Training Without Orthogonalization, Inference With SVD: A Gradient Analysis of Rotation Representations
Pith reviewed 2026-05-10 19:28 UTC · model grok-4.3
The pith
SVD orthogonalization distorts gradients during training of rotation matrices, with distortion worst early on when matrices lie far from SO(3).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
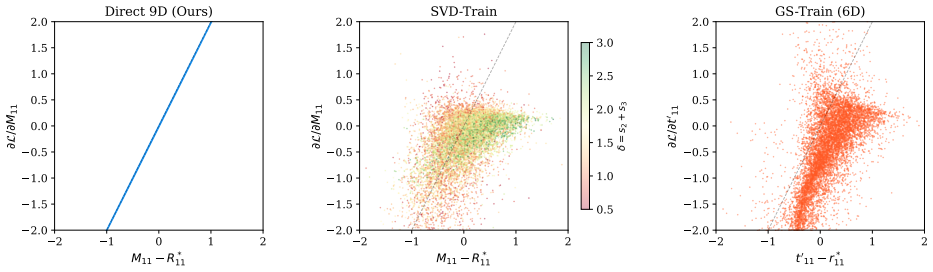
Our central result derives the exact spectrum of the SVD backward pass Jacobian: it has rank 3 (matching the dimension of SO(3)) with nonzero singular values 2/(s_i + s_j) and condition number κ = (s_1 + s_2)/(s_2 + s_3), creating quantifiable gradient distortion that is most severe when the predicted matrix is far from SO(3) (e.g., early in training when s_3 ≈ 0). We further show that even stabilized SVD gradients introduce gradient direction error, whereas removing SVD from the training loop avoids this tradeoff entirely. We also prove that the 6D Gram-Schmidt Jacobian has an asymmetric spectrum: its parameters receive unequal gradient signal, explaining why 9D parameterization is prefera
What carries the argument
The SVD backward-pass Jacobian for 3x3 matrices projected onto SO(3), whose singular values 2/(s_i + s_j) set the gradient scaling factors and whose condition number measures the resulting distortion.
If this is right
- Direct 9D regression during training sidesteps all SVD-induced gradient distortion.
- Applying SVD projection only at inference supplies orthogonal rotations without harming the training dynamics.
- 9D representations are preferable to 6D ones because the Gram-Schmidt Jacobian on 6D inputs gives unequal gradient magnitudes to its parameters.
- Stabilizing the SVD gradients does not remove directional error in the back-propagated signal.
Where Pith is reading between the lines
- Similar spectral analysis could be applied to other manifold-projection layers to detect training-time gradient pathologies before they appear in experiments.
- Tracking the smallest singular value of the predicted matrix during training would give an online estimate of the instantaneous gradient condition number.
- The same reasoning may extend to rotation groups in higher dimensions once the corresponding Jacobian spectrum is derived.
Load-bearing premise
The derived spectrum and condition-number formula assume SVD is performed on 3x3 matrices whose projection target is the SO(3) manifold.
What would settle it
Compute or measure the singular values of the actual backward Jacobian on a 3x3 input matrix whose singular values s1 > s2 > s3 are known; the nonzero values should equal 2/(si + sj) and the condition number should equal (s1 + s2)/(s2 + s3).
Figures



read the original abstract
Recent work has shown that removing orthogonalization during training and applying it only at inference improves rotation estimation in deep learning, with empirical evidence favoring 9D representations with SVD projection. However, the theoretical understanding of why SVD orthogonalization specifically harms training, and why it should be preferred over Gram-Schmidt at inference, remains incomplete. We provide a detailed gradient analysis of SVD orthogonalization specialized to $3 \times 3$ matrices and $SO(3)$ projection. Our central result derives the exact spectrum of the SVD backward pass Jacobian: it has rank $3$ (matching the dimension of $SO(3)$) with nonzero singular values $2/(s_i + s_j)$ and condition number $\kappa = (s_1 + s_2)/(s_2 + s_3)$, creating quantifiable gradient distortion that is most severe when the predicted matrix is far from $SO(3)$ (e.g., early in training when $s_3 \approx 0$). We further show that even stabilized SVD gradients introduce gradient direction error, whereas removing SVD from the training loop avoids this tradeoff entirely. We also prove that the 6D Gram-Schmidt Jacobian has an asymmetric spectrum: its parameters receive unequal gradient signal, explaining why 9D parameterization is preferable. Together, these results provide the theoretical foundation for training with direct 9D regression and applying SVD projection only at inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a gradient analysis of SVD orthogonalization specialized to 3x3 matrices and SO(3) projection. Its central claim is that the SVD backward-pass Jacobian has exact rank 3 (matching the SO(3) tangent space dimension), with nonzero singular values 2/(s_i + s_j) and condition number κ = (s_1 + s_2)/(s_2 + s_3), which quantifies gradient distortion that is worst when the predicted matrix is far from SO(3) (e.g., s_3 ≈ 0 early in training). The work further asserts that stabilized SVD gradients still introduce direction error, that removing SVD from training avoids the tradeoff, and that the 6D Gram-Schmidt Jacobian has an asymmetric spectrum (unequal gradient signals across parameters), favoring 9D direct regression with SVD only at inference.
Significance. If the stated derivations hold, the paper supplies a concrete theoretical explanation for the empirical advantage of 9D representations with post-training SVD projection. The explicit spectrum and condition-number formula allow quantitative assessment of gradient behavior and could guide future stabilization techniques or manifold-projection analyses. The comparison to Gram-Schmidt provides a clear rationale for parameterization choice.
major comments (2)
- [Central result on SVD Jacobian spectrum] Central result (SVD Jacobian spectrum): the exact singular values 2/(s_i + s_j), rank-3 property, and condition number κ = (s_1 + s_2)/(s_2 + s_3) are presented as derived results, yet the manuscript supplies neither the intermediate matrix-calculus steps nor verification that the formulas hold under the 3×3 SO(3) assumptions. This is load-bearing for the central claim.
- [6D Gram-Schmidt Jacobian analysis] 6D Gram-Schmidt analysis: the claim of an asymmetric spectrum (unequal gradient signals) is asserted without exhibiting the explicit Jacobian entries or the eigenvalue calculation that would confirm the asymmetry.
minor comments (2)
- The abstract states that 'exact derivations were performed' but does not point readers to the specific equations or appendix containing the full steps.
- A compact table or figure juxtaposing the SVD and Gram-Schmidt spectra would improve readability and allow direct visual comparison of the claimed properties.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The two major comments correctly identify places where the derivations underlying our central claims were not presented with sufficient explicit steps. We address each point below and will revise the manuscript to include the requested intermediate calculations and verifications.
read point-by-point responses
-
Referee: Central result (SVD Jacobian spectrum): the exact singular values 2/(s_i + s_j), rank-3 property, and condition number κ = (s_1 + s_2)/(s_2 + s_3) are presented as derived results, yet the manuscript supplies neither the intermediate matrix-calculus steps nor verification that the formulas hold under the 3×3 SO(3) assumptions. This is load-bearing for the central claim.
Authors: We agree that the intermediate matrix-calculus steps were omitted from the main text and that this omission weakens the presentation of the load-bearing result. In the revised manuscript we will add a new appendix that derives the SVD backward-pass Jacobian from first principles: starting from the SVD of a 3×3 matrix, forming the orthogonal projection onto SO(3), differentiating through the projection, and obtaining the Jacobian matrix whose nonzero singular values are exactly 2/(s_i + s_j). We will explicitly verify that the kernel has dimension 6 (hence rank 3) under the SO(3) constraints and that the condition number is κ = (s_1 + s_2)/(s_2 + s_3). The appendix will also contain a short numerical check comparing the analytical singular values against finite-difference approximations for several test matrices, including cases with s_3 near zero. revision: yes
-
Referee: 6D Gram-Schmidt analysis: the claim of an asymmetric spectrum (unequal gradient signals) is asserted without exhibiting the explicit Jacobian entries or the eigenvalue calculation that would confirm the asymmetry.
Authors: We accept that the explicit Jacobian and its eigenvalue decomposition for the 6D Gram-Schmidt parameterization were not shown. In the revision we will insert a new subsection that writes out the full 9-to-6 Jacobian of the Gram-Schmidt orthogonalization applied to a 6D vector, computes its singular-value decomposition analytically, and demonstrates that the resulting spectrum is asymmetric (three distinct nonzero singular values). This calculation will directly support the claim that the six parameters receive unequal gradient magnitudes, providing a concrete rationale for preferring 9D regression. revision: yes
Circularity Check
No significant circularity; derivations are direct matrix calculus
full rationale
The paper derives the SVD backward-pass Jacobian spectrum (rank 3, singular values 2/(s_i + s_j), condition number (s_1 + s_2)/(s_2 + s_3)) and the asymmetric 6D Gram-Schmidt spectrum as explicit results of matrix calculus applied to the 3x3 SVD and projection operators. These quantities are obtained from the paper's own equations without any reduction to fitted parameters, self-referential definitions, or load-bearing self-citations. The central claims remain independent of the paper's own inputs and do not invoke uniqueness theorems or ansatzes from prior author work. The analysis is self-contained and externally verifiable via standard linear-algebra identities.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math SVD exists and is differentiable for 3x3 real matrices with distinct singular values
- domain assumption The projection target is the special orthogonal group SO(3)
Lean theorems connected to this paper
-
Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Our central result derives the exact spectrum of the SVD backward pass Jacobian: it has rank 3 (matching the dimension of SO(3)) with nonzero singular values 2/(s_i + s_j) and condition number κ = (s_1 + s_2)/(s_2 + s_3)
-
Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The 1/(s_i + s_j) scaling in (7) creates three pathologies for training: gradient explosion, poor conditioning, and gradient coupling.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
K. S. Arun, T. S. Huang, and S. D. Blostein. Least-squares fitting of two 3- D point sets. IEEE Transactions on Pattern Analysis and Machine Intelligence, 9 0 (5): 0 698--700, 1987
work page 1987
-
[2]
Deep regression on manifolds: A 3D rotation case study
Romain Br \'e gier. Deep regression on manifolds: A 3D rotation case study. In International Conference on 3D Vision (3DV), 2021
work page 2021
-
[3]
Christopher Choy, Wei Dong, and Vladlen Koltun. Deep global registration. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
work page 2020
-
[4]
Du mouvement de rotation des corps solides autour d'un axe variable
Leonhard Euler. Du mouvement de rotation des corps solides autour d'un axe variable. M \'e moires de l'acad \'e mie des sciences de Berlin , pages 154--193, 1765
-
[5]
Ren \'e Geist, Jonas Frey, Mikel Zhobro, Anna Levina, and Georg Martius
A. Ren \'e Geist, Jonas Frey, Mikel Zhobro, Anna Levina, and Georg Martius. Learning with 3D rotations, a hitchhiker's guide to SO(3) . In International Conference on Machine Learning (ICML), 2024
work page 2024
-
[6]
Mike B. Giles. Collected matrix derivative results for forward and reverse mode algorithmic differentiation. In Advances in Automatic Differentiation, pages 35--44. Springer, 2008
work page 2008
-
[7]
Deep orientation uncertainty learning based on a B ingham loss
Igor Gilitschenski, Roshni Sahoo, Wilko Schwarting, Alexander Amini, Sertac Karaman, and Daniela Rus. Deep orientation uncertainty learning based on a B ingham loss. In International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[8]
F. Sebastian Grassia. Practical parameterization of rotations using the exponential map. Journal of Graphics Tools, 3 0 (3): 0 29--48, 1998
work page 1998
-
[9]
Learning unorthogonalized matrices for rotation estimation
Kerui Gu, Zhihao Li, Shiyong Liu, Jianzhuang Liu, Songcen Xu, Youliang Yan, Michael Bi Mi, Kenji Kawaguchi, and Angela Yao. Learning unorthogonalized matrices for rotation estimation. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[10]
Matrix backpropagation for deep networks with structured layers
Catalin Ionescu, Orestis Vantzos, and Cristian Sminchisescu. Matrix backpropagation for deep networks with structured layers. In IEEE International Conference on Computer Vision (ICCV), 2015
work page 2015
-
[11]
An analysis of SVD for deep rotation estimation
Jake Levinson, Carlos Esteves, Kefan Chen, Noah Snavely, Angjoo Kanazawa, Afshin Rostamizadeh, and Ameesh Makadia. An analysis of SVD for deep rotation estimation. In Advances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[12]
Shuai Liao, Efstratios Gavves, and Cees G. M. Snoek. Spherical regression: Learning viewpoints, surface normals and 3D rotations on n-spheres. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
work page 2019
-
[13]
A mixed classification-regression framework for 3D pose estimation from 2D images
Siddharth Mahendran, Haider Ali, and Ren \'e Vidal. A mixed classification-regression framework for 3D pose estimation from 2D images. In British Machine Vision Conference (BMVC), 2018
work page 2018
- [14]
-
[15]
Valentin Peretroukhin, Matthew Giamou, W. Nicholas Greene, David M. Rosen, Nicholas Roy, and Jonathan Kelly. A smooth representation of belief over SO(3) for deep rotation learning with uncertainty. In Robotics: Science and Systems (RSS), 2020
work page 2020
-
[16]
Deep directional statistics: Pose estimation with uncertainty quantification
Sergey Prokudin, Peter Gehler, and Sebastian Nowozin. Deep directional statistics: Pose estimation with uncertainty quantification. In European Conference on Computer Vision (ECCV), 2018
work page 2018
-
[17]
On the parametrization of the three-dimensional rotation group
John Stuelpnagel. On the parametrization of the three-dimensional rotation group. SIAM Review, 6 0 (4): 0 422--430, 1964
work page 1964
-
[18]
Differentiating the singular value decomposition, 2016
James Townsend. Differentiating the singular value decomposition, 2016. Technical note
work page 2016
-
[19]
Wei Wang, Zheng Dang, Yinlin Hu, Pascal Fua, and Mathieu Salzmann. Robust differentiable SVD . IEEE Transactions on Pattern Analysis and Machine Intelligence, 44 0 (9): 0 5472--5487, 2022
work page 2022
-
[20]
On the continuity of rotation representations in neural networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.