Persona-E²: A Human-Grounded Dataset for Personality-Shaped Emotional Responses to Textual Events
Pith reviewed 2026-05-10 18:01 UTC · model grok-4.3
The pith
Personality traits produce distinct emotional responses to identical textual events, and a new human dataset shows state-of-the-art LLMs fail to capture these shifts without trait cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a human-grounded dataset linking personality profiles to reader emotional responses reveals the limitations of current LLMs in simulating authentic appraisal shifts and that explicit personality data, particularly Big Five traits, helps models avoid personality illusion by moving beyond stereotypes to more accurate cognitive patterns.
What carries the argument
The Persona-E² dataset, which pairs textual events with human emotional response annotations conditioned on MBTI and Big Five personality profiles.
If this is right
- LLMs achieve better performance on emotional response tasks when supplied with personality trait details.
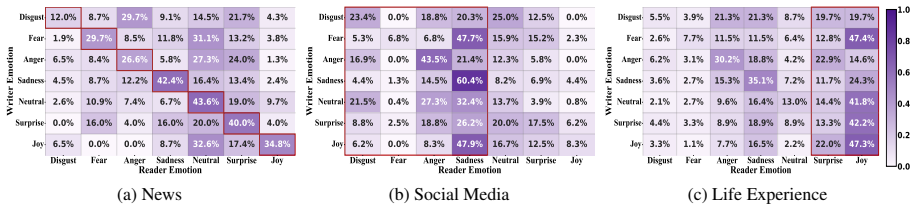
- Social media content presents the greatest difficulty for accurate personality-shaped appraisal modeling.
- Big Five traits reduce stereotypical outputs more effectively than MBTI traits in LLM simulations.
- The dataset supports improved training of models for personalized affective computing applications.
Where Pith is reading between the lines
- Similar human-grounded datasets could be built for personality effects on other processes such as decision-making or ethical judgments.
- The collection method offers a way to test and reduce personality stereotypes across a wider range of AI tasks beyond emotion.
- Extending the approach to non-text inputs like images could show how personality influences multimodal emotional reactions.
Load-bearing premise
The annotated personality traits and collected human emotional responses reflect genuine individual cognitive differences rather than surface-level stereotypes or inconsistent judgments.
What would settle it
A follow-up study that gathers fresh human emotional responses for the same events and personality profiles and finds low agreement with the original annotations, or shows that LLMs given personality information still match human responses no better than models without it.
Figures






read the original abstract
Most affective computing research treats emotion as a static property of text, focusing on the writer's sentiment while overlooking the reader's perspective. This approach ignores how individual personalities lead to diverse emotional appraisals of the same event. Although role-playing Large Language Models (LLMs) attempt to simulate such nuanced reactions, they often suffer from "personality illusion'' -- relying on surface-level stereotypes rather than authentic cognitive logic. A critical bottleneck is the absence of ground-truth human data to link personality traits to emotional shifts. To bridge the gap, we introduce Persona-E$^2$ (Persona-Event2Emotion), a large-scale dataset grounded in annotated MBTI and Big Five traits to capture reader-based emotional variations across news, social media, and life narratives. Extensive experiments reveal that state-of-the-art LLMs struggle to capture precise appraisal shifts, particularly in social media domains. Crucially, we find that personality information significantly improves comprehension, with the Big Five traits alleviating "personality illusion.'
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Persona-E², a large-scale human-grounded dataset annotating reader emotional responses to textual events across news, social media, and life narratives, using MBTI and Big Five personality traits. It claims that LLMs suffer from 'personality illusion' (relying on stereotypes rather than authentic cognitive logic) when simulating nuanced reactions, demonstrates that state-of-the-art LLMs struggle with precise appraisal shifts (especially in social media), and shows that conditioning on personality traits—particularly Big Five—significantly improves comprehension and alleviates this illusion.
Significance. If the annotations reliably link traits to emotional appraisals via genuine mechanisms rather than stereotypes, the dataset would be a valuable benchmark resource for affective computing and personalized NLP, enabling better evaluation of role-playing LLMs. The empirical results on LLM limitations and personality conditioning benefits could guide future work on nuanced emotion modeling, provided the ground truth is validated.
major comments (2)
- [§3 (Dataset Construction)] §3 (Dataset Construction): The claim that annotated MBTI and Big Five traits capture authentic cognitive logic for emotional appraisals (rather than surface stereotypes) is load-bearing for the 'personality illusion' alleviation result, yet no inter-annotator agreement on appraisal dimensions, controls for stereotypical priors, or checks that trait–emotion mappings exceed label-only predictions are described. This leaves open whether LLM improvements reflect deeper comprehension or better stereotype matching.
- [§4–5 (Experiments)] §4–5 (Experiments): The headline finding that 'personality information significantly improves comprehension, with the Big Five traits alleviating personality illusion' and that LLMs 'struggle to capture precise appraisal shifts' lacks reported error bars, baseline comparisons, statistical tests, or domain-specific breakdowns; without these, the robustness of the cross-domain and Big-Five-vs-MBTI claims cannot be assessed.
minor comments (2)
- [Abstract] Abstract: The term 'personality illusion' is used without a concise definition or citation to prior work; adding one sentence would improve accessibility.
- [Introduction] Throughout: Ensure 'appraisal shifts' is explicitly defined in the introduction, as it is central to the evaluation metrics but appears only in the abstract and results.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important aspects of validation and statistical rigor. We have revised the manuscript to strengthen the presentation of our dataset construction and experimental results. Below we respond to each major comment.
read point-by-point responses
-
Referee: §3 (Dataset Construction): The claim that annotated MBTI and Big Five traits capture authentic cognitive logic for emotional appraisals (rather than surface stereotypes) is load-bearing for the 'personality illusion' alleviation result, yet no inter-annotator agreement on appraisal dimensions, controls for stereotypical priors, or checks that trait–emotion mappings exceed label-only predictions are described. This leaves open whether LLM improvements reflect deeper comprehension or better stereotype matching.
Authors: We agree that demonstrating the annotations reflect cognitive mechanisms beyond stereotypes is central to our claims. The original §3 detailed the annotation protocol, including event-focused prompts and a diverse pool of annotators screened for consistency. In the revision, we now report inter-annotator agreement specifically on the appraisal dimensions (using Fleiss' kappa and percentage agreement). We have also added a control analysis in §4 that compares trait-conditioned emotion predictions against a label-only baseline (emotion prediction without personality traits), showing statistically higher alignment with human data when traits are included. While exhaustive elimination of all stereotypical priors is challenging in any annotation study, the event-centric design and post-annotation debriefs were intended to reduce reliance on trait stereotypes. We have expanded the limitations discussion accordingly. revision: yes
-
Referee: §4–5 (Experiments): The headline finding that 'personality information significantly improves comprehension, with the Big Five traits alleviating personality illusion' and that LLMs 'struggle to capture precise appraisal shifts' lacks reported error bars, baseline comparisons, statistical tests, or domain-specific breakdowns; without these, the robustness of the cross-domain and Big-Five-vs-MBTI claims cannot be assessed.
Authors: We concur that additional statistical details are needed to support the robustness of these findings. The original experiments already included non-personality baselines and cross-domain results, but the revision now incorporates error bars (standard deviation across 5 random seeds) for all metrics in Tables 2–4. We have added paired statistical tests (McNemar’s test with Bonferroni correction) to confirm the significance of improvements from personality conditioning, with particular emphasis on Big Five versus MBTI. Expanded domain-specific breakdowns, including per-domain appraisal shift errors, are now provided in new supplementary tables and figures in §5. These revisions allow clearer evaluation of the claims regarding LLM limitations and the relative benefits of different trait frameworks. revision: yes
Circularity Check
No circularity in empirical dataset and evaluation pipeline
full rationale
The paper constructs a human-annotated dataset linking MBTI/Big Five traits to emotional appraisals of events and evaluates LLM performance on it. No equations, fitted parameters, or predictive derivations are present; all claims rest on direct experimental comparisons between models with and without personality conditioning. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes, and the work does not rename prior results or smuggle assumptions through citations. The derivation chain is therefore self-contained against external human annotations and benchmark evaluations.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce Persona-E2 ... grounded in annotated MBTI and Big Five traits to capture reader-based emotional variations ... personality information significantly improves comprehension, with the Big Five traits alleviating 'personality illusion.'
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Personality Agreement Gap (PAG = Agrin − Agrout) ... BFI K-means clustering ... in-group Top-1 agreement consistently outperforms the global average.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.11734
Scaling law in llm simulated personality: More detailed and realistic persona profile is all you need. arXiv preprint arXiv:2510.11734. Roy F Baumeister, Ellen Bratslavsky, Catrin Finkenauer, and Kathleen D V ohs. 2001. Bad is stronger than good.Review of general psychology, 5(4):323–370. Laura Ana Maria Bostan, Evgeny Kim, and Roman Klinger. 2020. GoodNe...
-
[2]
GoEmotions: A dataset of fine-grained emo- tions. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4040–4054, Online. Association for Computational Linguistics. Keyang Ding, Chuang Fan, Yiwen Ding, Qianlong Wang, Zhiyuan Wen, Jing Li, and Ruifeng Xu
-
[3]
Lcsep: A large-scale chinese dataset for so- cial emotion prediction to online trending topics. IEEE Transactions on Computational Social Systems, 11(3):3362–3375. Paul Ekman. 1992. An argument for basic emotions. Cognition & emotion, 6(3-4):169–200. Maxwell Forbes, Jena D. Hwang, Vered Shwartz, Maarten Sap, and Yejin Choi. 2020. Social chem- istry 101: L...
-
[4]
Scaling Laws for Neural Language Models
Big five inventory.Journal of personality and social psychology. Oliver P John, Richard W Robins, and Lawrence A Pervin. 2010.Handbook of personality: Theory and research. Guilford Press. John A. Johnson. 2014. Measuring thirty facets of the five factor model with a 120-item public domain in- ventory: Development of the ipip-neo-120.Journal of Research in...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
Editing personality for large language mod- els. InNatural Language Processing and Chinese Computing: 13th National CCF Conference, NLPCC 2024, Hangzhou, China, November 1–3, 2024, Pro- ceedings, Part II, page 241–254, Berlin, Heidelberg. Springer-Verlag. Margaret W Matlin. 2016. Pollyanna principle. InCog- nitive illusions, pages 315–335. Psychology Pres...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Enrica Troiano, Sebastian Padó, and Roman Klinger
Dimensional modeling of emotions in text with appraisal theories: Corpus creation, annotation reliability, and prediction.Computational Linguis- tics, 49(1):1–72. Enrica Troiano, Sebastian Padó, and Roman Klinger
-
[7]
Crowdsourcing and validating event-focused emotion corpora for German and English. InPro- ceedings of the 57th Annual Meeting of the Asso- ciation for Computational Linguistics, pages 4005– 4011, Florence, Italy. Association for Computational Linguistics. Yu-Min Tseng, Yu-Chao Huang, Teng-Yun Hsiao, Wei- Lin Chen, Chao-Wei Huang, Yu Meng, and Yun- Nung Ch...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
collected first-person narratives of life events, treating the event as the primitive stimulus for ac- tual affective responses, rather than inferring emo- tion from lexical cues alone. Subsequent datasets expanded this scope to interpersonal and social commonsense scenarios (Rashkin et al., 2018; Sap et al., 2019b; Forbes et al., 2020). Subse- quent rese...
work page 2018
-
[9]
and EmotionLines (Hsu et al., 2018) have ex- tended this paradigm to dialogues and audiovisual interactions. While valuable, these datasets pri- marily capture writer-side expressions rather than reader-side elicitation. Conversely, implicit meth- ods bypass questionnaires and derive personality from textual expressions (Gao et al., 2013; Hu et al., 2024b...
work page 2018
-
[10]
to detect potential offensive content. A data sample was discarded if either model predicted it as "NSFW" (Not Safe For Work) with a confidence score exceeding the default threshold. This rigor- ous process minimizes the inclusion of explicit or harmful text. •Distilbert-NSFW (Albouzidi, 2023): eliasalbouzidi/distilbert-nsfw-text-classifier •Roberta-large...
work page 2023
-
[11]
Dr Blaine McGraw is alleged to have secretly filmed intimate videos of patients in his care
-
[12]
The teacher, Abby Zwerner, was shot in January 2023 in her classroom at Richneck Elementary School in Newport News, Virginia
work page 2023
-
[13]
Aircraft ‘disappeared from radar without transmit- ting distress signal’ minutes after entering Georgian airspace
-
[14]
A woman sworn in as a city council member in Bangor, Maine, served time in prison for manslaughter
-
[15]
climate talks in Brazil, prompting evacuations as firefighters rushed to control the flames
A fire broke out at the venue hosting U.N. climate talks in Brazil, prompting evacuations as firefighters rushed to control the flames
-
[16]
Surprisingly, they were both sat quietly watching TV
Today, we got back from our second honeymoon and went to pick the kids up from my mom’s. Surprisingly, they were both sat quietly watching TV . Half jokingly, I asked my mom what her secret was. Without even a guilty pause she told me, Benadryl for chesty coughs in their juice. You’re welcome
-
[17]
We got them and then went to the cashier
Today, I went to the store for some pads with my dad. We got them and then went to the cashier. That’s when he realized that they were scented. He took one out of the box, sniffed it, made me sniff it, then insisted the cashier smell it
-
[18]
He said not to bother, and that he already had someone else in mind to take with him
Today, I told my boyfriend I wouldn’t be able to get any time off work to go to Mexico with him, and that we’d have to get our tickets refunded, and reschedule. He said not to bother, and that he already had someone else in mind to take with him
-
[19]
Today, my best friend on Snapchat is my mum
-
[20]
My mom recently passed away and I miss her more than words could ever express. During the height of the pandemic she underwent awful, brutal rounds of chemo and never ever complained. I have a photo of her on my desk showing her true RandomActsofKindness, a day in the life of my mom. She’s walking into treatment wearing a mask, her cute bald head in a cut...
-
[21]
Why do I always feel like I’m going to die and run through disaster scenarios every time I speak publicly at work?
-
[22]
When I look over, no one is there
Has anyone else felt or seen “ghosts”? When other people don’t notice? I’ve walked with friends and seen someone keeping pace, in my peripherally, on the sidewalk across the street. When I look over, no one is there. I’ve dreamt of people who passed away hours before or after they do. They never know they are dead, so I end up having to tell them. Looking...
-
[23]
My coworker complained about being broke then showed up with a designer bag the next day 14. Bought the apartment across the street for my parents—yet a bowl of soup’s distance has turned into yesterday’s leftovers
-
[24]
No name" option to avoid an extra $20 embroidering fee. My jacket now has
Is it normal to not give your roommate a heads up about a SO sleeping over for 5 day per week ? C Annotation Details C.1 Annotation Platform The annotation platform is designed for conve- nient online annotation and will be released in two months. The demonstration is shown in Fig. 7. C.2 Quality Control To ensure high-fidelity emotional annotations, we i...
work page 1962
-
[25]
Sensitivity analysis for α has not been conducted
Intra-group Consistency:We retain events where specific personality groups demonstrate high internal agreement ( Sconsensus(G)> α, α= 0..3 ), ensuring the emotional signal is not random noise. Sensitivity analysis for α has not been conducted
-
[26]
Inter-group Divergence:Among high- consensus events, we select those where the dominant emotional labels differ significantly across distinct personality profiles. Following this process, the final SDS comprises 413 events, distributed across domains as 257 from News, 69 from Social Media, and 87 from Life Experience. E.3.3 Prompt Settings We conducted ex...
-
[27]
Do not output your thinking process; 3) Strictly fol- low the required output format. # USER ROLE Please analyze the underlying reasons for {real_name}’s reported emotion and intensity when reading the text below: [Event Text]: {event_text} [Reported Emotion]: {emotion} [Emotion Intensity]: {intensity} (1-5) Please output the analysis in the following for...
-
[28]
Conscientiousness (C):self-discipline, dutifulness
-
[29]
Agree- ableness (A):altruism, empathy;5
Extraversion (E):sociability, optimism;4. Agree- ableness (A):altruism, empathy;5. Neuroticism (N): emotional instability, anxiety. [Current Subject]Name: {real_name}; Personality Scores: {bfi_desc}. [Rules]1) Output analysis directly without fillers; 2) Explain how specific O/C/E/A/N dimensions influ- enced the emotion; 3) Do not output thinking process
-
[30]
Follow the required format. # USER ROLE Please analyze the underlying reasons for {real_name}’s reported emotion and intensity when reading the text below: [Event]: {event_text} [Emotion]: {emotion} [Intensity]: {intensity} (1-5) Please output the analysis in the following format: •Event Summary:(One sentence summary) • Personality Analysis:(Explicitly me...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.