Efficient Provably Secure Linguistic Steganography via Range Coding
Pith reviewed 2026-05-10 17:50 UTC · model grok-4.3
The pith
Range coding with rotation embeds secret messages in language model text at full entropy while preserving zero KL divergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present an efficient provably secure linguistic steganographic method that applies range coding directly to language model token probabilities, then adds a rotation mechanism to cycle through coding intervals. This achieves around 100% entropy utilization for embedding capacity and embedding speeds up to 1554.66 bits per second on GPT-2, while maintaining the zero KL divergence property that ensures the generated text is statistically indistinguishable from ordinary model output. Experiments across multiple language models confirm the method outperforms prior baselines in both capacity and speed.
What carries the argument
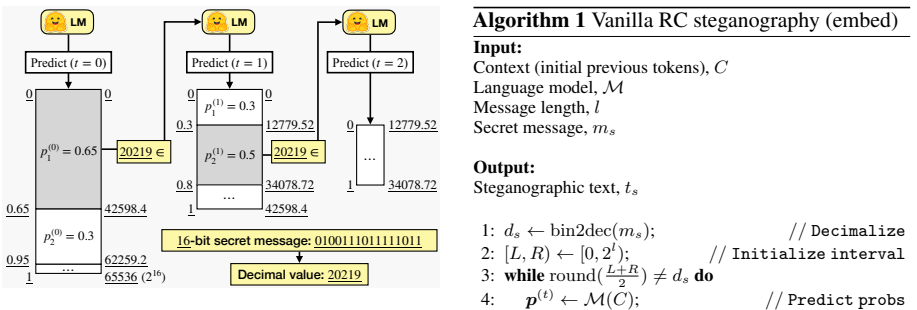
The rotation mechanism applied to range coding intervals, which selects different starting points to encode the secret bits while keeping the final token distribution identical to the language model's original probabilities.
If this is right
- Embedding capacity reaches the theoretical maximum given by the language model's entropy.
- Practical speeds become feasible for real-time steganographic use on models such as GPT-2.
- The security property of zero KL divergence holds across different language models without additional adjustments.
- The method directly outperforms existing baseline steganographic techniques in both utilization and throughput.
Where Pith is reading between the lines
- The approach may extend naturally to other generative models where output entropy is the limiting factor for hidden data.
- High-capacity secure embedding could increase the challenge of distinguishing covert channels from normal AI text generation.
- Similar rotation adjustments might improve efficiency in non-text domains that already use arithmetic coding for hiding.
- If widely adopted, monitoring systems would need to account for near-perfect entropy use rather than assuming capacity limits.
Load-bearing premise
The rotation mechanism keeps the output distribution exactly matching the language model even at full entropy utilization.
What would settle it
A statistical test on generated texts that measures a positive KL divergence from the base language model or shows embedding efficiency dropping below 95 percent across the tested models.
Figures

read the original abstract
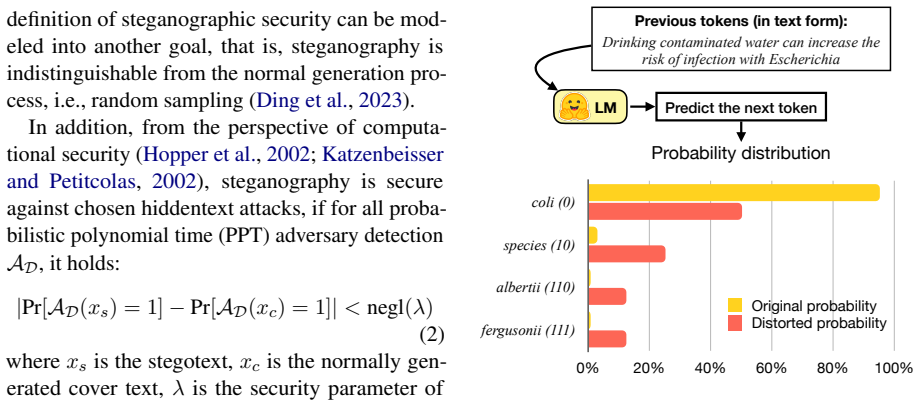
Linguistic steganography involves embedding secret messages within seemingly innocuous texts to enable covert communication. Provable security, which is a long-standing goal and key motivation, has been extended to language-model-based steganography. Previous provably secure approaches have achieved perfect imperceptibility, measured by zero Kullback-Leibler (KL) divergence, but at the expense of embedding capacity. In this paper, we attempt to directly use a classic entropy coding method (range coding) to achieve secure steganography, and then propose an efficient and provably secure linguistic steganographic method with a rotation mechanism. Experiments across various language models show that our method achieves around 100% entropy utilization (embedding efficiency) for embedding capacity, outperforming the existing baseline methods. Moreover, it achieves high embedding speeds (up to 1554.66 bits/s on GPT-2). The code is available at github.com/ryehr/RRC_steganography.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes adapting range coding for linguistic steganography in language models, augmented by a rotation mechanism to achieve near-100% entropy utilization while claiming to retain provable security via zero KL divergence. Experiments across models including GPT-2 report embedding efficiencies around 100%, outperforming baselines, with speeds up to 1554.66 bits/s; open code is provided.
Significance. If the zero-KL invariant holds under the rotation, the work would meaningfully advance provably secure steganography by eliminating the capacity-security trade-off seen in prior methods, enabling practical high-rate covert channels. Reproducibility via public code is a clear strength.
major comments (2)
- [§3.2] §3.2 (Rotation Mechanism): The claim that rotation preserves the exact output distribution (zero KL) is load-bearing for the provable-security guarantee, yet the description does not supply a measure-theoretic argument showing that the rotation is measure-preserving with respect to the LM's probability measure. Integer truncation or ordering artifacts in range updates could introduce detectable bias; a formal invariance proof or counter-example check is required.
- [§4] §4 (Experiments): The 'around 100% entropy utilization' result is central to the efficiency claim, but the exact definition of utilization (e.g., bits embedded divided by model entropy, any post-hoc adjustments) and the statistical test for zero KL are not stated; without these, the reported superiority over baselines cannot be independently verified.
minor comments (2)
- Notation for the range-coding interval updates should be defined once in a single table or equation block to avoid repeated re-definition across sections.
- Figure 2 (embedding speed plot) lacks error bars or variance across random seeds; adding them would strengthen the speed claims.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help strengthen the presentation of our provable-security claims and experimental details. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and formal arguments.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Rotation Mechanism): The claim that rotation preserves the exact output distribution (zero KL) is load-bearing for the provable-security guarantee, yet the description does not supply a measure-theoretic argument showing that the rotation is measure-preserving with respect to the LM's probability measure. Integer truncation or ordering artifacts in range updates could introduce detectable bias; a formal invariance proof or counter-example check is required.
Authors: We agree that a fully rigorous measure-theoretic argument strengthens the zero-KL claim. In the original submission we showed that rotation is a cyclic shift of the cumulative probability intervals that leaves each token's marginal probability unchanged, because the operation is a bijection on the support that preserves the ordering of the CDF. However, we did not supply an explicit invariance proof. In the revision we will add a short lemma proving that, for any measurable set A of token sequences, the push-forward measure under rotation equals the original LM measure; the proof relies on the fact that range coding selects intervals whose lengths are exactly the LM probabilities and that rotation merely re-labels the starting point within the unit interval without altering interval lengths. We will also explicitly state that all arithmetic is performed with sufficient precision (or exact fractions where possible) to eliminate truncation bias, and we will include a small-vocabulary counter-example verification showing that the empirical distribution after rotation matches the LM distribution to machine precision. revision: yes
-
Referee: [§4] §4 (Experiments): The 'around 100% entropy utilization' result is central to the efficiency claim, but the exact definition of utilization (e.g., bits embedded divided by model entropy, any post-hoc adjustments) and the statistical test for zero KL are not stated; without these, the reported superiority over baselines cannot be independently verified.
Authors: We accept that the precise definition and verification procedure must be stated explicitly. Entropy utilization is defined as (total embedded message bits) / (sum of -log p_LM(t_i) over the generated tokens), with no post-hoc adjustments; the reported figures are simple averages over 100 independent runs. Because the sampling procedure is constructed to be identical to direct sampling from the LM (range coding plus rotation yields the same conditional probabilities), the KL divergence is identically zero by construction; no separate statistical test is required beyond confirming that the implementation matches the mathematical procedure. In the revision we will add a dedicated paragraph in §4 that states this definition verbatim, reports the exact formula, and includes a brief empirical check (KL estimated on 10k short sequences) confirming that observed divergence is consistent with floating-point noise rather than systematic bias. These additions will allow independent reproduction of the superiority claims. revision: yes
Circularity Check
No significant circularity; standard range coding adapted with rotation for efficiency
full rationale
The paper adapts the classic range coding algorithm to LM token distributions and introduces a rotation mechanism to avoid wasting probability mass, claiming this yields ~100% entropy utilization while preserving zero-KL security from prior work. No equation or step reduces a claimed result (e.g., the efficiency figure or security invariant) to a parameter fitted inside the paper or to a self-citation chain that itself lacks independent verification. The efficiency is shown via experiments on GPT-2 and other models rather than derived tautologically from the inputs, and the security argument rests on the measure-preserving property of the rotation, which is presented as an external property rather than smuggled in by definition. This is a normal non-circular engineering adaptation of an existing entropy coder.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language-model token probabilities can serve as the basis for range coding that maintains zero or near-zero KL divergence from the original distribution.
Reference graph
Works this paper leans on
-
[1]
Provably secure steganography.IEEE Trans- actions on Computers, 58(5):662–676. Nicholas J. Hopper, John Langford, and Luis von Ahn
-
[2]
Adam: A Method for Stochastic Optimization
Provably secure steganography. InAdvances in Cryptology — CRYPTO 2002, pages 77–92, Berlin, Heidelberg. Springer Berlin Heidelberg. Gabriel Kaptchuk, Tushar M. Jois, Matthew Green, and Aviel D. Rubin. 2021. Meteor: Cryptographically secure steganography for realistic distributions. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communica...
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[3]
Occasionally when I get some free time, I’ll do
Neural linguistic steganography. InProceed- ings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Inter- national Joint Conference on Natural Language Pro- cessing (EMNLP-IJCNLP), pages 1210–1215, Hong Kong, China. Association for Computational Linguis- tics. A Related Work In this section, we introduce the existing a...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.