Recognition: 2 theorem links
· Lean TheoremYMIR: A new Benchmark Dataset and Model for Arabic Yemeni Music Genre Classification Using Convolutional Neural Networks
Pith reviewed 2026-05-10 19:46 UTC · model grok-4.3
The pith
A new dataset of Yemeni music enables a convolutional neural network to classify five traditional genres at 98.8 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
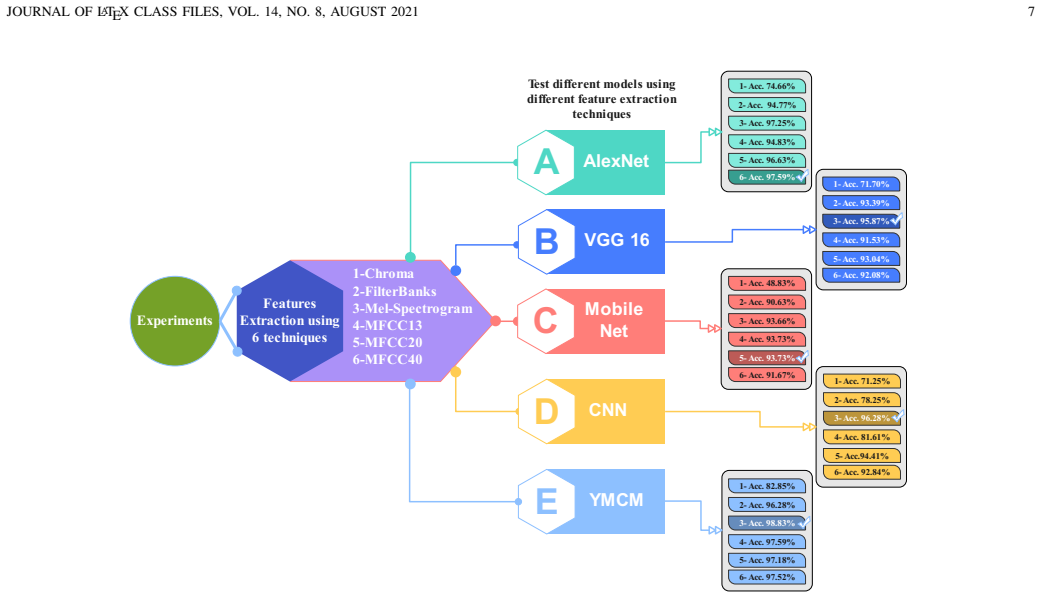
We introduce the YMIR dataset containing 1,475 carefully selected audio clips across five traditional Yemeni genres: Sanaani, Hadhrami, Lahji, Tihami, and Adeni. The clips were annotated by five Yemeni music experts with a Fleiss kappa of 0.85. We propose YMCM, a CNN model for genre classification from time-frequency features. In experiments comparing six groups and five architectures, YMCM with Mel-spectrogram features achieves the highest accuracy of 98.8 percent and outperforms AlexNet, VGG16, MobileNet, and a baseline CNN.
What carries the argument
The Yemeni Music Classification Model (YMCM), a convolutional neural network that processes time-frequency representations such as Mel-spectrograms to assign clips to one of five Yemeni music genres.
If this is right
- The YMIR dataset serves as a benchmark for future models that classify Yemeni music genres.
- Mel-spectrograms yield higher accuracy than Chroma, FilterBank, or MFCC features when used with convolutional networks on this material.
- A custom CNN architecture can exceed the performance of standard models such as AlexNet and VGG16 under matched experimental conditions.
- The systematic comparison of features and architectures supplies guidance for applying similar methods to other culturally specific music traditions.
Where Pith is reading between the lines
- Acoustic patterns that separate the five genres appear sufficiently distinct for convolutional networks to exploit once suitable features are chosen.
- The same dataset and modeling approach could be extended to additional Yemeni or regional genres to test whether the reported accuracy generalizes.
- Trained models from this benchmark might later support comparative studies between Yemeni music and other Arabic or non-Western traditions.
Load-bearing premise
The 1,475 selected clips and the expert annotations form a representative sample of the five genres with no significant overlap or labeling artifacts.
What would settle it
Running the trained YMCM on a fresh collection of Yemeni music recordings gathered separately from the YMIR clips and checking whether accuracy remains near 98.8 percent.
Figures








read the original abstract
Automatic music genre classification is a major task in music information retrieval; however, most current benchmarks and models have been developed primarily for Western music, leaving culturally specific traditions underrepresented. In this paper, we introduce the Yemeni Music Information Retrieval (YMIR) dataset, which contains 1,475 carefully selected audio clips covering five traditional Yemeni genres: Sanaani, Hadhrami, Lahji, Tihami, and Adeni. The dataset was labeled by five Yemeni music experts following a clear and structured protocol, resulting in strong inter-annotator agreement (Fleiss kappa = 0.85). We also propose the Yemeni Music Classification Model (YMCM), a convolutional neural network (CNN)-based system designed to classify music genres from time-frequency features. Using a consistent preprocessing pipeline, we perform a systematic comparison across six experimental groups and five different architectures, resulting in a total of 30 experiments. Specifically, we evaluate several feature representations, including Mel-spectrograms, Chroma, FilterBank, and MFCCs with 13, 20, and 40 coefficients, and benchmark YMCM against standard models (AlexNet, VGG16, MobileNet, and a baseline CNN) under the same experimental conditions. The experimental findings reveal that YMCM is the most effective, achieving the highest accuracy of 98.8% with Mel-spectrogram features. The results also provide practical insights into the relationship between feature representation and model capacity. The findings establish YMIR as a useful benchmark and YMCM as a strong baseline for classifying Yemeni music genres.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the YMIR dataset of 1,475 audio clips spanning five Yemeni genres (Sanaani, Hadhrami, Lahji, Tihami, Adeni), annotated by five experts with Fleiss' kappa = 0.85. It proposes the YMCM CNN and reports results from 30 experiments comparing feature representations (Mel-spectrograms, Chroma, FilterBank, MFCCs) and architectures (YMCM vs. AlexNet, VGG16, MobileNet, baseline CNN), with YMCM achieving the highest accuracy of 98.8% on Mel-spectrograms.
Significance. If the reported accuracies are shown to reflect generalization rather than leakage, the work provides a valuable new benchmark for underrepresented non-Western music in MIR, supported by strong expert annotation agreement and a systematic multi-feature, multi-model comparison that yields practical insights on feature-model interactions.
major comments (1)
- [Abstract and experimental results] Abstract and experimental protocol: the headline claim that YMCM achieves 98.8% accuracy and is superior to AlexNet/VGG16/MobileNet under identical conditions is load-bearing, yet the manuscript supplies no train/test split ratios, source-blocking procedure for clips from the same performance or artist, cross-validation scheme, or variance across repeated runs. On a 1,475-clip corpus this omission prevents verification that the 30 experiments used a truly held-out test set, directly undermining the generalization and comparison results.
minor comments (2)
- [Dataset] Dataset section: per-genre clip counts and balance statistics are not reported, making it difficult to assess whether the five-class benchmark is balanced or whether class imbalance could affect the reported accuracies.
- [Abstract] The abstract refers to 'six experimental groups' without defining them; a brief enumeration in the methods would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the experimental protocol description in the original manuscript was incomplete, which is a significant omission given the importance of verifying generalization and the absence of data leakage. We will revise the manuscript to address this fully.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and experimental protocol: the headline claim that YMCM achieves 98.8% accuracy and is superior to AlexNet/VGG16/MobileNet under identical conditions is load-bearing, yet the manuscript supplies no train/test split ratios, source-blocking procedure for clips from the same performance or artist, cross-validation scheme, or variance across repeated runs. On a 1,475-clip corpus this omission prevents verification that the 30 experiments used a truly held-out test set, directly undermining the generalization and comparison results.
Authors: We agree that this is a valid and important criticism. The manuscript did not include the required details on data partitioning and evaluation, which prevents independent assessment of whether the reported accuracies reflect true generalization. In the revised version, we will add a dedicated subsection on the experimental protocol that specifies the train/test split ratios, the source-blocking procedure used to keep clips from the same performance or artist within the same split, the cross-validation scheme, and the mean accuracy with standard deviation across repeated runs. These additions will allow verification that a truly held-out test set was used and will strengthen the comparative claims. revision: yes
Circularity Check
No circularity: empirical accuracy from held-out evaluation on new dataset
full rationale
The paper's central result (98.8% accuracy for YMCM on Mel-spectrograms) is produced by standard supervised training of CNNs on time-frequency features extracted from the 1,475-clip YMIR dataset. No equations, derivations, or parameter-fitting steps are present that would reduce the reported metric to a self-referential definition, a renamed input, or a load-bearing self-citation. Dataset labeling (Fleiss κ=0.85) and model comparisons occur under explicitly described experimental conditions without any uniqueness theorem or ansatz imported from prior author work. The evaluation chain is therefore self-contained against external audio benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert annotations with Fleiss kappa 0.85 provide reliable ground-truth labels for the five genres
- domain assumption Mel-spectrograms and related features capture genre-discriminative information in Yemeni music
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose the Yemeni Music Classification Model (YMCM), a convolutional neural network (CNN)-based system... Mel-spectrograms, Chroma, FilterBank, and MFCCs... 98.83% accuracy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
five traditional Yemeni genres... 30 experiments... stratified training/testing splits
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Music genre classification and music recom- mendation by using deep learning,
A. Elbir and N. Aydin, “Music genre classification and music recom- mendation by using deep learning,”Electronics Letters, vol. 56, no. 12, pp. 627–629, 2020
2020
-
[2]
Representing musical genre: A state of the art,
J.-J. Aucouturier and F. Pachet, “Representing musical genre: A state of the art,”Journal of New Music Research, vol. 32, no. 1, pp. 83–93, 2003
2003
-
[3]
Music genre classification and recommendation by using machine learning techniques,
A. Elbir, H. B. C ¸ am, M. E. ˙Iyican, B. ¨Ozt¨urk, and N. Aydın, “Music genre classification and recommendation by using machine learning techniques,” in2018 Innovations in Intelligent Systems and Applications Conference (ASYU). IEEE, 2018, pp. 1–5. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10
2018
-
[4]
Ga-based parameterization and feature selection for automatic music genre recognition,
M. Serwach and B. Stasiak, “Ga-based parameterization and feature selection for automatic music genre recognition,” inProceedings of 2016 17th International Conference Computational Problems of Electrical Engineering (CPEE), 2016
2016
-
[5]
Musical genre classification of audio signals,
G. Tzanetakis and P. Cook, “Musical genre classification of audio signals,”IEEE Transactions on Speech and Audio Processing, vol. 10, no. 5, pp. 293–302, 2002
2002
-
[6]
Content-based classifi- cation, search, and retrieval of audio,
E. Wold, T. Blum, D. Keislar, and J. Wheaton, “Content-based classifi- cation, search, and retrieval of audio,”IEEE Multimedia, vol. 3, no. 3, pp. 27–36, 1996
1996
-
[7]
A historical glimpse of music in yemen in the 1930s: The cylinders recorded by hans helfritz,
J. Lambert, “A historical glimpse of music in yemen in the 1930s: The cylinders recorded by hans helfritz,”The World of Music (new series), vol. 9, no. 2, pp. 49–66, 2020. [Online]. Available: https://journals.uni-goettingen.de/wom/article/view/1426
2020
-
[8]
G. Lavin, “Music in colonial aden: Globalization, cultural politics and the record industry in an indian ocean port city, c. 1937–1960,”SOAS Musicology Series, 2020. [Online]. Available: https://www.academia. edu/73304097
-
[9]
J. A. Ahmed,From the Yemeni Music Scene. Cultural Affairs Publishing House, 2007
2007
-
[10]
Cultural heritage of yemeni folk song: The importance of singing,
M. Altwaiji, “Cultural heritage of yemeni folk song: The importance of singing,”International Journal of Sociology and Political Science, vol. 6, no. 1, 2024. [Online]. Available: https://www.sociologyjournal. in/assets/archives/2024/vol6issue1/6001.pdf
2024
-
[11]
Al-ghina al-san’ani, traditional sanaa-style singing,
UNESCO, “Al-ghina al-san’ani, traditional sanaa-style singing,” https://ich.unesco.org/en/RL/ al-ghina-al-sanani-traditional-sanaa-style-singing-00161, 2003
2003
-
[12]
Genre classification empowered by knowledge-embedded music representation,
H. Ding, L. Zhai, C. Zhao, F. Wang, G. Wang, W. Xi, Z. Wang, and J. Zhao, “Genre classification empowered by knowledge-embedded music representation,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2764–2776, 2024
2024
-
[13]
Multimodal music genre classification of sotho-tswana musical videos,
O. E. Oguike and M. Primus, “Multimodal music genre classification of sotho-tswana musical videos,”IEEE Access, 2025
2025
-
[14]
Music genre classification based on functional data analysis,
J. Shen and G. Xiao, “Music genre classification based on functional data analysis,”IEEE Access, 2024
2024
-
[15]
Musical genre classification using advanced audio analysis and deep learning techniques,
M. Ahmed, U. Rozario, M. M. Kabir, Z. Aung, J. Shin, and M. Mridha, “Musical genre classification using advanced audio analysis and deep learning techniques,”IEEE Open Journal of the Computer Society, 2024
2024
-
[16]
Music genre classification using deep neural networks and data augmentation,
T. C. Ba, T. D. T. Le, and L. T. Van, “Music genre classification using deep neural networks and data augmentation,”Entertainment Computing, vol. 53, p. 100929, 2025
2025
-
[17]
Optimizing the configuration of deep learning models for music genre classification,
T. Li, “Optimizing the configuration of deep learning models for music genre classification,”Heliyon, p. e24892, 2024
2024
-
[18]
An improved vit model for music genre classification based on mel spectrogram,
P. Wu, W. Gao, Y . Chen, F. Xu, Y . Ji, J. Tu, and H. Lin, “An improved vit model for music genre classification based on mel spectrogram,”PLOS ONE, vol. 20, no. 3, p. e0319027, 2025
2025
-
[19]
Free-marginal multirater kappa (multirater k [free]): An alternative to fleiss’ fixed-marginal multirater kappa,
J. J. Randolph, “Free-marginal multirater kappa (multirater k [free]): An alternative to fleiss’ fixed-marginal multirater kappa,” Online sub- mission, 2005
2005
-
[20]
Music genre classification using machine learning algorithms: a comparison,
S. Chillara, A. Kavitha, S. A. Neginhal, S. Haldia, and K. Vidyul- latha, “Music genre classification using machine learning algorithms: a comparison,”International Research Journal of Engineering and Technology, vol. 6, no. 5, pp. 851–858, 2019
2019
-
[21]
Music genre classification with convolutional neural networks and comparison with f, q, and mel spectrogram-based images,
A. Dhall, Y . S. Murthy, and S. G. Koolagudi, “Music genre classification with convolutional neural networks and comparison with f, q, and mel spectrogram-based images,” inAdvances in Speech and Music Technology. Springer, 2021, pp. 235–248
2021
-
[22]
Combining cnn and broad learning for music classification,
H. Tang and N. Chen, “Combining cnn and broad learning for music classification,”IEICE Transactions on Information and Systems, vol. 103, no. 3, pp. 695–701, 2020
2020
-
[23]
Music genre classification using machine learning,
A. Ghildiyal, K. Singh, and S. Sharma, “Music genre classification using machine learning,” in2020 4th International Conference on Electronics, Communication and Aerospace Technology (ICECA). IEEE, 2020, pp. 1368–1372
2020
-
[24]
Speech processing for machine learning: Filter banks, mel-frequency cepstral coefficients (mfccs) and what’s in-between,
H. Fayek, “Speech processing for machine learning: Filter banks, mel-frequency cepstral coefficients (mfccs) and what’s in-between,” URL: https://haythamfayek. com/2016/04/21/speech-processingfor- machine-learning. html, 2016
2016
-
[25]
Verification for robustness of chroma feature,
X. Zhang, N. Li, and W. Li, “Verification for robustness of chroma feature,”Computer Science, p. S1, 2014
2014
-
[26]
Deep learning neural networks for music information retrieval,
M. Singh, S. K. Jha, B. Singh, and B. Rajput, “Deep learning neural networks for music information retrieval,” in2021 International Confer- ence on Computational Intelligence and Knowledge Economy (ICCIKE). IEEE, 2021, pp. 500–503
2021
-
[27]
Music genre classification using convolutional neural networks,
S. Pulipati, C. P. Sai, K. S. Krishna, and C. Akhil, “Music genre classification using convolutional neural networks,”Design Engineering, pp. 2727–2732, 2021
2021
-
[28]
Classification of classic turkish music makams,
M. A. Kızrak, K. S. Bayram, and B. Bolat, “Classification of classic turkish music makams,” in2014 IEEE International Symposium on In- novations in Intelligent Systems and Applications (INISTA) Proceedings. IEEE, 2014, pp. 394–397
2014
-
[29]
Music genre classification using mfcc and aann,
R. Thiruvengatanadhan, “Music genre classification using mfcc and aann,”International Research Journal of Engineering and Technology (IRJET), 2018
2018
-
[30]
Automatic music genre detection using artificial neural networks,
P. Mandal, I. Nath, N. Gupta, K. Jha Madhav, G. Ganguly Dev, and S. Pal, “Automatic music genre detection using artificial neural networks,”Intelligent Computing in Engineering, pp. 17–24, 2020
2020
-
[31]
Classification of indian classical music with time-series matching deep learning approach,
A. K. Sharma, G. Aggarwal, S. Bhardwaj, P. Chakrabarti, T. Chakrabarti, J. H. Abawajyet al., “Classification of indian classical music with time-series matching deep learning approach,”IEEE Access, vol. 9, pp. 102 041–102 052, 2021
2021
-
[32]
To catch a chorus: Using chroma- based representations for audio thumbnailing,
M. A. Bartsch and G. H. Wakefield, “To catch a chorus: Using chroma- based representations for audio thumbnailing,” inProceedings of the 2001 IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics (Cat. No. 01TH8575). IEEE, 2001, pp. 15–18
2001
-
[33]
Music emotion recognition in assamese songs using mfcc features and mlp classifier,
J. Dutta and D. Chanda, “Music emotion recognition in assamese songs using mfcc features and mlp classifier,” in2021 International Conference on Intelligent Technologies (CONIT). IEEE, 2021, pp. 1–5
2021
-
[34]
A low latency modular- level deeply integrated mfcc feature extraction architecture for speech recognition,
A. X. Glittas, L. Gopalakrishnanet al., “A low latency modular- level deeply integrated mfcc feature extraction architecture for speech recognition,”Integration, vol. 76, pp. 69–75, 2021
2021
-
[35]
Genre classification and the invariance of mfcc features to key and tempo,
T. L. Li and A. B. Chan, “Genre classification and the invariance of mfcc features to key and tempo,” inInternational Conference on MultiMedia Modeling. Springer, 2011, pp. 317–327
2011
-
[36]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,”Advances in neural informa- tion processing systems, vol. 25, 2012
2012
-
[37]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convo- lutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review arXiv 2017
-
[38]
librosa: Audio and music signal analysis in python
B. McFee, C. Raffel, D. Liang, D. P. Ellis, M. McVicar, E. Battenberg, and O. Nieto, “librosa: Audio and music signal analysis in python.” SciPy, vol. 2015, pp. 18–24, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.