Recognition: 2 theorem links
· Lean TheoremDiffuMask: Diffusion Language Model for Token-level Prompt Pruning
Pith reviewed 2026-05-10 18:11 UTC · model grok-4.3
The pith
A diffusion model prunes LLM prompts by masking many tokens in parallel per step, cutting length up to 80 percent while keeping reasoning accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
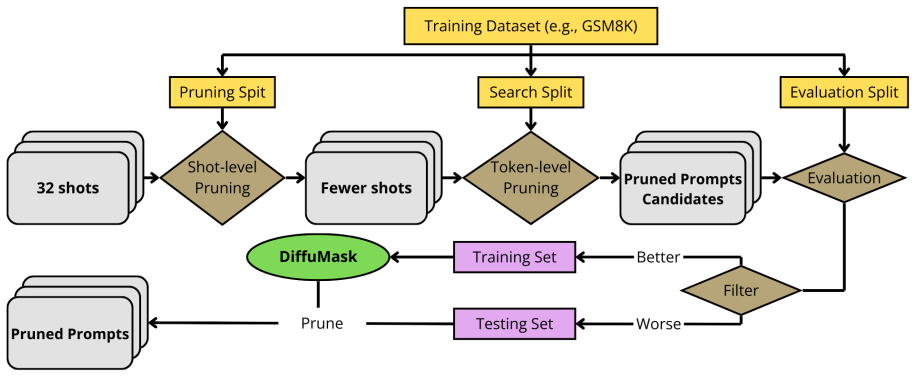
DiffuMask is a diffusion-based framework that integrates hierarchical shot-level and token-level pruning signals to perform iterative mask prediction, enabling rapid parallel prompt pruning that achieves up to 80 percent length reduction while preserving essential reasoning context and maintaining or improving accuracy across in-domain, out-of-domain, and cross-model evaluations.
What carries the argument
Iterative mask prediction inside a diffusion language model guided by combined shot-level and token-level pruning signals.
If this is right
- Prompt length can be reduced to one-fifth while the model still solves the original reasoning problem correctly.
- Compression time drops because many tokens are masked together in each denoising step instead of one by one.
- Users can adjust the retained fraction to trade off speed against fidelity for different applications.
- The same compressed prompt works across multiple models and on tasks not seen during pruning.
- Reasoning performance stays stable or improves even after aggressive pruning in both in-domain and out-of-domain settings.
Where Pith is reading between the lines
- The same diffusion masking approach could be tested on compressing full documents or dialogue histories rather than just few-shot prompts.
- If the pruning signals generalize further, they might be combined with existing gradient-based or attention-based methods to reach even higher compression ratios.
- Production systems could run the diffusion pruner once per prompt template and then reuse the shortened version for many queries, lowering repeated inference cost.
- Measuring wall-clock latency on real hardware at different compression levels would show whether the parallel masking actually translates into measurable speed-ups for end users.
Load-bearing premise
The diffusion process can reliably identify and preserve essential reasoning context using only hierarchical shot-level and token-level pruning signals without access to the downstream task loss during pruning.
What would settle it
An experiment showing that DiffuMask-compressed prompts at 80 percent reduction cause accuracy to fall more than 5 points below the uncompressed baseline on a held-out out-of-domain reasoning task would falsify the preservation claim.
Figures


read the original abstract
In-Context Learning and Chain-of-Thought prompting improve reasoning in large language models (LLMs). These typically come at the cost of longer, more expensive prompts that may contain redundant information. Prompt compression based on pruning offers a practical solution, yet existing methods rely on sequential token removal which is computationally intensive. We present DiffuMask, a diffusion-based framework integrating hierarchical shot-level and token-level pruning signals, that enables rapid and parallel prompt pruning via iterative mask prediction. DiffuMask substantially accelerates the compression process via masking multiple tokens in each denoising step. It offers tunable control over retained content, preserving essential reasoning context and achieving up to 80\% prompt length reduction. Meanwhile, it maintains or improves accuracy across in-domain, out-of-domain, and cross-model settings. Our results show that DiffuMask provides a generalizable and controllable framework for prompt compression, facilitating faster and more reliable in-context reasoning in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiffuMask, a diffusion-based framework for prompt pruning in in-context learning and chain-of-thought prompting. It integrates hierarchical shot-level and token-level pruning signals to enable parallel iterative mask prediction during denoising steps, claiming substantial acceleration of compression, tunable control over retained content, up to 80% prompt length reduction, and maintenance or improvement of accuracy across in-domain, out-of-domain, and cross-model settings.
Significance. If the empirical claims hold with proper controls, this could represent a meaningful contribution to efficient prompting techniques by replacing sequential token removal with a parallelizable diffusion process, offering generalizability and controllability that prior pruning methods lack. The novelty of applying diffusion language models to hierarchical pruning signals is a strength worth highlighting if supported by reproducible experiments.
major comments (2)
- [Methods] The central claim that hierarchical shot- and token-level signals alone suffice to preserve essential ICL reasoning context (up to 80% pruning while matching or exceeding full-prompt accuracy) rests on the assumption that the diffusion model can generalize 'importance' without access to downstream task loss. This is load-bearing because task-specific reasoning tokens in ICL/CoT are highly dependent on the particular exemplars or intermediate steps; the methods description provides no mechanism or ablation showing how the trained diffusion process reliably identifies these without task loss signals.
- [Abstract and §4] Abstract and §4 (Results): performance claims of maintained/improved accuracy with 80% reduction lack any quantitative details, baselines, error bars, ablation results, or controls for prompt length/task difficulty. Without these, it is impossible to assess whether the reported gains are attributable to the diffusion masking or to other factors, undermining verification of the cross-setting generalizability.
minor comments (2)
- [§3] Notation for the hierarchical signals (shot-level vs. token-level) should be defined more explicitly with equations or pseudocode to clarify how they are combined in the mask prediction objective.
- [Abstract] The abstract states 'maintains or improves accuracy' but does not specify the exact metrics or tasks; adding a table summarizing key results with comparisons would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major point below and have revised the paper accordingly to improve clarity, provide additional details, and strengthen the empirical support.
read point-by-point responses
-
Referee: [Methods] The central claim that hierarchical shot- and token-level signals alone suffice to preserve essential ICL reasoning context (up to 80% pruning while matching or exceeding full-prompt accuracy) rests on the assumption that the diffusion model can generalize 'importance' without access to downstream task loss. This is load-bearing because task-specific reasoning tokens in ICL/CoT are highly dependent on the particular exemplars or intermediate steps; the methods description provides no mechanism or ablation showing how the trained diffusion process reliably identifies these without task loss signals.
Authors: We agree that the training mechanism and its ability to generalize importance merit clearer exposition. DiffuMask trains the diffusion language model to predict hierarchical masks conditioned on shot-level and token-level signals extracted from the prompt structure, enabling the model to learn importance patterns from the data distribution across diverse ICL examples. The parallel denoising process refines these predictions iteratively without requiring downstream task loss. However, the original Methods section did not include sufficient detail on the training objective or supporting ablations. We have revised the Methods section to explicitly describe the conditioning and training process and added an ablation study isolating the contribution of the hierarchical signals. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (Results): performance claims of maintained/improved accuracy with 80% reduction lack any quantitative details, baselines, error bars, ablation results, or controls for prompt length/task difficulty. Without these, it is impossible to assess whether the reported gains are attributable to the diffusion masking or to other factors, undermining verification of the cross-setting generalizability.
Authors: We acknowledge that the abstract and the presentation in §4 could have included more explicit quantitative summaries. The full results section reports accuracy metrics across pruning ratios (including 80%), comparisons against baselines such as random pruning and prior sequential methods, error bars from repeated runs, and evaluations on in-domain, out-of-domain, and cross-model settings. To directly address the concern, we have expanded the abstract with key quantitative results, added further controls for prompt length and task difficulty in §4, and included additional ablation tables showing the contribution of the diffusion process versus other factors. revision: yes
Circularity Check
No circularity: derivation relies on independent diffusion modeling of pruning signals
full rationale
The paper introduces DiffuMask as a diffusion framework that learns hierarchical shot- and token-level pruning signals to perform parallel mask prediction during denoising. No equations or steps in the provided description reduce a claimed prediction or performance result to a fitted parameter on the same target quantity by construction. The method is presented as generalizable across in-domain, out-of-domain, and cross-model settings without invoking self-citations as uniqueness theorems or smuggling ansatzes. The central performance claims (up to 80% reduction while preserving accuracy) are positioned as empirical outcomes of the trained diffusion process rather than tautological renamings or self-referential fits, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DIFFUMASK frames prompt pruning as an iterative denoising process, predicting token retention masks in parallel... trained using binary cross-entropy (BCE) loss... top-k mask prediction strategy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrating hierarchical shot-level and token-level pruning signals... up to 80% prompt length reduction
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2023 conference on empirical methods in natural language processing, pages 6342–6353
Compressing context to enhance inference ef- ficiency of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 6342–6353. Zongqian Li, Yinhong Liu, Yixuan Su, and Nigel Col- lier. 2025. Prompt compression for large language models: A survey. InProceedings of the 2025 Con- ference of the Nati...
2023
-
[2]
11 Wendy Johnson and Thomas J Bouchard Jr
Text generation with diffusion language mod- els: A pre-training approach with continuous para- graph denoise. InInternational Conference on Ma- chine Learning, pages 21051–21064. PMLR. Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. 2021. What makes good in-context examples for gpt- 3?arXiv preprint arXiv:2101.06804....
-
[3]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834. William Merrill and Ashish Sabharwal. 2024. The ex- pressive power of transformers with chain of thought. InThe Twelfth International Conference on Learning Representations. Jesse Mu, Xiang Li, and Noah Goodman. 2023. Learn- ing to compress promp...
work page internal anchor Pith review arXiv 2024
-
[4]
InFind- ings of the Association for Computational Linguistics ACL 2024, pages 963–981
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. InFind- ings of the Association for Computational Linguistics ACL 2024, pages 963–981. Mihir Prabhudesai, Mengning Wu, Amir Zadeh, Kate- rina Fragkiadaki, and Deepak Pathak. 2025. Diffu- sion beats autoregressive in data-constrained settings. InThe Thirty-ninth Ann...
2024
-
[5]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 883– 902, Suzhou (China)
Can LLMs narrate tabular data? an evaluation framework for natural language representations of text-to-SQL system outputs. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 883– 902, Suzhou (China). Association for Computational Linguistics. Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, ...
2025
-
[6]
InInternational Conference on Learning Representations
Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations. Taylor Sorensen, Joshua Robinson, Christopher Rytting, Alexander Shaw, Kyle Rogers, Alexia Delorey, Mah- moud Khalil, Nancy Fulda, and David Wingate. 2022. An information-theoretic approach to prompt engi- neering without grou...
2022
-
[7]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. 10 Chanwoong Yoon, Taewhoo Lee, Hyeon Hwang, Min- byul Jeong, and Jaewoo Kang. 2024. Compact: Com- pressing retrieved documents actively for question answering. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Process- ing, pages 21424–21439. Michelle ...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.