Recognition: unknown
Is More Data Worth the Cost? Dataset Scaling Laws in a Tiny Attention-Only Decoder
Pith reviewed 2026-05-10 16:38 UTC · model grok-4.3
The pith
A tiny attention-only decoder reaches about 90% of full-data accuracy using only 30% of the training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the reduced attention-only decoder, validation token accuracy improves smoothly with dataset size yet shows pronounced diminishing returns, such that training on approximately 30 percent of the data suffices to reach about 90 percent of the accuracy achieved with the full training set.
What carries the argument
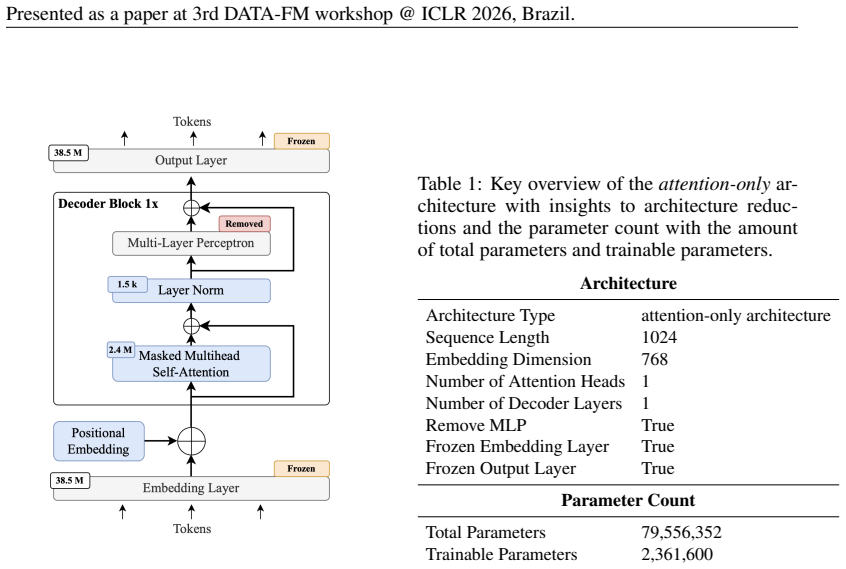
Progressively larger power-of-two subsets of the training data, which trace the scaling curve while the stripped-down decoder holds other architectural factors fixed.
If this is right
- Performance follows predictable scaling-law shapes even in very small, component-isolated models.
- The bulk of accuracy gains occurs early, so later additions of data yield progressively smaller improvements.
- Compute budgets in restricted environments can be redirected from data collection to other uses once the 30-percent threshold is passed.
- The observed diminishing returns supply a practical stopping criterion for dataset construction.
Where Pith is reading between the lines
- The same early-saturation pattern may appear in larger models, suggesting that targeted data pruning or quality filtering could substitute for raw volume in many cases.
- The method could be reused to compare different data sources or curricula rather than simple random subsets.
- Extending the power-of-two schedule to measure exact cost-benefit breakpoints for specific downstream tasks would make the guidance more actionable.
Load-bearing premise
The strongly reduced attention-only decoder isolates pure dataset-size effects without adding confounding behaviors that would not appear in standard full-scale models.
What would settle it
If a standard full-scale Transformer trained on the same power-of-two subsets required substantially more than 30 percent of the data to reach 90 percent of its own maximum accuracy, the isolation claim would be undermined.
Figures






read the original abstract
Training Transformer language models is expensive, as performance typically improves with increasing dataset size and computational budget. Although scaling laws describe this trend at large scale, their implications in controlled, smaller-scale settings remain less explored. In this work, we isolate dataset-size effects using a strongly reduced attention-only decoder architecture. By training on progressively larger power-of-two subsets, we observe smooth performance improvements accompanied by clear diminishing returns, consistent with scaling-law behavior. Using only about 30% of the training data is sufficient to reach approximately 90% of the full-data validation token-level accuracy. These results provide actionable insights into dataset scaling in a controlled, component-isolated setting and offer practical guidance for balancing dataset size and computational cost in compute- and data-restricted environments, such as small research labs and exploratory model development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that in a strongly reduced attention-only decoder, training on progressively larger power-of-two subsets of data yields smooth performance gains with diminishing returns, such that approximately 30% of the full training data suffices to reach about 90% of the full-data validation token-level accuracy. The work positions this as an empirical isolation of dataset-size effects in a controlled small-scale setting.
Significance. If the central empirical ratio holds after details are supplied, the result supplies concrete, actionable guidance for data-efficient training in compute-limited environments. The direct measurement of held-out token accuracy (rather than a fitted functional form) is a methodological strength that avoids circularity.
major comments (2)
- [Abstract] Abstract: the 30%/90% claim is stated without any supporting numbers, error bars, model dimensions (layers, heads, embedding size), dataset identity, tokenization scheme, subset-sampling procedure, or training hyperparameters. These omissions are load-bearing because they prevent assessment of whether the observed ratio is reproducible or architecture-specific.
- [Abstract] Abstract: the premise that the 'strongly reduced attention-only decoder' isolates dataset-size effects is asserted without justification or controls. In a minimal-capacity model, performance is plausibly dominated by parameter count and depth rather than data volume, so the early onset of diminishing returns could be an artifact of under-capacity rather than a general dataset scaling law.
minor comments (1)
- [Abstract] Abstract: the phrase 'clear diminishing returns, consistent with scaling-law behavior' would benefit from a brief quantitative illustration (e.g., accuracy delta between the 50% and 100% data regimes) to make the consistency claim concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 30%/90% claim is stated without any supporting numbers, error bars, model dimensions (layers, heads, embedding size), dataset identity, tokenization scheme, subset-sampling procedure, or training hyperparameters. These omissions are load-bearing because they prevent assessment of whether the observed ratio is reproducible or architecture-specific.
Authors: The abstract is intentionally concise as a high-level summary. All requested details—model dimensions, dataset identity, tokenization, subset-sampling method, training hyperparameters, and supporting numbers with variability measures—are provided in the Methods and Experiments sections of the full manuscript. To make the central claim more self-contained, we will revise the abstract to include a brief specification of the model architecture, dataset, and experimental procedure. revision: yes
-
Referee: [Abstract] Abstract: the premise that the 'strongly reduced attention-only decoder' isolates dataset-size effects is asserted without justification or controls. In a minimal-capacity model, performance is plausibly dominated by parameter count and depth rather than data volume, so the early onset of diminishing returns could be an artifact of under-capacity rather than a general dataset scaling law.
Authors: The strongly reduced attention-only decoder was deliberately chosen to hold architecture, depth, and parameter count fixed while varying only dataset size, thereby isolating the effect of data volume. This controlled design is justified in the introduction as a means to study dataset scaling in a minimal, reproducible setting relevant to compute-limited environments. We agree that capacity constraints may influence the exact point of diminishing returns and will add an expanded justification plus a limitations discussion in the introduction to clarify the scope and generalizability of the findings. revision: partial
Circularity Check
No circularity; direct empirical measurements of observed accuracy
full rationale
The paper reports direct training runs on power-of-two data subsets of a fixed tiny attention-only decoder, measuring validation token-level accuracy as an observed outcome. The central claim (approximately 30% data reaching 90% of full-data accuracy) is presented as an empirical result, not as a prediction derived from any equation, fitted parameter, or self-citation chain. No load-bearing step reduces to its own inputs by construction; the work contains no derivations, uniqueness theorems, or ansatzes that could introduce circularity. This is the most common honest finding for purely observational scaling studies.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Power-of-two data subsets allow fair isolation of dataset-size effects without selection bias or distribution shift.
Reference graph
Works this paper leans on
-
[1]
URLhttp://arxiv.org/ abs/2410.13732
doi: 10.5220/0012891000003838. URLhttp://arxiv.org/ abs/2410.13732. arXiv:2410.13732 [cs]. Zhengyu Chen, Siqi Wang, Teng Xiao, Yudong Wang, Shiqi Chen, Xunliang Cai, Junxian He, and Jingang Wang. Revisiting Scaling Laws for Language Models: The Role of Data Qual- ity and Training Strategies. InProceedings of the 63rd Annual Meeting of the Association for ...
-
[2]
doi: 10.18653/v1/2025.acl-long.1163
Association for Computational Linguistics. doi: 10.18653/v1/2025.acl-long.1163. URL https://aclanthology.org/2025.acl-long.1163. Danny Hernandez, Tom Brown, Tom Conerly, Nova DasSarma, Dawn Drain, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Tom Henighan, Tristan Hume, Scott Johnston, Ben Mann, Chris Olah, Catherine Olsson, Dario Amodei, Nicholas Jo...
-
[3]
Computing Research Repository , eprint=
URL http://arxiv.org/abs/2205.10487. arXiv:2205.10487 [cs]. Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan...
-
[4]
Training Compute-Optimal Large Language Models
URLhttp: //arxiv.org/abs/2203.15556. arXiv:2203.15556 [cs]. Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling Laws for Neural Language Models, January
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Scaling Laws for Neural Language Models
URLhttp://arxiv.org/abs/2001.08361. arXiv:2001.08361 [cs]. J. Lin. Divergence measures based on the Shannon entropy.IEEE Transactions on Information Theory, 37(1):145–151, January
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[6]
ISSN 00189448. doi: 10.1109/18.61115. URLhttp: //ieeexplore.ieee.org/document/61115/. Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer Sentinel Mixture Models, September
-
[7]
Pointer Sentinel Mixture Models
URLhttps://arxiv.org/abs/1609.07843. Niklas Muennighoff, Alexander M. Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Noua- mane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling Data-Constrained Language Models, June
work page internal anchor Pith review arXiv
-
[8]
URLhttp://arxiv.org/abs/2305.16264. arXiv:2305.16264 [cs]. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Lan- guage Models are Unsupervised Multitask Learners.OpenAI Blog,
-
[9]
URLhttp://arxiv.org/ abs/2410.16523
doi: 10.5220/0012893600003838. URLhttp://arxiv.org/ abs/2410.16523. arXiv:2410.16523 [cs]. Andrew Thompson. All the news 2.0, March
-
[10]
URLhttp://arxiv.org/abs/2305. 12816. arXiv:2305.12816 [cs]. 11 Presented as a paper at 3rd DATA-FM workshop @ ICLR 2026, Brazil. A DATASETSTATISTICSAllTheNews2.0 Table 4: Training and validation dataset statistics of articles after cleaning (>500tokens) Statistic Training Dataset Validation Dataset Number of Sequences 131,072 20,000 Sequence Length 1024 t...
-
[11]
Loss Val
Subset Level Val. Loss Val. Perplexity Val. Accuracy (%) 27 11.24±0.07 76 320±4973 0.40±0.12 28 9.71±0.10 16 453±1588 2.12±0.41 29 8.68±0.05 5911±268 3.13±0.21 210 8.21±0.02 3683±80 4.00±0.50 211 7.70±0.08 2203±178 5.74±1.20 212 7.36±0.04 1574±63 7.13±0.27 213 7.20±0.06 1336±86 7.80±0.31 214 6.88±0.05 974±47 9.18±0.28 215 6.61±0.05 746±35 10.37±0.19 216 6...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.