Uncertainty Estimation for the Open-Set Text Classification systems
Pith reviewed 2026-05-15 09:55 UTC · model grok-4.3
The pith
HolUE adapted to text predicts open-set classification errors by modeling query and data uncertainties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
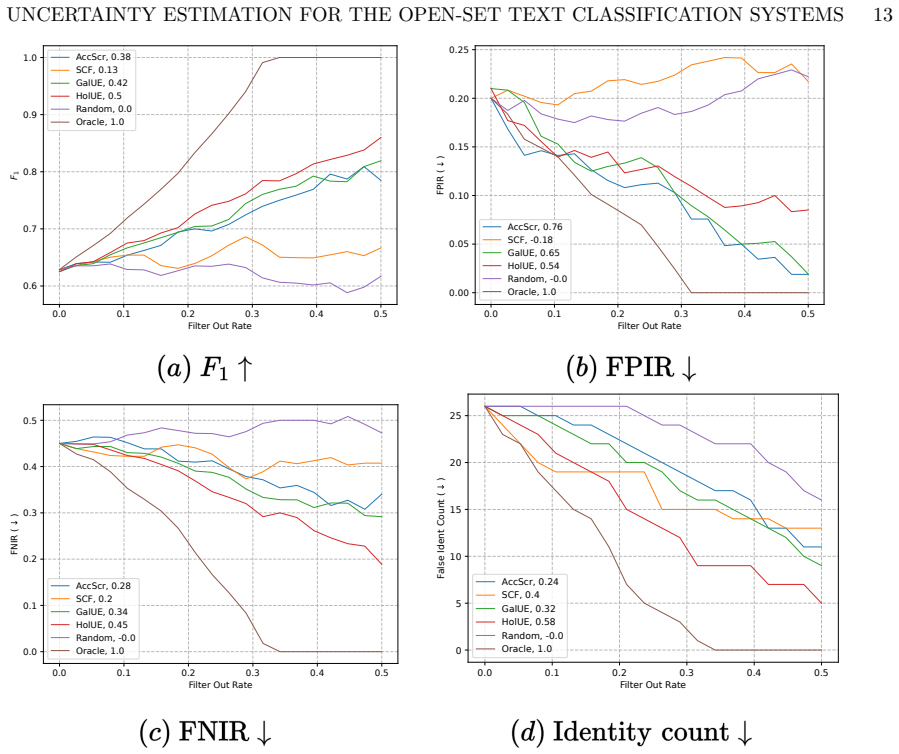
Adapting HolUE to capture text uncertainty from ill-formulated queries and gallery uncertainty related to data distribution ambiguity makes it possible to predict when an open-set text classifier will err, as shown by consistent 40-365 percent improvements in Prediction Rejection Ratio over the SCF baseline across Yahoo Answers, DBPedia, PAN authorship, and CLINC150 datasets.
What carries the argument
HolUE adapted for text, which combines estimates of text uncertainty and gallery uncertainty into a single reliability score used for prediction rejection.
If this is right
- Classifiers can safely reject a higher fraction of errors while retaining most correct predictions on known classes.
- Performance gains appear across authorship, intent, and topic tasks, suggesting broad applicability within text domains.
- The released benchmark and protocols provide a standard testbed for comparing future uncertainty methods in OSTC.
- Systems gain the ability to flag ambiguous inputs for human review before deployment errors occur.
Where Pith is reading between the lines
- If the two uncertainty sources dominate, the same separation of concerns could be tested in open-set image or speech tasks where input quality and training distribution issues also arise.
- Scaling the underlying text model might change the relative contribution of query versus gallery uncertainty, offering a testable extension using larger language models.
- The public code enables direct checks on whether the gains persist when inputs are adversarially perturbed or drawn from streaming sources.
Load-bearing premise
The two named uncertainty types are the main sources of prediction errors and the adapted HolUE method measures them effectively enough to rank predictions by reliability.
What would settle it
On a new open-set text dataset the Prediction Rejection Ratio for HolUE would fall below or equal the SCF baseline at the reported operating points.
Figures


read the original abstract
Accurate uncertainty estimation is essential for building robust and trustworthy recognition systems. In this paper, we consider the open-set text classification (OSTC) task - and uncertainty estimation for it. For OSTC a text sample should be classified as one of the existing classes or rejected as unknown. To account for the different uncertainty types encountered in OSTC, we adapt the Holistic Uncertainty Estimation (HolUE) method for the text domain. Our approach addresses two major causes of prediction errors in text recognition systems: text uncertainty that stems from ill formulated queries and gallery uncertainty that is related the ambiguity of data distribution. By capturing these sources, it becomes possible to predict when the system will make a recognition error. We propose a new OSTC benchmark and conduct extensive experiments on a wide range of data, utilizing the authorship attribution, intent and topic classification datasets. HolUE achieves 40-365% improvement in Prediction Rejection Ratio (PRR) over the quality-based SCF baseline across datasets: 365% on Yahoo Answers (0.79 vs 0.17 at FPIR 0.1), 347% on DBPedia (0.85 vs 0.19), 240% on PAN authorship attribution (0.51 vs 0.15 at FPIR 0.5), and 40% on CLINC150 intent classification (0.73 vs~0.52). We make public our code and protocols https://github.com/Leonid-Erlygin/text_uncertainty.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper adapts Holistic Uncertainty Estimation (HolUE) to open-set text classification (OSTC) by modeling text uncertainty (from ill-formulated queries) and gallery uncertainty (from ambiguous data distributions) to predict recognition errors. It introduces a new OSTC benchmark and reports 40-365% gains in Prediction Rejection Ratio (PRR) over the quality-based SCF baseline on four datasets (Yahoo Answers, DBPedia, PAN authorship, CLINC150 intent), with public code release at the provided GitHub link.
Significance. If the PRR improvements hold under verification, the work provides a practical method for uncertainty-aware OSTC that could improve reliability in applications such as intent detection and authorship attribution. The public code and benchmark strengthen the contribution by supporting direct reproducibility and extension.
major comments (2)
- [§4] §4 (Experimental Protocol): The abstract and results claim large PRR gains (e.g., 0.79 vs 0.17 at FPIR 0.1 on Yahoo Answers) but supply no derivation of the adapted HolUE combination rule, no adaptation steps for text embeddings, and no statistical significance tests or variance estimates across runs, making it impossible to confirm that the data support the stated improvements.
- [§3.2] §3.2 (HolUE Adaptation): The two uncertainty sources are presented as independent and load-bearing for error prediction, yet no ablation is described that isolates their individual contributions or shows that the combined score reduces to something other than a fitted linear combination of existing quality signals.
minor comments (2)
- [Abstract] Abstract: 'related the ambiguity' should read 'related to the ambiguity'.
- [Tables/Figures] Figure captions and Table 1: FPIR thresholds are reported inconsistently (0.1 vs 0.5) without a unified legend explaining why different operating points are chosen per dataset.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. We address each major comment below and will revise the manuscript accordingly to improve clarity, provide missing details, and add supporting analyses.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Protocol): The abstract and results claim large PRR gains (e.g., 0.79 vs 0.17 at FPIR 0.1 on Yahoo Answers) but supply no derivation of the adapted HolUE combination rule, no adaptation steps for text embeddings, and no statistical significance tests or variance estimates across runs, making it impossible to confirm that the data support the stated improvements.
Authors: We will add a clear derivation of the adapted HolUE combination rule to the revised Section 3. The adaptation steps for text embeddings will be expanded with explicit details and examples. We will also rerun experiments to report variance estimates across multiple random seeds and include statistical significance tests (e.g., paired t-tests) to substantiate the PRR improvements. revision: yes
-
Referee: [§3.2] §3.2 (HolUE Adaptation): The two uncertainty sources are presented as independent and load-bearing for error prediction, yet no ablation is described that isolates their individual contributions or shows that the combined score reduces to something other than a fitted linear combination of existing quality signals.
Authors: We will include a new ablation study in the revised manuscript that isolates text uncertainty and gallery uncertainty. The results will show that the holistic combination yields gains beyond what a linear regression on quality signals alone can achieve, confirming the value of integrating the two sources as adapted from the original HolUE framework. revision: yes
Circularity Check
No significant circularity; empirical adaptation of HolUE with public verification
full rationale
The paper adapts the existing Holistic Uncertainty Estimation (HolUE) method to open-set text classification by addressing text and gallery uncertainty sources, then reports empirical PRR gains across four datasets with public code and protocols. No equations, fitted parameters renamed as predictions, or self-citation chains are present that reduce the central claims to inputs by construction. The derivation is self-contained: performance numbers are externally verifiable via the released benchmark and code, with no load-bearing steps that collapse to self-definition or prior author results invoked as uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text uncertainty from ill-formulated queries and gallery uncertainty from data distribution ambiguity are the two major causes of prediction errors in OSTC.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adapt the Holistic Uncertainty Estimation (HolUE) framework... KL-divergence between posterior p(c|x) and prior p(c)... von Mises-Fisher distributions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HolUE achieves 40-365% improvement in Prediction Rejection Ratio (PRR) over the quality-based SCF baseline
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
W. J. Scheirer, A. de Rezende Rocha, A. Sapkota, and T. E. Boult. Toward open set recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence , 35(7):1757–1772, 2013
work page 2013
-
[2]
Anil K. Jain Stan Z. Li. Handbook of Face Recognition. Springer London, 2011
work page 2011
-
[3]
Open-world machine learning: Applications, challenges, and opportunities
Jitendra Parmar, Satyendra Chouhan, Vaskar Raychoudhury, and Santosh Rathore. Open-world machine learning: Applications, challenges, and opportunities. ACM Comput. Surv. , 55(10), February 2023
work page 2023
-
[4]
A review of uncertainty quantification in deep learning: Techniques, applications and challenges
Moloud Abdar, Farhad Pourpanah, Sadiq Hussain, and et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Information Fusion, 76:243–297, 2021
work page 2021
-
[5]
M. G¨ unther, S. Cruz, E. M. Rudd, and T. E. Boult. Toward open-set face recognition. 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR W) , pages 573–582, 2017
work page 2017
-
[6]
Holistic uncertainty estimation for open-set recognition
Leonid Erlygin and Alexey Zaytsev. Holistic uncertainty estimation for open-set recognition. IEEE Access, 14:18868–18880, 2026
work page 2026
-
[7]
Spherical confidence learning for face recognition
Shen Li, Jianqing Xu, Xiaqing Xu, Pengcheng Shen, Shaoxin Li, and Bryan Hooi. Spherical confidence learning for face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 15629–15637, June 2021
work page 2021
-
[8]
Open set text classification using convolu- tional neural networks
Sridhama Prakhya, Vinodini Venkataram, and Jugal Kalita. Open set text classification using convolu- tional neural networks. International Conference on Natural Language Processing , 2017. ИНФОРМАЦИОННЫЕ ПРОЦЕССЫ ТОМ 24 № 1 2024 UNCERTAINTY ESTIMATION FOR THE OPEN-SET TEXT CLASSIFICATION SYSTEMS 15
work page 2017
-
[9]
Peper, Christopher Clarke, Andrew Lee, Parker Hill, Jonathan K
Stefan Larson, Anish Mahendran, Joseph J. Peper, Christopher Clarke, Andrew Lee, Parker Hill, Jonathan K. Kummerfeld, Kevin Leach, Michael A. Laurenzano, Lingjia Tang, and Jason Mars. An evaluation dataset for intent classification and out-of-scope prediction. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors, Proceedings of the 2019 Confer...
work page 2019
-
[10]
Deep unknown intent detection with margin loss
Ting-En Lin and Hua Xu. Deep unknown intent detection with margin loss. In Anna Korhonen, David Traum, and Llu ´ ıs M` arquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 5491–5496, Florence, Italy, July 2019. Association for Computational Linguistics
work page 2019
-
[11]
Authorship attribution using text distortion
Efstathios Stamatatos. Authorship attribution using text distortion. In Mirella Lapata, Phil Blunsom, and Alexander Koller, editors, Proceedings of the 15th Conference of the European Chapter of the Asso- ciation for Computational Linguistics: Volume 1, Long Papers , pages 1138–1149, Valencia, Spain, April
-
[12]
Association for Computational Linguistics
-
[13]
Patrick Juola. Authorship attribution. Found. Trends Inf. Retr. , 1(3):233334, December 2006
work page 2006
-
[14]
Open set authorship attribution toward demystifying victorian periodicals
Sarkhan Badirli, Mary Borgo Ton, Abdulmecit Gungor, and Murat Dundar. Open set authorship attribution toward demystifying victorian periodicals. In Document Analysis and Recognition ICDAR 2021: 16th International Conference, Lausanne, Switzerland, September 510, 2021, Proceedings, Part IV, page 221235, Berlin, Heidelberg, 2021. Springer-Verlag
work page 2021
-
[15]
Open-set semi-supervised text classification with latent outlier softening
Junfan Chen, Richong Zhang, Junchi Chen, Chunming Hu, and Yongyi Mao. Open-set semi-supervised text classification with latent outlier softening. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , KDD ’23, page 226236, New York, NY, USA, 2023. Association for Computing Machinery
work page 2023
-
[16]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4690–4699, 2019
work page 2019
-
[17]
Manuel G¨ unther, Steve Cruz, Ethan M. Rudd, and Terrance E. Boult. Toward open-set face recognition. 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR W) , pages 573– 582, 2017
work page 2017
-
[18]
VoxBlink2: A 100K+ speaker recognition corpus and the open-set speaker-identification benchmark
Yuke Lin, Ming Cheng, Fulin Zhang, Yingying Gao, Shilei Zhang, and Ming Li. VoxBlink2: A 100K+ speaker recognition corpus and the open-set speaker-identification benchmark. In Proc. Interspeech 2024, pages 4263–4267, 2024
work page 2024
-
[19]
DOC: Deep open classification of text documents
Lei Shu, Hu Xu, and Bing Liu. DOC: Deep open classification of text documents. In Martha Palmer, Rebecca Hwa, and Sebastian Riedel, editors, Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages 2911–2916, Copenhagen, Denmark, September 2017. Association for Computational Linguistics
work page 2017
-
[20]
Towards open set deep networks
Abhijit Bendale and Terrance E Boult. Towards open set deep networks. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 1563–1572, 2016
work page 2016
-
[21]
Breaking the closed world assumption in text classification
Geli Fei and Bing Liu. Breaking the closed world assumption in text classification. In Kevin Knight, Ani Nenkova, and Owen Rambow, editors, Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 506– 514, San Diego, California, June 2016. Association for Computa...
work page 2016
-
[22]
Yichun Shi and Anil K. Jain. Probabilistic face embeddings. In Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV) , October 2019
work page 2019
-
[23]
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? In Advances in neural information processing systems , volume 30, 2017
work page 2017
-
[24]
Dropout as a bayesian approximation: Representing model uncer- tainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncer- tainty in deep learning. In International conference on machine learning , pages 1050–1059, 2016. ИНФОРМАЦИОННЫЕ ПРОЦЕССЫ ТОМ 24 № 1 2024 16 ERLYGIN
work page 2016
-
[25]
Simple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in neural information processing systems , volume 30, 2017
work page 2017
-
[26]
Transferring bert-like transformers’ knowledge for authorship verification
Andrei Manolache, Florin Brad, Elena Burceanu, Antonio Barbalau, Radu Tudor Ionescu, and Mar- ius Popescu. Transferring bert-like transformers’ knowledge for authorship verification. CoRR, abs/2112.05125, 2021
-
[27]
Overview of the cross-domain authorship verification task at PAN 2020
Mike Kestemont, Enrique Manjavacas, Ilia Markov, Janek Bevendorff, Matti Wiegmann, Efstathios Stamatatos, Martin Potthast, and Benno Stein. Overview of the cross-domain authorship verification task at PAN 2020. In Linda Cappellato, Carsten Eickhoff, Nicola Ferro, and Aur´ elie N´ ev´ eol, editors, Working Notes of CLEF 2020 - Conference and Labs of the Evalu...
work page 2020
-
[28]
Recent advances in open set recognition: A survey
Chuanxing Geng, Sheng jun Huang, and Songcan Chen. Recent advances in open set recognition: A survey. 2018
work page 2018
-
[29]
C. Chow. On optimum recognition error and reject tradeoff. IEEE Transactions on Information Theory , 16(1):41–46, 1970
work page 1970
-
[30]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc., 2017
work page 2017
-
[31]
E. Fadeeva, R. Vashurin, A. Tsvigun, and et al. Lm-polygraph: Uncertainty estimation for language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , 2023
work page 2023
- [32]
-
[33]
Bert: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 4171–4186, 2019
work page 2019
-
[34]
Fisher, Toby Lewis, and Brian J
Nicholas I. Fisher, Toby Lewis, and Brian J. J. Embleton. Statistical Analysis of Spherical Data . Cam- bridge University Press, Cambridge, UK, 1993
work page 1993
-
[35]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yixuan Sun, and Kilian Q Weinberger. On calibration of modern neural networks. In International conference on machine learning , pages 1321–1330, 2017
work page 2017
-
[36]
Hallucination detection in llms with topological divergence on attention graphs, 2025
Alexandra Bazarova, Aleksandr Yugay, Andrey Shulga, Alina Ermilova, Andrei Volodichev, Konstantin Polev, Julia Belikova, Rauf Parchiev, Dmitry Simakov, Maxim Savchenko, Andrey Savchenko, Serguei Barannikov, and Alexey Zaytsev. Hallucination detection in llms with topological divergence on attention graphs, 2025. ИНФОРМАЦИОННЫЕ ПРОЦЕССЫ ТОМ 24 № 1 2024
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.