Recognition: 2 theorem links
· Lean TheoremWhen Agent Markets Arrive
Pith reviewed 2026-05-10 18:04 UTC · model grok-4.3
The pith
Agent markets generate 3.2 times the wealth of isolated agents, but common institutional choices can reduce those gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Market exchange among heterogeneous tool-using agents produces 3.2 times the wealth of self-sufficient agents, yet these gains are sensitive to institutional structure; interventions such as identity transparency and stronger competitive selection can degrade rather than improve market performance.
What carries the argument
DIAGON, a programmable market system that makes the full cycle of job posting, bidding, negotiation, execution, payment, and reputation accumulation end-to-end observable and experimentally manipulable.
Where Pith is reading between the lines
- Platform builders should run controlled variants of identity and selection rules before committing to any single design.
- If real agent cognition diverges from the simulated rules, the magnitude of market gains could change substantially.
- The simulation framework could be extended to hybrid human-agent markets to test whether the same institutional sensitivities appear.
Load-bearing premise
The heterogeneous tool-using agents and their decision rules in the DIAGON simulation are sufficiently representative of the behaviors that will appear in deployed agent cognitive-labour markets.
What would settle it
Deploying the same market rules with actual production AI agents and measuring whether total wealth reaches or falls short of 3.2 times the self-sufficient baseline.
Figures







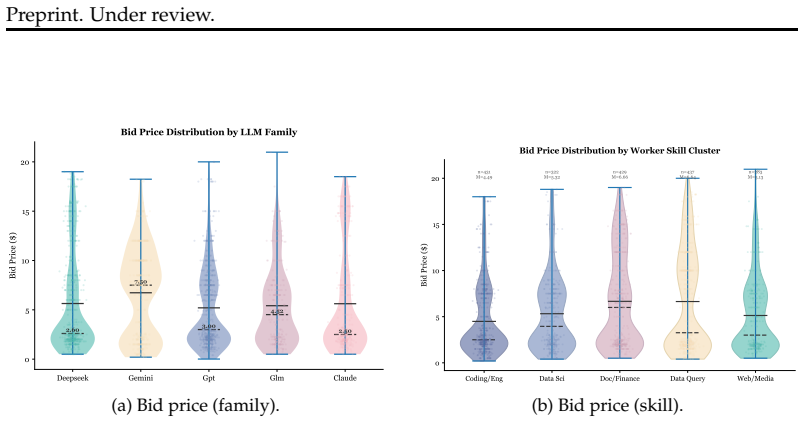
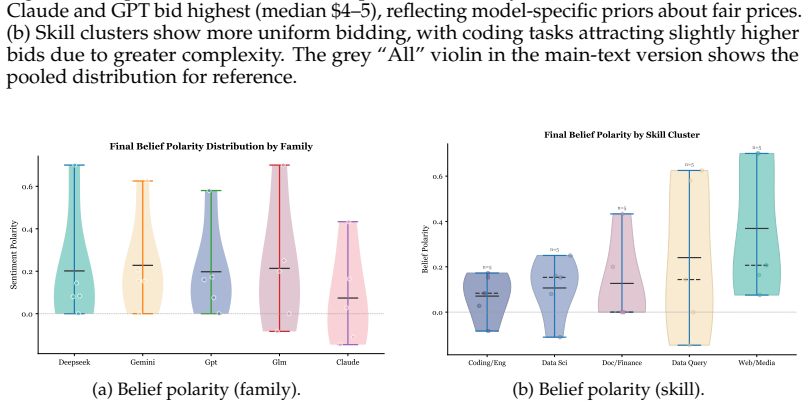




read the original abstract
AI agents are increasingly transacting on behalf of users -- delegating tasks, spending budgets, and negotiating with unfamiliar counterparties. From skill marketplaces to agent-only bazaars, the economic infrastructure of these emerging platforms is being built ad-hoc, yet early design choices tend to lock in; understanding what dynamics they produce is urgent. We present \diagon, a programmable market system designed to inform the institutional design of near-future agent cognitive-labour markets. \diagon is populated by heterogeneous tool-using agents, making the full cycle of job posting, bidding, negotiation, execution, payment, and reputation accumulation end-to-end observable and experimentally manipulable. We instantiate one market form to demonstrate \diagon. We find that market exchange generates \(3.2\times\) the wealth of self-sufficient agents, but these gains depend strongly on institutional structure; for example, interventions such as identity transparency and stronger competitive selection can degrade market performance rather than improve it. These findings highlight concrete design requirements for the economic infrastructure of the agent era. Code and data are available at https://github.com/assassin808/diagon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DIAGON, a programmable simulation platform for modeling cognitive-labour markets among heterogeneous tool-using AI agents. By simulating one specific market instantiation, the authors report that market-based exchange yields 3.2 times the wealth accumulation of self-sufficient agents. They further demonstrate that these gains are highly sensitive to institutional design choices, with interventions such as identity transparency and intensified competitive selection sometimes reducing rather than enhancing market performance.
Significance. If the simulation results hold under more varied agent behaviors, this work would be significant for the emerging field of agent economics by providing a concrete, manipulable testbed and initial quantitative insights into how market institutions affect efficiency in AI-mediated transactions. The public release of code and data is a clear strength that supports reproducibility.
major comments (2)
- [Agent Model and Simulation Setup] The 3.2× wealth multiplier and the directional effects of institutional interventions (e.g., identity transparency degrading performance) are generated by the specific bidding, negotiation, and tool-selection rules of the heterogeneous agents in DIAGON. No sensitivity sweeps or alternative policy specifications are reported, which is load-bearing for the central claim because different agent heuristics could alter both the magnitude of gains and the sign of institutional effects.
- [Results and Discussion] The experimental results for one market form report the 3.2× figure and degradation under certain interventions without accompanying variance estimates, number of random seeds, or statistical controls. This limits assessment of whether the findings are robust to stochasticity in the simulation.
minor comments (2)
- [Abstract] The GitHub link is provided but lacks a specific commit hash or release tag corresponding to the reported experiments.
- [Introduction] Notation for key agent parameters (e.g., tool utility functions or reputation update rules) could be defined earlier to aid readers in following the simulation logic.
Simulated Author's Rebuttal
Thank you for the constructive review. We respond to the major comments below, agreeing with the need for additional robustness checks and planning revisions accordingly.
read point-by-point responses
-
Referee: [Agent Model and Simulation Setup] The 3.2× wealth multiplier and the directional effects of institutional interventions (e.g., identity transparency degrading performance) are generated by the specific bidding, negotiation, and tool-selection rules of the heterogeneous agents in DIAGON. No sensitivity sweeps or alternative policy specifications are reported, which is load-bearing for the central claim because different agent heuristics could alter both the magnitude of gains and the sign of institutional effects.
Authors: We concur that the quantitative results, including the 3.2× wealth multiplier, are specific to the agent model and market rules implemented in this study. DIAGON is designed as a programmable platform, and the current work focuses on demonstrating its capabilities with a single, well-specified instantiation rather than a comprehensive parameter sweep. To strengthen the claims, we will add a new section in the revised manuscript presenting sensitivity analyses on key parameters such as bidding aggressiveness, negotiation protocols, and tool selection heuristics. These will include variations in agent heterogeneity to evaluate whether the performance gains and institutional effects persist. revision: yes
-
Referee: [Results and Discussion] The experimental results for one market form report the 3.2× figure and degradation under certain interventions without accompanying variance estimates, number of random seeds, or statistical controls. This limits assessment of whether the findings are robust to stochasticity in the simulation.
Authors: The referee is correct that variance estimates and details on random seeds are not provided in the current version. We will revise the Results section to include these: specifically, we will report results averaged over 20 independent random seeds, with standard errors, and perform basic statistical tests (e.g., t-tests) to confirm the significance of the wealth differences and intervention effects. This will be added to both the main text and supplementary materials. revision: yes
Circularity Check
No circularity: results are direct simulation outputs with no reduction to inputs by construction
full rationale
The paper reports empirical outcomes from executing the DIAGON simulation under one specific instantiation of heterogeneous agents whose bidding, negotiation, execution, and reputation rules are explicitly coded. The 3.2× wealth multiplier and directional effects of institutional interventions are generated by running the model forward; they are not obtained by fitting parameters to a data subset and then predicting a closely related quantity, nor by any self-referential definition or self-citation chain that collapses the claim back onto its own premises. The representativeness of the agent rules to future deployed systems is an external validity question, not a circularity issue. No load-bearing step in the reported derivation reduces to an algebraic identity or fitted input by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
market exchange generates 3.2× the wealth of self-sufficient agents, but these gains depend strongly on institutional structure
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
interventions such as identity transparency and stronger competitive selection can degrade market performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1038/s41562-025-02172-y. George A Akerlof. The market for “lemons”: Quality uncertainty and the market mechanism. InUncertainty in economics, pp. 235–251. Elsevier,
-
[2]
Language models as agent models
Jacob Andreas. Language models as agent models. InFindings of the Association for Computa- tional Linguistics: EMNLP 2022,
2022
-
[3]
Robert Axelrod.The Evolution of Cooperation
Accessed 2025-03-31. Robert Axelrod.The Evolution of Cooperation. Basic Books, New York,
2025
-
[4]
doi: 10.1257/aer.20190623. Alan Chan, Kevin Wei, Sihao Huang, Nitarshan Rajkumar, Elija Perrier, Seth Lazar, Gillian K Hadfield, and Markus Anderljung. Infrastructure for AI agents.Transactions on Machine Learning Research,
-
[5]
Mechanism design for large language models
Paul Duetting, Vahab Mirrokni, Renato Paes Leme, Haifeng Xu, and Song Zuo. Mechanism design for large language models. InProceedings of the ACM Web Conference 2024, pp. 144–155,
2024
-
[6]
Modular pluralism: Pluralistic alignment via multi-LLM collaboration
Shangbin Feng, Taylor Sorensen, Yuhan Liu, Jillian Fisher, Chan Young Park, Yejin Choi, and Yulia Tsvetkov. Modular pluralism: Pluralistic alignment via multi-LLM collaboration. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 4151–4171,
2024
-
[7]
Agam Goyal, Olivia Pal, Hari Sundaram, Eshwar Chandrasekharan, and Koustuv Saha
Accessed 2025-03-30. Agam Goyal, Olivia Pal, Hari Sundaram, Eshwar Chandrasekharan, and Koustuv Saha. Social simulacra in the wild: AI agent communities on Moltbook.arXiv preprint arXiv:2603.16128,
-
[8]
Gillian K Hadfield and Andrew Koh. An economy of AI agents.arXiv preprint arXiv:2509.01063,
-
[9]
arXiv preprint arXiv:2301.07543 , year=
John J Horton. Large language models as simulated economic agents: What can we learn from homo silicus?arXiv preprint arXiv:2301.07543,
-
[10]
Sayash Kapoor, Noam Kolt, and Seth Lazar
doi: 10.3982/ECTA19978. Sayash Kapoor, Noam Kolt, and Seth Lazar. Position: Build agent advocates, not platform agents. InInternational Conference on Machine Learning,
-
[11]
David M Kreps and Robert Wilson
doi: 10.1038/s41586-025-09505-x. David M Kreps and Robert Wilson. Reputation and imperfect information.Journal of Economic Theory, 27(2):253–279,
-
[12]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670,
work page internal anchor Pith review arXiv
-
[13]
Strategic collusion of LLM agents: Market division in multi-commodity competitions
Ryan Y Lin, Siddhartha Ojha, Kevin Cai, and Maxwell F Chen. Strategic collusion of LLM agents: Market division in multi-commodity competitions. InNeurIPS 2024 Workshop on Language Gamification,
2024
-
[14]
Xianyang Liu, Shangding Gu, and Dawn Song. AgenticPay: A multi-agent LLM negotiation system for buyer–seller transactions.arXiv preprint arXiv:2602.06008,
-
[15]
Xuan Liu, Haoyang Shang, and Haojian Jin. CoBRA: Programming cognitive bias in social agents using classic social science experiments.arXiv preprint arXiv:2509.13588, 2025a. Xuan Liu, Jie Zhang, HaoYang Shang, Song Guo, Chengxu Yang, and Quanyan Zhu. Ex- ploring prosocial irrationality for LLM agents: A social cognition view. InThe Thirteenth Internationa...
-
[16]
Myle Ott, Yejin Choi, Claire Cardie, and Jeffrey T Hancock
Accessed 2025-03-30. Myle Ott, Yejin Choi, Claire Cardie, and Jeffrey T Hancock. Finding deceptive opinion spam by any stretch of the imagination. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics, pp. 309–319,
2025
-
[17]
Kenneth Payne and Baptiste Alloui-Cros. Strategic intelligence in large language models: Evidence from evolutionary game theory.arXiv preprint arXiv:2507.02618,
-
[18]
doi: 10.1038/s42256-023-00646-0. Alvin E Roth. The economist as engineer: Game theory, experimentation, and computation as tools for design economics.Econometrica, 70(4):1341–1378,
-
[19]
Nenad Tomasev, Matija Franklin, Joel Z Leibo, Julian Jacobs, William A Cunningham, Iason Gabriel, and Simon Osindero. Virtual agent economies.arXiv preprint arXiv:2509.10147,
-
[20]
Michelle Vaccaro, Michael Caosun, Harang Ju, Sinan Aral, and Jared R Curhan. Advancing AI negotiations: New theory and evidence from a large-scale autonomous negotiation competition.arXiv preprint arXiv:2503.06416,
-
[21]
Isadora White, Kolby Nottingham, Ayush Maniar, Max Robinson, Hansen Lillemark, Mehul Maheshwari, Lianhui Qin, and Prithviraj Ammanabrolu. Collaborating action by action: A multi-agent LLM framework for embodied reasoning.arXiv preprint arXiv:2504.17950,
-
[22]
Reasoning or reciting? Exploring the capabilities and limitations of language models through counterfactual tasks
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Aky¨urek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. Reasoning or reciting? Exploring the capabilities and limitations of language models through counterfactual tasks. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics, pp. 1...
2024
-
[23]
Beyond numeric rewards: In-context dueling bandits with LLM agents
Fanzeng Xia, Hao Liu, Yisong Yue, and Tongxin Li. Beyond numeric rewards: In-context dueling bandits with LLM agents. InFindings of the Association for Computational Linguistics: ACL 2025,
2025
-
[24]
The effective reward becomes µ·R(τ j) and the effective execution cost becomes µ·c ex i , while backbone (thinking) cost remains unscaled. This ensures that execution cost dominates the agent’s budget— matching the economics of real outsourcing where the cost ofdoingthe work far exceeds the cost ofdecidingto do it (Williamson, 1985). Skill clusters.The se...
1985
-
[25]
and comparative advan- tage (Ricardo, 2005): an agent whose cluster si matches a task’s domain dj receives skill packages (documentation and helper scripts) that are injected into the Worker’s execution environment via prompt, improving execution quality. Skills therefore reside in thetask environment, not in the model itself; the Trader’s role is to sele...
2005
-
[26]
in his foundational study of cooperation: agents play repeated games, accumulate payoff, and the population is periodically updated so that successful strategies proliferate while unsuccessful ones are removed. In Axelrod’s original iterated prisoner’s dilemma tournaments, this mechanism produced the celebrated result thattit- for-tat—a simple reciprocity...
1998
-
[27]
where trust must be earned, not inherited. This mechanism yields 4% active-population turnover per cycle (1 /25), applied every 6 rounds—a high-frequency, low-amplitude approximation to the continuous replicator dynamic (Weibull, 1997), chosen to minimise per-event market disruption while maintaining meaningful selection pressure. Over a 100-round experim...
1997
-
[28]
−5% per successful match prevents persistent inflation
Trader budget $0.05/call Backbone cost cap Worker timeout 900 s Execution deadline Worker max turns 30 Tool-use iteration cap Table 2: Configuration parameters and their economic mechanisms. −5% per successful match prevents persistent inflation. Surge tasks are offered before fresh tasks each round (drain-first policy), ensuring that no contract is perma...
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.