Recognition: no theorem link
Improving Sparse Memory Finetuning
Pith reviewed 2026-05-10 18:47 UTC · model grok-4.3
The pith
Sparse memory modules with KL-based slot selection let LLMs learn new facts while preserving most prior capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adding sparse memory modules to an existing model and selecting update slots through KL divergence on tokens that deviate from a background distribution, the retrofitted model acquires new factual knowledge while exhibiting minimal forgetting of held-out capabilities.
What carries the argument
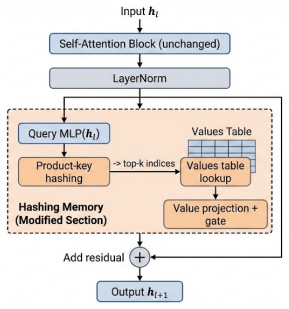
KL-divergence slot-selection mechanism that routes memory updates to tokens whose output distribution differs most from a background distribution.
If this is right
- Continual adaptation becomes feasible on consumer hardware without retraining the entire model.
- New knowledge can be added incrementally while old task performance stays largely intact.
- Sparse memory provides a practical way to test the hypothesis that localized updates reduce interference.
- The approach extends prior sparse finetuning work by grounding slot choice in an information-theoretic criterion.
Where Pith is reading between the lines
- The same slot-selection logic could be applied to larger models or to sequences of tasks that arrive over time.
- Hybrid systems might combine sparse memory for facts with dense layers for reasoning patterns.
- Measuring the actual sparsity achieved and the compute saved would clarify scalability limits.
Load-bearing premise
That choosing memory slots by KL divergence on surprising tokens reliably isolates new information from the rest of the model's knowledge.
What would settle it
An experiment in which the retrofitted model is trained on new facts and then shows large drops in accuracy on the held-out capability tests compared with the unmodified model.
Figures




read the original abstract
Large Language Models (LLMs) are typically static after training, yet real-world applications require continual adaptation to new knowledge without degrading existing capabilities. Standard approaches to updating models, like full finetuning or parameter-efficient methods (e.g., LoRA), face a fundamental trade-off: catastrophic forgetting. They modify shared dense representations, causing interference across tasks. Sparse Memory Finetuning (SMF) offers a promising alternative by localizing updates to a small subset of parameters in explicit memory layers. In this work, we present an open-source pipeline to retrofit existing pretrained models (Qwen-2.5-0.5B) with sparse memory modules, enabling effective continual learning on consumer hardware. We extend prior work by introducing a theoretically grounded slot-selection mechanism based on Kullback-Leibler (KL) divergence, which prioritizes memory updates for informationally "surprising" tokens relative to a background distribution. Our experiments demonstrate that our retrofitted models can acquire new factual knowledge with minimal forgetting of held-out capabilities, validating the sparse update hypothesis in a practical setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Sparse Memory Finetuning (SMF) to retrofit pretrained LLMs (e.g., Qwen-2.5-0.5B) with explicit sparse memory layers, using a KL-divergence slot-selection mechanism to localize updates to informationally surprising tokens. It presents an open-source pipeline for continual learning on consumer hardware and claims that experiments show new factual knowledge can be acquired with minimal forgetting of held-out capabilities, thereby validating the sparse update hypothesis in practice.
Significance. If substantiated, the work would offer a practical, hardware-efficient route to continual adaptation of LLMs that avoids the interference inherent in dense updates. The open-source pipeline and focus on sparse localization are strengths that could support reproducibility and further research on the sparse-update hypothesis.
major comments (2)
- [Abstract] Abstract: the central claim that 'our experiments demonstrate that our retrofitted models can acquire new factual knowledge with minimal forgetting of held-out capabilities' supplies no quantitative metrics, baselines, error bars, data-split details, or held-out capability definitions. This absence is load-bearing because the validation of the sparse-update hypothesis rests entirely on the experimental outcome.
- [Slot-selection mechanism] Slot-selection mechanism: the KL-divergence rule is described as 'theoretically grounded' and as prioritizing 'surprising' tokens relative to a background distribution, yet no derivation, optimality argument, or comparison against alternatives (random selection, entropy, gradient magnitude) is supplied. This is load-bearing because the pipeline's value proposition is precisely the effective localization enabled by this choice; without evidence that KL outperforms simpler criteria, the contribution of the mechanism to minimal forgetting remains unisolated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and have revised the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'our experiments demonstrate that our retrofitted models can acquire new factual knowledge with minimal forgetting of held-out capabilities' supplies no quantitative metrics, baselines, error bars, data-split details, or held-out capability definitions. This absence is load-bearing because the validation of the sparse-update hypothesis rests entirely on the experimental outcome.
Authors: We agree that the abstract would be strengthened by including quantitative support for the central claim. In the revised manuscript, we have updated the abstract to summarize the key experimental metrics, including performance on new factual knowledge, forgetting rates on held-out capabilities, baseline comparisons, data-split details, and held-out task definitions. These elements were reported in the experiments section of the original submission and are now also reflected in the abstract. revision: yes
-
Referee: [Slot-selection mechanism] Slot-selection mechanism: the KL-divergence rule is described as 'theoretically grounded' and as prioritizing 'surprising' tokens relative to a background distribution, yet no derivation, optimality argument, or comparison against alternatives (random selection, entropy, gradient magnitude) is supplied. This is load-bearing because the pipeline's value proposition is precisely the effective localization enabled by this choice; without evidence that KL outperforms simpler criteria, the contribution of the mechanism to minimal forgetting remains unisolated.
Authors: We acknowledge that the original manuscript provided only a high-level motivation for the KL-divergence slot-selection without a full derivation or direct comparisons. In the revision, we have added a dedicated subsection deriving the criterion from information-theoretic principles and included ablation studies comparing it to random selection, entropy, and gradient-magnitude alternatives. These additions isolate the contribution of the KL mechanism to localization and reduced forgetting. revision: yes
Circularity Check
No significant circularity; empirical validation stands independent of inputs.
full rationale
The paper describes an empirical pipeline for retrofitting LLMs with sparse memory modules and reports experimental outcomes on new fact acquisition with minimal forgetting. The KL-based slot-selection is labeled 'theoretically grounded' but no equations, derivations, or parameter-fitting steps are shown that reduce the claimed results to the selection rule by construction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim rests on held-out capability measurements rather than a closed mathematical chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Memory Layers at Scale
Vincent-Pierre Berges et al. “Memory Layers at Scale”. In:F orty-second International Con- ference on Machine Learning. 2025.URL: https : / / openreview . net / forum ? id = ATqGm1WyDj
2025
-
[2]
On Tiny Episodic Memories in Continual Learning
Arslan Chaudhry et al. “On Tiny Episodic Memories in Continual Learning”. In:Proceedings of the Workshop on Continual Learning at CVPR. 2019
2019
-
[3]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu et al. “LoRA: Low-Rank Adaptation of Large Language Models”. In:Interna- tional Conference on Learning Representations. 2022.URL: https://openreview.net/ forum?id=nZeVKeeFYf9
2022
- [4]
-
[5]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. In:Advances in Neural Information Processing Systems. V ol. 33. 2020, pp. 9459–9474
2020
-
[6]
Patrick Lewis et al.Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
-
[7]
arXiv:2005.11401 [cs.CL].URL:https://arxiv.org/abs/2005.11401
work page internal anchor Pith review arXiv 2005
- [8]
-
[9]
Yun Luo et al. “An empirical study of catastrophic forgetting in large language models during continual fine-tuning”. In:arXiv preprint arXiv:2308.08747(2023)
-
[10]
End-To-End Memory Networks
Sainbayar Sukhbaatar, Jason Weston, and Rob Fergus. “End-To-End Memory Networks”. In: Advances in Neural Information Processing Systems. V ol. 28. 2015
2015
-
[11]
Sikuan Yan et al.Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning. 2025. arXiv: 2508.19828 [cs.CL] .URL: https://arxiv.org/abs/2508.19828. 8
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.