Recognition: 1 theorem link
· Lean TheoremJoint Knowledge Base Completion and Question Answering by Combining Large Language Models and Small Language Models
Pith reviewed 2026-05-10 19:59 UTC · model grok-4.3
The pith
A framework lets knowledge base completion and question answering strengthen each other by mixing large and small language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
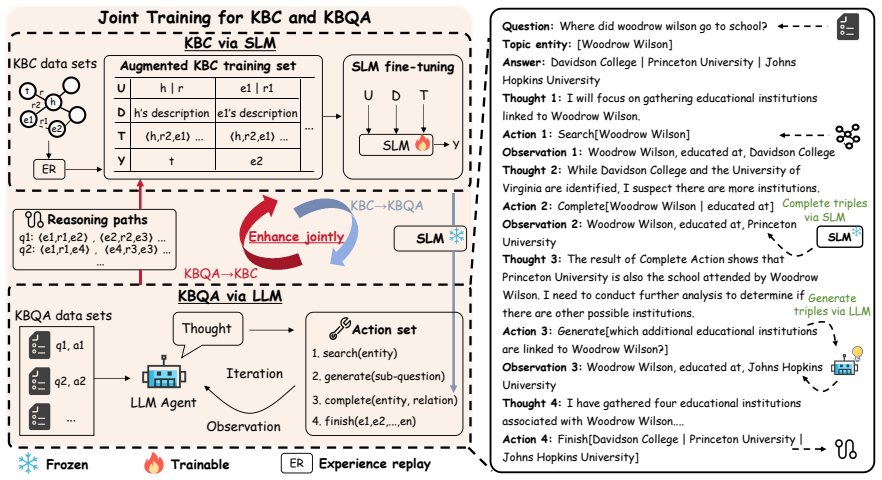
JCQL makes KBC and KBQA enhance each other iteratively: the SLM-trained KBC model serves as an action in the LLM agent to augment reasoning paths and reduce hallucinations in KBQA, while KBQA reasoning paths are used as supplementary data to fine-tune the KBC model, leading to superior performance on both tasks.
What carries the argument
The iterative JCQL loop that alternates between using an SLM KBC model as an action inside an LLM agent for KBQA and fine-tuning the SLM KBC model on paths from KBQA.
If this is right
- Both KBC and KBQA reach higher accuracy than models trained independently on each task alone.
- The LLM agent for KBQA produces fewer incorrect answers because the KBC model supplies grounded actions.
- The SLM for KBC improves its predictions after fine-tuning on paths generated during KBQA.
- Overall computation for KBQA decreases because the LLM does not need to handle every step alone.
Where Pith is reading between the lines
- The same alternating pattern could be tried on other paired KB tasks such as entity linking and relation extraction.
- Repeated rounds of the loop might produce further gains without needing new labeled data.
- The method offers a template for letting outputs from one model size supervise training of the other size across domains.
Load-bearing premise
KBQA reasoning paths supply reliable extra training examples for the KBC model that do not add errors or noise from the large model's mistakes.
What would settle it
A replication on the same two public benchmark datasets in which the joint JCQL process fails to beat the strongest separate baselines on either KBC or KBQA accuracy would show the mutual enhancement does not hold.
Figures




read the original abstract
Knowledge Bases (KBs) play a key role in various applications. As two representative KB-related tasks, knowledge base completion (KBC) and knowledge base question answering (KBQA) are closely related and inherently complementary with each other. Thus, it will be beneficial to solve the task of joint KBC and KBQA to make them reinforce each other. However, existing studies usually rely on the small language model (SLM) to enhance them jointly, and the large language model (LLM)'s strong reasoning ability is ignored. In this paper, by combining the strengths of the LLM with the SLM, we propose a novel framework JCQL, which can make these two tasks enhance each other in an iterative manner. To make KBC enhance KBQA, we augment the LLM agent-based KBQA model's reasoning paths by incorporating an SLM-trained KBC model as an action of the agent, alleviating the LLM's hallucination and high computational costs issue in KBQA. To make KBQA enhance KBC, we incrementally fine-tune the KBC model by leveraging KBQA's reasoning paths as its supplementary training data, improving the ability of the SLM in KBC. Extensive experiments over two public benchmark data sets demonstrate that JCQL surpasses all baselines for both KBC and KBQA tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes JCQL, a framework for jointly solving knowledge base completion (KBC) and knowledge base question answering (KBQA) by iteratively combining LLMs and SLMs. The SLM KBC model is inserted as an agent action to curb LLM hallucinations during KBQA reasoning, while KBQA-generated reasoning paths are used as supplementary data for incremental fine-tuning of the SLM KBC model. Experiments on two public benchmarks are claimed to show that JCQL outperforms all baselines on both tasks.
Significance. If the empirical claims hold after addressing validation concerns, the work could be significant for KB-related tasks by demonstrating a practical hybrid LLM-SLM approach that leverages task complementarity through iterative augmentation. This addresses LLM hallucination and SLM knowledge limits in a mutually reinforcing loop, potentially offering efficiency gains over pure LLM or SLM methods and inspiring similar joint frameworks.
major comments (2)
- [Abstract] Abstract: The central claim that KBQA reasoning paths provide useful supplementary training data for incremental KBC fine-tuning is load-bearing, yet the description provides no details on validation, filtering, or consistency checks of these paths against the KB. Without such safeguards, errors (e.g., incorrect entities or relations from LLM hallucinations) risk being reinforced across iterations, undermining the joint improvement assertion.
- [Abstract] Abstract: The claim that JCQL surpasses all baselines on two public benchmarks lacks any mention of specific baselines, metrics, ablation studies, dataset details, or experimental setup. This absence prevents assessment of whether the outperformance is robust or attributable to the proposed joint mechanism.
minor comments (1)
- [Abstract] The abstract could more explicitly name the two public benchmark datasets to help readers immediately contextualize the results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the abstract to provide greater clarity on the experimental details and safeguards in the joint training process.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that KBQA reasoning paths provide useful supplementary training data for incremental KBC fine-tuning is load-bearing, yet the description provides no details on validation, filtering, or consistency checks of these paths against the KB. Without such safeguards, errors (e.g., incorrect entities or relations from LLM hallucinations) risk being reinforced across iterations, undermining the joint improvement assertion.
Authors: We agree that explicit safeguards are important to prevent potential error reinforcement. The core design of JCQL uses the SLM KBC model as an agent action to ground LLM reasoning and reduce hallucinations before paths are collected for fine-tuning. To make this more transparent, we have revised the abstract to briefly note the use of consistency verification against the KB when incorporating paths as supplementary data. We have also expanded the relevant method description in the revised manuscript to detail the filtering steps applied during the iterative process. revision: yes
-
Referee: [Abstract] Abstract: The claim that JCQL surpasses all baselines on two public benchmarks lacks any mention of specific baselines, metrics, ablation studies, dataset details, or experimental setup. This absence prevents assessment of whether the outperformance is robust or attributable to the proposed joint mechanism.
Authors: The abstract is a concise summary, while the full manuscript details the experimental setup in Sections 5 and 6, including the specific baselines for both KBC and KBQA, evaluation metrics, the two public benchmark datasets, and ablation studies isolating the joint mechanism. To address the concern directly in the abstract, we have revised it to reference the key datasets, primary metrics, and the fact that ablations confirm the contribution of the iterative LLM-SLM augmentation. revision: yes
Circularity Check
No circularity: empirical iterative framework validated on external benchmarks
full rationale
The paper presents JCQL as an iterative empirical method that augments KBQA reasoning with an SLM KBC action and fine-tunes the KBC model on KBQA paths. All performance claims rest on experiments over two public benchmark datasets rather than any derivation, equation, or prediction that reduces to the method's own inputs by construction. No self-citations, ansatzes, or fitted quantities are invoked as load-bearing proofs. The framework is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
JCQL augments LLM agent with SLM KBC model as 'complete' action and uses KBQA reasoning paths for incremental SLM fine-tuning via experience replay
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Debate to Align: Reliable Entity Alignment through Two-Stage Multi-Agent Debate
AgentEA improves entity alignment reliability by combining entity representation preference optimization with a two-stage multi-agent debate mechanism consisting of lightweight verification and deep alignment.
Reference graph
Works this paper leans on
-
[1]
Scaling Instruction-Finetuned Language Models
Translating Embeddings for Modeling Multi- relational Data. InNeurIPS, pages 2787–2795. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, ...
work page internal anchor Pith review arXiv 2020
-
[2]
Playing Atari with Deep Reinforcement Learning
SIT: Selective Incremental Training for Dy- namic Knowledge Graph Embedding . InICDE, pages 1607–1621. Youmin Ko, Hyemin Yang, Taeuk Kim, and Hyun- joon Kim. 2025. Subgraph-aware training of lan- guage models for knowledge graph completion using structure-aware contrastive learning. InWWW, page 72–85. Jens Lehmann, Robert Isele, Max Jakob, Anja Jentzsch, ...
work page internal anchor Pith review arXiv 2025
-
[3]
LLaMA: Open and Efficient Foundation Language Models
Sequence-to-sequence knowledge graph com- pletion and question answering. InACL, pages 2814– 2828. Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel Ni, Heung- Yeung Shum, and Jian Guo. 2024. Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph. InICLR, pages 1–31. Zhiqing Sun, Zhi-H...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Complete
solves questions through step-by-step rea- soning without requiring the KB. • Self-Consistency (SC) (Wang et al., 2023) can generate multiple candidate answers via CoT and select the most consistent answer. • KG-CoT (Zhao et al., 2024) leverages a step-by- step graph reasoning model to perform reasoning over KBs and generates chains of knowledge with high...
2023
-
[5]
United States of America, instance of, federal republic
-
[6]
United States of America, instance of, Democratic Republic
-
[7]
"" North Korea, office held by head of state, Kim Il-sung North Korea, office held by head of state, Kim Jong-un Pak Pong-ju, head of government, North Korea
United States of America, basic form of government, presidential system """ We first link the relations within the generated triples to the canonical relations in the background KB using the BM25 algorithm. As shown in Prompt 6, the prompt is then designed to modify the triples generated by LLM. The LLM often fre- quently generates unreliable triples. For...
-
[8]
office held by head of state: This relation links a geographical or political entity
-
[9]
member of political party: This relation connects individuals to the political parties
-
[10]
head of government: This relation links a specific location—such as a city, municipality
-
[11]
"" Schemas:
head of state: This relation links a geographical input ⟨Justin Bieber, father, ?⟩ sequence predict tail: Justin Bieber|father entity description: Justin Bieber [Canadian singer (born 1994)] related relationship: father context: ⟨ Justin Bieber | mother | Pattie Mallette ⟩ ⟨SEP⟩ ⟨ Justin Bieber | sibling | Jazmyn Bieber⟩ ⟨SEP⟩... output Jeremy Bieber Tabl...
1994
-
[12]
office held by head of state: [Location], office held by head of state, [Political Office]
-
[13]
member of political party: [Human], member of political party, [Political Party]
-
[14]
head of government: [Location], head of government, [Human]
-
[15]
"" New Triples:
head of state: [Location], head of state, [Human] """ New Triples:"""
-
[16]
North Korea, head of state, Kim Il-sung
-
[17]
North Korea, head of state, Kim Jong-un
-
[18]
"" Related relations:father, mother, occupation Related triples:
North Korea, head of government, Pak Pong-ju """ As shown in Prompt 7, the prompt is designed to select the triples most relevant to the question to construct reasoning paths. Prompt 7.The Prompt for Path Generation •Instruction: Considering the known triples and relations, please select the triples and relations that are relevant to the questions and ans...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.