Recognition: 2 theorem links
· Lean TheoremVDPP: Video Depth Post-Processing for Speed and Scalability
Pith reviewed 2026-05-10 17:57 UTC · model grok-4.3
The pith
VDPP refines any image depth model into temporally coherent video depth using only low-resolution geometric adjustments without RGB input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VDPP operates purely on geometric refinements in low-resolution space, achieving exceptional speed while matching the temporal coherence of E2E systems, with dense residual learning driving geometric representations rather than full reconstructions. The RGB-free architecture ensures true scalability, enabling immediate integration with any evolving image depth model and providing a superior balance of speed, accuracy, and memory efficiency for real-time edge deployment.
What carries the argument
targeted geometric refinement in low-resolution space driven by dense residual learning
Load-bearing premise
That low-resolution geometric residual refinements applied to any image depth model are sufficient to produce full temporal coherence and accuracy in video depth without RGB data or explicit scene reconstruction.
What would settle it
A benchmark comparison on standard video depth sequences with rapid camera motion where VDPP's output shows higher temporal inconsistency or lower accuracy than a current end-to-end model when both use the same underlying image depth estimator.
Figures









read the original abstract
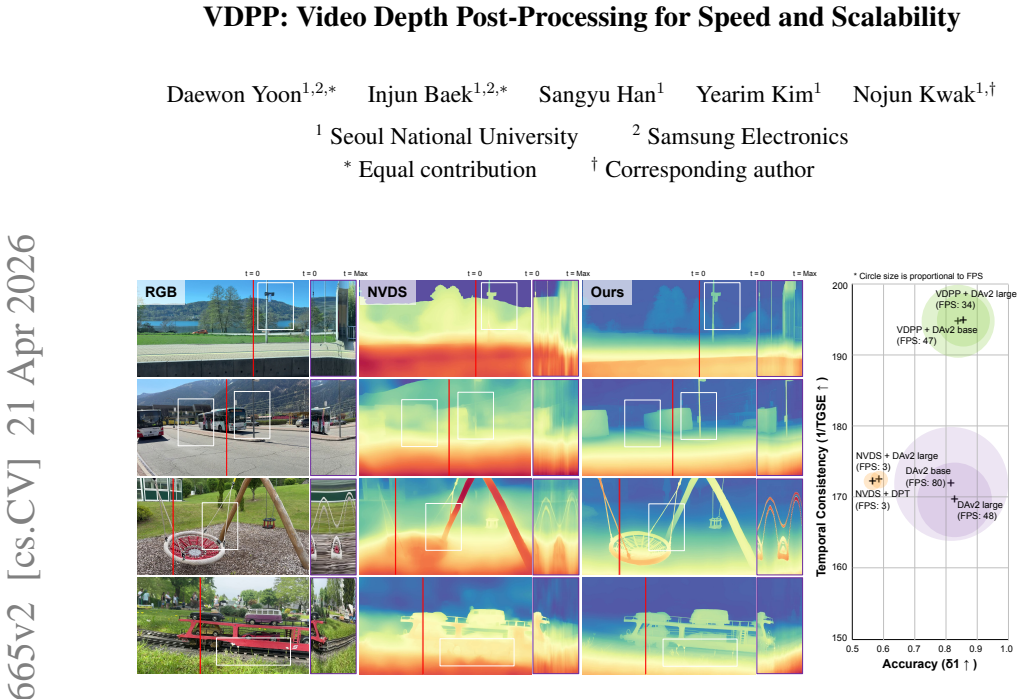
Video depth estimation is essential for providing 3D scene structure in applications ranging from autonomous driving to mixed reality. Current end-to-end video depth models have established state-of-the-art performance. Although current end-to-end (E2E) models have achieved state-of-the-art performance, they function as tightly coupled systems that suffer from a significant adaptation lag whenever superior single-image depth estimators are released. To mitigate this issue, post-processing methods such as NVDS offer a modular plug-and-play alternative to incorporate any evolving image depth model without retraining. However, existing post-processing methods still struggle to match the efficiency and practicality of E2E systems due to limited speed, accuracy, and RGB reliance. In this work, we revitalize the role of post-processing by proposing VDPP (Video Depth Post-Processing), a framework that improves the speed and accuracy of post-processing methods for video depth estimation. By shifting the paradigm from computationally expensive scene reconstruction to targeted geometric refinement, VDPP operates purely on geometric refinements in low-resolution space. This design achieves exceptional speed (>43.5 FPS on NVIDIA Jetson Orin Nano) while matching the temporal coherence of E2E systems, with dense residual learning driving geometric representations rather than full reconstructions. Furthermore, our VDPP's RGB-free architecture ensures true scalability, enabling immediate integration with any evolving image depth model. Our results demonstrate that VDPP provides a superior balance of speed, accuracy, and memory efficiency, making it the most practical solution for real-time edge deployment. Our project page is at https://github.com/injun-baek/VDPP
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VDPP, a post-processing framework for video depth estimation that performs targeted geometric refinement in low-resolution space via dense residual learning. It is designed to be RGB-free, avoid full scene reconstruction, achieve high inference speed (>43.5 FPS on NVIDIA Jetson Orin Nano), match the temporal coherence of end-to-end video depth models, and enable plug-and-play integration with any evolving single-image depth estimator without retraining.
Significance. If the performance and coherence claims are substantiated, VDPP would offer a modular and scalable alternative to tightly coupled E2E video depth models, facilitating rapid adoption of improved single-image estimators in real-time edge applications such as autonomous driving and mixed reality.
major comments (2)
- Abstract: The central claim that VDPP 'matches the temporal coherence of E2E systems' is load-bearing for the practicality argument but is unsupported by any quantitative comparisons, ablation studies, temporal consistency metrics, or failure-case analysis on dynamic scenes. The design explicitly discards RGB input (which E2E models exploit for motion and occlusion cues), so explicit deltas versus E2E baselines on relevant benchmarks are required to validate sufficiency of low-resolution geometric residuals alone.
- Abstract: The assertion of a 'superior balance of speed, accuracy, and memory efficiency' for real-time edge deployment lacks any reported accuracy numbers, memory footprints, or head-to-head comparisons against NVDS or E2E models on identical hardware and datasets, undermining evaluation of the scalability and efficiency advantages.
minor comments (2)
- Abstract: The phrase 'our results demonstrate' is used without previewing any concrete accuracy or consistency numbers beyond the FPS figure; adding one or two key quantitative highlights would improve informativeness.
- The GitHub project page link is a helpful addition for reproducibility and should be retained.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where additional quantitative evidence will strengthen the manuscript's claims. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: Abstract: The central claim that VDPP 'matches the temporal coherence of E2E systems' is load-bearing for the practicality argument but is unsupported by any quantitative comparisons, ablation studies, temporal consistency metrics, or failure-case analysis on dynamic scenes. The design explicitly discards RGB input (which E2E models exploit for motion and occlusion cues), so explicit deltas versus E2E baselines on relevant benchmarks are required to validate sufficiency of low-resolution geometric residuals alone.
Authors: We agree that explicit quantitative validation is required to support this claim. The initial manuscript relies primarily on qualitative video demonstrations for temporal coherence. In the revision, we will add direct comparisons using established temporal consistency metrics (e.g., temporal warping error) against representative E2E models on benchmarks such as KITTI and NYU-V2. We will also include an ablation study on the low-resolution residual components and failure-case analysis focused on dynamic scenes to demonstrate that geometric refinement alone suffices despite the RGB-free design. revision: yes
-
Referee: Abstract: The assertion of a 'superior balance of speed, accuracy, and memory efficiency' for real-time edge deployment lacks any reported accuracy numbers, memory footprints, or head-to-head comparisons against NVDS or E2E models on identical hardware and datasets, undermining evaluation of the scalability and efficiency advantages.
Authors: We acknowledge that the abstract claim would be more robust with explicit numerical support. The current submission reports the speed figure (>43.5 FPS on Jetson Orin Nano) and qualitative accuracy gains but does not provide tabulated head-to-head results. We will revise the abstract for precision and add tables in the experiments section with accuracy metrics (AbsRel, RMSE), memory footprints, and FPS measurements for VDPP, NVDS, and E2E baselines on the same hardware and datasets. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces VDPP as a new modular post-processing framework that replaces full scene reconstruction with targeted low-resolution geometric refinement driven by dense residual learning. No load-bearing equations, fitted parameters, or predictions are shown to reduce by construction to quantities defined inside the paper itself. Claims of matching E2E temporal coherence rest on empirical results and architectural choices rather than self-referential definitions or self-citation chains. The derivation is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from the authors' prior work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By shifting the paradigm from computationally expensive scene reconstruction to targeted geometric refinement, VDPP operates purely on geometric refinements in low-resolution space... dense residual learning driving geometric representations rather than full reconstructions.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RGB-free architecture ensures true scalability... immediate integration with any evolving image depth model.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bidirectional attention network for monocular depth estimation
Shubhra Aich, Jean Marie Uwabeza Vianney, Md Amirul Is- lam, and Mannat Kaur Bingbing Liu. Bidirectional attention network for monocular depth estimation. In2021 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 11746–11752. IEEE, 2021. 2
2021
-
[2]
A naturalistic open source movie for op- tical flow evaluation
Daniel J Butler, Jonas Wulff, Garrett B Stanley, and Michael J Black. A naturalistic open source movie for op- tical flow evaluation. InEuropean conference on computer vision, pages 611–625. Springer, 2012. 1, 5, 6, 7, 8, 14, 16
2012
-
[3]
Yohann Cabon, Naila Murray, and Martin Humenberger. Vir- tual kitti 2.arXiv preprint arXiv:2001.10773, 2020. 11
work page internal anchor Pith review arXiv 2001
-
[4]
Video depth any- thing: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zi- long Huang, Jiashi Feng, and Bingyi Kang. Video depth any- thing: Consistent depth estimation for super-long videos. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22831–22840, 2025. 2, 3, 4, 5, 6, 7, 11
2025
-
[5]
Self-supervised learning with geometric constraints in monocular video: Connecting flow, depth, and camera
Yuhua Chen, Cordelia Schmid, and Cristian Sminchis- escu. Self-supervised learning with geometric constraints in monocular video: Connecting flow, depth, and camera. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7063–7072, 2019. 3
2019
-
[6]
Depth map prediction from a single image using a multi-scale deep net- work.Advances in neural information processing systems, 27, 2014
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep net- work.Advances in neural information processing systems, 27, 2014. 2
2014
-
[7]
Deep ordinal regression net- work for monocular depth estimation
Huan Fu, Mingming Gong, Chaohui Wang, Kayhan Bat- manghelich, and Dacheng Tao. Deep ordinal regression net- work for monocular depth estimation. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 2002–2011, 2018. 2
2002
-
[8]
Vision meets robotics: The kitti dataset.The in- ternational journal of robotics research, 32(11):1231–1237,
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The in- ternational journal of robotics research, 32(11):1231–1237,
-
[9]
Depthcrafter: Generating consistent long depth sequences for open-world videos
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan. Depthcrafter: Generating consistent long depth sequences for open-world videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2005–2015, 2025. 3
2005
-
[10]
Svd: Spatial video dataset
MohammadHossein Izadimehr, Milad Ghanbari, Guodong Chen, Wei Zhou, Xiaoshuai Hao, Mallesham Dasari, Chris- tian Timmerer, and Hadi Amirpour. Svd: Spatial video dataset. InProceedings of the 33rd ACM International Con- ference on Multimedia, pages 12988–12994, 2025. 5, 6
2025
-
[11]
Ro- bust consistent video depth estimation
Johannes Kopf, Xuejian Rong, and Jia-Bin Huang. Ro- bust consistent video depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1611–1621, 2021. 3
2021
-
[12]
Jin Han Lee, Myung-Kyu Han, Dong Wook Ko, and Il Hong Suh. From big to small: Multi-scale local planar guid- ance for monocular depth estimation.arXiv preprint arXiv:1907.10326, 2019. 2
-
[13]
Depthformer: Exploiting long-range correlation and local in- formation for accurate monocular depth estimation.Machine Intelligence Research, 20(6):837–854, 2023
Zhenyu Li, Zehui Chen, Xianming Liu, and Junjun Jiang. Depthformer: Exploiting long-range correlation and local in- formation for accurate monocular depth estimation.Machine Intelligence Research, 20(6):837–854, 2023. 2
2023
-
[14]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016. 11
work page internal anchor Pith review arXiv 2016
-
[15]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Consistent video depth estimation.ACM Transactions on Graphics (ToG), 39(4):71–1, 2020
Xuan Luo, Jia-Bin Huang, Richard Szeliski, Kevin Matzen, and Johannes Kopf. Consistent video depth estimation.ACM Transactions on Graphics (ToG), 39(4):71–1, 2020. 3
2020
-
[17]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 4, 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Refusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting resid- uals
Emanuele Palazzolo, Jens Behley, Philipp Lottes, Philippe Giguere, and Cyrill Stachniss. Refusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting resid- uals. In2019 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 7855–7862. IEEE,
-
[19]
P3depth: Monocular depth estimation with a piecewise planarity prior
Vaishakh Patil, Christos Sakaridis, Alexander Liniger, and Luc Van Gool. P3depth: Monocular depth estimation with a piecewise planarity prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1610–1621, 2022. 2
2022
-
[20]
Ren ´e Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020. 2, 4
2020
-
[21]
Vi- sion transformers for dense prediction
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021. 2, 6
2021
-
[22]
Learning temporally consistent video depth from video diffusion priors
Jiahao Shao, Yuanbo Yang, Hongyu Zhou, Youmin Zhang, Yujun Shen, Vitor Guizilini, Yue Wang, Matteo Poggi, and Yiyi Liao. Learning temporally consistent video depth from video diffusion priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22841– 22852, 2025. 3
2025
-
[23]
Indoor segmentation and support inference from rgbd images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. InEuropean conference on computer vision, pages 746–760. Springer, 2012. 5, 6
2012
-
[24]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Se- bastian Scherer. Tartanair: A dataset to push the limits of visual slam. 2020. 11
2020
-
[25]
Neural video depth stabilizer
Yiran Wang, Min Shi, Jiaqi Li, Zihao Huang, Zhiguo Cao, Jianming Zhang, Ke Xian, and Guosheng Lin. Neural video depth stabilizer. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 9466–9476,
-
[26]
Nvds+: Towards efficient and versatile neural stabilizer for video depth estimation.IEEE transactions on pattern analysis and machine intelligence, 2024
Yiran Wang, Min Shi, Jiaqi Li, Chaoyi Hong, Zihao Huang, Juewen Peng, Zhiguo Cao, Jianming Zhang, Ke Xian, and Guosheng Lin. Nvds+: Towards efficient and versatile neural stabilizer for video depth estimation.IEEE transactions on pattern analysis and machine intelligence, 2024. 3
2024
-
[27]
Vita: Video transformer adaptor for robust video depth estimation.IEEE Transactions on Multimedia, 26:3302–3316, 2023
Ke Xian, Juewen Peng, Zhiguo Cao, Jianming Zhang, and Guosheng Lin. Vita: Video transformer adaptor for robust video depth estimation.IEEE Transactions on Multimedia, 26:3302–3316, 2023. 3
2023
-
[28]
Transformer-based attention networks for continuous pixel-wise prediction
Guanglei Yang, Hao Tang, Mingli Ding, Nicu Sebe, and Elisa Ricci. Transformer-based attention networks for continuous pixel-wise prediction. InProceedings of the IEEE/CVF International Conference on Computer vision, pages 16269–16279, 2021. 2
2021
-
[29]
arXiv preprint arXiv:2410.10815 , year =
Honghui Yang, Di Huang, Wei Yin, Chunhua Shen, Haifeng Liu, Xiaofei He, Binbin Lin, Wanli Ouyang, and Tong He. Depth any video with scalable synthetic data.arXiv preprint arXiv:2410.10815, 2024. 3
-
[30]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024. 3
2024
-
[31]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024. 1, 2, 3, 5, 6, 7, 8, 11
2024
-
[32]
Mamo: Leveraging memory and attention for monocular video depth estimation
Rajeev Yasarla, Hong Cai, Jisoo Jeong, Yunxiao Shi, Risheek Garrepalli, and Fatih Porikli. Mamo: Leveraging memory and attention for monocular video depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8754–8764, 2023. 3
2023
-
[33]
Consistent depth of moving objects in video.ACM Transactions on Graphics (ToG), 40(4):1–12,
Zhoutong Zhang, Forrester Cole, Richard Tucker, William T Freeman, and Tali Dekel. Consistent depth of moving objects in video.ACM Transactions on Graphics (ToG), 40(4):1–12,
-
[34]
Harley, Bokui Shen, Gordon Wet- zstein, and Leonidas J
Yang Zheng, Adam W. Harley, Bokui Shen, Gordon Wet- zstein, and Leonidas J. Guibas. Pointodyssey: A large-scale synthetic dataset for long-term point tracking. InICCV,
-
[35]
Raw Inpainted
11 VDPP: Video Depth Post-Processing for Speed and Scalability Supplementary Material Appendix In this supplementary material, we provide additional im- plementation details in Appendix A. We then offer an in- depth qualitative analysis (Appendix B) against compet- ing methods, visually validating VDPP’s superior spatio- temporal coherence in Figure 6, 7....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.