Recognition: 2 theorem links
· Lean TheoremHierarchical Kernel Transformer: Multi-Scale Attention with an Information-Theoretic Approximation Analysis
Pith reviewed 2026-05-10 18:13 UTC · model grok-4.3
The pith
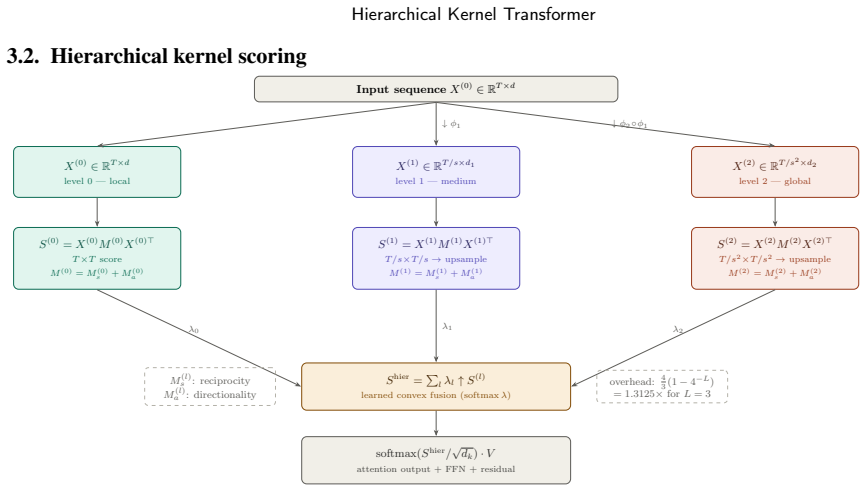
The Hierarchical Kernel Transformer processes sequences at multiple resolutions to subsume standard attention and causal convolution at 1.31 times the cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HKT processes sequences at L resolution levels via trainable causal downsampling, combining level-specific score matrices through learned convex weights. The total computational cost is bounded by 4/3 times that of standard attention, reaching 1.3125x for L = 3. The hierarchical score matrix defines a positive semidefinite kernel under a sufficient condition on the symmetrised bilinear form. The asymmetric score matrix decomposes uniquely into a symmetric part controlling reciprocal attention and an antisymmetric part controlling directional attention, with HKT supplying L independent such pairs. The approximation error decomposes into three interpretable components with an explicit non-Gaus
What carries the argument
The hierarchical score matrix formed by convex combination of level-specific attention scores at different resolutions, which carries the multi-scale structure, positive-semidefiniteness guarantee, and strict subsumption of baseline attention and convolution.
If this is right
- HKT supplies L independent symmetric-antisymmetric attention pairs, one per resolution scale.
- The approximation error admits an explicit non-Gaussian correction term whose size is bounded by a geometric series in L.
- Computational overhead stays at most 4/3 of standard attention for arbitrary L and equals 1.3125x specifically at L = 3.
- Empirical accuracy improves by 4.77 points on ListOps, 1.44 points on sequential CIFAR-10, and 7.47 points on character-level IMDB relative to retrained baselines.
Where Pith is reading between the lines
- The per-scale decomposition into reciprocal and directional components supplies a concrete way to inspect how different resolutions contribute to attention patterns.
- Because the construction already contains causal convolution as a special case, the same hierarchy could be used to blend convolution-like local processing with attention-like global processing inside one module.
- The geometric decay bound on error suggests that only a small number of additional levels is needed to capture most of the benefit, which could inform practical choices of L.
Load-bearing premise
The symmetrised bilinear form satisfies a sufficient condition that makes the hierarchical score matrix positive semidefinite at every resolution level.
What would settle it
Setting L equal to 1 in the implementation and checking whether the model, cost, and outputs become identical to single-head standard attention, or verifying whether the reported accuracy gains disappear when the convex combination of levels is replaced by a single fixed level.
Figures


read the original abstract
The Hierarchical Kernel Transformer (HKT) is a multi-scale attention mechanism that processes sequences at L resolution levels via trainable causal downsampling, combining level-specific score matrices through learned convex weights. The total computational cost is bounded by 4/3 times that of standard attention, reaching 1.3125x for L = 3. Four theoretical results are established. (i) The hierarchical score matrix defines a positive semidefinite kernel under a sufficient condition on the symmetrised bilinear form (Proposition 3.1). (ii) The asymmetric score matrix decomposes uniquely into a symmetric part controlling reciprocal attention and an antisymmetric part controlling directional attention; HKT provides L independent such pairs across scales, one per resolution level (Propositions 3.5-3.6). (iii) The approximation error decomposes into three interpretable components with an explicit non-Gaussian correction and a geometric decay bound in L (Theorem 4.3, Proposition 4.4). (iv) HKT strictly subsumes single-head standard attention and causal convolution (Proposition 3.4). Experiments over 3 random seeds show consistent gains over retrained standard attention baselines: +4.77pp on synthetic ListOps (55.10+-0.29% vs 50.33+-0.12%, T = 512), +1.44pp on sequential CIFAR-10 (35.45+-0.09% vs 34.01+-0.19%, T = 1,024), and +7.47pp on IMDB character-level sentiment (70.19+-0.57% vs 62.72+-0.40%, T = 1,024), all at 1.31x overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Hierarchical Kernel Transformer (HKT), a multi-scale attention architecture that processes input sequences at L different resolution levels using trainable causal downsampling operations. Level-specific score matrices are combined via learned convex weights, with total compute bounded by 4/3 of standard attention. The paper presents four main theoretical contributions: (i) the hierarchical score matrix forms a positive semidefinite kernel provided a sufficient condition on the symmetrised bilinear form holds (Proposition 3.1); (ii) the asymmetric score matrix admits a unique decomposition into symmetric and antisymmetric components, with HKT providing independent pairs at each scale (Propositions 3.5 and 3.6); (iii) the approximation error to standard attention decomposes into three components with geometric decay in L (Theorem 4.3 and Proposition 4.4); and (iv) HKT strictly subsumes both single-head standard attention and causal convolution (Proposition 3.4). Empirical results on ListOps (T=512), sequential CIFAR-10 (T=1024), and character-level IMDB (T=1024) demonstrate consistent improvements over retrained baselines across three random seeds, at approximately 1.31x computational cost for L=3.
Significance. If the theoretical results hold, particularly the kernel property under the stated condition and the information-theoretic error decomposition, this work could provide a principled extension of attention mechanisms that incorporates multi-scale processing with explicit approximation guarantees. The strict subsumption of standard attention and causal convolution, together with the bounded computational overhead, are clear strengths. The reported experimental gains are consistent but their broader significance hinges on verification of the theoretical assumptions and more detailed controls.
major comments (3)
- [Proposition 3.1] Proposition 3.1: The claim that the hierarchical score matrix defines a positive semidefinite kernel rests on an unverified sufficient condition on the symmetrised bilinear form. The manuscript provides no evidence that this condition holds for the learned parameters, nor that the architecture enforces it during training. This is load-bearing for the kernel interpretation and for the grounding of the information-theoretic approximation analysis in Theorem 4.3.
- [Propositions 3.5-3.6] Propositions 3.5-3.6: The unique decomposition of the asymmetric score matrix into symmetric and antisymmetric parts is asserted to hold independently across all L levels under hierarchical downsampling. The manuscript does not explicitly verify that this decomposition remains valid after the trainable causal downsampling operations, which is necessary to support the claim of L independent reciprocal/directional attention pairs.
- [Experiments] Experiments: Performance improvements are reported as means and standard deviations over three random seeds (+4.77pp on ListOps, +1.44pp on sequential CIFAR-10, +7.47pp on IMDB). However, the manuscript does not detail whether baselines were retrained with matched hyperparameters, the precise implementation of the standard attention baseline, or any statistical significance testing, limiting assessment of whether the gains are robustly attributable to HKT.
minor comments (1)
- [Abstract] The abstract refers to an 'information-theoretic approximation analysis' without naming the specific divergence or entropy measure employed; a brief clarification in the introduction would improve accessibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below with clarifications and commit to specific revisions that strengthen the theoretical grounding and experimental reporting without altering the core claims.
read point-by-point responses
-
Referee: [Proposition 3.1] Proposition 3.1: The claim that the hierarchical score matrix defines a positive semidefinite kernel rests on an unverified sufficient condition on the symmetrised bilinear form. The manuscript provides no evidence that this condition holds for the learned parameters, nor that the architecture enforces it during training. This is load-bearing for the kernel interpretation and for the grounding of the information-theoretic approximation analysis in Theorem 4.3.
Authors: We thank the referee for identifying this point. Proposition 3.1 presents a sufficient (not necessary) condition for the hierarchical score matrix to define a PSD kernel. The current manuscript neither claims that training enforces the condition nor provides verification for the learned parameters. In the revised manuscript we will add an empirical check: for each trained model we will compute the eigenvalues of the symmetrised bilinear form and report the fraction of negative eigenvalues (if any) across the three random seeds and all datasets. This verification will be placed in the main text or a new appendix subsection and will directly support the applicability of the kernel interpretation and the error decomposition in Theorem 4.3. revision: yes
-
Referee: [Propositions 3.5-3.6] Propositions 3.5-3.6: The unique decomposition of the asymmetric score matrix into symmetric and antisymmetric parts is asserted to hold independently across all L levels under hierarchical downsampling. The manuscript does not explicitly verify that this decomposition remains valid after the trainable causal downsampling operations, which is necessary to support the claim of L independent reciprocal/directional attention pairs.
Authors: The algebraic decomposition of any real matrix into unique symmetric and antisymmetric components holds independently at each resolution level by construction. However, the manuscript does not explicitly demonstrate that the trainable causal downsampling preserves this independence. In the revision we will insert a short lemma (with proof) showing that the causal linear downsampling operators commute with the symmetrisation/antisymmetrisation operations, thereby guaranteeing that the L pairs remain independent. The lemma will appear in Section 3 or the supplementary material. revision: yes
-
Referee: [Experiments] Experiments: Performance improvements are reported as means and standard deviations over three random seeds (+4.77pp on ListOps, +1.44pp on sequential CIFAR-10, +7.47pp on IMDB). However, the manuscript does not detail whether baselines were retrained with matched hyperparameters, the precise implementation of the standard attention baseline, or any statistical significance testing, limiting assessment of whether the gains are robustly attributable to HKT.
Authors: We agree that the experimental section requires additional detail for reproducibility and statistical assessment. In the revised manuscript we will: (i) state that all baselines were retrained using an identical hyperparameter grid search and the same total training budget as HKT; (ii) provide the exact implementation of the standard attention baseline (including the attention formulation, masking, and any fused-kernel optimisations used); and (iii) report paired t-test p-values for the observed accuracy differences across the three seeds. These additions will be incorporated into Section 5 and the appendix. revision: yes
Circularity Check
Subsumption claim (Prop 3.4) is by construction; kernel and error results are independent propositions under stated conditions
specific steps
-
self definitional
[Proposition 3.4]
"HKT strictly subsumes single-head standard attention and causal convolution (Proposition 3.4)."
The subsumption holds by selecting specific convex weights, downsampling factors, and level-specific matrices in the HKT definition that recover the standard single-head attention score matrix or causal convolution kernel exactly; the result is therefore true by construction from the architecture rather than derived from independent first principles.
full rationale
The paper's core claims are framed as propositions and a theorem with explicit sufficient conditions (e.g., on the symmetrised bilinear form for PSD). No fitted parameters are renamed as predictions, no self-citation chains underpin the derivations, and no ansatz is smuggled. The sole minor issue is that the strict subsumption of standard attention and causal convolution follows directly from the hierarchical definition by parameter choice, making it definitional rather than a non-trivial independent result. All other steps (unique decomposition, error decomposition with geometric decay) are presented as derived properties rather than tautologies. This warrants a low score of 2 with no load-bearing circularity in the main analysis.
Axiom & Free-Parameter Ledger
free parameters (2)
- trainable causal downsampling parameters
- learned convex weights
axioms (1)
- domain assumption The symmetrised bilinear form satisfies a sufficient condition that renders the hierarchical score matrix positive semidefinite.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 3.1: hierarchical score matrix defines PSD kernel under sufficient condition on symmetrised bilinear form M^(l)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150 . Cao, S., Wang, L.,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[2]
Rethinking attention with Performers, in: Proceedings of the International Conference on Learning Representations (ICLR). G. Cirrincione:Preprint submitted to ElsevierPage 18 of 20 Hierarchical Kernel Transformer 0 5 10 15 20 25 30 Epoch 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7Loss (a) Training Curve (HKT-Small, d=128) Train loss Val accuracy (%) 50 60 70 80 90 Va...
2000
-
[3]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 . Hatamizadeh, A., Heinrich, G., Yin, H., Tao, A., Alvarez, J.M., Kautz, J., Molchanov, P.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Swin transformer v2: Scaling up capacity and resolution, 2022
Vision transformers with hierarchical attention. Machine Intelligence Research 21, 670–683. Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B., 2021a. Swin Transformer: Hierarchical vision transformer using shifted windows, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 10012–10022. Liu, Z., Li...
-
[5]
Transformer dissection: An unified understanding for transformer’s attention via the lens of kernel, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics. pp. 4335–4344. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.,
2019
-
[6]
Cluster-former: Clustering-based sparse transformer for long-form question answering, in: Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Association for Computational Linguistics. pp. 3947–3957. Wang, S., Li, B.Z., Khabsa, M., Fang, H., Ma, H.,
2021
-
[7]
Linformer: Self-Attention with Linear Complexity
Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768 . Zaheer, M., Guruganesh, G., Dubey, K.A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., Ahmed, A.,
work page internal anchor Pith review arXiv 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.