Recognition: unknown
HyperMem: Hypergraph Memory for Long-Term Conversations
Pith reviewed 2026-05-10 16:56 UTC · model grok-4.3
The pith
HyperMem uses hyperedges to link multiple conversation episodes and facts, enabling more coherent retrieval for long-term dialogues than standard pairwise graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
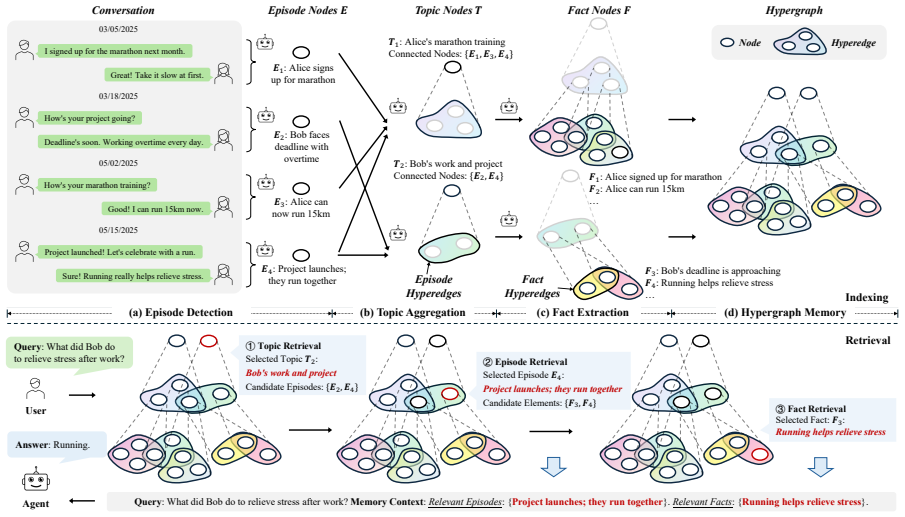
HyperMem structures memory into three levels of topics, episodes, and facts, and uses hyperedges to group related episodes and facts, unifying scattered content. It employs a hybrid lexical-semantic index and a coarse-to-fine retrieval strategy to accurately and efficiently retrieve high-order associations, achieving 92.73 percent LLM-as-a-judge accuracy on the LoCoMo benchmark.
What carries the argument
The hypergraph-based hierarchical memory with hyperedges that connect groups of related episodes and their facts at once, rather than only pairs.
If this is right
- Supports coherent retrieval of high-order associations in extended dialogues.
- Achieves state-of-the-art accuracy on long-term conversation benchmarks.
- Provides efficient retrieval using hybrid indices and multi-level strategies.
- Unifies scattered facts into coherent units for better personalized interactions.
Where Pith is reading between the lines
- This structure could apply to other memory-intensive tasks like long-document summarization where multiple facts relate jointly.
- It implies that memory design for AI should focus on higher-order relations to minimize fragmentation in recall.
- Scalability tests on very long dialogues could show if hyperedge indexing costs remain manageable.
Load-bearing premise
That connecting multiple episodes via hyperedges will yield more coherent retrieval than pairwise graphs without adding significant noise or indexing costs.
What would settle it
If a pairwise graph-based memory system matches HyperMem's accuracy on LoCoMo while using less computation, the benefit of hyperedges would be called into question.
Figures











read the original abstract
Long-term memory is essential for conversational agents to maintain coherence, track persistent tasks, and provide personalized interactions across extended dialogues. However, existing approaches as Retrieval-Augmented Generation (RAG) and graph-based memory mostly rely on pairwise relations, which can hardly capture high-order associations, i.e., joint dependencies among multiple elements, causing fragmented retrieval. To this end, we propose HyperMem, a hypergraph-based hierarchical memory architecture that explicitly models such associations using hyperedges. Particularly, HyperMem structures memory into three levels: topics, episodes, and facts, and groups related episodes and their facts via hyperedges, unifying scattered content into coherent units. Leveraging this structure, we design a hybrid lexical-semantic index and a coarse-to-fine retrieval strategy, supporting accurate and efficient retrieval of high-order associations. Experiments on the LoCoMo benchmark show that HyperMem achieves state-of-the-art performance with 92.73% LLM-as-a-judge accuracy, demonstrating the effectiveness of HyperMem for long-term conversations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HyperMem, a hypergraph-based hierarchical memory architecture for long-term conversational agents. Memory is structured into three levels (topics, episodes, facts) with hyperedges explicitly modeling high-order associations among multiple elements; a hybrid lexical-semantic index and coarse-to-fine retrieval strategy are introduced to support coherent retrieval. Experiments on the LoCoMo benchmark report 92.73% LLM-as-a-judge accuracy, presented as state-of-the-art over existing RAG and pairwise graph methods.
Significance. If the performance gains can be attributed to the hypergraph component, the work would offer a concrete advance in memory architectures for extended dialogues by reducing fragmentation in high-order dependencies. The hierarchical design and retrieval strategy address a recognized limitation in current systems, but the lack of isolating experiments prevents a clear assessment of novelty or impact.
major comments (1)
- [Experiments] Experiments section: the headline 92.73% LoCoMo accuracy is reported without ablations, error bars, or a pairwise-graph control within the same three-level hierarchy. No results isolate whether hyperedges (vs. pairwise edges) drive the claimed improvement in high-order association retrieval, leaving the central claim unsupported by the presented evidence.
minor comments (2)
- [Abstract] Abstract: the claim of 'state-of-the-art performance' is made without naming specific baselines or their scores for direct comparison.
- The description of hyperedge construction, indexing, and the coarse-to-fine retrieval procedure would benefit from a figure or pseudocode to clarify implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below and commit to revisions that strengthen the experimental evidence.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline 92.73% LoCoMo accuracy is reported without ablations, error bars, or a pairwise-graph control within the same three-level hierarchy. No results isolate whether hyperedges (vs. pairwise edges) drive the claimed improvement in high-order association retrieval, leaving the central claim unsupported by the presented evidence.
Authors: We agree that the current experiments would be strengthened by more targeted controls to isolate the hyperedge contribution. The manuscript already compares against existing RAG and pairwise-graph baselines, but these do not share the identical three-level hierarchy. In the revised version we will add: (1) a pairwise-edge control that retains the exact same topic-episode-fact hierarchy but replaces hyperedges with standard edges, (2) error bars from multiple runs with different random seeds, and (3) additional ablations on the hybrid index and coarse-to-fine retrieval. These results will be included in an expanded Experiments section to directly test whether high-order associations improve retrieval coherence. revision: yes
Circularity Check
No circularity: architecture proposal with experimental results only
full rationale
The paper describes a hypergraph memory architecture (three-level hierarchy, hyperedges, hybrid index, coarse-to-fine retrieval) and reports an empirical 92.73% LLM-as-judge accuracy on LoCoMo. No equations, fitted parameters, or first-principles derivations are present. The performance number is an experimental outcome, not a quantity obtained by construction from the model definition or self-citations. No load-bearing step reduces to its own inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
SAGE: A Self-Evolving Agentic Graph-Memory Engine for Structure-Aware Associative Memory
SAGE is a self-evolving agentic graph-memory engine that dynamically constructs and refines structured memory graphs via writer-reader feedback, yielding performance gains on multi-hop QA, open-domain retrieval, and l...
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
The paper surveys agent skills for LLM agents, organizing the literature into a four-stage lifecycle of representation, acquisition, retrieval, and evolution while highlighting their role in system scalability.
Reference graph
Works this paper leans on
-
[1]
Pathrag: Pruning graph-based retrieval aug- mented generation with relational paths.CoRR, abs/2502.14902. Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building production-ready AI agents with scalable long-term memory.CoRR, abs/2504.19413. Jialin Dong, Bahare Fatemi, Bryan Perozzi, Lin F. Yang, and Anton Tsitsu...
-
[2]
ACM. Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang. 2025. Lightmem: Lightweight and efficient memory-augmented generation.CoRR, abs/2510.18866. Yifan Feng, Hao Hu, Xingliang Hou, Shiquan Liu, Shi- hui Ying, Shaoyi Du, Han Hu, and Yue Gao. 2025. Hyper...
-
[3]
Hypergraphrag: Retrieval-augmented genera- tion with hypergraph-structured knowledge represen- tation.CoRR, abs/2503.21322. Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. 2024. Reasoning on graphs: Faithful and interpretable large language model reasoning. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienn...
-
[4]
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 13851–13870. Association for Computational Lin- guistics. Jiayan Nan, Wenquan Ma, Wenlong Wu, and Yize Chen
2024
-
[5]
What Deserves Memory: Adaptive Memory Distillation for LLM Agents
Nemori: Self-organizing agent memory in- spired by cognitive science.CoRR, abs/2508.03341. Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. 2023. Memgpt: Towards llms as operating systems.CoRR, abs/2310.08560. Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: A tem...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
arXiv preprint arXiv:2503.21760 , year=
Meminsight: Autonomous memory augmenta- tion for LLM agents.CoRR, abs/2503.21760. Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning
-
[7]
arXiv preprint arXiv:2412.15235 , year=
RAPTOR: recursive abstractive processing for tree-organized retrieval. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. Kartik Sharma, Peeyush Kumar, and Yunqing Li. 2024. OG-RAG: ontology-grounded retrieval-augmented generation for large language models.CoRR, abs/2412.15235. Y...
-
[8]
arXiv preprint arXiv:2509.25911 , year=
Mem- α: Learning memory construction via reinforcement learning.CoRR, abs/2509.25911. Yuan Xia, Jingbo Zhou, Zhenhui Shi, Jun Chen, and Haifeng Huang. 2025. Improving retrieval aug- mented language model with self-reasoning. In AAAI-25, Sponsored by the Association for the Ad- vancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia...
-
[9]
Substantive Topic Change(Highest Priority): Do new messages introduce a completely different substantive topic? Is there a shift from one specific event to another distinct event?
-
[10]
Intent and Purpose Transition: Has the fundamental purpose of the conversation changed significantly? Has the core question been fully resolved and a new substantial topic begun?
-
[11]
Temporal Signals: Significant time gap between messages (hours or days)? Long gaps strongly suggest new episodes
-
[12]
Thanks!”, “Take care!
Structural Signals: Clear concluding statements followed by genuinely new topics? Explicit topic transition phrases? Special Rules:Greetings + Topic = ONE episode; Ignore social formalities and pleasantries; Closures (“Thanks!”, “Take care!”) stay with current episode. Output: {should_end: bool, should_wait: bool, confidence: float, topic_summary: str} Fi...
-
[13]
Jon’s career transition
Same Specific Event/Theme: E.g., “Jon’s career transition” at different stages. NOT just related topics—“Jon’s business” and “Gina’s business” are DIFFERENT situations
-
[14]
Started X
Narrative Continuity: Later Episode continues/develops the earlier event. E.g., “Started X” → “X encountered problem”→“X succeeded” = SAME situation
-
[15]
NOT just same people or same topic category
Identity of Core Subject: Same specific person’s journey, same specific project/initiative, same specific relationship. NOT just same people or same topic category
-
[16]
Look for recurring discussions or multi-stage developments across time
Temporal Tolerance: Same situation CAN span multiple time points (weeks or months). Look for recurring discussions or multi-stage developments across time. Aggregation Cases: CE =∅ ⇒ Create new Topic; CE ̸=∅,C T =∅ ⇒ Aggregate into new Topic; CT ̸=∅ ⇒Update existing Topic. Output:{title: str, summary: str, keywords: list, episode_weights: dict} Figure 7: ...
-
[17]
Each Fact should be a standalone, queryable assertion
Answerable Facts: Focus on facts that directly answer queries, not narrative context. Each Fact should be a standalone, queryable assertion
-
[18]
Every Fact is anchored to the Episodes from which it originates
Provenance: Maintain explicit links to source Episodes for traceability. Every Fact is anchored to the Episodes from which it originates
-
[19]
Store query patterns in the potentialfield for proactive retrieval alignment
Query Anticipation: Predict potential queries this fact can answer. Store query patterns in the potentialfield for proactive retrieval alignment
-
[20]
That's a great lesson to pass on to your kids, John. Both are really important for strong relationships. Any plans to give another pet a loving home?
Importance Weights: Assign salience scores w∈[0,1] based on relevance to the Topic, reflecting each Fact’s contribution. Output:{content: str, potential: str, keywords: list, importance_weight: float} Figure 8: Prompt templates of fact extraction. Conversation & Evidences: [2022-06-03] Maria: "That's a great lesson to pass on to your kids, John. Both are ...
2022
-
[21]
Hey! So much has changed since last time we talked - meet Toby, my puppy…
The fifth tournament on August 21, 2022 (international gaming tournament). 6. The sixth tournament on September 29, 2022 (significant tournament with prize money). 7. The seventh tournament on November 5, 2022 (Valorant tournament final). [GraphRAG] Nate has won at least two regional video game tournaments as of late May 2022-his first… [HyperGraphRAG] ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.