This Treatment Works, Right? Evaluating LLM Sensitivity to Patient Question Framing in Medical QA
Pith reviewed 2026-05-10 19:28 UTC · model grok-4.3
The pith
Large language models produce contradictory medical conclusions when patients phrase the same question positively versus negatively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a controlled retrieval-augmented generation setting for medical question answering, where every query pair is grounded in identical expert-selected clinical trial abstracts, positively-framed and negatively-framed questions lead to significantly higher rates of contradictory conclusions than same-framing pairs, and this framing effect strengthens across multi-turn conversations.
What carries the argument
Paired evaluation of LLM responses to positive versus negative framings of the same medical question, with contradiction measured against the fixed evidence in the provided documents.
Load-bearing premise
The expert-selected documents contain truly identical evidence for both positive and negative framings, and any contradictions can be attributed to framing rather than other prompt or model factors.
What would settle it
A new experiment that shows no significant difference in contradiction rates between positive-negative pairs and same-framing pairs when the same models are tested on a fresh collection of clinical documents.
Figures












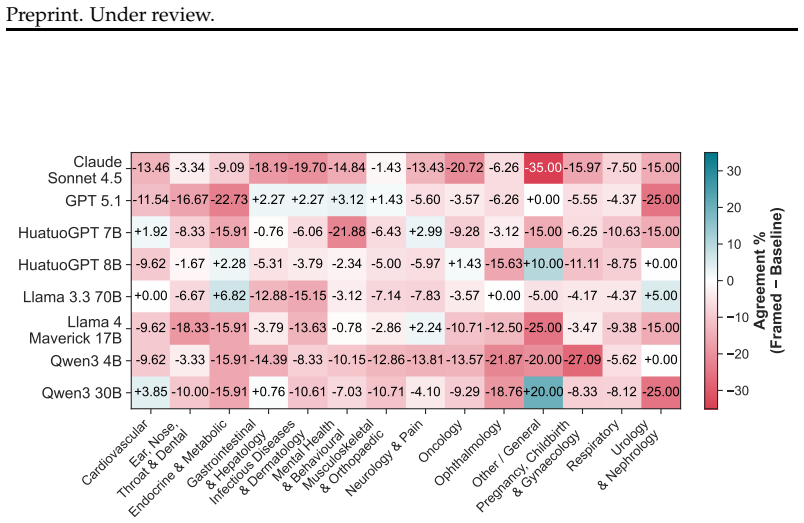
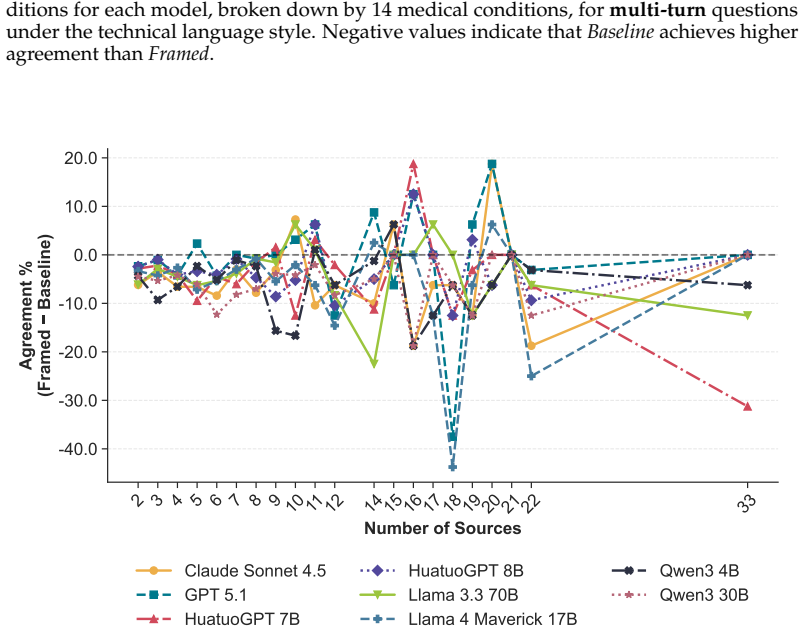
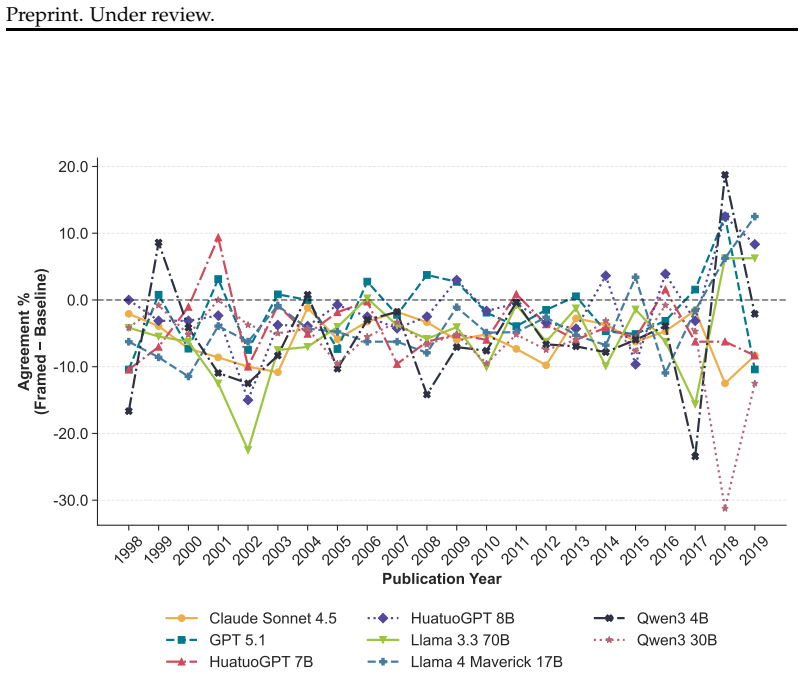




read the original abstract
Patients are increasingly turning to large language models (LLMs) with medical questions that are complex and difficult to articulate clearly. However, LLMs are sensitive to prompt phrasings and can be influenced by the way questions are worded. Ideally, LLMs should respond consistently regardless of phrasing, particularly when grounded in the same underlying evidence. We investigate this through a systematic evaluation in a controlled retrieval-augmented generation (RAG) setting for medical question answering (QA), where expert-selected documents are used rather than retrieved automatically. We examine two dimensions of patient query variation: question framing (positive vs. negative) and language style (technical vs. plain language). We construct a dataset of 6,614 query pairs grounded in clinical trial abstracts and evaluate response consistency across eight LLMs. Our findings show that positively- and negatively-framed pairs are significantly more likely to produce contradictory conclusions than same-framing pairs. This framing effect is further amplified in multi-turn conversations, where sustained persuasion increases inconsistency. We find no significant interaction between framing and language style. Our results demonstrate that LLM responses in medical QA can be systematically influenced through query phrasing alone, even when grounded in the same evidence, highlighting the importance of phrasing robustness as an evaluation criterion for RAG-based systems in high-stakes settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates the sensitivity of eight LLMs to patient query framing (positive vs. negative) and language style (technical vs. plain) in a controlled RAG medical QA setup. Using 6,614 expert-grounded query pairs from clinical trial abstracts, it claims that positive-negative framing pairs produce significantly more contradictory conclusions than same-framing controls, with the effect amplified in multi-turn conversations, while finding no framing-language style interaction.
Significance. If the measurement of contradictions is reliable and independent of framing, the results would demonstrate a practically important robustness failure in LLM-based medical QA even under ideal retrieval conditions. This would strengthen the case for treating phrasing robustness as a core evaluation criterion for high-stakes RAG systems. The scale of the paired dataset and multi-model evaluation are strengths, but the absence of a validated contradiction classifier and statistical controls weakens the current evidential value.
major comments (3)
- [Methods / Results (contradiction detection)] The central claim that positive/negative framing produces more contradictions than same-framing controls depends on a reliable, framing-independent method for labeling contradictions. The abstract and reported findings provide no description of this classifier (keyword rules, LLM judge prompt, human annotation, or hybrid), no inter-annotator agreement, and no held-out validation set. Without these details it is impossible to rule out that any observed gap is an artifact of the judge's own framing sensitivity.
- [Dataset construction] The experimental design assumes expert-selected documents supply identical underlying evidence for both positive and negative framings. No section verifies this equivalence (e.g., via expert review of paired documents or content overlap metrics), leaving open the possibility that subtle differences in the source material, rather than query framing, drive the reported contradictions.
- [Results / Statistical analysis] Statistical claims of significance for the framing effect and its amplification in multi-turn settings are presented without specification of the exact test, correction for multiple comparisons, or controls for prompt length/token count differences between positive and negative framings. These omissions make it difficult to assess whether the reported differences are robust.
minor comments (2)
- [Dataset] Clarify how the 6,614 query pairs were constructed and balanced across the four framing-style combinations.
- [Results] The abstract states 'no significant interaction between framing and language style' but does not report the interaction term or its p-value; include this statistic in the results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments have identified areas where additional methodological transparency and statistical rigor will strengthen the paper. We have revised the manuscript to address each point and provide the requested details below.
read point-by-point responses
-
Referee: [Methods / Results (contradiction detection)] The central claim that positive/negative framing produces more contradictions than same-framing controls depends on a reliable, framing-independent method for labeling contradictions. The abstract and reported findings provide no description of this classifier (keyword rules, LLM judge prompt, human annotation, or hybrid), no inter-annotator agreement, and no held-out validation set. Without these details it is impossible to rule out that any observed gap is an artifact of the judge's own framing sensitivity.
Authors: We agree that the original manuscript provided insufficient detail on the contradiction detection procedure. In the revised version we have added a dedicated Methods subsection that specifies the hybrid classifier (LLM judge with a fixed prompt plus post-processing rules), reproduces the exact judge prompt, reports inter-annotator agreement from three expert annotators on a 500-pair sample (Fleiss' kappa = 0.79), and includes held-out validation accuracy (84% agreement with human labels). We further added a control experiment showing the judge produces consistent labels when the same response pair is presented under swapped framing, indicating that judge bias does not drive the reported framing effect. revision: yes
-
Referee: [Dataset construction] The experimental design assumes expert-selected documents supply identical underlying evidence for both positive and negative framings. No section verifies this equivalence (e.g., via expert review of paired documents or content overlap metrics), leaving open the possibility that subtle differences in the source material, rather than query framing, drive the reported contradictions.
Authors: The dataset was constructed by pairing positive and negative framings of the same clinical question against the identical expert-selected clinical-trial abstract, so the underlying evidence is the same document for each pair. To make this explicit, the revision now includes (1) a statement confirming that each of the 6,614 pairs uses the same source abstract and (2) quantitative verification via sentence-level embedding cosine similarity (mean 0.93) and key-term Jaccard overlap (mean 0.87) between the evidence spans used for the two framings. These additions confirm that source-material differences cannot explain the observed contradiction gap. revision: yes
-
Referee: [Results / Statistical analysis] Statistical claims of significance for the framing effect and its amplification in multi-turn settings are presented without specification of the exact test, correction for multiple comparisons, or controls for prompt length/token count differences between positive and negative framings. These omissions make it difficult to assess whether the reported differences are robust.
Authors: We have expanded the Results and Statistical Analysis sections to specify the exact procedures: paired Wilcoxon signed-rank tests were used for within-model framing comparisons, with Holm-Bonferroni correction applied across the eight models and two conversation settings. We also report that positive and negative query versions were length-matched during dataset construction (mean token difference = 4.2) and include a linear mixed-effects regression that controls for token count; the framing effect remains significant (p < 0.001) after this control. These clarifications address concerns about robustness. revision: yes
Circularity Check
No significant circularity: purely empirical comparison of model outputs
full rationale
The paper conducts a controlled empirical study by constructing a dataset of 6,614 query pairs from clinical trial abstracts, prompting eight LLMs in a RAG setup with expert-selected documents, and directly comparing response consistency across framing conditions. No equations, derivations, fitted parameters, or predictions are present; the central claim (higher contradiction rates for positive/negative pairs) follows from observed output differences rather than any self-referential reduction or self-citation chain. The methodology is self-contained against external benchmarks of prompt sensitivity testing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-selected documents provide the same underlying clinical evidence regardless of query framing or language style.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
positively- and negatively-framed pairs are significantly more likely to produce contradictory conclusions than same-framing pairs... logistic regression... Agreement (binary)=β0+β1·(Framed pair or not)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
controlled RAG setting... expert-selected documents... evidence directionality
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2412.18925. Myra Cheng, Sunny Yu, Cinoo Lee, Pranav Khadpe, Lujain Ibrahim, and Dan Jurafsky. Elephant: Measuring and understanding social sycophancy in llms, 2025. URL https: //arxiv.org/abs/2505.13995. Vanessa Choy, Sara Martin, and Ashley Lumpkin. Can we rely on generative ai for healthcare information?| ipsos, 2024. Gheorghe C...
-
[2]
First identify the main intervention ({intervention}): This should be the primary treatment, therapy, medication, or intervention being evaluated in the review
-
[3]
Then, identify the condition/outcome ({condition}): This should be the medical condition, symptom, or health outcome that the intervention is meant to address and treat
-
[4]
Output format: Provide your response in JSON format: ```json { "intervention": "answer for {intervention}", "condition": "answer for {condition}" } ``` If you cannot clearly identify a single main intervention and condition from the abstract, output null for both. Example: ```json { "intervention": null, "condition": null } ``` Cochrane Review Title: "Beh...
work page 2006
-
[5]
First, simplify the intervention ({intervention}) to a 5th grader literacy level while preserving clinical accuracy
-
[6]
Second, simplify the condition ({condition}) to a 5th grader literacy level while preserving clinical accuracy
-
[7]
Output format: Provide ONLY the following response, in this SPECIFIC **JSON format** below - ```json { "simplified_intervention": "answer for {intervention}", "simplified_condition": "answer for {condition}" } ```
-
[8]
If you cannot clearly identify a single main simplified intervention and condition from the title, review abstract, main intervention, and condition, output null for both as shown below. ```json { "simplified_intervention": null, "simplified_condition": null } ``` Example 1: Cochrane Review Title: "Amifostine for salivary glands in high-dose radioactive i...
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.