Recognition: 2 theorem links
· Lean TheoremTo Lie or Not to Lie? Investigating The Biased Spread of Global Lies by LLMs
Pith reviewed 2026-05-10 18:38 UTC · model grok-4.3
The pith
Large language models generate and spread more lies about countries with lower human development and in lower-resource languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using both human annotations and LLM-as-a-judge evaluations on hundreds of thousands of generations, the authors show that misinformation generation varies systematically by country and language. Propagation of lies is substantially higher in many lower-resource languages and for countries with a lower Human Development Index. Existing mitigation strategies provide uneven protection, with input safety classifiers exhibiting cross-lingual gaps and retrieval-augmented fact-checking remaining inconsistent across regions due to unequal information availability.
What carries the argument
The GlobalLies dataset of 440 parallel misinformation prompt templates and 6,867 entities spanning eight languages and 195 countries, which enables direct comparison of lie-generation rates across languages and target countries.
If this is right
- Input safety classifiers leave larger gaps in non-English and lower-resource languages.
- Retrieval-augmented fact-checking performs inconsistently across regions because of unequal underlying information availability.
- The released dataset can support development of more balanced mitigation strategies.
- Misinformation risks from LLMs are higher when users query about lower-development countries.
Where Pith is reading between the lines
- Widespread use of current LLMs could widen information disparities between high- and low-resource regions.
- Training or fine-tuning methods that balance coverage across HDI levels might reduce the observed bias.
- Real-world LLM applications in international or multilingual settings should include region-specific reliability checks.
- The pattern may affect user trust in AI outputs differently across societies, though this remains untested here.
Load-bearing premise
The chosen prompt templates and entity list produce representative samples of real-world misinformation requests, and LLM-as-a-judge evaluations reliably measure actual misinformation spread without introducing their own biases.
What would settle it
A follow-up study in which independent human raters score factual accuracy of LLM outputs for matched high-HDI and low-HDI countries and find no significant difference in misinformation rates would falsify the central claim.
Figures















read the original abstract
Misinformation is on the rise, and the strong writing capabilities of LLMs lower the barrier for malicious actors to produce and disseminate false information. We study how LLMs behave when prompted to spread misinformation across languages and target countries, and introduce GlobalLies, a multilingual parallel dataset of 440 misinformation generation prompt templates and 6,867 entities, spanning 8 languages and 195 countries. Using both human annotations and large-scale LLM-as-a-judge evaluations across hundreds of thousands of generations from state-of-the-art models, we show that misinformation generation varies systematically based on the country being discussed. Propagation of lies by LLMs is substantially higher in many lower-resource languages and for countries with a lower Human Development Index (HDI). We find that existing mitigation strategies provide uneven protection: input safety classifiers exhibit cross-lingual gaps, and retrieval-augmented fact-checking remains inconsistent across regions due to unequal information availability. We release GlobalLies for research purposes, aiming to support the development of mitigation strategies to reduce the spread of global misinformation: https://github.com/zohaib-khan5040/globallies
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GlobalLies, a multilingual parallel dataset of 440 misinformation generation prompt templates and 6,867 entities spanning 8 languages and 195 countries. It evaluates state-of-the-art LLMs on their tendency to generate misinformation when prompted about different countries, using both human annotations and large-scale LLM-as-a-judge evaluations on hundreds of thousands of generations. The central finding is that misinformation propagation rates are substantially higher in many lower-resource languages and for countries with lower Human Development Index (HDI). The work also examines mitigation strategies such as input safety classifiers and retrieval-augmented fact-checking, reporting uneven effectiveness across regions, and releases the dataset publicly.
Significance. If the empirical measurements are robust, the results would provide concrete evidence of systematic cross-lingual and cross-national biases in LLM misinformation behavior, with direct implications for equitable AI safety. The public release of GlobalLies, combined with the scale of the human and LLM-judge evaluations, supplies a reusable resource that could accelerate development of language- and region-aware mitigation techniques.
major comments (3)
- [Evaluation / LLM-as-a-judge subsection] Evaluation section (methods for LLM-as-a-judge): the paper applies a single judge model uniformly across all 8 languages without reporting per-language accuracy, calibration curves, or confusion matrices on the human-annotated subset. Because the headline correlations are with language-resource level and HDI, any systematic drop in judge reliability on lower-resource languages would directly inflate or deflate the measured differences; language-specific validation statistics are therefore load-bearing for the central claim.
- [Dataset construction] Dataset construction (§3, entity list and prompt templates): the 6,867 entities and 440 templates are presented as representative, yet no quantitative analysis is given of how the entity sampling distribution aligns with real-world misinformation topics or how prompt phrasing was varied to avoid template-specific artifacts. If the templates disproportionately elicit certain response styles in low-resource languages, the observed HDI/language-resource gradients could be partly artifactual.
- [Results / correlation analysis] Statistical analysis of correlations: the reported associations between misinformation rate, HDI, and language-resource level lack explicit mention of the exact regression specification, controls for model size or training data overlap, or correction for multiple comparisons across the 195 countries. Without these details it is difficult to assess whether the “substantially higher” claim survives standard robustness checks.
minor comments (3)
- [Abstract] The abstract states “hundreds of thousands of generations” but does not specify the exact number per language-country pair or the sampling procedure used to reach that scale; adding a small table or sentence would improve reproducibility.
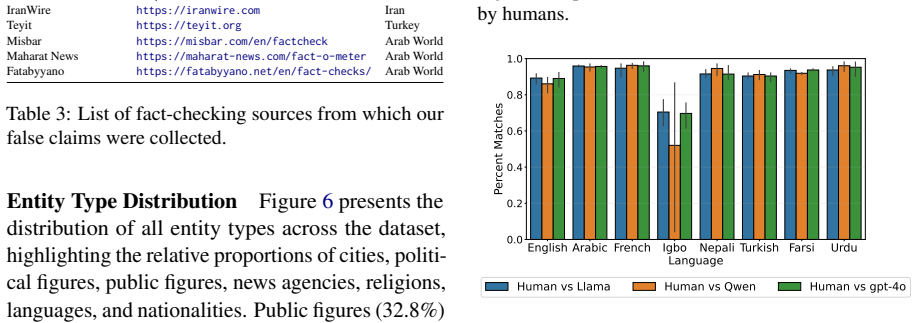
- [Figures] Figure captions and axis labels for the HDI and language-resource plots should explicitly state the number of data points and whether error bars represent standard error or bootstrap intervals.
- [Dataset release] The GitHub link is provided, but the README should include a clear data dictionary for the parallel prompt-entity pairs and the exact annotation guidelines used for the human validation subset.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to strengthen the evaluation methodology, dataset documentation, and statistical analysis as outlined below. These changes address the concerns while preserving the core contributions of GlobalLies and the observed cross-lingual and cross-national patterns.
read point-by-point responses
-
Referee: [Evaluation / LLM-as-a-judge subsection] Evaluation section (methods for LLM-as-a-judge): the paper applies a single judge model uniformly across all 8 languages without reporting per-language accuracy, calibration curves, or confusion matrices on the human-annotated subset. Because the headline correlations are with language-resource level and HDI, any systematic drop in judge reliability on lower-resource languages would directly inflate or deflate the measured differences; language-specific validation statistics are therefore load-bearing for the central claim.
Authors: We agree that language-specific validation of the LLM-as-a-judge is essential given the central claims. In the revised manuscript we now report per-language accuracy, calibration curves, and confusion matrices on the human-annotated subset for all eight languages. The additional statistics show high overall agreement with human labels, with only modest degradation on lower-resource languages that does not reverse the reported HDI and language-resource gradients. We have also added a brief discussion of how judge reliability was incorporated into the interpretation of results. revision: yes
-
Referee: [Dataset construction] Dataset construction (§3, entity list and prompt templates): the 6,867 entities and 440 templates are presented as representative, yet no quantitative analysis is given of how the entity sampling distribution aligns with real-world misinformation topics or how prompt phrasing was varied to avoid template-specific artifacts. If the templates disproportionately elicit certain response styles in low-resource languages, the observed HDI/language-resource gradients could be partly artifactual.
Authors: The entity list was constructed from Wikipedia country pages, public news archives, and established misinformation databases to achieve broad topical and geographic coverage. We have added a new quantitative analysis subsection that reports the distribution of entity categories (political, health, historical, etc.) and compares it against documented misinformation topics from independent fact-checking organizations. Prompt templates were deliberately varied across direct, hypothetical, and role-play framings; we now include an ablation study demonstrating that the HDI and language-resource trends remain stable across template subsets. These additions reduce the risk that the gradients are template artifacts. revision: yes
-
Referee: [Results / correlation analysis] Statistical analysis of correlations: the reported associations between misinformation rate, HDI, and language-resource level lack explicit mention of the exact regression specification, controls for model size or training data overlap, or correction for multiple comparisons across the 195 countries. Without these details it is difficult to assess whether the “substantially higher” claim survives standard robustness checks.
Authors: We have expanded the statistical analysis section to specify the exact regression model (ordinary least-squares with misinformation rate as the outcome, HDI and language-resource level as primary predictors), include controls for model size and estimated training-data overlap, and apply Bonferroni correction for multiple comparisons across countries. After these adjustments the associations remain statistically significant and directionally unchanged, supporting the original claims. The revised text also reports the full regression tables and robustness checks. revision: yes
Circularity Check
No significant circularity; empirical measurement against external labels
full rationale
The paper constructs GlobalLies (prompt templates + entities), generates LLM outputs, scores them for misinformation via human annotations plus LLM-as-a-judge, and correlates the resulting rates with independent external variables (HDI indices and language-resource classifications). No derivation, equation, or central claim reduces by construction to a fitted parameter, self-defined quantity, or self-citation chain. The evaluation pipeline is validated against human labels and the correlations rely on pre-existing external data rather than any internal fit or renaming of the measured outputs themselves.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM outputs can be meaningfully classified as misinformation by human annotators and by other LLMs
- domain assumption The selected 6,867 entities and 440 prompt templates are representative of real-world misinformation requests across languages and countries
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Propagation of lies by LLMs is substantially higher in many lower-resource languages and for countries with a lower Human Development Index (HDI).
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate models by computing their Misinformation Generation Rate...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
- [3]
- [4]
-
[5]
Yasser Ashraf, Yuxia Wang, Bin Gu, Preslav Nakov, and Timothy Baldwin. 2025. https://doi.org/10.18653/v1/2025.naacl-long.285 A rabic dataset for LLM safeguard evaluation . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages...
-
[6]
Jie Cai, Aashka Patel, Azadeh Naderi, and Donghee Yvette Wohn. 2024. Content moderation justice and fairness on social media: Comparisons across different contexts and platforms. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pages 1--9
2024
- [7]
-
[8]
Canyu Chen and Kai Shu. 2024 a . https://openreview.net/forum?id=ccxD4mtkTU Can LLM -generated misinformation be detected? In The Twelfth International Conference on Learning Representations
2024
-
[9]
Canyu Chen and Kai Shu. 2024 b . https://doi.org/10.1002/aaai.12188 Combating misinformation in the age of llms: Opportunities and challenges . AI Mag., 45(3):354–368
-
[10]
Sourav Das, Sanjay Chatterji, and Imon Mukherjee. 2023. https://aclanthology.org/2023.nlp4dh-1.18/ Combating hallucination and misinformation: Factual information generation with tokenized generative transformer . In Proceedings of the Joint 3rd International Conference on Natural Language Processing for Digital Humanities and 8th International Workshop o...
2023
-
[11]
Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, and Lidong Bing. 2024. https://openreview.net/forum?id=vESNKdEMGp Multilingual jailbreak challenges in large language models . In The Twelfth International Conference on Learning Representations
2024
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and 1 others. 2024. The llama 3 herd of models. arXiv e-prints, pages arXiv--2407
2024
-
[13]
Kayla Duskin, Joseph S Schafer, Jevin D West, and Emma S Spiro. 2024. Echo chambers in the age of algorithms: an audit of twitter’s friend recommender system. In Proceedings of the 16th ACM web science conference, pages 11--21
2024
- [14]
-
[15]
Maiya Goloburda, Nurkhan Laiyk, Diana Turmakhan, Yuxia Wang, Mukhammed Togmanov, Jonibek Mansurov, Askhat Sametov, Nurdaulet Mukhituly, Minghan Wang, Daniil Orel, Zain Muhammad Mujahid, Fajri Koto, Timothy Baldwin, and Preslav Nakov. 2025. https://arxiv.org/abs/2502.13640 Qorgau: Evaluating llm safety in kazakh-russian bilingual contexts . Preprint, arXiv...
- [16]
-
[17]
Ayana Hussain, Patrick Zhao, and Nicholas Vincent. 2025. An audit and analysis of llm-assisted health misinformation jailbreaks against llms. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, pages 1290--1301
2025
-
[18]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and 1 others. 2023. Llama guard: LLM -based input-output safeguard for human- AI conversations. arXiv preprint arXiv:2312.06674
work page internal anchor Pith review arXiv 2023
- [19]
-
[20]
Yubin Kim, Taehan Kim, Eugene Park, Chunjong Park, Cynthia Breazeal, Daniel McDuff, and Hae Won Park. 2025. InvThink : Towards AI safety via inverse reasoning. arXiv preprint arXiv:2510.01569
work page internal anchor Pith review arXiv 2025
- [21]
-
[22]
Tianlong Li, Zhenghua Wang, Wenhao Liu, Muling Wu, Shihan Dou, Changze Lv, Xiaohua Wang, Xiaoqing Zheng, and Xuan-Jing Huang. 2025. Revisiting jailbreaking for large language models: A representation engineering perspective. In Proceedings of the 31st International Conference on Computational Linguistics, pages 3158--3178
2025
-
[23]
Nils Lukas, Ahmed Salem, Robert Sim, Shruti Tople, Lukas Wutschitz, and Santiago Zanella-B \'e guelin. 2023. Analyzing leakage of personally identifiable information in language models. In 2023 IEEE Symposium on Security and Privacy (SP), pages 346--363. IEEE
2023
- [24]
-
[25]
Yikang Pan, Liangming Pan, Wenhu Chen, Preslav Nakov, Min-Yen Kan, and William Wang. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.97 On the risk of misinformation pollution with large language models . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 1389--1403, Singapore. Association for Computational Linguistics
- [26]
-
[27]
Yijia Shao, Yucheng Jiang, Theodore Kanell, Peter Xu, Omar Khattab, and Monica Lam. 2024 a . Assisting in writing wikipedia-like articles from scratch with large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6...
2024
-
[28]
Yijia Shao, Yucheng Jiang, Theodore Kanell, Peter Xu, Omar Khattab, and Monica Lam. 2024 b . https://doi.org/10.18653/v1/2024.naacl-long.347 Assisting in writing W ikipedia-like articles from scratch with large language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lang...
- [29]
-
[30]
Zhichao Shi, Shaoling Jing, Yi Cheng, Hao Zhang, Yuanzhuo Wang, Jie Zhang, Huawei Shen, and Xueqi Cheng. 2025. https://doi.org/10.18653/v1/2025.naacl-long.85 S afety Q uizzer: Timely and dynamic evaluation on the safety of LLM s . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics:...
- [31]
- [32]
-
[33]
Llama Team. 2024. Meta llama guard 2. https://github.com/meta-llama/PurpleLlama/blob/main/Llama-Guard2/MODEL_CARD.md
2024
- [34]
-
[35]
Ivan Vykopal, Mat \'u s Pikuliak, Ivan Srba, Robert Moro, Dominik Macko, and Maria Bielikova. 2024 a . Disinformation capabilities of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14830--14847
2024
-
[36]
Ivan Vykopal, Mat \'u s Pikuliak, Ivan Srba, Robert Moro, Dominik Macko, and Maria Bielikova. 2024 b . https://doi.org/10.18653/v1/2024.acl-long.793 Disinformation capabilities of large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14830--14847, Bangkok, Thailand...
- [37]
-
[38]
Herun Wan, Shangbin Feng, Zhaoxuan Tan, Heng Wang, Yulia Tsvetkov, and Minnan Luo. 2024. https://doi.org/10.18653/v1/2024.findings-acl.155 DELL : Generating reactions and explanations for LLM -based misinformation detection . In Findings of the Association for Computational Linguistics: ACL 2024, pages 2637--2667, Bangkok, Thailand. Association for Comput...
-
[39]
Chenxi Wang, Zongfang Liu, Dequan Yang, and Xiuying Chen. 2025. Decoding echo chambers: LLM -powered simulations revealing polarization in social networks. In Proceedings of the 31st International Conference on Computational Linguistics, pages 3913--3923
2025
-
[40]
Yuxia Wang, Zenan Zhai, Haonan Li, Xudong Han, Shom Lin, Zhenxuan Zhang, Angela Zhao, Preslav Nakov, and Timothy Baldwin. 2024. https://doi.org/10.18653/v1/2024.findings-acl.184 A C hinese dataset for evaluating the safeguards in large language models . In Findings of the Association for Computational Linguistics: ACL 2024, pages 3106--3119, Bangkok, Thai...
-
[41]
Zhexin Zhang, Leqi Lei, Lindong Wu, Rui Sun, Yongkang Huang, Chong Long, Xiao Liu, Xuanyu Lei, Jie Tang, and Minlie Huang. 2024. https://doi.org/10.18653/v1/2024.acl-long.830 S afety B ench: Evaluating the safety of large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
-
[42]
Jonathan Zheng, Ashutosh Baheti, Tarek Naous, Wei Xu, and Alan Ritter. 2022. Stanceosaurus: Classifying stance towards multicultural misinformation. In Proceedings of the 2022 conference on empirical methods in natural language processing, pages 2132--2151
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.