Selecting Decision-Relevant Concepts in Reinforcement Learning
Pith reviewed 2026-05-10 20:17 UTC · model grok-4.3
The pith
A state abstraction approach lets reinforcement learning agents automatically select decision-relevant concepts with performance guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
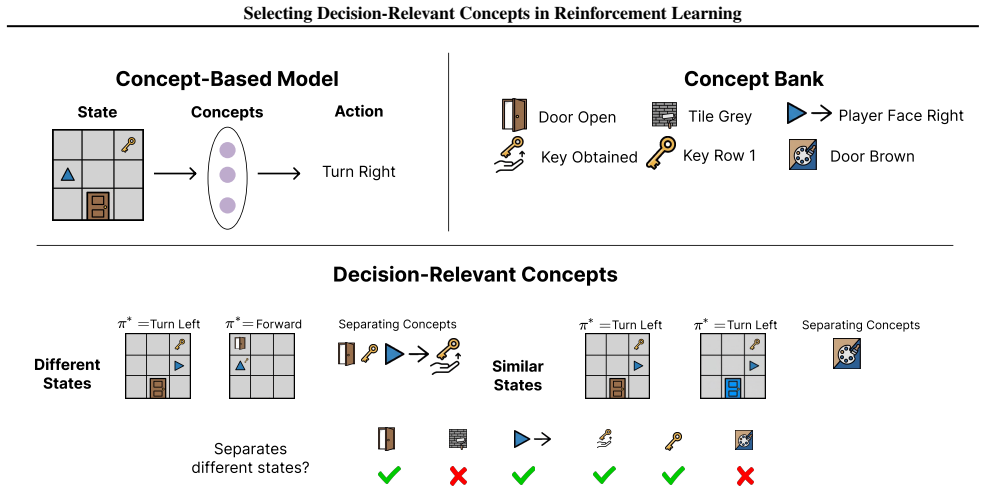
Concept selection can be viewed through state abstraction: a concept is decision-relevant if removing it would cause the agent to confuse states requiring different actions. Agents relying on such concepts ensure that states with the same concept representation share the same optimal action, thereby preserving the optimal decision structure. This leads to the DRS algorithm that selects subsets from candidates along with performance bounds, and empirically recovers manually curated sets while matching or exceeding their performance.
What carries the argument
Decision-Relevant Selection (DRS) algorithm, which selects concepts by ensuring same-concept states have identical optimal actions via state abstraction.
If this is right
- DRS provides performance bounds relating selected concepts to the original policy's performance.
- Selected concepts enable effective test-time interventions in RL environments.
- The method recovers expert-curated concept sets automatically across benchmarks.
- It improves outcomes in real-world applications such as healthcare decision support.
Where Pith is reading between the lines
- The state abstraction perspective could apply to selecting interpretable features in non-sequential machine learning tasks.
- Future work might combine DRS with other abstraction methods like bisimulations for more robust concept choices.
- Scalability to high-dimensional concept candidate sets remains an open question for broader adoption.
Load-bearing premise
The premise that states sharing a concept representation will have the same optimal action, preserving the original decision structure.
What would settle it
An environment where applying DRS yields a policy that confuses states with different optimal actions under the selected concepts, leading to suboptimal performance not bounded as claimed.
Figures











read the original abstract
Training interpretable concept-based policies requires practitioners to manually select which human-understandable concepts an agent should reason with when making sequential decisions. This selection demands domain expertise, is time-consuming and costly, scales poorly with the number of candidates, and provides no performance guarantees. To overcome this limitation, we propose the first algorithms for principled automatic concept selection in sequential decision-making. Our key insight is that concept selection can be viewed through the lens of state abstraction: intuitively, a concept is decision-relevant if removing it would cause the agent to confuse states that require different actions. As a result, agents should rely on decision-relevant concepts; states with the same concept representation should share the same optimal action, which preserves the optimal decision structure of the original state space. This perspective leads to the Decision-Relevant Selection (DRS) algorithm, which selects a subset of concepts from a candidate set, along with performance bounds relating the selected concepts to the performance of the resulting policy. Empirically, DRS automatically recovers manually curated concept sets while matching or exceeding their performance, and improves the effectiveness of test-time concept interventions across reinforcement learning benchmarks and real-world healthcare environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that concept selection in RL can be framed as state abstraction, where a concept is decision-relevant if states sharing its representation have identical optimal actions (preserving decision structure). This leads to the DRS algorithm for automatic subset selection from candidates, accompanied by performance bounds on the resulting policy, with empirical results showing automatic recovery of manual concept sets and competitive or superior performance on RL benchmarks and real-world healthcare environments.
Significance. If the central claims hold without circularity and with valid bounds, the work would enable principled, automatic selection of interpretable concepts for RL policies, reducing dependence on manual domain expertise while providing performance guarantees; this could meaningfully advance interpretable sequential decision-making in high-stakes domains.
major comments (2)
- [Abstract] Abstract: the key insight equates decision-relevance with an abstraction in which identical concept vectors imply identical optimal actions. Operationalizing selection via partitioning states by candidate subsets and verifying action constancy within blocks requires access to (or estimation of) optimal actions/Q* for each state under varying projections. This presupposes a solution to the original MDP and introduces circularity for the motivating use case of learning policies when the optimal policy is unknown or expensive to compute.
- [Abstract] Abstract (performance bounds): the bounds are asserted to relate selected concepts to policy performance, but the excerpt provides no derivation, assumptions, or error analysis. Without these details it is impossible to evaluate whether the bounds are non-vacuous or whether they apply only conditionally on already knowing the decision structure the method claims to recover.
minor comments (1)
- The abstract is concise but the full manuscript should include explicit pseudocode or algorithmic steps for DRS to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting two important issues in the abstract: the potential circularity in operationalizing decision-relevance and the lack of visible derivation for the performance bounds. We address both points below. Where the comments identify gaps in exposition or assumptions, we have revised the manuscript to improve clarity without altering the core claims or algorithms.
read point-by-point responses
-
Referee: [Abstract] Abstract: the key insight equates decision-relevance with an abstraction in which identical concept vectors imply identical optimal actions. Operationalizing selection via partitioning states by candidate subsets and verifying action constancy within blocks requires access to (or estimation of) optimal actions/Q* for each state under varying projections. This presupposes a solution to the original MDP and introduces circularity for the motivating use case of learning policies when the optimal policy is unknown or expensive to compute.
Authors: We agree that a literal requirement for the exact optimal action function Q* would render the procedure circular for the primary use case of learning policies from scratch. The DRS algorithm is therefore instantiated with an approximate policy (or Q-function) obtained from a short initial training run or simulator rollouts; the selected concepts are then used to train or fine-tune the final policy. This two-stage procedure is already described in Section 3.2 and Algorithm 1, but we have added an explicit paragraph in the revised abstract and introduction clarifying the approximation, its error tolerance, and the conditions under which the recovered concepts remain decision-relevant. The theoretical analysis in Section 4 continues to use the exact optimal policy for the purpose of proving bounds, which we now flag as an idealized reference point rather than a prerequisite for practical deployment. revision: yes
-
Referee: [Abstract] Abstract (performance bounds): the bounds are asserted to relate selected concepts to policy performance, but the excerpt provides no derivation, assumptions, or error analysis. Without these details it is impossible to evaluate whether the bounds are non-vacuous or whether they apply only conditionally on already knowing the decision structure the method claims to recover.
Authors: The performance bounds appear in Theorem 4.1 and are derived from the standard state-abstraction regret analysis under the assumption that the selected concept mapping preserves the optimal action partition. The key assumptions (finite state space, known transition model or simulator, and Lipschitz continuity of the value function) are stated in Section 4.1; the proof shows that the sub-optimality gap is at most the diameter of the largest abstraction block times a discount-dependent constant. We have inserted a concise statement of the main assumptions and a one-sentence sketch of the bound into the revised abstract, while retaining the full derivation and error analysis in the main text. The bounds are therefore not conditional on already knowing the final decision structure; they quantify the worst-case loss relative to the optimal policy of the original MDP once the selected concepts are fixed. revision: yes
Circularity Check
No significant circularity; definition and bounds are self-contained via standard state abstraction without reducing to fitted inputs or self-citations.
full rationale
The paper's core insight equates decision-relevance with state abstractions that preserve optimal action uniformity across concept-equivalent states, leading to DRS selection and performance bounds. No equations, fitted parameters, or self-citations are shown in the provided text that would force the result by construction. The approach imports the abstraction lens as an external perspective and claims empirical recovery of curated sets plus bounds relating selection quality to policy performance, remaining independent of the target policy itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A concept is decision-relevant if removing it would cause the agent to confuse states that require different actions; states with the same concept representation share the same optimal action.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
states with the same concept representation should share the same optimal action, which preserves the optimal decision structure of the original state space... ϵQπ(g) := max_{s,s′:g(s)=g(s′)} D_{s,s′}
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
V π∗(s)−V π∗c(s)≤ 2ϵ(gc)/(1−γ)²
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
CartPoleoriginally has a state space consisting of four numbers: the position, velocity, angle, and angular ve- locity. We discretize each of these with two thresholds for position and angle, and four thresholds for angular velocity and velocity. This gives a total of 12 concepts
-
[2]
MiniGridis characterized through the agent’s position, door location, key obtaining, and door unlock status. 10 Selecting Decision-Relevant Concepts in Reinforcement Learning For MiniGrid, we use a fully symbolic state represen- tation consisting of 12 discrete features extracted from the final observation frame. These features encode the agent’s(x, y) po...
-
[3]
Ponghas concepts derived from object-centric state variables computed from the last one or two frames of the observation stack. Base features include continuous-valued positions, velocities, and relative offsets of the agent paddle, ball, and opponent paddle. Specifically, we extract the agent paddle’s vertical posi- tion; the ball’s horizontal and vertic...
-
[4]
Boxingconcepts are constructed from the positions and movements of the player and opponent sprites. Base features include the normalized x- and y-positions of both the player and the enemy in the final observation frame, as well as their velocities computed as differ- ences between the last two frames. We additionally include relative position features ca...
-
[5]
Glucosehas a state which consists of six continuous- valued physiological or control-related variables ex- tracted from the final observation frame. Each feature corresponds to a scalar quantity, such as an absolute level, rate of change, or control signal, and no tem- poral differencing is applied. Concepts are defined by thresholding each feature at a h...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.