Lessons Without Borders? Evaluating Cultural Alignment of LLMs Using Multilingual Story Moral Generation
Pith reviewed 2026-05-10 16:45 UTC · model grok-4.3
The pith
Frontier LLMs generate story morals similar to humans but with markedly less cross-linguistic variation and a narrower set of values.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using a new dataset of human-written story morals collected across 14 language-culture pairs, we compare model outputs with human interpretations via semantic similarity, a human preference survey, and value categorization. We show that frontier models such as GPT-4o and Gemini generate story morals that are semantically similar to human responses and preferred by human evaluators. However, their outputs exhibit markedly less cross-linguistic variation and concentrate on a narrower set of widely shared values. These findings suggest that while contemporary models can approximate central tendencies of human moral interpretation, they struggle to reproduce the diversity that characterizes nder
What carries the argument
The multilingual story moral generation task, which collects and compares human and model moral interpretations of stories across 14 language-culture pairs through semantic similarity, preference surveys, and value categorization to assess cultural alignment.
If this is right
- Contemporary models can approximate central tendencies of human moral interpretation in narrative contexts.
- Models risk producing homogenized outputs that overlook the range of cultural and linguistic differences in story understanding.
- Evaluation of cultural alignment benefits from tasks that measure variation and diversity rather than only average similarity.
- New human datasets of moral interpretations provide a grounded benchmark for testing how well models capture cultural differences.
Where Pith is reading between the lines
- Alignment methods may need explicit objectives for preserving variation to better match the spread of human moral views.
- Similar generation tasks could be applied to other narrative elements like plot resolutions or character judgments to check for parallel flattening effects.
- Human preference for model outputs could stem from models favoring broadly acceptable morals over those tied to specific cultural contexts.
Load-bearing premise
The new dataset of human-written story morals across 14 language-culture pairs accurately captures genuine cultural diversity in moral interpretation, and semantic similarity, preference surveys, and value categorization sufficiently measure cultural alignment.
What would settle it
Collecting a larger and more varied set of human moral responses for the same stories and demonstrating that model outputs display cross-linguistic variation comparable to the full range of human responses would challenge the claim of reduced model diversity.
Figures











read the original abstract
Stories are key to transmitting values across cultures, but their interpretation varies across linguistic and cultural contexts. Thus, we introduce multilingual story moral generation as a novel culturally grounded evaluation task. Using a new dataset of human-written story morals collected across 14 language-culture pairs, we compare model outputs with human interpretations via semantic similarity, a human preference survey, and value categorization. We show that frontier models such as GPT-4o and Gemini generate story morals that are semantically similar to human responses and preferred by human evaluators. However, their outputs exhibit markedly less cross-linguistic variation and concentrate on a narrower set of widely shared values. These findings suggest that while contemporary models can approximate central tendencies of human moral interpretation, they struggle to reproduce the diversity that characterizes human narrative understanding. By framing narrative interpretation as an evaluative task, this work introduces a new approach to studying cultural alignment in language models beyond static benchmarks or knowledge-based tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces multilingual story moral generation as a novel task for evaluating cultural alignment in LLMs. It presents a new dataset of human-written story morals across 14 language-culture pairs and compares outputs from frontier models (GPT-4o, Gemini) to human responses using semantic similarity, a human preference survey, and value categorization. The central findings are that these models generate morals that are semantically similar to and preferred by human evaluators, yet exhibit markedly less cross-linguistic variation and concentrate on a narrower set of widely shared values, implying they approximate central human tendencies but fail to capture narrative diversity.
Significance. If the results hold after addressing methodological gaps, this work provides a culturally grounded, narrative-based benchmark that advances evaluation of LLM cultural alignment beyond static knowledge tests or English-centric probes. The new dataset and multi-metric approach (similarity + preference + values) could become a reusable resource for studying value diversity in multilingual settings, with direct relevance to global deployment of LLMs.
major comments (3)
- [§3.1] §3.1 (Dataset Construction): The protocol for collecting the 14 language-culture human moral dataset is underspecified regarding sample sizes per pair, participant recruitment and demographics, whether stories were originally authored in each language or translated/adapted from a source, and controls for prompt wording. This directly affects the validity of the claim that human responses show greater cross-linguistic variation than models, as translation artifacts or sampling biases could inflate measured human diversity.
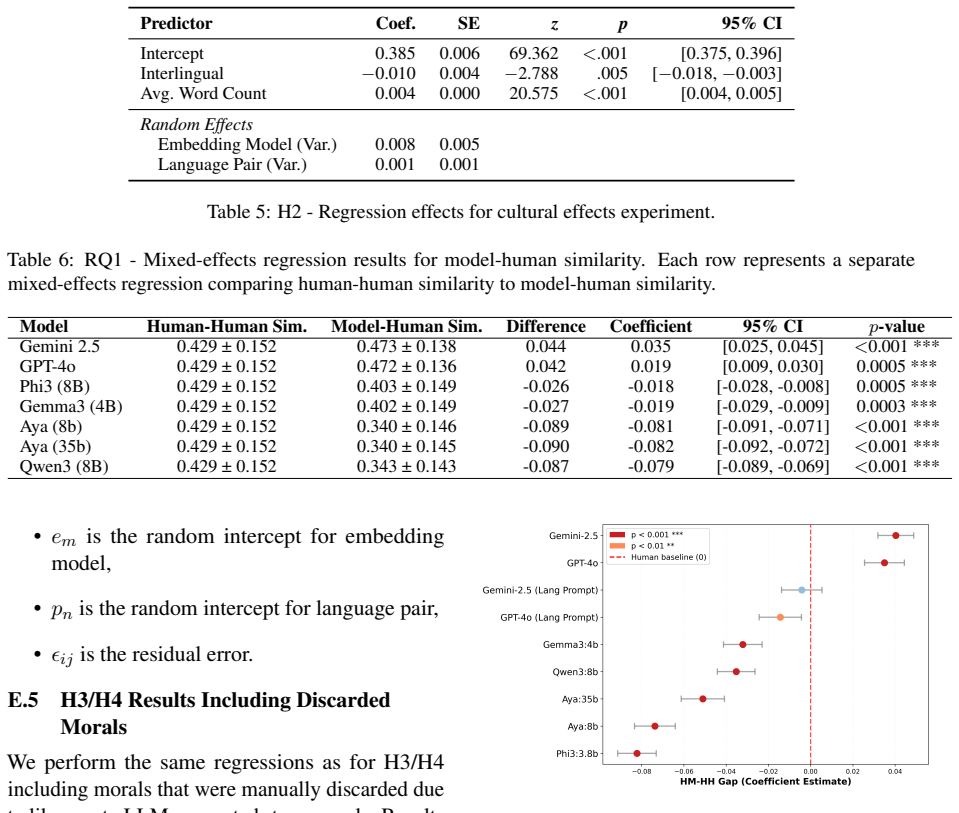
- [§4.2] §4.2 (Evaluation Metrics): No statistical significance tests, effect sizes, or confidence intervals are reported for the differences in cross-linguistic variation (e.g., variance in embeddings or value distributions) between models and humans. Without these, the assertion of 'markedly less' variation lacks quantitative grounding and cannot be assessed for robustness against confounds such as generation length or lexical consistency.
- [§4.3] §4.3 (Value Categorization): The procedure for assigning value categories to outputs does not report inter-rater reliability, use of culture-specific blinded annotators, or the taxonomy source. This is load-bearing for the conclusion that models use a narrower set of 'widely shared values,' as post-hoc labeling without cultural validation risks circularity with the diversity claim.
minor comments (3)
- [Abstract / §3] The abstract and §3 do not enumerate the 14 specific language-culture pairs; adding this list (or a table) would aid reproducibility and reader understanding.
- [Figures 2-4] Figures illustrating variation (e.g., embedding clusters or value histograms) lack error bars or statistical annotations, reducing clarity on the magnitude of model-human differences.
- [§2] Related work section omits several recent papers on multilingual value alignment benchmarks; citing them would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which help improve the clarity and rigor of our work. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Dataset Construction): The protocol for collecting the 14 language-culture human moral dataset is underspecified regarding sample sizes per pair, participant recruitment and demographics, whether stories were originally authored in each language or translated/adapted from a source, and controls for prompt wording. This directly affects the validity of the claim that human responses show greater cross-linguistic variation than models, as translation artifacts or sampling biases could inflate measured human diversity.
Authors: We agree that additional details on dataset construction are necessary for reproducibility and to support claims about human diversity. In the revised version, we will expand §3.1 with: per-pair sample sizes (N=30-50 depending on language), recruitment via Prolific and local university networks with screening for native speakers, full demographics (age, gender, education, self-reported cultural affiliation), confirmation that all morals were originally elicited and written in the target language (no post-hoc translation of responses), and exact prompt templates with controls for wording consistency across languages. These additions will allow direct assessment of potential biases. revision: yes
-
Referee: [§4.2] §4.2 (Evaluation Metrics): No statistical significance tests, effect sizes, or confidence intervals are reported for the differences in cross-linguistic variation (e.g., variance in embeddings or value distributions) between models and humans. Without these, the assertion of 'markedly less' variation lacks quantitative grounding and cannot be assessed for robustness against confounds such as generation length or lexical consistency.
Authors: We acknowledge this gap in quantitative support. In revision, we will add statistical tests (e.g., Levene's test for equality of variances on embedding variances and chi-square tests on value distributions), report effect sizes (Cohen's d or eta-squared), and 95% confidence intervals for all key differences. We will also include controls for generation length by length-matching subsets and report results on normalized metrics to address potential confounds. revision: yes
-
Referee: [§4.3] §4.3 (Value Categorization): The procedure for assigning value categories to outputs does not report inter-rater reliability, use of culture-specific blinded annotators, or the taxonomy source. This is load-bearing for the conclusion that models use a narrower set of 'widely shared values,' as post-hoc labeling without cultural validation risks circularity with the diversity claim.
Authors: We will clarify and expand this section. The taxonomy is drawn from the Schwartz Theory of Basic Values with adaptations for narrative morals; two independent annotators (blinded to model vs. human origin) performed the categorization, and we will now report inter-rater reliability (Cohen's kappa = 0.78). However, due to practical constraints, annotators were not recruited from all 14 cultures; we will explicitly discuss this limitation and its potential impact on the diversity findings rather than claiming full cultural validation. revision: partial
Circularity Check
No circularity: empirical evaluation against new external dataset
full rationale
The paper introduces a new multilingual story moral generation task and collects a fresh human-written dataset across 14 language-culture pairs. It then performs direct comparisons of model outputs to this external human data using standard metrics (semantic similarity, preference surveys, value categorization). No derivations, equations, fitted parameters, or predictions are claimed that reduce by construction to prior outputs or self-citations. The central claim—that models approximate central tendencies but show less cross-linguistic variation—rests on new data collection and evaluation rather than any self-referential loop. This is a standard empirical study with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic similarity, human preference judgments, and value categorization together measure cultural alignment in moral story interpretation.
Reference graph
Works this paper leans on
-
[1]
InAdvances in experi- mental social psychology, volume 47, pages 55–130
Moral foundations theory: The pragmatic va- lidity of moral pluralism. InAdvances in experi- mental social psychology, volume 47, pages 55–130. Elsevier. Jian Guan, Ziqi Liu, and Minlie Huang. 2022. A cor- pus for understanding and generating moral stories. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computa- ...
work page 2022
-
[2]
Narrabench: A comprehensive frame- work for narrative benchmarking.arXiv preprint arXiv:2510.09869. Dan Hendrycks, Steven Basart, Saurav Kadavath, Man- tas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Purtell, Horace He, Dawn Song, and Jacob Steinhardt. 2021. Aligning ai with shared human values.arXiv preprint arXiv:2008.02275. David Hobson, Haiqi ...
-
[3]
Can machines learn morality? the delphi experiment
Can machines learn morality? the delphi ex- periment.arXiv preprint arXiv:2110.07574. Ariba Khan, Stephen Casper, and Dylan Hadfield- Menell. 2025. Randomness, not representation: The unreliability of evaluating cultural alignment in llms. InProceedings of the 2025 ACM Conference on Fair- ness, Accountability, and Transparency, pages 2151– 2165. Louis Kwo...
-
[4]
arXiv preprint arXiv:2408.06929
Evaluating cultural adaptability of a large lan- guage model via simulation of synthetic personas. Preprint, arXiv:2408.06929. Claude Lévi-Strauss. 1955. The structural study of myth.The journal of American folklore, 68(270):428– 444. 10 John H Lockwood. 1999.The moral of the story: Content, process, and reflection in moral education through narratives. U...
-
[5]
arXiv preprint arXiv:2307.14324 , year =
Evaluating the moral beliefs encoded in LLMs. arXiv preprint arXiv:2307.14324. Shalom H Schwartz. 1992. Universals in the content and structure of values: Theoretical advances and empirical tests in 20 countries. InAdvances in exper- imental social psychology, volume 25, pages 1–65. Elsevier. Shalom H Schwartz. 2012. An overview of the schwartz theory of ...
-
[6]
does the guide cane have sections that are white in color?
Culture is not trivia: Sociocultural theory for cultural nlp.arXiv preprint arXiv:2502.12057. Appendices A Story Dataset A.1 Dataset Breakdown The names and WikiIDs of all stories, along with their countries of origin and their original lan- guages, can be viewed in Table 3. Full stories, along with all translations, can be viewed on our project repositor...
-
[7]
for all language translations except for trans- lations involving Hebrew (since this language is not yet available on the DeepL API), where we use the Google Translate API (Google LLC, 2025). We avoided using an LLM for this process because we did not want the LLM translation to possibly bias the interpretation of the human story morals towards the LLM in...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.