Recognition: no theorem link
A Graph Foundation Model for Wireless Resource Allocation
Pith reviewed 2026-05-10 18:20 UTC · model grok-4.3
The pith
A pre-trained graph model for wireless networks adapts to new resource allocation tasks with few examples even when scenarios differ from training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
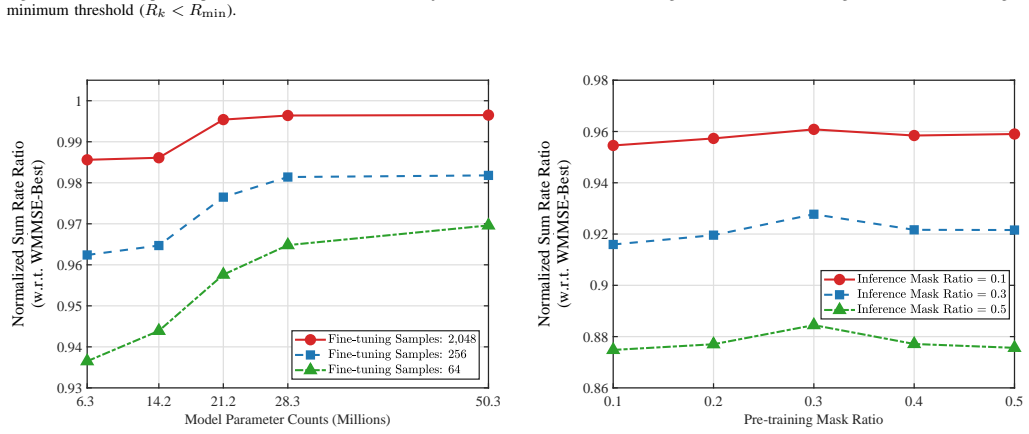
The GFM-RA model employs an interference-aware Transformer with a bias projector to inject network topologies into attention, paired with hybrid self-supervised pre-training of masked edge prediction and Teacher-Student contrastive learning on unlabeled data, yielding unified representations that deliver state-of-the-art performance, effective scaling with model size, and strong few-shot adaptation to diverse unsupervised downstream objectives in out-of-distribution scenarios.
What carries the argument
Interference-aware Transformer with bias projector that injects interference topologies into global attention, driven by a hybrid self-supervised pre-training strategy of masked edge prediction and negative-free Teacher-Student contrastive learning on unlabeled datasets.
Load-bearing premise
Pre-training on unlabeled interference data produces structural representations that transfer to new objectives and out-of-distribution network conditions with only few-shot fine-tuning.
What would settle it
Run the pre-trained model on a new set of network topologies and objectives that differ markedly from the pre-training distribution; if few-shot adaptation accuracy or convergence speed falls below that of a task-specific model trained from scratch on the same small data, the transfer claim does not hold.
Figures









read the original abstract
The aggressive densification of modern wireless networks necessitates judicious resource allocation to mitigate severe mutual interference. However, classical iterative algorithms remain computationally prohibitive for real-time applications requiring rapid responsiveness. While recent deep learning-based methods show promise, they typically function as task-specific solvers lacking the flexibility to adapt to different objectives and scenarios without expensive retraining. To address these limitations, we propose a graph foundation model for resource allocation (GFM-RA) based on a pre-training and fine-tuning paradigm to extract unified representations, thereby enabling rapid adaptation to different objectives and scenarios. Specifically, we introduce an interference-aware Transformer architecture with a bias projector that injects interference topologies into global attention mechanisms. Furthermore, we develop a hybrid self-supervised pre-training strategy that synergizes masked edge prediction with negative-free Teacher-Student contrastive learning, enabling the model to capture transferable structural representations from massive unlabeled datasets. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art performance and scales effectively with increased model capacity. Crucially, leveraging its unified representations, the foundation model exhibits exceptional sample efficiency, enabling robust few-shot adaptation to diverse and unsupervised downstream objectives in out-of-distribution (OOD) scenarios. These results demonstrate the promise of pre-trained foundation models for adaptable wireless resource allocation and provide a strong foundation for future research on generalizable learning-based wireless optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GFM-RA, a graph foundation model for wireless resource allocation. It introduces an interference-aware Transformer with a bias projector to incorporate interference topologies into global attention, paired with a hybrid self-supervised pre-training strategy (masked edge prediction combined with negative-free Teacher-Student contrastive learning) on unlabeled interference graphs. The central claims are that the resulting unified representations achieve SOTA performance, scale with model capacity, and enable exceptional few-shot adaptation to diverse unsupervised downstream objectives in OOD scenarios without expensive retraining.
Significance. If the pre-training successfully yields representations that transfer to new objectives and OOD topologies via few-shot fine-tuning, the work would be significant. It would extend the foundation-model paradigm to graph-structured wireless optimization problems, addressing the task-specific retraining burden of prior DL-based resource allocation methods and potentially improving sample efficiency in dynamic interference environments.
major comments (3)
- [Abstract] Abstract: The abstract asserts that 'extensive experiments demonstrate that the proposed framework achieves state-of-the-art performance' and that the model 'exhibits exceptional sample efficiency, enabling robust few-shot adaptation to diverse and unsupervised downstream objectives in out-of-distribution (OOD) scenarios,' yet no quantitative metrics, baseline comparisons, dataset sizes, or performance tables are provided. This directly undermines evaluation of the headline generalization claim.
- [Abstract] Abstract: The hybrid pre-training is described as capturing 'transferable structural representations from massive unlabeled datasets,' but no evidence is given that the learned embeddings encode optimization-relevant quantities (such as SINR distributions or power-control sensitivities) rather than generic graph statistics. Without such verification, the transfer to unsupervised OOD objectives remains untested.
- [Abstract] Abstract: The notions of 'out-of-distribution (OOD) scenarios' and 'unsupervised downstream objectives' are invoked without any definition, construction details, or shift metrics. This is load-bearing for the few-shot adaptation claim, as it is impossible to assess whether performance holds under the stated conditions.
minor comments (1)
- [Abstract] The bias projector is introduced as injecting interference topologies into attention but lacks even a brief functional description or comparison to standard positional or edge biases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight opportunities to strengthen the abstract's self-containment. We address each point below and will revise the abstract to incorporate key quantitative highlights, clarify the nature of the learned representations, and provide brief definitions with pointers to the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that 'extensive experiments demonstrate that the proposed framework achieves state-of-the-art performance' and that the model 'exhibits exceptional sample efficiency, enabling robust few-shot adaptation to diverse and unsupervised downstream objectives in out-of-distribution (OOD) scenarios,' yet no quantitative metrics, baseline comparisons, dataset sizes, or performance tables are provided. This directly undermines evaluation of the headline generalization claim.
Authors: We agree that the abstract would benefit from representative quantitative indicators to better support the claims. The full manuscript includes detailed experimental results, tables, and baseline comparisons in Sections 4 and 5, covering metrics such as sum-rate, convergence speed, and few-shot adaptation accuracy across multiple wireless tasks. In the revised version, we will add concise quantitative statements to the abstract, for example noting pre-training scale and relative gains in few-shot settings, while keeping the abstract length appropriate. revision: yes
-
Referee: [Abstract] Abstract: The hybrid pre-training is described as capturing 'transferable structural representations from massive unlabeled datasets,' but no evidence is given that the learned embeddings encode optimization-relevant quantities (such as SINR distributions or power-control sensitivities) rather than generic graph statistics. Without such verification, the transfer to unsupervised OOD objectives remains untested.
Authors: The masked edge prediction objective is explicitly designed around interference graph edges that determine SINR and power sensitivities, while the negative-free contrastive component encourages invariance to topology-preserving augmentations relevant to wireless scenarios. Although we do not include direct embedding analyses (e.g., correlations with SINR histograms) in the current version, the strong empirical transfer to downstream optimization tasks provides supporting evidence. We will add a short discussion in the revised manuscript linking the pre-training losses to optimization-relevant quantities and, if space permits, include a supplementary figure showing representation correlations. revision: partial
-
Referee: [Abstract] Abstract: The notions of 'out-of-distribution (OOD) scenarios' and 'unsupervised downstream objectives' are invoked without any definition, construction details, or shift metrics. This is load-bearing for the few-shot adaptation claim, as it is impossible to assess whether performance holds under the stated conditions.
Authors: We will revise the abstract to include concise definitions: OOD scenarios refer to interference graphs drawn from distributions differing in node density, path-loss exponents, or shadowing statistics from the pre-training data, while unsupervised downstream objectives encompass tasks such as power control and link scheduling solved via the frozen encoder plus lightweight heads without task-specific labels. Construction details and quantitative shift measures (e.g., graph-level distribution distances) appear in Section 3.3 and the appendix; we will add a parenthetical reference in the abstract. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a standard pre-training/fine-tuning pipeline for a graph foundation model: an interference-aware Transformer is pre-trained via masked edge prediction plus negative-free contrastive learning on unlabeled graphs, then adapted via few-shot fine-tuning to downstream resource-allocation objectives. No equations or claims reduce a prediction to its own fitted inputs by construction; the pre-training objectives are defined independently of the target supervised or unsupervised tasks, and reported gains are framed as empirical outcomes on held-out OOD scenarios rather than algebraic identities. Self-citations are not invoked as load-bearing uniqueness theorems. The derivation therefore remains self-contained against external data and benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised pre-training on graph structures learns transferable representations for downstream tasks
invented entities (1)
-
bias projector
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AI empowered wireless communications: From bits to semantics,
Z. Qin, L. Liang, Z. Wang, S. Jin, X. Tao, W. Tong, and G. Y . Li, “AI empowered wireless communications: From bits to semantics,”Proc. IEEE, vol. 112, no. 7, pp. 621–652, Jul. 2024
2024
-
[2]
A survey of graph-based resource man- agement in wireless networks—Part II: Learning approaches,
Y . Dai, L. Lyu, N. Cheng, M. Sheng, J. Liu, X. Wang, S. Cui, L. Cai, and X. Shen, “A survey of graph-based resource man- agement in wireless networks—Part II: Learning approaches,” IEEE Trans. Cogn. Commun. Netw., vol. 10, no. 4, pp. 1–1, 2024, early Access
2024
-
[3]
Weighted sum-rate maximization using weighted MMSE for MIMO-BC beamforming design,
S. S. Christensen, R. Agarwal, E. de Carvalho, and J. M. Cioffi, “Weighted sum-rate maximization using weighted MMSE for MIMO-BC beamforming design,”IEEE Trans. Wireless Com- mun., vol. 7, no. 12, pp. 4868–4877, Dec. 2008
2008
-
[4]
Fractional programming for communica- tion systems—Part I: Power control and beamforming,
K. Shen and W. Yu, “Fractional programming for communica- tion systems—Part I: Power control and beamforming,”IEEE Trans. Signal Process., vol. 66, no. 10, pp. 2616–2630, May 2018
2018
-
[5]
Fractional programming for communication systems— Part II: Uplink scheduling via matching,
——, “Fractional programming for communication systems— Part II: Uplink scheduling via matching,”IEEE Trans. Signal Process., vol. 66, no. 10, pp. 2631–2644, May 2018
2018
-
[6]
Learning to optimize: Training deep neural networks for interference management,
H. Sun, X. Chen, Q. Shi, M. Hong, X. Fu, and N. D. Sidiropou- los, “Learning to optimize: Training deep neural networks for interference management,”IEEE Trans. Signal Process., vol. 66, no. 20, pp. 5438–5453, Oct. 2018
2018
-
[7]
Spatial deep learning for wireless scheduling,
W. Cui, K. Shen, and W. Yu, “Spatial deep learning for wireless scheduling,”IEEE J. Sel. Areas Commun., vol. 37, no. 6, pp. 1248–1261, Jun. 2019
2019
-
[8]
Spectrum sharing in vehicular networks based on multi-agent reinforcement learning,
L. Liang, H. Ye, and G. Y . Li, “Spectrum sharing in vehicular networks based on multi-agent reinforcement learning,”IEEE J. Sel. Areas Commun., vol. 37, no. 10, pp. 2282–2292, Oct. 2019
2019
-
[9]
Graph neural networks for scalable radio resource management: Architecture design and theoretical analysis,
Y . Shen, Y . Shi, J. Zhang, and K. B. Letaief, “Graph neural networks for scalable radio resource management: Architecture design and theoretical analysis,”IEEE J. Sel. Areas Commun., vol. 39, no. 1, pp. 101–115, Nov. 2020
2020
-
[10]
Graph neural networks for wireless communications: From theory to practice,
Y . Shen, J. Zhang, S. H. Song, and K. B. Letaief, “Graph neural networks for wireless communications: From theory to practice,”IEEE Trans. Wireless Commun., vol. 22, no. 5, pp. 3554–3569, Nov. 2022
2022
-
[11]
State-augmented learnable algorithms for resource management in wireless net- works,
N. NaderiAlizadeh, M. Eisen, and A. Ribeiro, “State-augmented learnable algorithms for resource management in wireless net- works,”IEEE Trans. Signal Process., vol. 70, pp. 5898–5912, Dec. 2022
2022
-
[12]
Meta-learning for wireless communications: A survey and a comparison to GNNs,
B. Zhao, J. Wu, Y . Ma, and C. Yang, “Meta-learning for wireless communications: A survey and a comparison to GNNs,”IEEE Open J. Commun. Soc., vol. 5, pp. 1987–2015, Apr. 2024
1987
-
[13]
Modular meta-learning for power control via random edge graph neural networks,
I. Nikoloska and O. Simeone, “Modular meta-learning for power control via random edge graph neural networks,”IEEE Trans. Wireless Commun., vol. 22, no. 1, pp. 457–470, Jan. 2023
2023
-
[14]
Meta-gating framework for fast and continuous resource optimization in dynamic wireless environments,
Q. Hou, M. Lee, G. Yu, and Y . Cai, “Meta-gating framework for fast and continuous resource optimization in dynamic wireless environments,”IEEE Trans. Commun., vol. 71, no. 9, pp. 5259– 5273, Sep. 2023
2023
-
[15]
Large language models for wireless communications: From adaptation to autonomy,
L. Liang, H. Ye, Y . Sheng, O. Wang, J. Wang, S. Jin, and G. Y . Li, “Large language models for wireless communications: From adaptation to autonomy,”IEEE Commun. Mag., pp. 1–8, Mar. 2026, early Access
2026
-
[16]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inProc. NAACL, Minneapolis, MN, USA, 2019, pp. 4171–4186
2019
-
[17]
Language models are few- shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantanet al., “Language models are few- shot learners,” inProc. NeurIPS, vol. 33, 2020, pp. 1877–1901
2020
-
[18]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghaniet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in Proc. ICLR, Vienna, Austria, 2021
2021
-
[19]
Large wireless model (LWM): A foundation model for wireless channels,
S. Alikhani, G. Charan, and A. Alkhateeb, “Large wireless model (LWM): A foundation model for wireless channels,” arXiv preprint arXiv:2411.08872, 2024
-
[20]
WirelessGPT: A generative pretrained multi-task learning framework for wireless commu- nication,
T. Yang, P. Zhang, M. Zhenget al., “WirelessGPT: A generative pretrained multi-task learning framework for wireless commu- nication,”IEEE Network, vol. 39, no. 5, pp. 58–65, sep 2025
2025
-
[21]
WiFo-2: a generalist foundation model unifies heterogeneous wireless system design
B. Liu, X. Liu, S. Gao, X. Cheng, and L. Yang, “Foundation model for intelligent wireless communications,”arXiv preprint arXiv:2511.22222, nov 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Deeper insights into graph convo- lutional networks for semi-supervised learning,
Q. Li, Z. Han, and X. Wu, “Deeper insights into graph convo- lutional networks for semi-supervised learning,” inProc. AAAI, vol. 32, no. 1, 2018
2018
-
[23]
Measuring and relieving the over-smoothing problem for graph neural networks from the topological view,
D. Chen, Y . Lin, W. Li, P. Li, J. Zhou, and X. Sun, “Measuring and relieving the over-smoothing problem for graph neural networks from the topological view,” inProc. AAAI, vol. 34, no. 04, 2020, pp. 3438–3445
2020
-
[24]
Do transformers really perform badly for graph representation?
C. Ying, T. Cai, S. Luo, S. Zheng, G. Ke, D. He, Y . Wang, and T.-Y . Liu, “Do transformers really perform badly for graph representation?” inProc. NeurIPS, vol. 34, 2021, pp. 28 877– 28 888
2021
-
[25]
Highly accurate protein structure predic- tion with AlphaFold,
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Figurnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. ˇZ´ıdek, A. Potapenkoet al., “Highly accurate protein structure predic- tion with AlphaFold,”Nature, vol. 596, no. 7873, pp. 583–589, Aug. 2021
2021
-
[26]
GPT- GNN: Generative pre-training of graph neural networks,
Z. Hu, Y . Dong, K. Wang, K.-W. Chang, and Y . Sun, “GPT- GNN: Generative pre-training of graph neural networks,” in Proc. ACM SIGKDD, Aug. 2020, pp. 1857–1867
2020
-
[27]
GraphMAE: Self-supervised masked graph autoencoders,
Z. Hou, X. Liu, Y . Cen, Y . Dong, H. Yang, C. Wang, and J. Tang, “GraphMAE: Self-supervised masked graph autoencoders,” in 13 Proc. ACM SIGKDD, Aug. 2022, pp. 594–604
2022
-
[28]
Strategies for pre-training graph neural networks.arXiv preprint arXiv:1905.12265, 2019
W. Hu, B. Liu, J. Gomes, M. Zitnik, P. Liang, V . Pande, and J. Leskovec, “Strategies for pre-training graph neural networks,” arXiv preprint arXiv:1905.12265, Feb. 2020
-
[29]
Graph contrastive learning with augmentations,
Y . You, T. Chen, Y . Sui, T. Chen, Z. Wang, and Y . Shen, “Graph contrastive learning with augmentations,” inProc. NeurIPS, 2020
2020
-
[30]
Deep graph infomax,
P. Veli ˇckovi´c, W. Fedus, W. L. Hamilton, P. Li`o, Y . Bengio, and R. D. Hjelm, “Deep graph infomax,” inProc. ICLR, 2019
2019
-
[31]
Dyer, Rémi Munos, Petar Veličković, and Michal Valko
S. Thakoor, C. Tallec, M. G. Azar, R. Munos, P. Veli ˇckovi´c, and M. Valko, “Bootstrapped representation learning on graphs,” arXiv preprint arXiv:2102.06514, 2021
-
[32]
SimGRACE: A simple framework for graph contrastive learning without data augmentation,
J. Xia, L. Wu, J. Chen, B. Hu, and S. Z. Li, “SimGRACE: A simple framework for graph contrastive learning without data augmentation,” inProc. ACM Web Conf., Apr. 2022, pp. 1070– 1079
2022
-
[33]
Unfolding WMMSE using graph neural networks for efficient power allocation,
A. Chowdhury, G. Verma, C. Rao, A. Swami, and S. Segarra, “Unfolding WMMSE using graph neural networks for efficient power allocation,”IEEE Trans. Wireless Commun., vol. 20, no. 9, pp. 6004–6017, Apr. 2021
2021
-
[34]
Learning re- silient radio resource management policies with graph neural networks,
N. NaderiAlizadeh, M. Eisen, and A. Ribeiro, “Learning re- silient radio resource management policies with graph neural networks,”IEEE Trans. Signal Process., vol. 71, pp. 995–1009, Mar. 2023
2023
-
[35]
Downlink cellular network anal- ysis with multi-slope path loss models,
X. Zhang and J. G. Andrews, “Downlink cellular network anal- ysis with multi-slope path loss models,”IEEE Trans. Commun., vol. 63, no. 5, pp. 1881–1894, May 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.