PCA-Driven Adaptive Sensor Triage for Edge AI Inference
Pith reviewed 2026-05-10 19:12 UTC · model grok-4.3
The pith
Incremental PCA loadings can set per-channel sampling rates to keep edge AI inference nearly as accurate as full-bandwidth operation under tight IoT limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
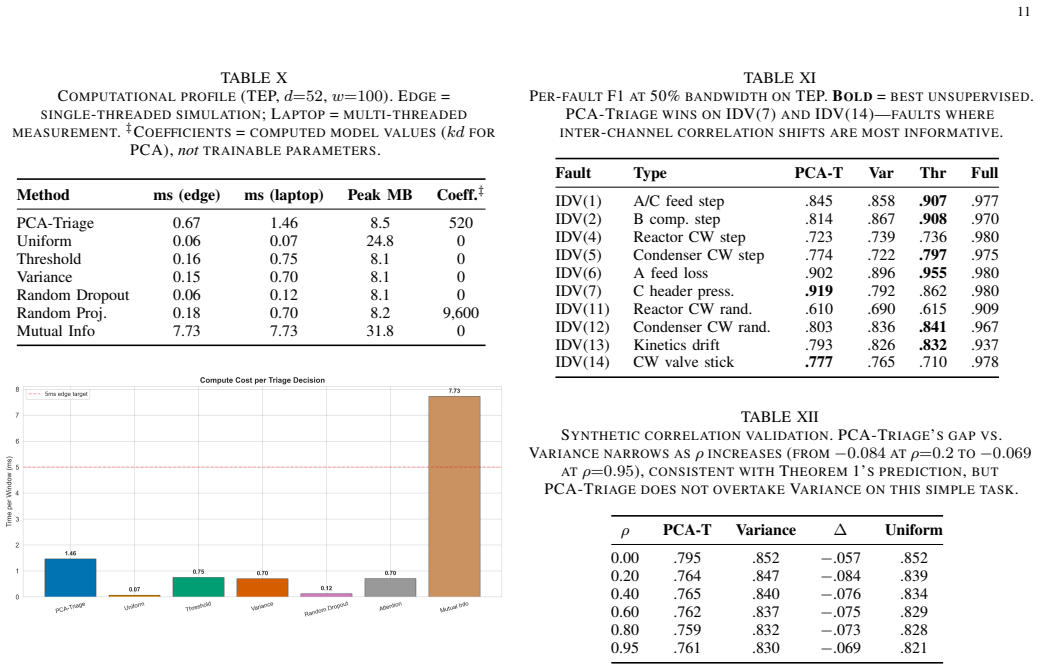
The central claim is that converting absolute loadings from an incremental PCA model on sliding windows of multi-channel readings into normalized per-channel sampling fractions yields a triage policy that preserves most of the information needed by a downstream classifier or detector. On six evaluated datasets at half bandwidth this produces the best unsupervised F1 scores, with large effect sizes against every baseline; on the Tennessee Eastman Process it reaches 0.961 F1, within 0.1 percent of the full-data result, while remaining above 0.90 F1 at 30 percent bandwidth and degrading only 3.7 to 4.8 percent under combined packet loss and noise.
What carries the argument
The PCA-Triage mapping that turns incremental PCA loadings into bandwidth-proportional per-channel sampling rates.
If this is right
- Industrial sensor networks can transmit far less data yet retain high inference quality for anomaly detection and classification.
- The linear-time, zero-parameter design fits directly on edge hardware without retraining when conditions change.
- Performance remains stable under realistic packet loss and sensor noise typical of wireless industrial links.
- Budget reductions to 30 percent still deliver usable accuracy on standard process-control benchmarks.
Where Pith is reading between the lines
- The same loading-to-rate idea could be tested on other high-dimensional streaming sources such as environmental sensor arrays or medical device outputs.
- If downstream task feedback were occasionally available, the triage could be refined by weighting loadings according to observed model error.
- Lower average sampling rates would directly cut transmission energy and storage costs in large-scale IoT deployments.
Load-bearing premise
That the loadings produced by incremental PCA on the sensor streams reliably mark which channels carry the information most relevant to the downstream AI task.
What would settle it
A result on the Tennessee Eastman Process or a similar benchmark in which PCA-Triage at 50 percent bandwidth yields F1 scores no better than uniform random sampling or other simple baselines would disprove the central claim.
Figures












read the original abstract
Multi-channel sensor networks in industrial IoT often exceed available bandwidth. We propose PCA-Triage, a streaming algorithm that converts incremental PCA loadings into proportional per-channel sampling rates under a bandwidth budget. PCA-Triage runs in O(wdk) time with zero trainable parameters (0.67 ms per decision). We evaluate on 7 benchmarks (8--82 channels) against 9 baselines. PCA-Triage is the best unsupervised method on 3 of 6 datasets at 50% bandwidth, winning 5 of 6 against every baseline with large effect sizes (r = 0.71--0.91). On TEP, it achieves F1 = 0.961 +/- 0.001 -- within 0.1% of full-data performance -- while maintaining F1 > 0.90 at 30% budget. Targeted extensions push F1 to 0.970. The algorithm is robust to packet loss and sensor noise (3.7--4.8% degradation under combined worst-case).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PCA-Triage, a streaming, parameter-free algorithm that derives per-channel sampling rates from loadings of incremental PCA on raw multi-channel sensor streams to respect a bandwidth budget while preserving downstream edge AI inference performance. It reports empirical comparisons on 7 benchmarks (8-82 channels) against 9 baselines, claiming PCA-Triage is the best unsupervised method on 3 of 6 datasets at 50% bandwidth, wins 5 of 6 comparisons with large effect sizes, and on the TEP dataset reaches F1=0.961 (within 0.1% of full-data) at 50% budget while staying above 0.90 at 30% budget, with additional robustness results under noise and packet loss.
Significance. If the central assumption holds, the work supplies a lightweight, zero-parameter unsupervised triage method with O(wdk) runtime that could enable practical bandwidth reduction in industrial IoT without retraining. The concrete F1 numbers, large reported effect sizes, and near-full-data performance on TEP constitute a clear empirical contribution; the parameter-free nature and streaming formulation are additional strengths that distinguish it from supervised or heuristic alternatives.
major comments (3)
- [Abstract] Abstract and evaluation section: the claim that PCA-Triage preserves inference-critical information rests on the untested premise that high-variance directions identified by incremental PCA coincide with the features actually used by the downstream model; on fault-detection data such as TEP this alignment is not guaranteed, as normal-operation variance can dominate while faults appear in low-variance subspaces, yet no channel-level ablation, feature-importance comparison, or subspace analysis is supplied to rule out that the method is merely retaining background dynamics.
- [Evaluation] Evaluation section: the reported wins (best unsupervised on 3/6 datasets, F1=0.961±0.001 on TEP) are presented without dataset-specific confirmation that the PCA-selected channels are those the inference model relies upon; because all baselines are also unsupervised, the large effect sizes (r=0.71-0.91) do not address whether the triage is task-aware or merely variance-aware.
- [Method] Method description: although the algorithm is stated to be parameter-free, the precise mapping from PCA loadings to sampling rates (including any normalization, clipping, or budget allocation rule) is not given in sufficient detail to reproduce the exact per-channel rates or to verify that no hidden thresholds are introduced.
minor comments (2)
- [Abstract] Abstract: the text refers to '7 benchmarks' yet reports results on '3 of 6 datasets'; clarify the exact dataset count and which subset is used for the 'best unsupervised' summary statistic.
- [Evaluation] Evaluation: the nine baselines and their hyper-parameter settings are not enumerated; a table listing each baseline, its supervision type, and any tuning protocol would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each of the major points raised and indicate the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation section: the claim that PCA-Triage preserves inference-critical information rests on the untested premise that high-variance directions identified by incremental PCA coincide with the features actually used by the downstream model; on fault-detection data such as TEP this alignment is not guaranteed, as normal-operation variance can dominate while faults appear in low-variance subspaces, yet no channel-level ablation, feature-importance comparison, or subspace analysis is supplied to rule out that the method is merely retaining background dynamics.
Authors: We agree with the referee that PCA-Triage is fundamentally a variance-based unsupervised method and does not guarantee selection of inference-critical channels, particularly in scenarios like TEP where faults may reside in lower-variance directions. Our claims in the abstract and evaluation are strictly empirical: the method achieves F1 scores close to full-data performance across the tested benchmarks. We do not assert that it preserves 'inference-critical information' in a theoretical sense but rather that it maintains downstream performance in practice. The absence of channel-level ablations or subspace analyses means we cannot fully rule out retention of background dynamics; this is a valid limitation of the current evaluation. In the revised version, we will add a dedicated paragraph in the discussion section acknowledging this and clarifying the unsupervised, task-agnostic design of the algorithm. revision: partial
-
Referee: [Evaluation] Evaluation section: the reported wins (best unsupervised on 3/6 datasets, F1=0.961+/-0.001 on TEP) are presented without dataset-specific confirmation that the PCA-selected channels are those the inference model relies upon; because all baselines are also unsupervised, the large effect sizes (r=0.71-0.91) do not address whether the triage is task-aware or merely variance-aware.
Authors: The evaluation is designed to compare against other unsupervised triage methods, as PCA-Triage operates without access to the downstream model or task labels. The reported wins and large effect sizes demonstrate that our approach outperforms alternative unsupervised strategies in preserving inference performance. We acknowledge that this does not prove the triage is task-aware rather than variance-aware, and without model-specific feature importance, we cannot confirm alignment on a per-dataset basis. However, the near-full-data F1 on TEP (0.961) provides strong evidence of practical effectiveness. We will revise the evaluation section to explicitly state that the method is task-agnostic by construction and that the comparisons are among unsupervised techniques. revision: partial
-
Referee: [Method] Method description: although the algorithm is stated to be parameter-free, the precise mapping from PCA loadings to sampling rates (including any normalization, clipping, or budget allocation rule) is not given in sufficient detail to reproduce the exact per-channel rates or to verify that no hidden thresholds are introduced.
Authors: We appreciate this observation and agree that the mapping details were insufficiently specified. The algorithm computes per-channel sampling rates as r_i = min(1, max(0, |loading_i| / sum(|loadings|)) * budget), where loadings are from the first principal component of incremental PCA, with no additional thresholds. In the revised manuscript, we will include this exact formulation in the method section, along with pseudocode, to ensure full reproducibility. revision: yes
- Providing channel-level ablation studies or subspace analyses to directly verify alignment between PCA loadings and downstream model features on datasets like TEP.
Circularity Check
No circularity: parameter-free algorithm with empirical validation
full rationale
The paper defines PCA-Triage as a streaming conversion of incremental PCA loadings into per-channel sampling rates under a fixed bandwidth budget, with explicit O(wdk) complexity and zero trainable parameters. No equations or steps reduce a claimed prediction or result to a fitted input by construction. Performance claims rest on direct comparisons to external baselines across independent datasets rather than self-referential definitions or load-bearing self-citations. The central mapping from loadings to rates is presented as a direct, unsupervised heuristic without hidden fitting or uniqueness theorems imported from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Incremental PCA loadings on streaming sensor data reflect relative channel importance for the downstream inference task
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The importance score for channel j: s_j = Σ_i σ_i · V_ij² (Eq. 2). ... Rates are then allocated as: r_j = r_min + s̃_j · (B·d − r_min·d) (Eq. 6).
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PCA-Triage runs in O(w d k) time with zero trainable parameters (0.67 ms per decision).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Research on fault detection of Tennessee Eastman process based on PCA,
D. Chen, Z. Li, and Z. He, “Research on fault detection of Tennessee Eastman process based on PCA,” inChinese Control and Decision Conference (CCDC), 2013
work page 2013
-
[2]
Data-driven process monitoring and fault diagnosis: A comprehensive survey,
R. P. Monteiroet al., “Data-driven process monitoring and fault diagnosis: A comprehensive survey,”Processes, vol. 12, no. 2, p. 251, 2024
work page 2024
-
[3]
A plant-wide industrial process control problem,
J. J. Downs and E. F. V ogel, “A plant-wide industrial process control problem,”Computers & Chemical Engineering, vol. 17, no. 3, pp. 245– 255, 1993
work page 1993
-
[4]
Candid covariance-free incre- mental principal component analysis,
J. Weng, Y . Zhang, and W.-S. Hwang, “Candid covariance-free incre- mental principal component analysis,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 25, no. 8, pp. 1034–1040, 2003
work page 2003
-
[5]
Online identification and tracking of subspaces from highly incomplete information,
L. Balzano, R. Nowak, and B. Recht, “Online identification and tracking of subspaces from highly incomplete information,”arXiv preprint arXiv:1006.4046, 2010
-
[6]
History PCA: A new algorithm for streaming PCA,
P. Yang, C.-J. Hsieh, and J.-L. Wang, “History PCA: A new algorithm for streaming PCA,”arXiv preprint arXiv:1802.05447, 2018
-
[7]
On adaptive sampling algorithms for IoT devices,
Y . Ben-Aboud, D. Bonilla Licea, M. Ghogho, and A. Kobbane, “On adaptive sampling algorithms for IoT devices,” inIEEE International Conference on Communications (ICC), 2021
work page 2021
-
[8]
Energy-aware adaptive sampling for self-sustainability in resource-constrained IoT devices,
M. Giordano, S. Cortesi, P.-V . Mekikiset al., “Energy-aware adaptive sampling for self-sustainability in resource-constrained IoT devices,” in ACM ENSsys Workshop, 2023
work page 2023
-
[9]
Additional Tennessee Eastman process simulation data for anomaly detection evaluation,
C. A. Rieth, B. D. Amsel, R. Tran, and M. B. Cook, “Additional Tennessee Eastman process simulation data for anomaly detection evaluation,” Harvard Dataverse, 2017
work page 2017
-
[10]
Feature selection for fault detection systems: Application to the Tennessee Eastman process,
B. Mnassriet al., “Feature selection for fault detection systems: Application to the Tennessee Eastman process,”Applied Intelligence, vol. 44, no. 1, 2015
work page 2015
-
[11]
Simplified neuron model as a principal component analyzer,
E. Oja, “Simplified neuron model as a principal component analyzer,” Journal of Mathematical Biology, vol. 15, no. 3, pp. 267–273, 1982
work page 1982
-
[12]
Streaming PCA and subspace tracking: The missing data case,
L. Balzano, Y . Chi, and Y . M. Lu, “Streaming PCA and subspace tracking: The missing data case,”Proceedings of the IEEE, vol. 106, no. 8, pp. 1293–1310, 2018
work page 2018
-
[13]
S. Dasgupta, S. Kumar, and S. Pandey, “Low-precision streaming PCA,” inAISTATS, 2025
work page 2025
-
[14]
Incremental learning for robust visual tracking,
D. A. Ross, J. Lim, R.-S. Lin, and M.-H. Yang, “Incremental learning for robust visual tracking,”International Journal of Computer Vision, vol. 77, no. 1–3, pp. 125–141, 2008
work page 2008
-
[15]
Sequential Karhunen-Loeve basis extraction and its application to images,
A. Levy and M. Lindenbaum, “Sequential Karhunen-Loeve basis extraction and its application to images,”IEEE Transactions on Image Processing, vol. 9, no. 8, pp. 1371–1374, 2000
work page 2000
-
[16]
N. Halko, P.-G. Martinsson, and J. A. Tropp, “Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions,”SIAM Review, vol. 53, no. 2, pp. 217–288, 2011
work page 2011
-
[17]
Streaming feature selection using alpha-investing,
J. Zhou, D. P. Foster, R. A. Stine, and L. H. Ungar, “Streaming feature selection using alpha-investing,”JMLR, 2006
work page 2006
-
[18]
Scalable and accurate online feature selection for big data,
K. Yu, X. Wu, W. Ding, and J. Pei, “Scalable and accurate online feature selection for big data,”ACM Transactions on Knowledge Discovery from Data, 2014
work page 2014
-
[19]
Online feature selection with streaming features,
X. Wu, K. Yu, W. Ding, H. Wang, and X. Zhu, “Online feature selection with streaming features,” inIEEE Transactions on Pattern Analysis and Machine Intelligence, 2013
work page 2013
-
[20]
Online feature selection for streaming features with high redundancy using sliding- window sampling,
D. You, X. Wu, L. Shen, Z. Chen, C. Ma, and S. Deng, “Online feature selection for streaming features with high redundancy using sliding- window sampling,” inIEEE International Conference on Big Knowledge (ICBK), 2018. 1https://github.com/ankitlade12/pca-sensor-triage
work page 2018
-
[21]
Feature selection for online streaming high-dimensional data: A state-of-the-art review,
E. A. K. Zaman, A. Mohamed, and A. Ahmad, “Feature selection for online streaming high-dimensional data: A state-of-the-art review,” Applied Soft Computing, vol. 127, 2022
work page 2022
-
[22]
Online stable streaming feature selection via feature aggregation,
P. Zhou, Q. Wang, Y . Zhang, Z. Ling, S. Zhao, and X. Wu, “Online stable streaming feature selection via feature aggregation,”ACM Transactions on Knowledge Discovery from Data, vol. 19, no. 3, 2025
work page 2025
-
[23]
Parametric machine learning-based adaptive sampling algorithm for efficient IoT data collection,
W. Li, Y . Zhang, and J. Wang, “Parametric machine learning-based adaptive sampling algorithm for efficient IoT data collection,”Journal of Network and Systems Management, 2024
work page 2024
-
[24]
Application of compressive sensing techniques in distributed sensor networks,
R. Rana, C. T. Yang, and W. Abdulla, “Application of compressive sensing techniques in distributed sensor networks,”arXiv preprint arXiv:1709.10401, 2017
-
[25]
Edge AI: A taxonomy, sys- tematic review and future directions,
S. S. Gill, M. Golec, J. Hu, M. Xuet al., “Edge AI: A taxonomy, sys- tematic review and future directions,”arXiv preprint arXiv:2407.04053, 2024
-
[26]
A multiattention-based supervised feature selection method for multivariate time series,
L. Cao, Y . Chen, Z. Zhang, and N. Gui, “A multiattention-based supervised feature selection method for multivariate time series,”Com- putational Intelligence and Neuroscience, 2021
work page 2021
-
[27]
H. Kim, D. Lee, and S. Kim, “Transformer-based multivariate time series anomaly detection using inter-variable attention mechanism,”Knowledge- Based Systems, 2024
work page 2024
-
[28]
DCFF-MTAD: A multivariate time- series anomaly detection model based on dual-channel feature fusion,
Z. Xu, Y . Yang, X. Gao, and M. Hu, “DCFF-MTAD: A multivariate time- series anomaly detection model based on dual-channel feature fusion,” Sensors, vol. 23, no. 8, 2023
work page 2023
-
[29]
Unsupervised feature selection for sensor time-series in per- vasive computing applications,
D. Bacciu, “Unsupervised feature selection for sensor time-series in per- vasive computing applications,” inNeural Computing and Applications, 2016
work page 2016
-
[30]
Learning-based adaptive sensor selection framework for multi-sensing WSN,
A. Ghosh, S. D. Ghosh, and S. De, “Learning-based adaptive sensor selection framework for multi-sensing WSN,”IEEE Sensors Journal, vol. 21, no. 14, pp. 16 209–16 221, 2021
work page 2021
-
[31]
Edge intelligence framework for data-driven dynamic priority sensing and transmission,
A. Ghosh, A. Chatterjee, and D. Chatterjee, “Edge intelligence framework for data-driven dynamic priority sensing and transmission,”IEEE Transactions on Green Communications and Networking, 2021
work page 2021
-
[32]
Adaptive sampling-rate selection for resource-constrained IoT sensors,
C. Yanget al., “Adaptive sampling-rate selection for resource-constrained IoT sensors,”Sensors, 2023
work page 2023
-
[33]
Robust anomaly detection for multivariate time series through stochastic recurrent neural network,
Y . Su, Y . Zhao, C. Niu, R. Liu, W. Sun, and D. Pei, “Robust anomaly detection for multivariate time series through stochastic recurrent neural network,” inKDD, 2019
work page 2019
-
[34]
Detecting spacecraft anomalies using LSTMs and nonparametric dynamic thresholding,
K. Hundman, V . Constantinou, C. Laporte, I. Colwell, and T. Söderström, “Detecting spacecraft anomalies using LSTMs and nonparametric dynamic thresholding,” inKDD, 2018
work page 2018
-
[35]
Practical approach to asyn- chronous multivariate time series anomaly detection and localization,
A. Abdulaal, Z. Liu, and T. Lancewicki, “Practical approach to asyn- chronous multivariate time series anomaly detection and localization,” in KDD, 2021
work page 2021
-
[36]
HAI 1.0: HIL-based augmented ICS security dataset,
H.-K. Shin, W. Lee, J.-H. Yun, and H. Kim, “HAI 1.0: HIL-based augmented ICS security dataset,” inUSENIX CSET Workshop, 2020
work page 2020
-
[37]
L. Breiman, “Random forests,”Machine Learning, vol. 45, no. 1, pp. 5–32, 2001
work page 2001
-
[38]
Scikit-learn: Machine learning in Python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michelet al., “Scikit-learn: Machine learning in Python,”Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011
work page 2011
-
[39]
Individual comparisons by ranking methods,
F. Wilcoxon, “Individual comparisons by ranking methods,”Biometrics Bulletin, vol. 1, no. 6, pp. 80–83, 1945
work page 1945
-
[40]
The use of ranks to avoid the assumption of normality implicit in the analysis of variance,
M. Friedman, “The use of ranks to avoid the assumption of normality implicit in the analysis of variance,”Journal of the American Statistical Association, vol. 32, no. 200, pp. 675–701, 1937
work page 1937
-
[41]
Statistical comparisons of classifiers over multiple data sets,
J. Demšar, “Statistical comparisons of classifiers over multiple data sets,” Journal of Machine Learning Research, vol. 7, pp. 1–30, 2006
work page 2006
-
[42]
Galli,Feature Selection in Machine Learning with Python
S. Galli,Feature Selection in Machine Learning with Python. Leanpub, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.