Anchored Sliding Window: Toward Robust and Imperceptible Linguistic Steganography
Pith reviewed 2026-05-10 17:11 UTC · model grok-4.3
The pith
Anchoring the prompt and a bridge context in the sliding window lets language models produce steganographic text that resists edits while staying high quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
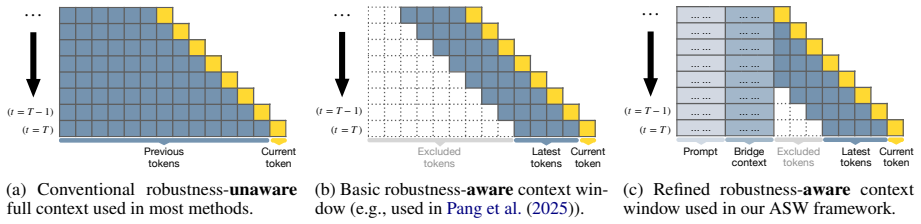
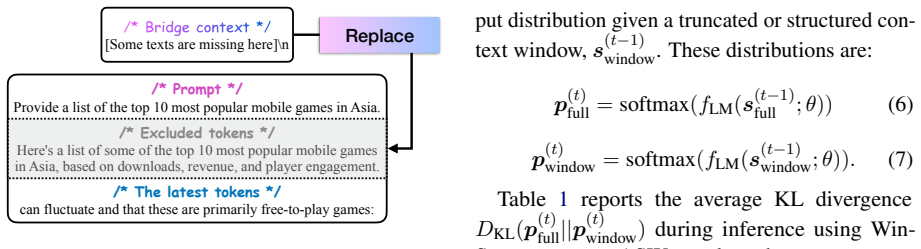
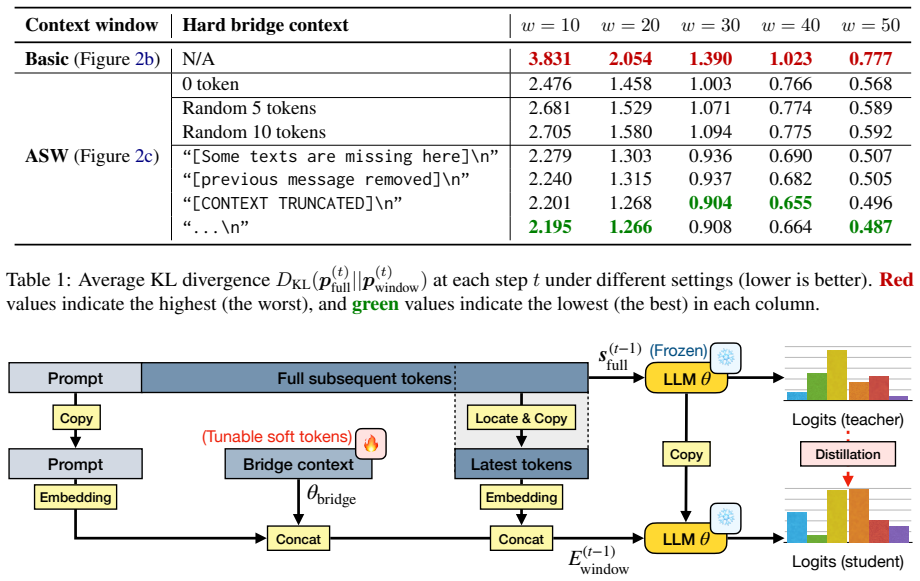
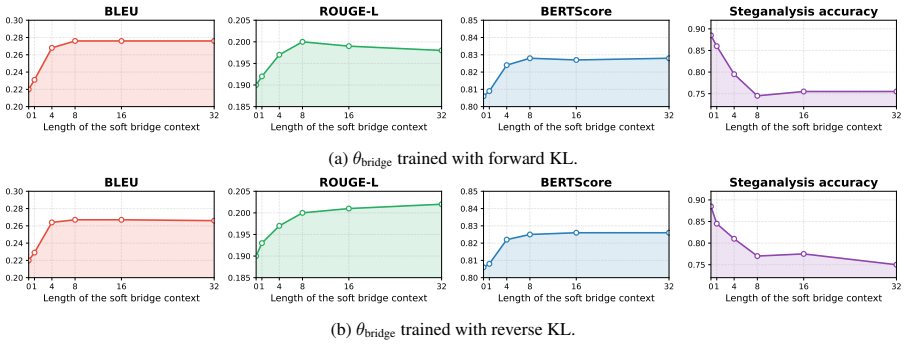
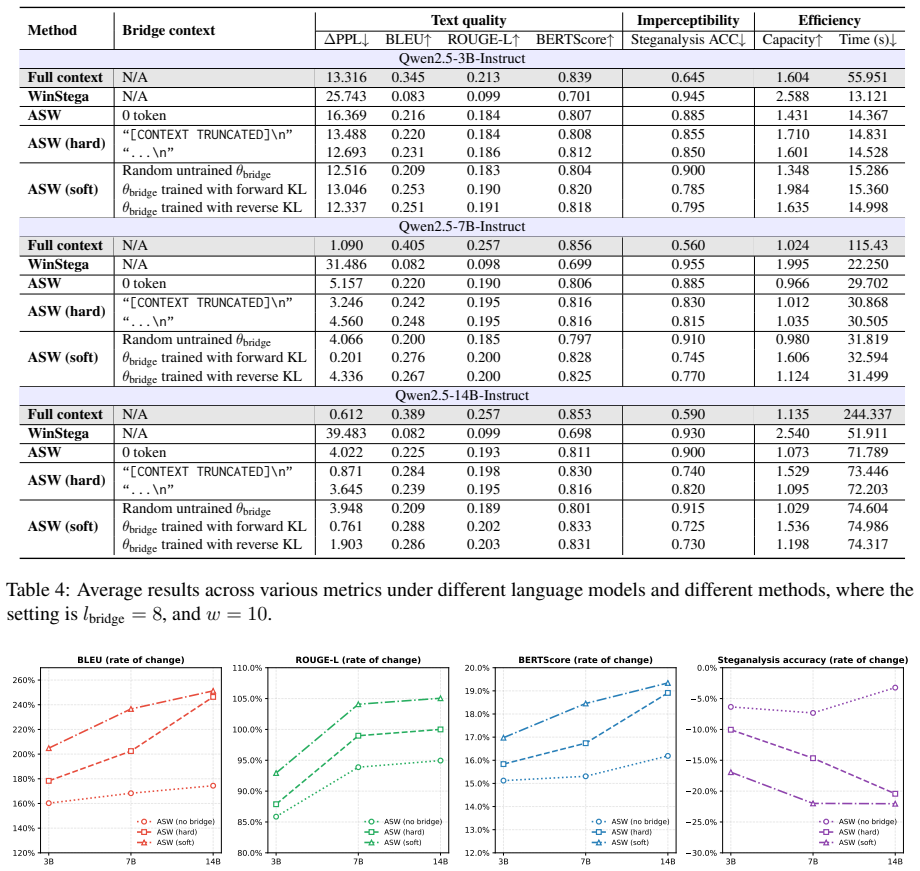
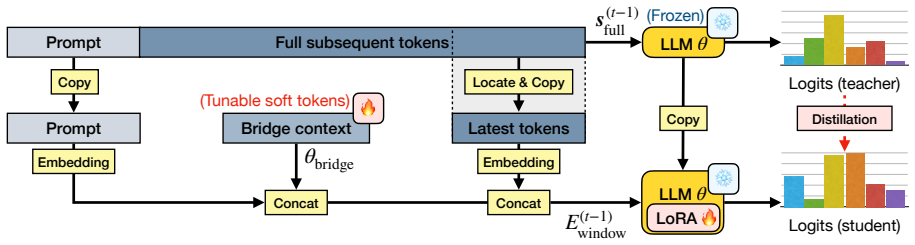
By anchoring both the prompt and a bridge context inside the language model's sliding context window and optimizing the bridge via a prompt-distillation objective extended with self-distillation, the model compensates for excluded tokens and thereby generates steganographic text that maintains higher quality, greater imperceptibility, and stronger robustness to modifications than text produced by the standard sliding-window approach.
What carries the argument
Anchored sliding window (ASW), which fixes the prompt and a distilled bridge context within the sliding context window so the language model compensates for tokens that drop out.
If this is right
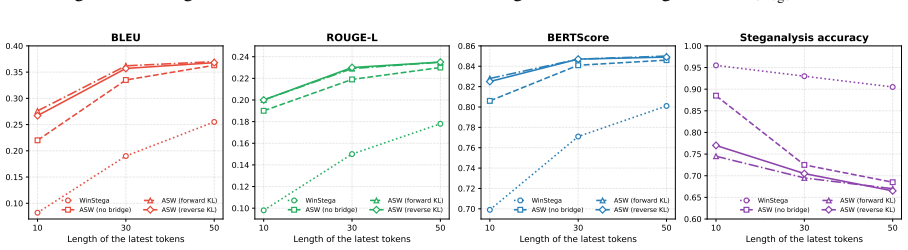
- Text quality stays higher than the baseline even while robustness increases.
- Imperceptibility improves because the generated sentences remain more natural.
- Robustness holds across different language models, message lengths, and embedding rates.
- Self-distillation of the bridge context yields further gains in the same three metrics.
Where Pith is reading between the lines
- The same anchoring idea could be tested in other generation settings where context truncation hurts coherence.
- Pairing ASW with existing watermark detectors might let one control both undetectability and later verifiability.
- Measuring performance under stronger adversarial edits would clarify how far the robustness extends in practice.
Load-bearing premise
Anchoring the prompt and bridge context will cause the language model to compensate for excluded tokens without creating detectable patterns or lowering text quality.
What would settle it
Generate steganographic text with the anchored sliding window, apply small edits such as synonym swaps or punctuation changes, then measure whether the hidden message can still be extracted at a significantly higher rate than with the unanchored baseline.
Figures

read the original abstract
Linguistic steganography based on language models typically assumes that steganographic texts are transmitted without alteration, making them fragile to even minor modifications. While previous work mitigates this fragility by limiting the context window, it significantly compromises text quality. In this paper, we propose the anchored sliding window (ASW) framework to improve imperceptibility and robustness. In addition to the latest tokens, the prompt and a bridge context are anchored within the context window, encouraging the model to compensate for the excluded tokens. We formulate the optimization of the bridge context as a variant of prompt distillation, which we further extend using self-distillation strategies. Experiments show that our ASW significantly and consistently outperforms the baseline method in text quality, imperceptibility, and robustness across diverse settings. The code is available at github.com/ryehr/ASW_steganography.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Anchored Sliding Window (ASW) framework for linguistic steganography. It anchors the initial prompt and a distilled bridge context (formulated via prompt distillation, extended with self-distillation) within the language model's sliding context window to encourage compensation for excluded tokens, aiming to improve robustness to modifications while preserving text quality and imperceptibility over standard sliding-window baselines. Experiments are claimed to show consistent outperformance in quality, imperceptibility, and robustness across diverse settings, with code released.
Significance. If the results and mechanism hold, the work could address a key limitation in LM-based steganography by reducing the quality penalty of context-window restrictions, offering a practical path to more robust covert communication. The prompt-distillation approach for bridge context and code availability are positive for reproducibility and potential follow-up.
major comments (2)
- [Abstract and Experiments section] Abstract and Experiments section: The central claim of 'significant and consistent' outperformance over the baseline in text quality, imperceptibility, and robustness is load-bearing but unsupported by any concrete metrics, baseline descriptions, statistical tests, or ablation results in the abstract (and apparently the experimental reporting). Without these, it is impossible to evaluate effect sizes or isolate whether gains derive from the anchoring mechanism itself.
- [Method section (bridge context optimization)] Method section (bridge context optimization): The weakest assumption—that anchoring the prompt plus distilled bridge context reliably induces the LM to compensate for excluded tokens without detectable artifacts or quality loss—is central to the robustness and imperceptibility claims yet lacks supporting analysis, examples of semantic dependency transfer, or controls showing the bridge captures more than surface statistics. Aggregate wins do not rule out alternative explanations for the reported gains.
minor comments (1)
- [Abstract] The abstract would benefit from including one or two key quantitative results (e.g., perplexity or detection-rate deltas) to strengthen the summary of contributions.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our work. We address each major comment below with clarifications from the manuscript and proposed revisions to strengthen the presentation of results and mechanisms.
read point-by-point responses
-
Referee: [Abstract and Experiments section] Abstract and Experiments section: The central claim of 'significant and consistent' outperformance over the baseline in text quality, imperceptibility, and robustness is load-bearing but unsupported by any concrete metrics, baseline descriptions, statistical tests, or ablation results in the abstract (and apparently the experimental reporting). Without these, it is impossible to evaluate effect sizes or isolate whether gains derive from the anchoring mechanism itself.
Authors: We acknowledge that the abstract summarizes findings at a high level without numerical values, consistent with typical length constraints. The Experiments section reports concrete comparisons against the standard sliding-window baseline using metrics for text quality (perplexity and human evaluation scores), imperceptibility (detection accuracy under steganalysis), and robustness (performance under token deletions, substitutions, and edits), with results aggregated across multiple language models and settings. To address the concern directly, we will revise the abstract to include key quantitative improvements (e.g., relative gains in each metric) and expand the Experiments section with statistical significance tests and targeted ablations that isolate the anchoring and bridge-distillation components from other factors. This will make effect sizes and mechanistic contributions more transparent. revision: yes
-
Referee: [Method section (bridge context optimization)] Method section (bridge context optimization): The weakest assumption—that anchoring the prompt plus distilled bridge context reliably induces the LM to compensate for excluded tokens without detectable artifacts or quality loss—is central to the robustness and imperceptibility claims yet lacks supporting analysis, examples of semantic dependency transfer, or controls showing the bridge captures more than surface statistics. Aggregate wins do not rule out alternative explanations for the reported gains.
Authors: We agree that additional mechanistic evidence would strengthen the claims. The bridge context is obtained via prompt distillation (extended with self-distillation) specifically to encode information from excluded tokens that the model needs for coherent generation. In the revision we will add qualitative examples showing how the anchored bridge enables the model to recover semantic dependencies (such as entity references or logical continuations) that would otherwise be lost. We will also include control experiments contrasting the distilled bridge against surface-level alternatives (e.g., n-gram or keyword-based contexts) to demonstrate that gains arise from deeper semantic capture rather than superficial statistics. These additions will help rule out alternative explanations while preserving the core optimization approach. revision: yes
Circularity Check
No circularity; empirical proposal with independent experimental validation
full rationale
The paper presents an engineering improvement (anchored sliding window with prompt/bridge anchoring and distillation-based optimization) whose central claims rest on experimental comparisons to a baseline across quality, imperceptibility, and robustness metrics. No derivation chain, uniqueness theorem, or fitted parameter is presented as a first-principles result that reduces to its own inputs by construction. The formulation of bridge-context optimization as a prompt-distillation variant is an explicit modeling choice, not a self-referential definition or renamed known result. Self-citations, if present, are not load-bearing for the core claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models generate coherent text conditioned on a context window that can be selectively anchored.
Reference graph
Works this paper leans on
-
[1]
Provably secure steganography.IEEE Trans- actions on Computers, 58(5):662–676. Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations. Fred Jelinek, Robert L Mercer, Lalit R Bahl, and Jame...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Neural linguistic steganography. InProceed- ings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Inter- national Joint Conference on Natural Language Pro- cessing (EMNLP-IJCNLP), pages 1210–1215, Hong Kong, China. Association for Computational Linguis- tics. A Imperceptibility of LM-based Steganography Following the ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.