Recognition: no theorem link
PinpointQA: A Dataset and Benchmark for Small Object-Centric Spatial Understanding in Indoor Videos
Pith reviewed 2026-05-15 06:33 UTC · model grok-4.3
The pith
PinpointQA is the first dataset to test precise localization of small objects in indoor videos for AI models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PinpointQA is built from 1,024 scenes and includes 10,094 QA pairs generated from intermediate spatial representations in indoor videos. The questions are divided into Target Presence Verification, Nearest Reference Identification, Fine-Grained Spatial Description, and Structured Spatial Prediction. Representative multimodal models exhibit a capability gap that widens along this chain of tasks, with Structured Spatial Prediction proving particularly difficult. Supervised fine-tuning on the dataset leads to substantial improvements, especially on the harder tasks.
What carries the argument
The four progressively challenging tasks that require increasing precision in localizing and describing small target objects within video frames.
If this is right
- Models succeeding on the final task would support more reliable object search and assistive applications.
- Fine-tuning with these questions strengthens spatial reasoning in multimodal models.
- The revealed gaps indicate specific areas where current video understanding architectures fall short.
- The automatic generation method supports creating additional similar evaluation data at scale.
Where Pith is reading between the lines
- Applying the same task structure to outdoor or moving scenes could reveal whether the observed gaps persist in more varied settings.
- Integrating PinpointQA-style training into robot systems might improve their ability to locate and interact with small items in real homes.
- The progressive chain could serve as a template for diagnosing other fine-grained perception skills beyond spatial position.
Load-bearing premise
Automatically generated questions from 3D scans, after quality checks, accurately reflect the precise localization skills needed for real-world uses.
What would settle it
A direct comparison of fine-tuned models against baselines on physical robot trials where the robot must locate and report positions of small objects in an actual indoor space.
Figures








read the original abstract
Small object-centric spatial understanding in indoor videos remains a significant challenge for multimodal large language models (MLLMs), despite its practical value for object search and assistive applications. Although existing benchmarks have advanced video spatial intelligence, embodied reasoning, and diagnostic perception, no existing benchmark directly evaluates whether a model can localize a target object in video and express its position with sufficient precision for downstream use. In this work, we introduce PinpointQA, the first dataset and benchmark for small object-centric spatial understanding in indoor videos. Built from ScanNet++ and ScanNet200, PinpointQA comprises 1,024 scenes and 10,094 QA pairs organized into four progressively challenging tasks: Target Presence Verification (TPV), Nearest Reference Identification (NRI), Fine-Grained Spatial Description (FSD), and Structured Spatial Prediction (SSP). The dataset is built from intermediate spatial representations, with QA pairs generated automatically and further refined through quality control. Experiments on representative MLLMs reveal a consistent capability gap along the progressive chain, with SSP remaining particularly difficult. Supervised fine-tuning on PinpointQA yields substantial gains, especially on the harder tasks, demonstrating that PinpointQA serves as both a diagnostic benchmark and an effective training dataset. The dataset and project page are available at https://rainchowz.github.io/PinpointQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PinpointQA, the first dataset and benchmark for small object-centric spatial understanding in indoor videos. Constructed from ScanNet++ and ScanNet200, it contains 1,024 scenes and 10,094 QA pairs organized into four progressively challenging tasks (TPV, NRI, FSD, SSP). QA pairs are generated automatically from intermediate 3D spatial representations with quality control. Experiments on MLLMs show capability gaps along the task chain, with SSP hardest, and demonstrate that supervised fine-tuning on the dataset yields substantial gains.
Significance. If the automatically generated QA pairs are shown to validly measure genuine localization and position expression from raw video without pipeline artifacts, PinpointQA would fill a clear gap in existing video spatial benchmarks and serve as both a diagnostic tool and effective training resource for MLLMs in assistive and search applications.
major comments (2)
- [§3 (Dataset Construction)] §3 (Dataset Construction): The central claim that the four tasks measure small-object spatial understanding from video rests on the assumption that automatically generated QA pairs from intermediate 3D representations (point clouds/meshes) do not introduce exploitable regularities. No quantitative validation—such as human agreement rates, error rates on a sampled subset, or analysis of ambiguity—is reported to rule out models succeeding via generation heuristics rather than video-based localization.
- [§5 (Experiments)] §5 (Experiments): Performance gaps and fine-tuning gains are reported without statistical significance tests, confidence intervals, or controls for task difficulty ordering. This weakens the claim that the progressive chain (TPV to SSP) reliably diagnoses capability limits, particularly since SSP remains difficult.
minor comments (2)
- [Abstract] Ensure all numerical claims (scene count, QA pair count, task definitions) are consistent between abstract and main text tables/figures.
- [Introduction] Clarify notation for the four tasks (TPV/NRI/FSD/SSP) on first use in the introduction for readers unfamiliar with the acronyms.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and will incorporate revisions to strengthen the validation of the dataset and the statistical rigor of the experiments.
read point-by-point responses
-
Referee: [§3 (Dataset Construction)] §3 (Dataset Construction): The central claim that the four tasks measure small-object spatial understanding from video rests on the assumption that automatically generated QA pairs from intermediate 3D representations (point clouds/meshes) do not introduce exploitable regularities. No quantitative validation—such as human agreement rates, error rates on a sampled subset, or analysis of ambiguity—is reported to rule out models succeeding via generation heuristics rather than video-based localization.
Authors: We agree that quantitative validation of the automatically generated QA pairs is important to confirm they measure genuine spatial understanding rather than pipeline artifacts. While the manuscript describes the deterministic generation from 3D annotations followed by manual quality control, we did not report agreement metrics. In the revised version we will add a human validation study: we will sample 300 QA pairs across tasks, have two independent annotators rate correctness and ambiguity against the source 3D data, and report inter-annotator agreement (Cohen’s kappa) together with error rates and examples of any residual ambiguities. This will directly address the concern that models might exploit generation heuristics. revision: yes
-
Referee: [§5 (Experiments)] §5 (Experiments): Performance gaps and fine-tuning gains are reported without statistical significance tests, confidence intervals, or controls for task difficulty ordering. This weakens the claim that the progressive chain (TPV to SSP) reliably diagnoses capability limits, particularly since SSP remains difficult.
Authors: We acknowledge that the absence of statistical tests and confidence intervals limits the strength of the claims about capability gaps and the progressive difficulty ordering. In the revision we will add bootstrap confidence intervals (1,000 resamples) for all reported accuracies, paired statistical tests (McNemar or Wilcoxon signed-rank) comparing model performances across tasks, and an explicit control analysis that randomizes task order to verify that the observed monotonic decline is not an artifact of presentation. These additions will support the diagnostic interpretation of the task chain. revision: yes
Circularity Check
No significant circularity in dataset construction or claims
full rationale
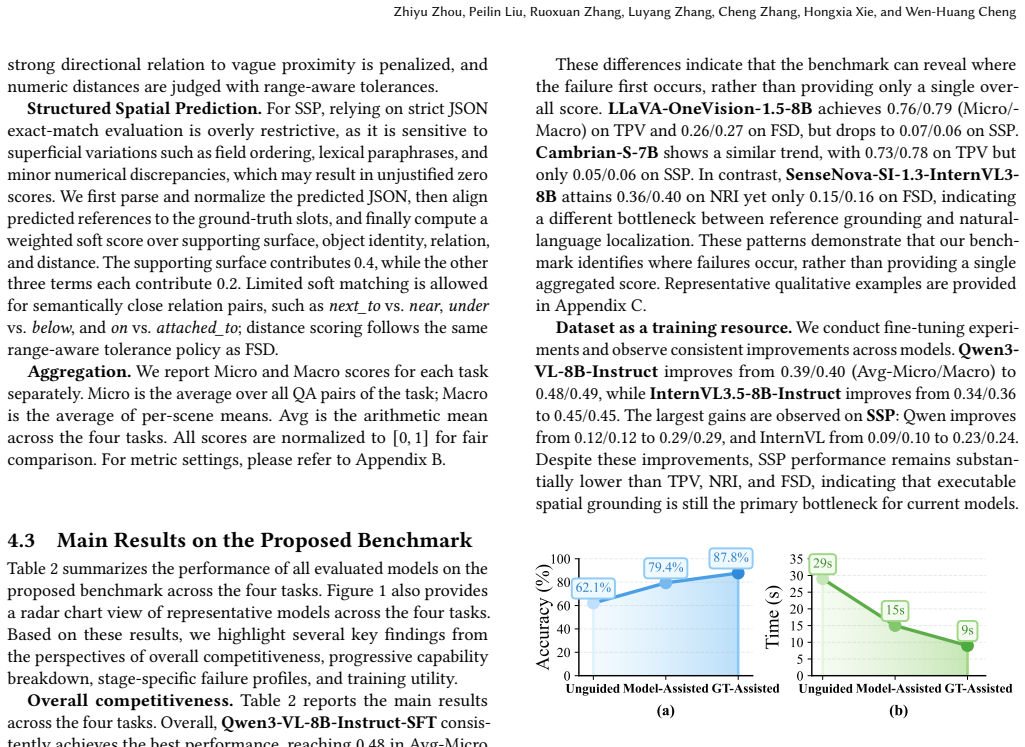
The paper introduces PinpointQA by constructing QA pairs automatically from existing public datasets (ScanNet++ and ScanNet200) using intermediate spatial representations followed by quality control, then evaluates MLLMs on four tasks. No mathematical derivations, equations, fitted parameters, or predictions appear in the text. The central claims rest on the external data sources, the described generation process, and downstream experiments rather than any self-referential reduction or load-bearing self-citation chain. The benchmark is therefore self-contained against external sources and model evaluations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. 2025. Llava-onevision- 1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Tara Boroushaki, Isaac Perper, Mergen Nachin, Alberto Rodriguez, and Fadel Adib. 2021. Rfusion: Robotic grasping via rf-visual sensing and learning. In Proceedings of the 19th ACM conference on embedded networked sensor systems. 192–205
work page 2021
- [4]
- [5]
-
[6]
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. 2017. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition. 5828–5839
work page 2017
-
[7]
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Evan- gelos Kazakos, Jian Ma, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. 2022. Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens-100.International Journal of Computer Vision130, 1 (2022), 33–55
work page 2022
-
[8]
Robert Desimone, John Duncan, et al . 1995. Neural mechanisms of selective visual attention.Annual review of neuroscience18, 1 (1995), 193–222
work page 1995
-
[9]
Mengfei Du, Binhao Wu, Zejun Li, Xuan-Jing Huang, and Zhongyu Wei. 2024. Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 346–355
work page 2024
-
[10]
Yisen Feng, Haoyu Zhang, Meng Liu, Weili Guan, and Liqiang Nie. 2025. Object- shot enhanced grounding network for egocentric video. InProceedings of the Computer Vision and Pattern Recognition Conference. 24190–24200
work page 2025
-
[11]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. 2022. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 18995–19012
work page 2022
-
[12]
Shuting He and Henghui Ding. 2024. Decoupling static and hierarchical motion perception for referring video segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13332–13341
work page 2024
-
[13]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
work page 2022
-
[14]
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, et al . 2024. Chat-scene: Bridging 3d scene and large language models with object identifiers.Advances in Neural Information Processing Systems37 (2024), 113991–114017
work page 2024
-
[15]
Shunya Kato, Shuhei Kurita, Chenhui Chu, and Sadao Kurohashi. 2023. Ark- itscenerefer: Text-based localization of small objects in diverse real-world 3d indoor scenes. InFindings of the Association for Computational Linguistics: EMNLP
work page 2023
-
[16]
Yun Li, Yiming Zhang, Tao Lin, XiangRui Liu, Wenxiao Cai, Zheng Liu, and Bo Zhao. 2025. Sti-bench: Are mllms ready for precise spatial-temporal world under- standing?. InProceedings of the IEEE/CVF International Conference on Computer Vision. 5622–5632
work page 2025
-
[17]
Tianming Liang, Kun-Yu Lin, Chaolei Tan, Jianguo Zhang, Wei-Shi Zheng, and Jian-Fang Hu. 2025. Referdino: Referring video object segmentation with visual grounding foundations. InProceedings of the IEEE/CVF International Conference on Computer Vision. 20009–20019
work page 2025
-
[18]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
work page 2004
-
[19]
Jingli Lin, Chenming Zhu, Runsen Xu, Xiaohan Mao, Xihui Liu, Tai Wang, and Jiangmiao Pang. 2025. OST-Bench: Evaluating the Capabilities of MLLMs in Online Spatio-temporal Scene Understanding. InThe Thirty-ninth Annual Con- ference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=vAkVKIOtcN
work page 2025
-
[20]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: NLG evaluation using gpt-4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language processing. 2511–2522
work page 2023
-
[21]
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. 2023. Egoschema: A diagnostic benchmark for very long-form video language un- derstanding.Advances in Neural Information Processing Systems36 (2023), 46212– 46244
work page 2023
-
[22]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
work page 2002
-
[23]
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Recasens, Larisa Mar- keeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. 2023. Perception test: A diagnostic benchmark for multimodal video models.Advances in Neural Information Processing Systems36 (2023), 42748–42761
work page 2023
-
[24]
David Rozenberszki, Or Litany, and Angela Dai. 2022. Language-grounded indoor 3d semantic segmentation in the wild. InEuropean conference on computer vision. Springer, 125–141
work page 2022
-
[25]
Yuhan Shen, Huiyu Wang, Xitong Yang, Matt Feiszli, Ehsan Elhamifar, Lorenzo Torresani, and Effrosyni Mavroudi. 2024. Learning to segment referred objects from narrated egocentric videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14510–14520
work page 2024
-
[26]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al
-
[27]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. 2026. Kimi K2. 5: Visual Agentic Intelligence.arXiv preprint arXiv:2602.02276(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Antonio Torralba, Aude Oliva, Monica S Castelhano, and John M Henderson
-
[31]
Contextual guidance of eye movements and attention in real-world scenes: the role of global features in object search.Psychological review113, 4 (2006), 766
work page 2006
-
[32]
Timothy J Vickery, Li-Wei King, and Yuhong Jiang. 2005. Setting up the target template in visual search.Journal of vision5, 1 (2005), 8–8
work page 2005
-
[33]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Wenqi Wang, Reuben Tan, Pengyue Zhu, Jianwei Yang, Zhengyuan Yang, Lijuan Wang, Andrey Kolobov, Jianfeng Gao, and Boqing Gong. 2025. Site: towards spa- tial intelligence thorough evaluation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 9058–9069
work page 2025
-
[35]
Jeremy M Wolfe. 2021. Guided Search 6.0: An updated model of visual search. Psychonomic bulletin & review28, 4 (2021), 1060–1092
work page 2021
- [36]
-
[37]
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. 2025. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference. 10632–10643
work page 2025
- [38]
-
[39]
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. 2023. Scannet++: A high-fidelity dataset of 3d indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision. 12–22
work page 2023
-
[40]
Yuqian Yuan, Hang Zhang, Wentong Li, Zesen Cheng, Boqiang Zhang, Long Li, Xin Li, Deli Zhao, Wenqiao Zhang, Yueting Zhuang, et al. 2025. Videorefer suite: Advancing spatial-temporal object understanding with video llm. InProceedings of the Computer Vision and Pattern Recognition Conference. 18970–18980
work page 2025
-
[41]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[42]
Weichen Zhang, Zile Zhou, Xin Zeng, Liu Xuchen, Jianjie Fang, Chen Gao, Jinqiang Cui, Yong Li, Xinlei Chen, and Xiao-Ping Zhang. 2025. Open3d-vqa: A benchmark for embodied spatial concept reasoning with multimodal large language model in open space. InProceedings of the 33rd ACM International Conference on Multimedia. 12784–12791
work page 2025
-
[43]
Chenchen Zhu, Fanyi Xiao, Andrés Alvarado, Yasmine Babaei, Jiabo Hu, Hichem El-Mohri, Sean Culatana, Roshan Sumbaly, and Zhicheng Yan. 2023. Egoobjects: A large-scale egocentric dataset for fine-grained object understanding. InProceed- ings of the IEEE/CVF international conference on computer vision. 20110–20120
work page 2023
-
[44]
Rui Zhu, Xin Shen, Shuchen Wu, Chenxi Miao, Xin Yu, Yang Li, Weikang Li, Deguo Xia, and Jizhou Huang. 2026. Video-MSR: Benchmarking Multi-hop Spatial Reasoning Capabilities of MLLMs.arXiv preprint arXiv:2601.09430(2026). PinpointQA: A Dataset and Benchmark for Small Object-Centric Spatial Understanding in Indoor Videos Appendix Due to space constraints in...
-
[45]
Reference Objects and Supporting Surface
- [46]
-
[47]
FSD Evaluation Setting
-
[48]
Representative Qualitative Examples
SSP Evaluation Setting C. Representative Qualitative Examples
-
[49]
Details of Human Assistance Evaluation
SSP Failure Case D. Details of Human Assistance Evaluation
-
[50]
Interface and Protocol
- [51]
-
[52]
Limitations A Details of Dataset Construction A.1 Scene Curation Scene curation converts each indoor 3D scene into intermediate spa- tial representations that can be reused across all four tasks. Starting from a predefined small object vocabulary, we identify candidate targets and retain nearby objects as potential references. Instead of using the full sc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.