (Simple, Complex, Compound, Complex-Compound) and tense (Present, Past, Future). The corpus is compiled from open-licensed encyclopedic sources and naturally composed conversational text, followed by systematic preprocessing and automated language identification, resulting in 30,534 sentences, including 17,465 English and 13,069 Bangla instances. Annotation quality is ensured through a multi-stage framework with three independent annotators and dimension-wise Fleiss Kappa ($\kappa$) agreement, yielding reliable and reproducible labels with $\kappa$ values of 0.82 and 0.88 for structural and temporal annotation, respectively. Statistical analyses demonstrate realistic structural and temporal distributions, while baseline evaluations show that dual-encoder architectures leveraging complementary language-specific representations consistently outperform strong multilingual encoders. Beyond benchmarking, BiST provides explicit linguistic supervision that supports grammatical modeling tasks, including controlled text generation, automated feedback generation, and cross-lingual representation learning. The corpus establishes a unified resource for bilingual grammatical modeling and facilitates linguistically grounded multilingual research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BiST, a bilingual Bangla-English corpus of 30,534 sentences (17,465 English, 13,069 Bangla) compiled from open-licensed encyclopedic and conversational sources. Sentences are annotated for syntactic structure (Simple, Complex, Compound, Complex-Compound) and tense (Present, Past, Future) by three independent annotators using a multi-stage process. The work reports Fleiss' kappa values of 0.82 (structure) and 0.88 (tense), statistical analyses of label distributions, and baseline experiments where dual-encoder models outperform strong multilingual encoders. It positions BiST as a gold-standard resource supporting grammatical modeling, controlled text generation, and cross-lingual learning in low-resource multilingual NLP.
Significance. If the reported inter-annotator agreement holds and the distributions prove representative, BiST addresses a documented resource gap for Bangla by supplying explicit linguistic supervision for sentence-level grammatical classification. The concrete kappa values and dual-encoder baseline comparisons are strengths that support its use for benchmarking and downstream tasks. The multi-stage annotation framework and open-licensed sourcing further enhance potential reproducibility and utility in the field.
major comments (1)
- [Statistical analyses section] Statistical analyses section: The claim that the corpus exhibits 'realistic structural and temporal distributions' is not supported by any quantitative comparison of class proportions, sentence complexity metrics, or tense frequencies against reference corpora (e.g., full Wikipedia or established conversational benchmarks). Without such validation, the representativeness of the encyclopedic and conversational sources remains an untested assumption that directly affects the 'gold standard' characterization.
minor comments (2)
- [Methods section] Methods section: Provide explicit details on the automated language identification tool, preprocessing pipeline (including any filtering criteria), and exact annotation guidelines for distinguishing Complex-Compound sentences or handling tense in bilingual contexts to improve reproducibility.
- [Baseline evaluations] Baseline evaluations: Report the specific multilingual encoder models used, hyperparameter settings, data splits, and statistical significance tests for the performance differences to allow direct replication of the dual-encoder superiority claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment point by point below, with a commitment to revise where the concern is valid.
read point-by-point responses
-
Referee: [Statistical analyses section] Statistical analyses section: The claim that the corpus exhibits 'realistic structural and temporal distributions' is not supported by any quantitative comparison of class proportions, sentence complexity metrics, or tense frequencies against reference corpora (e.g., full Wikipedia or established conversational benchmarks). Without such validation, the representativeness of the encyclopedic and conversational sources remains an untested assumption that directly affects the 'gold standard' characterization.
Authors: We acknowledge that the manuscript presents the observed label distributions and frequencies within BiST but does not include direct quantitative comparisons against large external reference corpora such as full Wikipedia or established benchmarks. The description of 'realistic structural and temporal distributions' was intended to reflect the natural composition of the open-licensed encyclopedic and conversational sources, yet we agree this remains an assumption without explicit validation. In the revised version, we will remove the unsupported claim of realism and instead neutrally describe the empirical distributions observed in the corpus. We will also add a brief discussion noting the limitations of representativeness claims and, where feasible with available resources, include comparisons to smaller public subsets of conversational or encyclopedic data. The gold-standard characterization of BiST rests primarily on the multi-stage annotation protocol and the reported Fleiss' kappa values (0.82 for structure, 0.88 for tense), which are independent of distributional representativeness. revision: partial
Circularity Check
No significant circularity; empirical corpus construction with independent agreement metrics
full rationale
The paper reports the assembly of a bilingual corpus from open-licensed sources, multi-annotator labeling of sentence structure and tense, computation of Fleiss' kappa (0.82 structural, 0.88 temporal), descriptive statistics on class distributions, and baseline classifier results. No equations, fitted parameters, or predictions are present that reduce by construction to the inputs (e.g., no self-definitional scales, no 'prediction' of quantities used in fitting, no uniqueness theorems imported from self-citations). The central claims rest on observable annotation agreement and empirical distributions rather than any tautological loop. This is the expected non-finding for a resource-creation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Fleiss Kappa is an appropriate measure of multi-annotator agreement for categorical labels
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The corpus is compiled from open-licensed encyclopedic sources and naturally composed conversational text, followed by systematic preprocessing and automated language identification, resulting in 30,534 sentences...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Emotion classification in bangla: A com- prehensive comparison of banglabert, mbert, and xlm-roberta with error analysis and signifi- cance testing. In 2025 9th International Sympo- sium on Multidisciplinary Studies and Innovative T echnologies (ISMSIT), pages 1–8. IEEE. Md Parvez Hossain, Ohidujjaman Ohidujjaman, Mohammad Shorif Uddin, Mohammad Nurul Hud...
work page 2025
-
[2]
Controllable text generation for large language models: A survey
From matching to generation: A survey on generative information retrieval. ACM T rans- actions on Information Systems , 43(3):1–62. Xun Liang, Hanyu Wang, Yezhaohui Wang, Shichao Song, Jiawei Yang, Simin Niu, Jie Hu, Dan Liu, Shunyu Yao, Feiyu Xiong, et al. 2024. Controllable text generation for large language models: A survey. arXiv:2408.12599. Euan D Li...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.