Residual-Mass Accounting for Partial-KV Decoding
Pith reviewed 2026-05-10 20:11 UTC · model grok-4.3
The pith
A residual-mass accounting rule using learned feature maps improves partial-KV decoding over pure Top-K selection at low exact-support budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
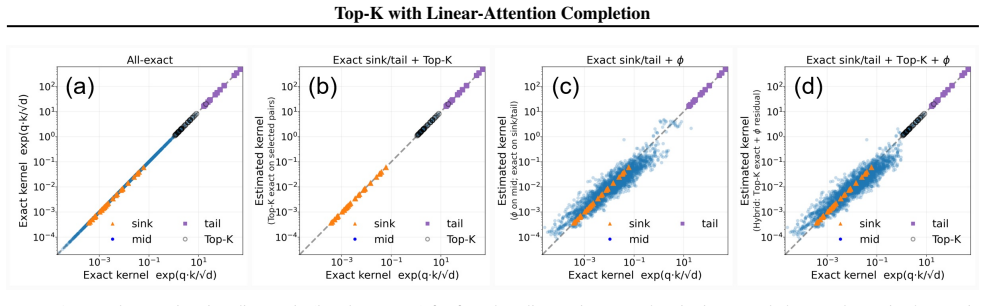
In controlled partial-KV decoding, exact unnormalized softmax terms are kept for sink/tail anchors and a retrieved set while the remaining prefill tokens are summarized by a residual estimate. The accounting rule builds fixed-size summary states (S, u) from learned positive feature maps φ, subtracts the retrieved-token feature contributions to keep the exact and residual partitions disjoint, and combines the estimated residual numerator and denominator with the exact branch under one normalization. At a 1% exact-support budget this yields gains over Top-K on RULER and BABILong for frozen 1B and 3B Llama backbones at all lengths; the 0.5-4% sweeps largely preserve the trend, LongBench summar
What carries the argument
Fixed-size summary states (S, u) constructed from learned positive feature maps φ, with explicit subtraction of retrieved-token feature contributions before merging the residual estimate with the exact branch under unified normalization.
If this is right
- At 1% exact-support budget the residual-completion method outperforms selection-only Top-K on RULER and BABILong for frozen 1B and 3B Llama-3.2-Instruct models at every reported context length.
- The performance trend largely persists across 0.5-4% exact-support budget sweeps.
- On LongBench the approach is mostly favorable for summarization tasks and mixed for multi-document QA.
- Attention-output diagnostics confirm that retrieved-token subtraction is the partition-consistent accounting rule.
Where Pith is reading between the lines
- Improving the fidelity of the φ approximation would directly address the main remaining error source identified in the diagnostics.
- The unchanged backbone and exact KV tensors allow the accounting rule to be layered on top of any retrieval selector beyond exhaustive Top-K.
- Because the method preserves the original model weights, it can be inserted into existing long-context inference stacks without retraining the language model itself.
Load-bearing premise
The learned positive feature maps φ accurately approximate the unretrieved residual mass after subtraction of retrieved-token contributions.
What would settle it
Recompute the full attention outputs using exact residual mass instead of the learned φ estimate and check whether the accuracy advantage over Top-K disappears.
Figures
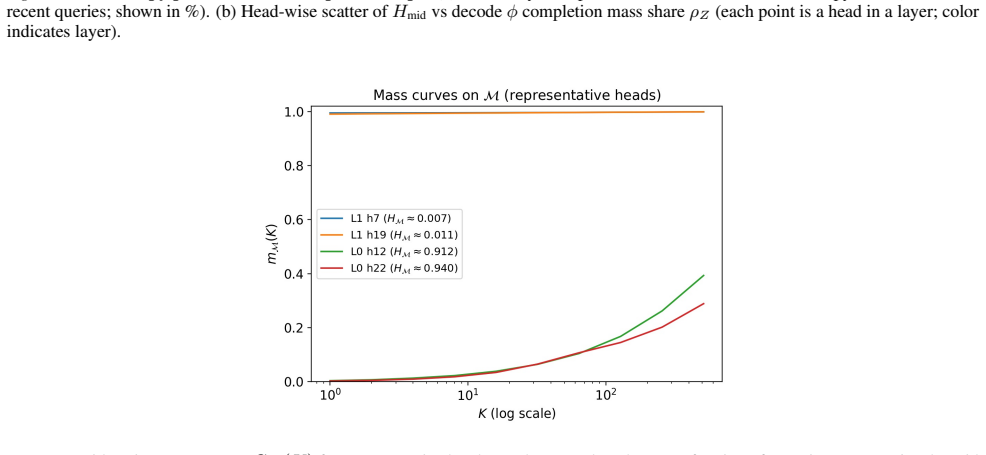
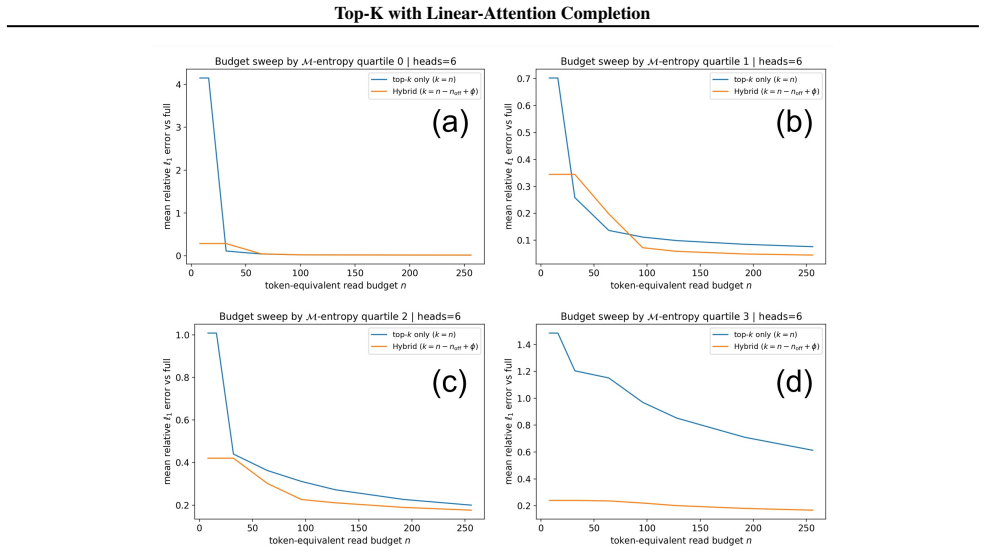
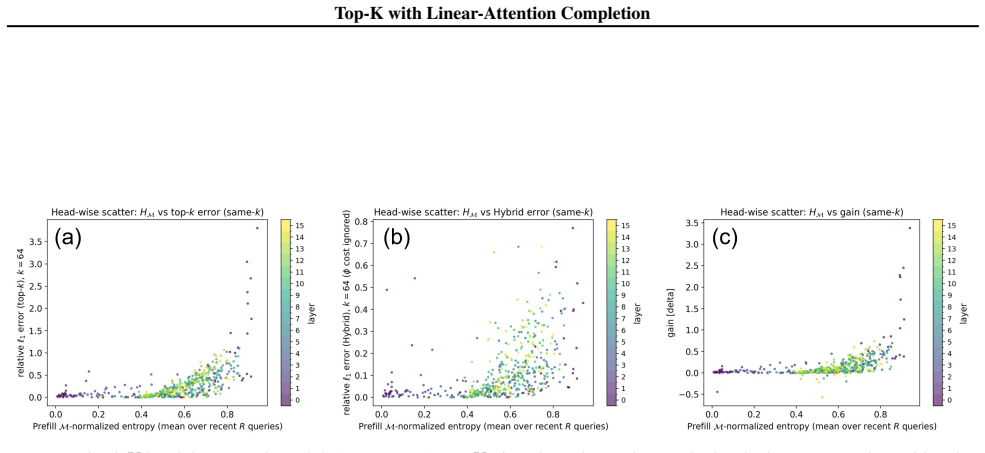
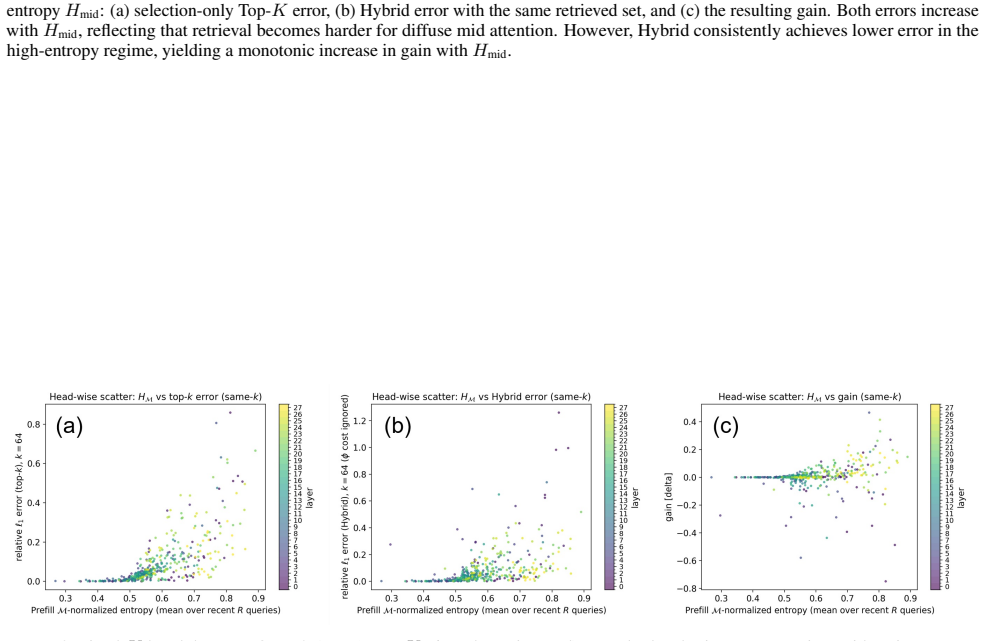
read the original abstract
We study a controlled partial-KV decoding setting in which exact unnormalized softmax contributions are computed for sink/tail anchors and a retrieved token set, while the remaining prefill tokens are represented by a residual estimate. We focus on the accounting rule after the query-dependent exact support has been selected, and use exhaustive Top-K only as an oracle selector, not as a deployable retrieval system. The proposed rule leaves the backbone language model and the exact-branch KV tensors unchanged. It builds fixed-size summary states $(S,u)$ from learned positive feature maps $\phi$, subtracts retrieved-token feature contributions to keep the exact and residual sets non-overlapping, and merges the estimated residual numerator and denominator with the exact branch under one normalization. At a 1% exact-support budget, our residual-completion method improves over the selection-only Top-K baseline on RULER and BABILong across frozen 1B and 3B Llama-3.2-Instruct backbones at all reported context lengths. In the 0.5-4% exact-support budget sweeps, this trend largely persists. On LongBench, summarization results are mostly favorable, while multi-document QA is mixed. Attention-output diagnostics support retrieved-token subtraction as the partition-consistent accounting rule, while indicating that the main remaining error is imperfect learned-$\phi$ approximation of the unretrieved residual mass.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a residual-mass accounting rule for partial-KV decoding: after selecting an exact-support set via oracle Top-K, fixed-size summary states (S, u) are built from learned positive feature maps φ; retrieved-token contributions are subtracted to enforce partition consistency; the resulting residual numerator/denominator estimate is merged with the exact branch under a single softmax normalization. Experiments report consistent gains over the selection-only Top-K baseline on RULER and BABILong (and mixed results on LongBench) for frozen 1B/3B Llama-3.2 backbones at 1% exact-support budgets across context lengths, with attention diagnostics supporting the subtraction step.
Significance. If the residual estimate proves reliable, the approach could enable more accurate low-budget partial decoding than pure selection methods while leaving the backbone and exact KV tensors unchanged. The partition-consistent accounting and diagnostic support for subtraction are positive elements; however, the central gains rest on the learned φ component whose training, validation, and error characterization are not detailed.
major comments (3)
- [Abstract] Abstract: the reported gains at 1% exact-support budget are attributed to the residual-completion step after subtraction, yet the abstract itself identifies “imperfect learned-φ approximation of the unretrieved residual mass” as the dominant remaining error without supplying quantitative bounds on that approximation error or an ablation that replaces learned φ with a non-learned surrogate (constant, mean-pool, etc.).
- [Evaluation section] Evaluation (RULER/BABILong results): the residual estimate depends on φ fitted to data and the method is evaluated on the same long-context tasks used to tune it; while the frozen backbone and oracle Top-K provide some separation, this leaves open whether observed improvements arise from the accounting rule or from extra capacity in φ.
- [Method section] Method description: no details are given on the training procedure, loss, data, or validation protocol for the positive feature maps φ, nor on whether φ is task-specific or shared across the 1B and 3B backbones; this information is load-bearing for assessing reproducibility and the strength of the central claim.
minor comments (2)
- [Method section] The notation (S, u) for summary states is introduced without an explicit equation showing how they are constructed from φ and the prefill tokens.
- [Evaluation section] LongBench results are described as “mostly favorable” for summarization and “mixed” for multi-document QA; a table or per-task breakdown would clarify the pattern.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and commit to revisions that supply the requested details and analyses without altering the core claims of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported gains at 1% exact-support budget are attributed to the residual-completion step after subtraction, yet the abstract itself identifies “imperfect learned-φ approximation of the unretrieved residual mass” as the dominant remaining error without supplying quantitative bounds on that approximation error or an ablation that replaces learned φ with a non-learned surrogate (constant, mean-pool, etc.).
Authors: We agree that the abstract would be strengthened by quantitative bounds on the approximation error and by an ablation against a non-learned surrogate. In the revised manuscript we will add a sentence reporting the observed residual-mass approximation error statistics from the attention diagnostics already present in the paper, and we will include a new ablation that substitutes a constant or mean-pool surrogate for the learned φ to isolate the contribution of the accounting rule. revision: yes
-
Referee: [Evaluation section] Evaluation (RULER/BABILong results): the residual estimate depends on φ fitted to data and the method is evaluated on the same long-context tasks used to tune it; while the frozen backbone and oracle Top-K provide some separation, this leaves open whether observed improvements arise from the accounting rule or from extra capacity in φ.
Authors: The referee correctly identifies that the current manuscript supplies insufficient information to rule out confounding from φ's capacity. We will revise the evaluation section to document the training and validation protocol used for φ and to discuss how the frozen backbone together with the oracle Top-K selector help isolate the effect of the residual accounting rule. We will also note any task overlap as a limitation and, where feasible, add a cross-task control experiment. revision: partial
-
Referee: [Method section] Method description: no details are given on the training procedure, loss, data, or validation protocol for the positive feature maps φ, nor on whether φ is task-specific or shared across the 1B and 3B backbones; this information is load-bearing for assessing reproducibility and the strength of the central claim.
Authors: We acknowledge the omission. The revised method section will contain a complete description of the training procedure, loss function, data sources, and validation protocol for φ, together with an explicit statement on whether φ is shared across the 1B and 3B backbones. These additions will directly address reproducibility and allow readers to evaluate the strength of the central claim. revision: yes
Circularity Check
No significant circularity; empirical method with external benchmarks
full rationale
The paper proposes an empirical method for residual-mass accounting using learned positive feature maps φ to build summary states, subtract retrieved contributions, and merge under normalization. Claims rest on reported improvements over oracle Top-K baseline on RULER, BABILong, and LongBench with frozen Llama backbones. No derivation chain reduces by construction to inputs; φ is a fitted component of the proposed technique rather than a self-referential loop. No self-citations, uniqueness theorems, or ansatzes smuggled via prior work are invoked as load-bearing. The approach is self-contained against external task benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned positive feature maps φ
axioms (2)
- domain assumption Retrieved-token feature contributions can be subtracted from the summary to keep exact and residual sets non-overlapping
- domain assumption Estimated residual numerator and denominator can be merged with the exact branch under a single normalization
invented entities (2)
-
residual estimate
no independent evidence
-
summary states (S,u)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
What Does BERT Look at? An Analysis of BERT ' s Attention
URL https://openreview.net/forum ?id=Ua6zuk0WRH. Clark, K., Khandelwal, U., Levy, O., and Manning, C. D. What does BERT look at? an analysis of BERT’s at- tention. In Linzen, T., Chrupała, G., Belinkov, Y ., and Hupkes, D. (eds.),Proceedings of the 2019 ACL Work- shop BlackboxNLP: Analyzing and Interpreting Neu- ral Networks for NLP, pp. 276–286, Florence...
-
[2]
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents
Association for Computational Linguistics. doi: 10.18653/v1/N18-2097. URL https://aclantho logy.org/N18-2097/. Dao, T., Fu, D. Y ., Ermon, S., Rudra, A., and R ´e, C. FLASHATTENTION: fast and memory-efficient exact attention with IO-awareness. InProceedings of the 36th International Conference on Neural Information Process- ing Systems, NIPS ’22, Red Hook...
-
[3]
doi: 10.18653/v1/2021.sustainlp-1.5
Association for Computational Linguistics. doi: 10.18653/v1/2021.sustainlp-1.5. URL https://acla nthology.org/2021.sustainlp-1.5/. Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., and Ginsburg, B. RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024. URL https: //openre...
-
[4]
Proceedings of the 29th Symposium on Operating Systems Principles , pages =
URL https://proceedings.mlr.pres s/v119/katharopoulos20a.html. Kuratov, Y ., Bulatov, A., Anokhin, P., Rodkin, I., Sorokin, D., Sorokin, A., and Burtsev, M. Babilong: testing the limits of llms with long context reasoning-in-a-haystack. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , US...
-
[5]
In: Korhonen, A., Traum, D., Màrquez, L
URL https://dl.acm.org/doi/abs/10. 5555/3692070.3694025. Tatsuno, K., Miyashita, D., Ikeda, T., Ishiyama, K., Sumiyoshi, K., and Deguchi, J. AiSAQ: All-in-storage 10 Top-K with Linear-Attention Completion anns with product quantization for dram-free information retrieval, 2025. URL https://arxiv.org/abs/ 2404.06004. V oita, E., Talbot, D., Moiseev, F., Se...
-
[6]
Curran Associates Inc. 11 Top-K with Linear-Attention Completion A. Appendix Roadmap The appendix collects definitions and implementation details referenced by the main text. Training objective and loss.Appendix B defines the full distillation loss used in all reported experiments. Numerically stable ϕ-summary cache.Appendix C defines the max-shifted cach...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.