A First Guess is Rarely the Final Answer: Learning to Search in the Traveling Salesperson Problem
Pith reviewed 2026-05-10 17:56 UTC · model grok-4.3
The pith
A two-stage trained neural policy learns to apply 2-opt moves and improves TSP tours more efficiently than classical local search or prior learned methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NICO-TSP is a 2-opt improvement framework that aligns its state representation with the neighborhood operator, scores moves directly, and trains via imitation on short-horizon optimal trajectories followed by critic-free group reinforcement learning. Under compute-matched evaluations the resulting policy produces stronger improvement per step than both learned baselines and classical 2-opt, generalizes reliably to out-of-distribution larger instances, and functions effectively either as a standalone local-search replacement or as a test-time refiner for constructive solvers.
What carries the argument
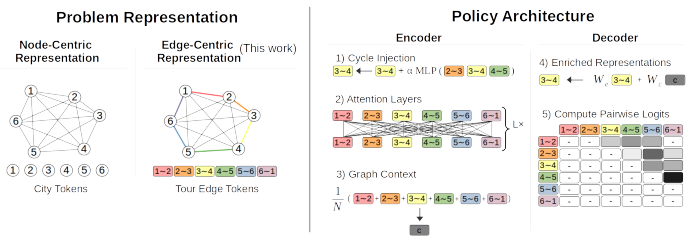
The NICO-TSP policy that uses n edge tokens aligned with the 2-opt operator, direct move scoring without tour positional encodings, and a two-stage training process of short-horizon imitation followed by group-based RL on longer trajectories.
If this is right
- NICO-TSP can serve as a direct replacement for classical local search inside existing TSP solvers.
- It can be applied at test time to refine tours produced by any constructive neural solver.
- The learned policy reaches higher-quality solutions with substantially fewer improvement steps than prior learned or heuristic search methods.
- Performance holds when instances grow larger than those seen during training.
Where Pith is reading between the lines
- The same alignment of representation to the local operator and the imitation-then-RL schedule might transfer to other combinatorial problems that rely on neighborhood-based search.
- Avoiding positional encodings for the full tour could reduce sensitivity to training instance size and ease scaling.
- If the group-based RL stage is the main driver of long-horizon stability, similar critic-free group training might benefit learned search in other domains.
Load-bearing premise
The two-stage training procedure yields policies that stay stable and effective when rolled out for many steps on instances drawn from distributions different from the training data.
What would settle it
An experiment showing that on larger out-of-distribution TSP instances NICO-TSP requires more steps than classical 2-opt to reach comparable or better solution quality would falsify the central performance and generalization claims.
Figures




read the original abstract
Most neural solvers for the Traveling Salesperson Problem (TSP) are trained to output a single solution, even though practitioners rarely stop there: at test time, they routinely spend extra compute on sampling or post-hoc search. This raises a natural question: can the search procedure itself be learned? Neural improvement methods take this perspective by learning a policy that applies local modifications to a candidate solution, accumulating gains over an improvement trajectory. Yet learned improvement for TSP remains comparatively immature, with existing methods still falling short of robust, scalable performance. We argue that a key reason is design mismatch: many approaches reuse state representations, architectural choices, and training recipes inherited from single-solution methods, rather than being built around the mechanics of local search. This mismatch motivates NICO-TSP (Neural Improvement for Combinatorial Optimization): a 2-opt improvement framework for TSP. NICO-TSP represents the current tour with exactly $n$ edge tokens aligned with the neighborhood operator, scores 2-opt moves directly without tour positional encodings, and trains via a two-stage procedure: imitation learning to short-horizon optimal trajectories, followed by critic-free group-based reinforcement learning over longer rollouts. Under compute-matched evaluations that measure improvement as a function of both search steps and wall-clock time, NICO-TSP delivers consistently stronger and markedly more step-efficient improvement than prior learned and heuristic search baselines, generalizes far more reliably to larger out-of-distribution instances, and serves both as a competitive replacement for classical local search and as a powerful test-time refinement module for constructive solvers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NICO-TSP, a 2-opt neural improvement framework for TSP. It represents tours with exactly n edge tokens aligned to the neighborhood operator, scores moves directly without positional encodings, and uses two-stage training (imitation on short-horizon optimal trajectories followed by critic-free group-based RL). Under compute-matched evaluations of improvement versus steps and wall-clock time, it claims consistently stronger and more step-efficient gains than prior learned and heuristic baselines, markedly better generalization to larger OOD instances, and utility both as a classical local-search replacement and as a test-time refiner for constructive solvers.
Significance. If the empirical claims hold under the stated protocols, the work advances learned improvement methods for combinatorial optimization by tailoring architecture and training to local-search mechanics rather than reusing single-solution designs. The two-stage procedure and operator-aligned representation offer a concrete template that could improve robustness and step-efficiency in other CO domains, with direct practical value as a drop-in module.
major comments (2)
- [§4.2] §4.2 (Training): the claim that the group-based RL stage ensures stable long-horizon behavior on OOD instances is load-bearing for the generalization and replacement-utility results, yet the section provides no ablations on rollout length, group-size sensitivity, or metrics for trajectory collapse/reward hacking; without these, the superiority over 2-opt and prior improvers cannot be fully assessed.
- [Table 3] Table 3 and §5.3 (OOD evaluation): the reported gains on instances larger than training size are presented without per-instance variance, statistical tests, or failure-case analysis; this weakens the 'far more reliably' generalization statement relative to the compute-matched protocol.
minor comments (2)
- [§3.1] §3.1: the edge-token state encoding is described in prose but would benefit from an explicit equation or small diagram showing alignment with the 2-opt neighborhood.
- [Abstract] Abstract and §1: the phrase 'compute-matched evaluations' is used without a one-sentence definition of the exact step and time budgets; this is clarified later but could be previewed for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, with revisions indicated where the manuscript will be updated to incorporate the suggestions.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Training): the claim that the group-based RL stage ensures stable long-horizon behavior on OOD instances is load-bearing for the generalization and replacement-utility results, yet the section provides no ablations on rollout length, group-size sensitivity, or metrics for trajectory collapse/reward hacking; without these, the superiority over 2-opt and prior improvers cannot be fully assessed.
Authors: We agree that explicit ablations would strengthen the evidence for the group-based RL stage's role in stable long-horizon behavior. In the revised manuscript we add ablations on rollout length and group size within §4.2, plus monitoring metrics (reward variance and trajectory diversity) to check for collapse or hacking. These results confirm that the two-stage procedure (imitation on short trajectories followed by critic-free group RL) maintains stable improvement on OOD instances, supporting the reported gains over 2-opt and prior methods. revision: yes
-
Referee: [Table 3] Table 3 and §5.3 (OOD evaluation): the reported gains on instances larger than training size are presented without per-instance variance, statistical tests, or failure-case analysis; this weakens the 'far more reliably' generalization statement relative to the compute-matched protocol.
Authors: We acknowledge that variance, statistical tests, and failure-case analysis would make the OOD claims more robust. The revised manuscript adds per-instance standard deviations to Table 3, paired t-tests for significance against baselines, and a dedicated failure-case discussion in §5.3 (with details in the appendix). These updates show the improvements remain statistically reliable and consistent with the compute-matched protocol. revision: yes
Circularity Check
No significant circularity detected; claims rest on external TSP instances and independent baselines
full rationale
The paper's core contribution is a two-stage training procedure (imitation on short-horizon optimal trajectories then critic-free group RL) for a 2-opt improvement policy, evaluated under compute-matched protocols against prior learned and heuristic baselines. No equations, self-definitional reductions, or fitted-input-as-prediction patterns appear in the provided text. Training draws on external TSP instances, and performance claims (step-efficient improvement, OOD generalization) are compared to independent methods rather than reducing to the training inputs by construction. Self-citations, if present, are not load-bearing for the central claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network hyperparameters
axioms (2)
- domain assumption TSP instances used for training and testing are drawn from standard random distributions
- domain assumption Short-horizon optimal 2-opt trajectories can be computed efficiently for imitation learning
Reference graph
Works this paper leans on
-
[1]
Neural large neighborhood search for the capacitated vehicle routing problem
André Hottung and Kevin Tierney. Neural large neighborhood search for the capacitated vehicle routing problem. InECAI 2020, pages 443–450. IOS Press,
work page 2020
-
[2]
arXiv preprint arXiv:2106.05126 , year=
André Hottung, Yeong-Dae Kwon, and Kevin Tierney. Efficient active search for combinatorial optimization problems.arXiv preprint arXiv:2106.05126,
-
[3]
Dian Meng, Zhiguang Cao, Yaoxin Wu, Yaqing Hou, Hongwei Ge, and Qiang Zhang. Eformer: An effective edge-based transformer for vehicle routing problems.arXiv preprint arXiv:2506.16428,
-
[4]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
The sine terms correspond to the signed 2D cross product and therefore disambiguate left vs
Define cos(u) k = ⟨ak, bk⟩ max(∥ak∥2∥bk∥2, ε),sin (u) k = a(1) k b(2) k −a (2) k b(1) k max(∥ak∥2∥bk∥2, ε), cos(v) k = ⟨bk, ck⟩ max(∥bk∥2∥ck∥2, ε),sin (v) k = b(1) k c(2) k −b (2) k c(1) k max(∥bk∥2∥ck∥2, ε). The sine terms correspond to the signed 2D cross product and therefore disambiguate left vs. right turns. In addition, we include two length-normali...
work page 2021
-
[7]
extends neural tour improvement beyond fixed 2-opt moves by learning a flexible neural k-opt policy. It combines a factorized move parameterization with a recurrent dual-stream decoder, and further introduces guided exploration of both feasible and infeasible intermediate states. Compared with fixed-operator methods, NeuOpt enlarges the move space and can...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.