Recognition: 2 theorem links
· Lean TheoremMemCoT: Test-Time Scaling through Memory-Driven Chain-of-Thought
Pith reviewed 2026-05-10 17:43 UTC · model grok-4.3
The pith
MemCoT converts long-context reasoning in language models into iterative stateful search using multi-view memory and dual short-term tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MemCoT redefines the reasoning process by transforming long-context reasoning into an iterative, stateful information search. It introduces a multi-view long-term memory perception module that performs Zoom-In evidence localization followed by Zoom-Out contextual expansion, and it adds a task-conditioned dual short-term memory system consisting of semantic state memory and episodic trajectory memory that records historical search decisions and dynamically guides query decomposition and pruning across iterations.
What carries the argument
The multi-view long-term memory perception module for zoom-in localization and zoom-out expansion, paired with a task-conditioned dual short-term memory system of semantic state memory and episodic trajectory memory that tracks history to direct subsequent steps.
If this is right
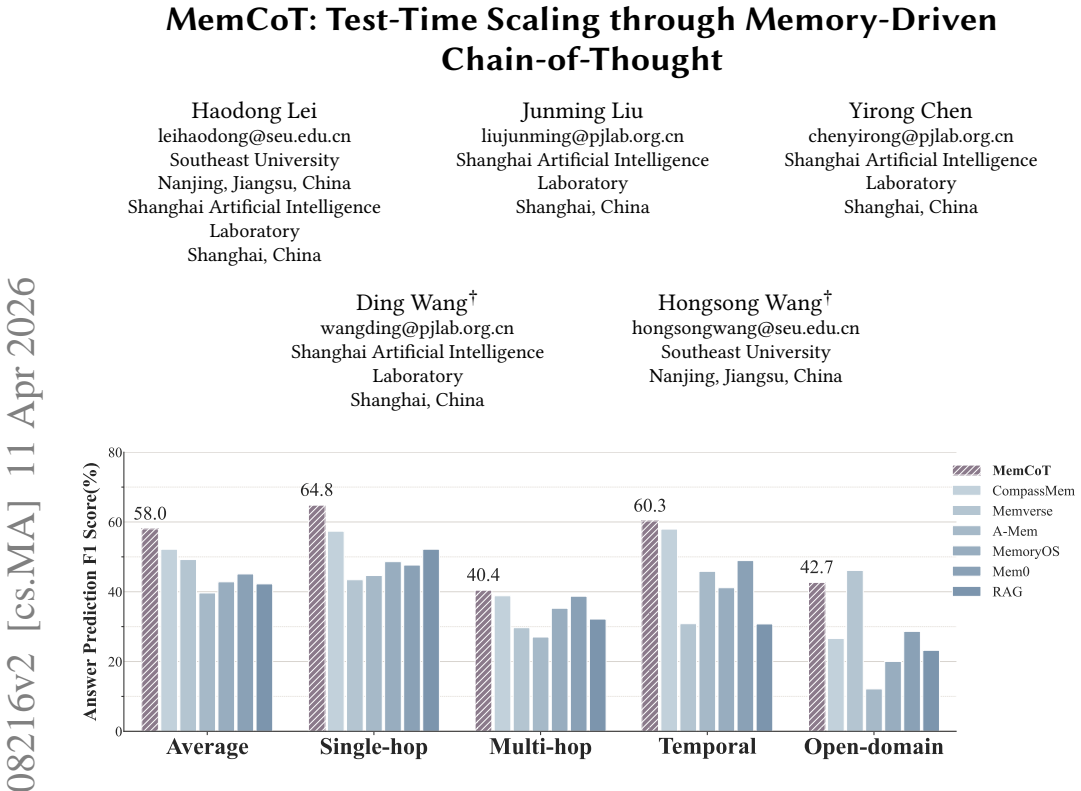
- Several open- and closed-source models achieve state-of-the-art results on the LoCoMo and LongMemEval-S benchmarks.
- Reasoning shifts from passive retrieval matching to active iterative search that maintains causal structure.
- Semantic dilution decreases because the model first isolates evidence then reconstructs surrounding context.
- Historical search decisions stored in episodic trajectory memory allow dynamic pruning and better query decomposition over multiple steps.
Where Pith is reading between the lines
- The same iterative memory loop could be tested on multi-document summarization tasks where context spans dozens of sources.
- If the dual memory overhead proves low, deployment systems might adopt it as a lightweight wrapper around existing context windows.
- The zoom-in then zoom-out pattern may generalize to visual reasoning agents that must locate then integrate evidence across image sequences.
Load-bearing premise
The proposed multi-view long-term memory and task-conditioned dual short-term memory will reliably reduce semantic dilution and contextual fragmentation without adding new failure modes or excessive overhead.
What would settle it
Apply MemCoT to models on the LoCoMo benchmark and observe whether hallucination rates and forgetting remain comparable to or higher than standard chain-of-thought baselines on the same long fragmented contexts.
Figures




read the original abstract
Large Language Models (LLMs) still suffer from severe hallucinations and catastrophic forgetting during causal reasoning over massive, fragmented long contexts. Existing memory mechanisms typically treat retrieval as a static, single-step passive matching process, leading to severe semantic dilution and contextual fragmentation. To overcome these fundamental bottlenecks, we propose MemCoT, a test-time memory scaling framework that redefines the reasoning process by transforming long-context reasoning into an iterative, stateful information search. MemCoT introduces a multi-view long-term memory perception module that enables Zoom-In evidence localization and Zoom-Out contextual expansion, allowing the model to first identify where relevant evidence resides and then reconstruct the surrounding causal structure necessary for reasoning. In addition, MemCoT employs a task-conditioned dual short-term memory system composed of semantic state memory and episodic trajectory memory. This short-term memory records historical search decisions and dynamically guides query decomposition and pruning across iterations. Empirical evaluations demonstrate that MemCoT establishes a state-of-the-art performance. Empowered by MemCoT, several open- and closed-source models achieve SOTA performance on the LoCoMo benchmark and LongMemEval-S benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemCoT, a test-time scaling framework for LLMs that addresses hallucinations and catastrophic forgetting in long-context causal reasoning. It introduces a multi-view long-term memory perception module enabling Zoom-In evidence localization and Zoom-Out contextual expansion, plus a task-conditioned dual short-term memory system (semantic state memory and episodic trajectory memory) that records historical decisions to guide iterative query decomposition and pruning. The central claim is that this architecture transforms static retrieval into stateful iterative search and delivers SOTA results on the LoCoMo and LongMemEval-S benchmarks across open- and closed-source models.
Significance. If the performance claims are substantiated with proper controls, MemCoT would offer a practical advance in test-time memory mechanisms for long-context reasoning, directly targeting semantic dilution and fragmentation that plague existing retrieval-augmented approaches. The iterative, multi-view design could generalize to other benchmarks requiring sustained causal structure over fragmented inputs.
major comments (3)
- [Abstract and §5] Abstract and §5 (Empirical Evaluations): The SOTA claims on LoCoMo and LongMemEval-S are stated without any description of experimental setup, chosen baselines, number of iterations, error bars, statistical significance, or ablation studies. This prevents assessment of whether gains arise from the proposed multi-view long-term memory and dual short-term memory or simply from additional test-time compute.
- [§4] §4 (Method, dual short-term memory): The task-conditioned semantic and episodic trajectory memories are described at a high level, but no formal specification, pseudocode, or analysis of the iterative loop is provided. In particular, there is no demonstration that performance deltas survive removal of the episodic trajectory memory or explicit caps on maximum iterations, leaving open the possibility of compounding errors in query decomposition and pruning.
- [§5] §5 (Results): The central claim that MemCoT establishes SOTA requires evidence that the reported improvements are robust to controls for iteration count and error propagation in the dual-memory loop. Without ablations isolating the Zoom-In/Zoom-Out module and the episodic memory component, the benchmark results cannot be attributed to the architecture rather than unaccounted compute.
minor comments (1)
- [Abstract] Abstract: Consider adding one sentence specifying the models and exact benchmark scores to make the SOTA claim more concrete for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the opportunity to clarify the experimental rigor and methodological details of MemCoT. We address each major comment below and have prepared revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Empirical Evaluations): The SOTA claims on LoCoMo and LongMemEval-S are stated without any description of experimental setup, chosen baselines, number of iterations, error bars, statistical significance, or ablation studies. This prevents assessment of whether gains arise from the proposed multi-view long-term memory and dual short-term memory or simply from additional test-time compute.
Authors: We agree that the abstract and §5 would benefit from greater transparency regarding the experimental protocol. In the revised manuscript, we will expand the abstract with a concise summary of key setup parameters and substantially augment §5 to include a full description of the experimental setup, all chosen baselines, the specific number of iterations used in the iterative search, error bars computed over multiple runs, statistical significance testing, and targeted ablation studies. These additions will allow readers to evaluate whether the reported gains derive from the multi-view long-term memory and dual short-term memory components rather than unaccounted test-time compute. revision: yes
-
Referee: [§4] §4 (Method, dual short-term memory): The task-conditioned semantic and episodic trajectory memories are described at a high level, but no formal specification, pseudocode, or analysis of the iterative loop is provided. In particular, there is no demonstration that performance deltas survive removal of the episodic trajectory memory or explicit caps on maximum iterations, leaving open the possibility of compounding errors in query decomposition and pruning.
Authors: We acknowledge that §4 currently presents the dual short-term memory system at a conceptual level. We will revise this section to include formal mathematical specifications for the semantic state memory and episodic trajectory memory, along with pseudocode for the complete iterative loop. We will also add new experiments that isolate the contribution of the episodic trajectory memory (performance with and without it) and that apply explicit caps on the maximum number of iterations, thereby addressing concerns about potential compounding errors in query decomposition and pruning. revision: yes
-
Referee: [§5] §5 (Results): The central claim that MemCoT establishes SOTA requires evidence that the reported improvements are robust to controls for iteration count and error propagation in the dual-memory loop. Without ablations isolating the Zoom-In/Zoom-Out module and the episodic memory component, the benchmark results cannot be attributed to the architecture rather than unaccounted compute.
Authors: We agree that additional controls and ablations are necessary to substantiate the attribution of gains to the proposed architecture. The revised §5 will incorporate new ablation studies that separately disable the Zoom-In/Zoom-Out long-term memory perception module and the episodic memory component. We will further include results under varying iteration counts and an analysis of error propagation within the dual-memory loop. These experiments will demonstrate the robustness of the SOTA performance to the specific design choices in MemCoT. revision: yes
Circularity Check
No derivation chain or equations present; purely empirical architecture description
full rationale
The paper introduces MemCoT as a test-time scaling framework with multi-view long-term memory and dual short-term memory components, but contains no equations, first-principles derivations, or mathematical predictions. Claims rest exclusively on empirical SOTA results on LoCoMo and LongMemEval-S benchmarks. No load-bearing step reduces to a fitted input, self-citation, or self-definition by construction. The architecture is described at the conceptual level without any reduction to its own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MemCoT ... multi-view long-term memory perception module ... task-conditioned dual short-term memory system ... maximum evolutionary iterations J is uniformly set to 8
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
J=8 ... query decomposition and pruning across iterations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi
-
[2]
InThe Twelfth International Conference on Learning Representations
Self-RAG: Learning to Retrieve, Generate, and Critique through Self- Reflection. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=hSyW5go0v8
-
[3]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ...
- [4]
- [5]
-
[6]
Thomas Y Chen. 2025. How Many Parameters for Multi-Hop? An Information- Theoretic Capacity Law for Knowledge Retrieval in Large Language Models. In Knowledgeable Foundation Models at ACL 2025
2025
-
[7]
Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, Han Zhang, Huishuai Zhang, Dongyan Zhao, and Wenfeng Liang. 2026. Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models. arXiv:2601.07372 [cs.CL]
-
[8]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav
-
[9]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory. arXiv:2504.19413 [cs.CL] https://arxiv.org/abs/2504.19413
work page internal anchor Pith review arXiv
-
[10]
Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, and Fabrizio Silvestri. 2024. The Power of Noise: Redefining Retrieval for RAG Systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2024). ACM
2024
-
[11]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2025. LightRAG: Simple and Fast Retrieval-Augmented Generation. InFindings of the Association for Computational Linguistics: EMNLP 2025, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, 10746–10761
2025
-
[12]
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su
-
[13]
Hipporag: Neurobiologically inspired long-term memory for large language models,
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. arXiv:2405.14831 [cs.CL]
- [14]
-
[15]
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, Zhenrong Cheng, Xuanbo Fan, Jiaxin Guo, Xinlei Yu, Zhenhong Zhou, Zewen Hu, Jiahao Huo, Junhao Wang, Yuwei Niu, Yu Wang, Zhe...
work page internal anchor Pith review arXiv 2026
-
[16]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F...
2020
-
[17]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th International Conference on Neural Information Processing Systems. Cu...
2020
-
[18]
Rui Li, Zeyu Zhang, Xiaohe Bo, Zihang Tian, Xu Chen, Quanyu Dai, Zhenhua Dong, and Ruiming Tang. 2025. CAM: A Constructivist View of Agentic Memory for LLM-Based Reading Comprehension. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id= ACSOnSHiWe
2025
-
[19]
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, Qingchen Yu, Jihao Zhao, Yezhaohui Wang, Peng Liu, Zehao Lin, Pengyuan Wang, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhen Tao, Huayi Lai, Hao Wu, Bo Tang, Zhengren Wang, Zhaoxin Fan, Ningyu Zhang, Linfeng Zhang, Junchi Yan, Mingchuan ...
work page internal anchor Pith review arXiv 2025
- [20]
-
[21]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173
2024
- [22]
-
[23]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Com...
-
[24]
Jiayan Nan, Wenquan Ma, Wenlong Wu, and Yize Chen. 2025. Nemori: Self-Organizing Agent Memory Inspired by Cognitive Science. arXiv:2508.03341 [cs.AI] https://arxiv.org/abs/2508.03341
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2024. MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Vicky Zhao, Lili Qiu, and Jianfeng Gao
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Jianfeng Gao. 2025. SeCom: On Memory Construction and Retrieval for Personalized Conversational Agents. InThe Thirteenth International Conference on Learning Representations
2025
-
[27]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: A Temporal Knowledge Graph Architecture for Agent Memory. arXiv:2501.13956 [cs.CL]
work page internal anchor Pith review arXiv 2025
-
[29]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. InInternational Conference on Learning Representations (ICLR)
2024
-
[30]
Yaorui Shi, Yuxin Chen, Siyuan Wang, Sihang Li, Hengxing Cai, Qi GU, Xiang Wang, and An Zhang. 2026. Look Back to Reason Forward: Revisitable Memory for Long-Context LLM Agents. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=1cymflI2Lh
2026
-
[31]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling LLM Test- Time Compute Optimally can be More Effective than Scaling Model Parameters. arXiv:2408.03314 [cs.LG] https://arxiv.org/abs/2408.03314
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Zihao Tang, Xin Yu, Ziyu Xiao, Zengxuan Wen, Zelin Li, Jiaxi Zhou, Hualei Wang, Haohua Wang, Haizhen Huang, Weiwei Deng, Feng Sun, and Qi Zhang
-
[33]
Mnemis: Dual-Route Retrieval on Hierarchical Graphs for Long-Term LLM Memory
Mnemis: Dual-Route Retrieval on Hierarchical Graphs for Long-Term LLM Memory. arXiv:2602.15313 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv
- [34]
- [35]
-
[36]
Haoran Wei, Yaofeng Sun, and Yukun Li. 2025. DeepSeek-OCR: Contexts Optical Compression. arXiv:2510.18234 [cs.CV] https://arxiv.org/abs/2510.18234
work page internal anchor Pith review arXiv 2025
-
[37]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA) (NIPS ’22). Curran Associates Inc., Red Hook, NY...
2022
-
[38]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H. Chi, Chi Wang, Shuo Chen, Fernando Pereira, Wang-Cheng Kang, and Derek Zhiyuan Cheng. 2025. Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory. arXiv:2511.20857 [cs.CL]
work page internal anchor Pith review arXiv 2025
-
[39]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu
-
[40]
InThe Thirteenth International Conference on Learning Representations
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. InThe Thirteenth International Conference on Learning Representations
-
[41]
Derong Xu, Yi Wen, Pengyue Jia, Yingyi Zhang, wenlin zhang, Yichao Wang, Huifeng Guo, Ruiming Tang, Xiangyu Zhao, Enhong Chen, and Tong Xu. 2025. From Single to Multi-Granularity: Toward Long-Term Memory Association and Selection of Conversational Agents. arXiv:2505.19549 [cs.CL]
-
[42]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
-
[43]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
A-Mem: Agentic Memory for LLM Agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/ forum?id=FiM0M8gcct
-
[44]
Xiucheng Xu, Bingbing Xu, Xueyun Tian, Zihe Huang, Rongxin Chen, Yunfan Li, and Huawei Shen. 2026. Chain-of-Memory: Lightweight Memory Construction with Dynamic Evolution for LLM Agents. arXiv:2601.14287 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 11809–11822
2023
-
[46]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
2023
-
[47]
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. 2026. MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent. InThe Fourteenth International Conference on Learning Representations
2026
-
[48]
Xinlei Yu, Chengming Xu, Guibin Zhang, Zhangquan Chen, Yudong Zhang, Yongbo He, Peng-Tao Jiang, Jiangning Zhang, Xiaobin Hu, and Shuicheng Yan
-
[49]
VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models. arXiv:2511.11007 [cs.CV]
- [50]
- [51]
- [52]
-
[53]
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. 2026. MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents. arXiv:2602.02474 [cs.CL]
work page internal anchor Pith review arXiv 2026
-
[54]
Yusen Zhang, Ruoxi Sun, Yanfei Chen, Tomas Pfister, Rui Zhang, and Sercan Ö. Arı k. 2024. Chain of Agents: Large Language Models Collaborating on Long- Context Tasks. InAdvances in Neural Information Processing Systems, A. Glober- son, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 132208–1322...
-
[55]
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2025. A survey on the memory mechanism of large language model-based agents.ACM Transactions on Information Systems 43, 6 (2025), 1–47
2025
-
[56]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. MemoryBank: enhancing large language models with long-term memory. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artifici...
-
[57]
A simple yet strong baseline for long-term conversational memory of LLM agents, 2025
Sizhe Zhou and Jiawei Han. 2025. A Simple Yet Strong Baseline for Long-Term Conversational Memory of LLM Agents. arXiv:2511.17208 [cs.CL] https://arxiv. org/abs/2511.17208 10 MemCoT: Test-Time Scaling through Memory-Driven Chain-of-Thought MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil A Unified Objective in MemCoT This appendix formalizes how the u...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.