Recognition: unknown
On the Representational Limits of Quantum-Inspired 1024-D Document Embeddings: An Experimental Evaluation Framework
Pith reviewed 2026-05-10 16:39 UTC · model grok-4.3
The pith
Quantum-inspired 1024-dimensional document embeddings show weak and unstable ranking signals compared to BM25 and dense teacher models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
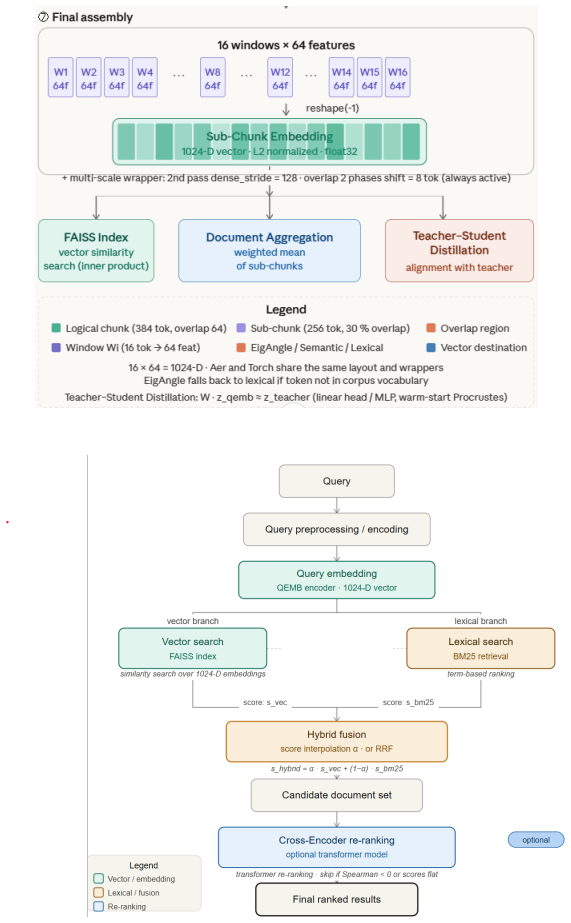
The paper claims that quantum-inspired 1024-D embeddings built from overlapping windows, multi-scale aggregation, EigAngle projections, and circuit-inspired mappings exhibit structural geometric limitations including distance compression and ranking instability. These properties make the embeddings unsuitable as standalone retrieval representations, as shown by their weak performance against BM25 baselines and teacher embeddings across domains. Distillation produces mixed alignment effects, but hybrid fusion of lexical and embedding signals through interpolation and candidate union recovers competitive results, positioning quantum-inspired methods as auxiliary rather than primary tools.
What carries the argument
The hybrid retrieval diagnostic tools, including static and dynamic score interpolation between BM25 and embeddings, candidate union strategies, and the alpha-oracle upper bound for fusion.
If this is right
- BM25 remains a strong baseline across technical, narrative, and legal document collections.
- Dense teacher embeddings from LLMs supply more stable semantic structure than the quantum-inspired variants.
- Standalone quantum-inspired embeddings produce weak and unstable ranking signals due to distance compression.
- Teacher-student distillation improves alignment in some cases but does not consistently raise retrieval metrics.
- Hybrid combinations of lexical matching and embedding scores via interpolation and union can achieve competitive overall performance.
Where Pith is reading between the lines
- The observed distance compression may indicate a deeper mismatch between Hilbert-space assumptions and actual text semantic geometry that alternative mappings could address.
- Extending the framework to authentic user queries rather than synthetic ones could reveal whether ranking instability increases or decreases outside controlled settings.
- These embeddings might perform better in non-ranking tasks such as document clustering where exact distance preservation matters less.
- The results imply that future quantum-inspired work should prioritize hybrid integration rather than attempts at fully standalone semantic representations.
Load-bearing premise
The assumption that experiments on controlled corpora with synthetic queries across three domains and the chosen EigAngle plus circuit-inspired mappings sufficiently represent real-world retrieval behavior of these embeddings.
What would settle it
Running the same embeddings on large real-user query logs from production search systems and observing stable high ranking performance without heavy hybrid fusion would falsify the claim of structural limitations.
Figures





read the original abstract
Text embeddings are central to modern information retrieval and Retrieval-Augmented Generation (RAG). While dense models derived from Large Language Models (LLMs) dominate current practice, recent work has explored quantum-inspired alternatives motivated by the geometric properties of Hilbert-like spaces and their potential to encode richer semantic structure. This paper presents an experimental framework for constructing quantum-inspired 1024-dimensional document embeddings based on overlapping windows and multi-scale aggregation. The pipeline combines semantic projections (e.g., EigAngle), circuit-inspired feature mappings, and optional teacher-student distillation, together with a fingerprinting mechanism for reproducibility and controlled evaluation. We introduce a set of diagnostic tools for hybrid retrieval, including static and dynamic interpolation between BM25 and embedding-based scores, candidate union strategies, and a conceptual alpha-oracle that provides an upper bound for score-level fusion. Experiments on controlled corpora of Italian and English documents across technical, narrative, and legal domains, using synthetic queries, show that BM25 remains a strong baseline, teacher embeddings provide stable semantic structure, and standalone quantum-inspired embeddings exhibit weak and unstable ranking signals. Distillation yields mixed effects, improving alignment in some cases but not consistently enhancing retrieval performance, while hybrid retrieval can recover competitive results when lexical and embedding-based signals are combined. Overall, the results highlight structural limitations in the geometry of quantum-inspired embeddings, including distance compression and ranking instability, and clarify their role as auxiliary components rather than standalone retrieval representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an experimental framework for constructing 1024-dimensional quantum-inspired document embeddings via overlapping windows, multi-scale aggregation, EigAngle and circuit-inspired mappings, optional teacher-student distillation, and a fingerprinting mechanism. It defines diagnostic tools for hybrid retrieval (static/dynamic score interpolation, candidate union, and an alpha-oracle upper bound) and evaluates them on controlled Italian and English corpora spanning technical, narrative, and legal domains using synthetic queries. The central empirical claim is that BM25 remains strong, teacher embeddings are stable, standalone quantum-inspired embeddings exhibit weak/unstable ranking signals due to distance compression and geometric limitations, distillation effects are mixed, and hybrids recover competitive performance, positioning quantum-inspired embeddings as auxiliary rather than standalone representations.
Significance. If the experimental results hold under more realistic conditions, the work supplies concrete evidence of representational limits in quantum-inspired embeddings for IR, usefully tempering claims about Hilbert-space advantages and clarifying their auxiliary role in hybrid systems. The diagnostic tools (interpolation strategies and alpha-oracle) and reproducibility fingerprinting are positive contributions that could be adopted more broadly.
major comments (1)
- [Experiments] The central claim of structural geometric limitations (distance compression and ranking instability) rests on experiments using synthetic queries generated for the technical/narrative/legal corpora. No ablation replacing these with held-out real queries from the same domains is reported, leaving open the possibility that observed instability is an artifact of query construction rather than inherent to the EigAngle or circuit-inspired mappings (see Experiments section and results on ranking signals).
minor comments (2)
- [Diagnostic tools] Clarify the precise definition and computation of the alpha-oracle upper bound for score-level fusion, including any assumptions about score normalization.
- [Embedding construction] The abstract and methods should explicitly state the window sizes, aggregation scales, and any free parameters used in the 1024-D construction to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped clarify the scope and limitations of our experimental framework. We respond point-by-point to the major comment below.
read point-by-point responses
-
Referee: [Experiments] The central claim of structural geometric limitations (distance compression and ranking instability) rests on experiments using synthetic queries generated for the technical/narrative/legal corpora. No ablation replacing these with held-out real queries from the same domains is reported, leaving open the possibility that observed instability is an artifact of query construction rather than inherent to the EigAngle or circuit-inspired mappings (see Experiments section and results on ranking signals).
Authors: We appreciate the referee highlighting this aspect of our experimental design. The use of synthetic queries is a deliberate feature of the proposed controlled evaluation framework: it enables the generation of queries with verifiable, segment-level relevance derived directly from the source documents, which is necessary to isolate the geometric properties (distance compression, ranking instability) and to exercise the diagnostic tools such as static/dynamic interpolation and the alpha-oracle upper bound. Real queries would introduce uncontrolled variability and require additional human annotation not central to demonstrating representational limits. We nevertheless agree that the absence of a real-query ablation leaves a gap in generalizability. In the revised manuscript we have added an explicit discussion subsection (new Section 5.4) that states the rationale for synthetic queries, acknowledges the limitation, and outlines how the framework could be extended to held-out real queries in future work. We do not claim the current results apply to every real-world query distribution, but maintain that the observed instabilities arise from the embedding geometry itself rather than query construction. revision: partial
Circularity Check
No circularity: purely experimental evaluation with no self-referential derivations
full rationale
The paper describes an experimental pipeline for constructing and testing 1024-D quantum-inspired embeddings on controlled corpora using synthetic queries, reporting empirical outcomes such as BM25 baselines, hybrid fusion results, and observed distance compression. No equations, predictions, or uniqueness claims are presented that reduce by construction to fitted parameters, self-citations, or ansatzes imported from the authors' prior work. The central findings about representational limits are grounded in the reported test results rather than tautological definitions or load-bearing self-references, satisfying the default expectation for non-circular experimental work.
Axiom & Free-Parameter Ledger
free parameters (2)
- Embedding dimension
- Window sizes and aggregation scales
axioms (1)
- domain assumption Documents can be meaningfully projected into Hilbert-like spaces for semantic encoding
Reference graph
Works this paper leans on
-
[1]
Large Language Models: A Survey
S. Minaee, T. Mikolov, N. Nikzad, M. Chenaghlu, R. Socher, X. Amatriain, and J. Gao, “Large language models: A survey,” 2024. [Online]. Available: https://arxiv.org/abs/2402.06196
work page internal anchor Pith review arXiv 2024
-
[2]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, and H. Wang, “Retrieval-augmented generation for large language models: A survey,” 2024. [Online]. Available: https://arxiv.org/abs/2312.10997 40
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
A survey on rag meets llms: Towards retrieval- augmented large language models,
W. Fan, Y. Ding, L. Ning, S. Wang, H. Li, D. Yin, T.-S. Chua, and Q. Li, “A survey on rag meeting llms: Towards retrieval-augmented large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2405.06211
-
[4]
On the surprising behavior of distance metrics in high dimensional space,
C. C. Aggarwal, A. Hinneburg, and D. A. Keim, “On the surprising behavior of distance metrics in high dimensional space,” inProceed- ings of the 8th International Conference on Database Theory (ICDT). Springer, 2001, pp. 420–434
2001
-
[5]
The probabilistic relevance framework: Bm25 and beyond,
S. Robertson and H. Zaragoza, “The probabilistic relevance framework: Bm25 and beyond,”Foundations and Trends in Information Retrieval, vol. 3, no. 4, pp. 333–389, 2009
2009
-
[6]
Billion-scale similarity search with gpus,
J. Johnson, M. Douze, and H. J´ egou, “Billion-scale similarity search with gpus,”IEEE Transactions on Big Data, 2019
2019
-
[7]
Meaning-focused and quantum-inspired information retrieval,
D. Aerts, J. Broekaert, and M. Czachor, “Meaning-focused and quantum-inspired information retrieval,”International Journal of Gen- eral Systems, vol. 42, no. 4, pp. 356–385, 2013
2013
-
[8]
´A. F. Huertas-Rosero, L. Azzopardi, and K. van Rijsbergen, “Charac- terising through erasing: A theoretical framework for representing doc- uments inspired by quantum theory,”arXiv preprint arXiv:0802.1738, 2008
-
[9]
A survey of quantum theory in- spired approaches to information retrieval,
S. Uprety, D. Gkoumas, and D. Song, “A survey of quantum theory in- spired approaches to information retrieval,”ACM Computing Surveys, vol. 53, no. 5, pp. 98:1–98:39, 2020
2020
-
[10]
J. Singh and R. Thakur, “Quantum-rag and pungpt2: Advancing low-resource language generation and retrieval for the punjabi language,”arXiv preprint arXiv:2508.01918, 2025. [Online]. Available: https://arxiv.org/abs/2508.01918
-
[11]
Quantum-inspired complex word embedding,
Q. Li, “Quantum-inspired complex word embedding,” inProceedings of the 2018 ACL Workshop on Representation Learning for NLP, 2018, pp. 50–57
2018
-
[12]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of NAACL-HLT, 2019, pp. 4171–4186. 41
2019
-
[13]
Overview of the trec 2019 deep learning track,
N. Craswell, B. Mitra, E. Yilmaz, D. Campos, and E. M. Voorhees, “Overview of the trec 2019 deep learning track,” inProceedings of the Twenty-Eighth Text REtrieval Conference (TREC 2019). NIST, 2020
2019
-
[14]
Quantum-inspired embeddings projec- tion and similarity metrics for representation learning,
I. Kankeu, S. G. Fritsch, G. Sch¨ onhoff, E. Mounzer, P. Lukowicz, and M. Kiefer-Emmanouilidis, “Quantum-inspired embeddings projec- tion and similarity metrics for representation learning,”arXiv preprint arXiv:2501.04591, 2025
-
[15]
Quantum embeddings for machine learning,
S. Lloyd, M. Schuld, A. Ijaz, J. Izaac, and N. Killoran, “Quantum embeddings for machine learning,” 2020, foundational work on quantum metric learning: trains the encoding circuit to maximize class separation in Hilbert space
2020
-
[16]
Quantum-inspired semantic matching based on neural networks with the duality of density ma- trices,
C. Zhang, Q. Li, D. Song, and P. Tiwari, “Quantum-inspired semantic matching based on neural networks with the duality of density ma- trices,”Engineering Applications of Artificial Intelligence, vol. 140, p. 109667, 2025
2025
-
[17]
Qsim: A quantum-inspired hierarchical semantic interaction model for text classification,
H. Gao, P. Zhang, J. Zhang, and C. Yang, “Qsim: A quantum-inspired hierarchical semantic interaction model for text classification,”Neuro- computing, vol. 611, p. 128658, 2025
2025
-
[18]
Quantum fusion module for open-domain question answering,
R. Duan, K. Zhang, W. Xu, and X. Li, “Quantum fusion module for open-domain question answering,”Electronics, vol. 13, no. 20, p. 4135, 2024
2024
-
[19]
Reciprocal rank fu- sion outperforms condorcet and individual rank learning methods,
G. V. Cormack, C. L. Clarke, and S. Buettcher, “Reciprocal rank fu- sion outperforms condorcet and individual rank learning methods,” in Proceedings of the 32nd ACM SIGIR Conference, 2009, pp. 758–759
2009
-
[20]
Exploiting quantum-like interference in de- cision fusion for ranking multimodal documents,
D. Gkoumas and D. Song, “Exploiting quantum-like interference in de- cision fusion for ranking multimodal documents,” inProceedings of the 2018 ACM SIGIR International Conference on Theory of Information Retrieval (ICTIR), 2018, pp. 27–34
2018
-
[21]
Sentence-bert: Sentence embeddings us- ing siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings us- ing siamese bert-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019, pp. 3980–3990
2019
-
[22]
Autoencoding improves pre-trained word embeddings,
M. Kaneko and D. Bollegala, “Autoencoding improves pre-trained word embeddings,” inProceedings of the 28th International Conference on Computational Linguistics (COLING), 2020, pp. 1699–1713. 42
2020
-
[23]
Compressing sentence representa- tion for semantic retrieval via homomorphic projective distillation,
X. Zhao, Z. Yu, M. Wu, and L. Li, “Compressing sentence representa- tion for semantic retrieval via homomorphic projective distillation,” in Findings of the Association for Computational Linguistics: ACL 2022. Association for Computational Linguistics, 2022, pp. 774–781
2022
-
[24]
Neural quantum embedding: Pushing the limits of quantum supervised learning,
Y. Shiet al., “Neural quantum embedding: Pushing the limits of quantum supervised learning,” 2023, uses a classical teacher model to guide quantum circuit optimization (knowledge distillation classical- ¿quantum); improves robustness and accuracy on IBM quantum de- vices
2023
-
[25]
Multilingual E5 Text Embeddings: A Technical Report
L. Wang, N. Yang, X. Huang, L. Yang, R. Majumder, and F. Wei, “Multilingual e5 text embeddings: A technical report,”arXiv preprint arXiv:2402.05672, 2024
work page internal anchor Pith review arXiv 2024
-
[26]
Schuld and F
M. Schuld and F. Petruccione,Machine Learning with Quantum Com- puters. Springer, 2021
2021
-
[27]
I. T. Jolliffe,Principal Component Analysis, 2nd ed., ser. Springer Se- ries in Statistics. Springer, 2002
2002
-
[28]
Indexing by latent semantic analysis,
S. Deerwester, S. T. Dumais, G. W. Furnas, T. K. Landauer, and R. Harshman, “Indexing by latent semantic analysis,”Journal of the American Society for Information Science, vol. 41, no. 6, pp. 391–407, 1990
1990
-
[29]
Supervised learning with quantum- enhanced feature spaces,
V. Havliˇ cek, A. D. C´ orcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, “Supervised learning with quantum- enhanced feature spaces,”Nature, vol. 567, no. 7747, pp. 209–212, 2019
2019
-
[30]
Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets,
A. Kandala, A. Mezzacapo, K. Temme, M. Takita, M. Brink, J. M. Chow, and J. M. Gambetta, “Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets,”Nature, vol. 549, no. 7671, pp. 242–246, 2017
2017
-
[31]
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Nation, L. S. Bishop, A. W. Cross, B. R. Johnson, and J. M. Gambetta, “Quantum computing with qiskit,” arXiv preprint arXiv:2405.08810, 2024
work page internal anchor Pith review arXiv 2024
-
[32]
Quantum kitchen sinks: An algorithm for machine learning on near-term quantum computers,
C. M. Wilson, J. S. Otterbach, N. Tezak, R. S. Smith, A. M. Polloreno, P. J. Karalekas, S. Heidel, M. S. Alam, G. E. Crooks, and M. P. da Silva, “Quantum kitchen sinks: An algorithm for machine learning on near- term quantum computers,”arXiv preprint arXiv:1806.08321, 2018. 43
-
[33]
Quan- tum recurrent architectures for text classification,
W. Xu, S. Clark, D. Brown, G. Matos, and K. Meichanetzidis, “Quan- tum recurrent architectures for text classification,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Pro- cessing (EMNLP). Association for Computational Linguistics, 2024, pp. 18 020–18 027
2024
-
[34]
Barren plateaus in quantum neural network training landscapes,
J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Babbush, and H. Neven, “Barren plateaus in quantum neural network training landscapes,”Na- ture Communications, vol. 9, no. 1, p. 4812, 2018
2018
- [35]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.