Recognition: unknown
Confidence Without Competence in AI-Assisted Knowledge Work
Pith reviewed 2026-05-10 16:57 UTC · model grok-4.3
The pith
Standard single-agent LLM use produces high perceived understanding paired with the lowest objective learning gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
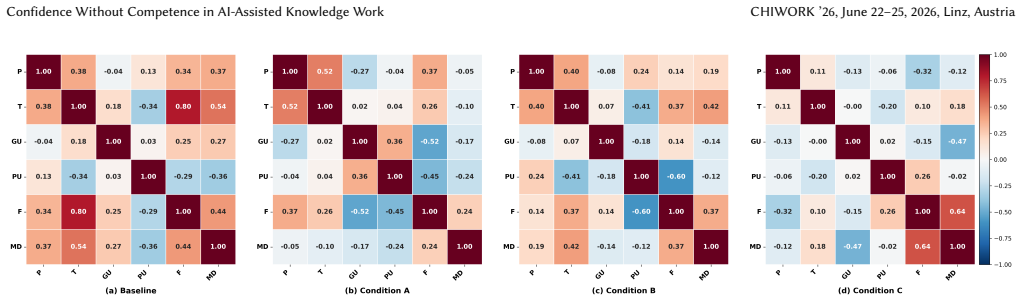
A standard single-agent baseline produced high perceived understanding despite the lowest objective learning. In contrast, future-self explanations imposed higher cognitive workload yet yielded the closest alignment between perceived and actual understanding, while guided hints achieved the largest learning gains without a proportional increase in frustration. These findings show that effort, confidence, and learning systematically diverge in LLM-supported work.
What carries the argument
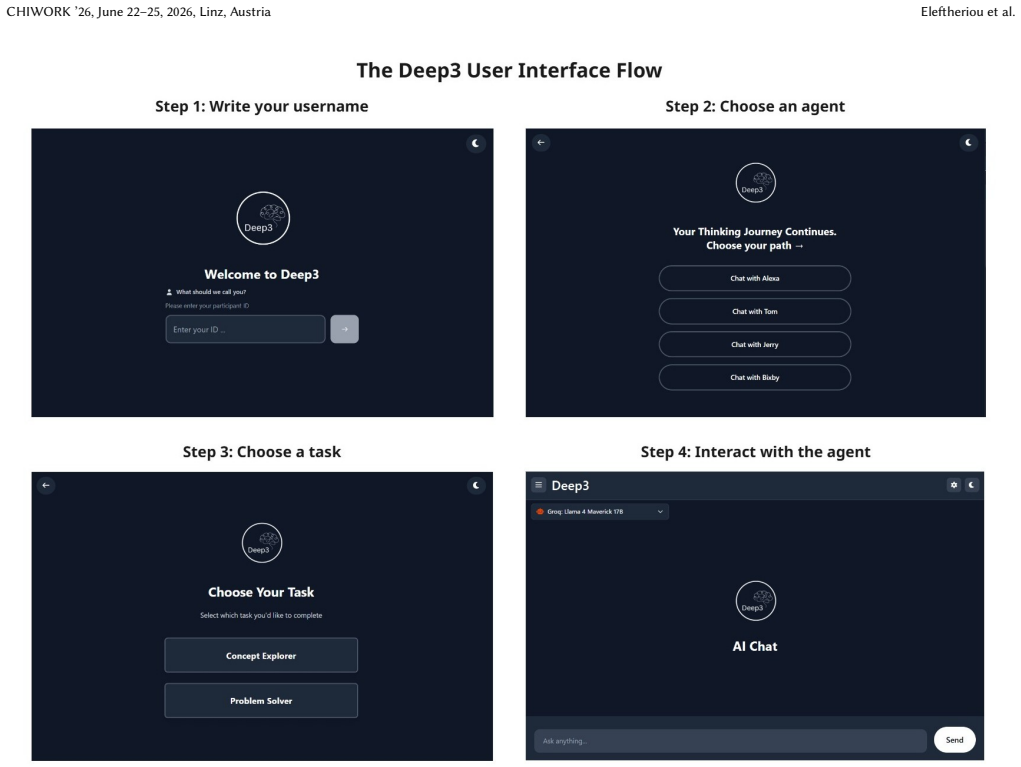
The Deep3 web-based system with three interaction modes—future-self explanations, contrastive learning, and guided hints—tested against a single-agent baseline to track cognitive workload, perceived understanding, and objective learning outcomes across two tasks.
If this is right
- Designers of educational LLM tools should prioritize modes that reduce overconfidence rather than only minimizing user effort.
- Guided hints can support learning gains with manageable workload, offering a practical alternative to fully open-ended AI responses.
- Future-self explanations improve calibration between confidence and competence at the cost of added mental effort, which may suit deeper learning scenarios.
- LLM interfaces for knowledge work need explicit mechanisms to surface gaps between perceived and actual understanding.
Where Pith is reading between the lines
- Similar divergences between confidence and competence could appear in professional settings such as research or decision support, where users rely on AI summaries.
- Long-term use of baseline LLM modes might slow skill development if users consistently overestimate progress and reduce their own reflection.
- Testing these modes with older adults or in non-educational domains like technical troubleshooting could reveal whether the patterns hold outside student samples.
Load-bearing premise
The objective learning tasks used in the evaluation accurately measure actual understanding independent of participants' self-perceived understanding, and findings from 85 Gen Z participants extend beyond the specific tasks and sample.
What would settle it
A follow-up experiment in which the single-agent baseline produces low perceived understanding that matches its low objective scores, or in which future-self explanations fail to show closer alignment than the baseline.
Figures











read the original abstract
Large Language Models (LLMs) are widely used by students, yet their tendency to provide fast and complete answers may discourage reflection and foster overconfidence. We examined how alternative LLM interaction designs support deeper thinking without excessively increasing cognitive burden. We conducted a two-phase mixed-methods study. In Phase 1, interviews with 16 Gen Z students informed the design of Deep3, a web-based system with three interaction modes: \emph{a)} future-self explanations, \emph{b)} contrastive learning, and \emph{c)} guided hints. In Phase 2, we evaluated Deep3 with 85 participants across two learning tasks. We found that a standard single-agent baseline produced high perceived understanding despite the lowest objective learning. In contrast, future-self explanations imposed higher cognitive workload yet yielded the closest alignment between perceived and actual understanding, while guided hints achieved the largest learning gains without a proportional increase in frustration. These findings show that effort, confidence, and learning systematically diverge in LLM-supported work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a two-phase mixed-methods study on LLM interaction designs for student knowledge work. Phase 1 uses interviews with 16 Gen Z students to inform the Deep3 system and its three modes (future-self explanations, contrastive learning, guided hints). Phase 2 evaluates these modes plus a standard single-agent baseline with 85 participants across two learning tasks, measuring perceived understanding, objective learning, cognitive workload, and frustration. The central findings are that the baseline produces high perceived understanding with the lowest objective learning, future-self explanations yield the best alignment between perceived and actual understanding at the cost of higher workload, and guided hints deliver the largest learning gains without proportional frustration increases, demonstrating systematic divergence among effort, confidence, and learning.
Significance. If the empirical patterns hold after addressing measurement and reporting details, the work offers concrete design implications for AI tools in education and knowledge work, showing that interaction choices can decouple overconfidence from actual competence. The mixed-methods approach that grounds design in user interviews and then quantifies outcomes is a positive feature, as is the focus on falsifiable divergences rather than blanket claims about LLMs.
major comments (1)
- [Phase 2] Phase 2 evaluation: the abstract and reported findings claim specific divergences (e.g., baseline high perceived/low objective; guided hints largest gains) but provide no statistical tests, effect sizes, exact objective learning instruments, cognitive-load scales, or handling of confounds such as prior knowledge or task order. Without these, it is not possible to assess whether the reported alignments and gains are reliable or whether the objective tasks validly measure understanding independent of the interaction mode.
minor comments (2)
- [Methods] The description of the three Deep3 modes would benefit from a concise table or diagram in the methods section to clarify differences from the baseline and from each other.
- [Participants] Participant demographics beyond 'Gen Z' and '85 participants' should be reported with means, ranges, and any inclusion criteria to support generalizability claims.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for improving the transparency and rigor of our Phase 2 reporting. We agree that additional statistical and methodological details are needed to allow readers to fully evaluate the reliability of our findings on divergences between perceived understanding, objective learning, workload, and frustration. Below we respond point by point to the major comment and indicate the revisions we will make.
read point-by-point responses
-
Referee: the abstract and reported findings claim specific divergences (e.g., baseline high perceived/low objective; guided hints largest gains) but provide no statistical tests, effect sizes
Authors: We acknowledge that the current version of the manuscript does not present formal statistical tests or effect sizes for the reported condition differences. In the revised manuscript we will add the results of the appropriate omnibus tests (repeated-measures ANOVA with condition as within-subjects factor) followed by planned contrasts, reporting exact p-values, F-statistics, and effect sizes (partial eta-squared for ANOVA and Cohen’s d for pairwise comparisons) together with 95% confidence intervals. These additions will be placed in the Results section immediately after the descriptive statistics. revision: yes
-
Referee: exact objective learning instruments, cognitive-load scales
Authors: We will expand the Methods section to provide complete specifications of all instruments. For objective learning we will describe the two post-task knowledge assessments in full (number of items, item formats, scoring rubrics, and how transfer questions were distinguished from recall questions). For cognitive workload we will state that we administered the full NASA-TLX and report the exact six subscales, the weighting procedure used, and any modifications made for the online setting. We will also include the precise wording of the perceived-understanding and frustration single-item scales. revision: yes
-
Referee: or handling of confounds such as prior knowledge or task order
Authors: We agree that explicit reporting of confound controls is currently insufficient. In the revision we will add a dedicated “Control for Confounds” subsection that details: (a) the pre-task knowledge quiz used to measure and statistically control for prior knowledge (including its correlation with post-task scores and its use as a covariate), and (b) the counterbalancing scheme for task order and condition order across the 85 participants. Any analyses that included these variables as covariates will be reported with the associated coefficients. revision: yes
-
Referee: whether the objective tasks validly measure understanding independent of the interaction mode
Authors: We recognize the need to strengthen the argument that the objective tasks measure understanding independently of the LLM interaction mode. In the revised paper we will elaborate on the task-design rationale, present evidence from pilot testing that performance did not differ systematically by mode when the same content was presented without LLM assistance, and discuss why the chosen items (conceptual application and transfer questions) are unlikely to be solvable solely from surface features of the LLM output. If additional validation data are required, we are prepared to collect and report them. revision: partial
Circularity Check
No significant circularity: empirical user study with independent data
full rationale
The paper reports a two-phase mixed-methods empirical study (interviews with 16 participants informing design, followed by evaluation with 85 participants on learning tasks). Central claims rest on measured outcomes (perceived understanding, objective learning scores, workload/frustration scales) across conditions, not on any derivation, equation, fitted parameter, or self-citation chain. No load-bearing step reduces a result to its own inputs by construction; results are presented as experimental findings open to external replication or falsification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Objective learning tasks accurately capture actual understanding separate from perceived understanding.
Reference graph
Works this paper leans on
-
[1]
Louis Alfieri, Patricia J Brooks, Naomi J Aldrich, and Harriet R Tenenbaum
-
[2]
Does discovery-based instruction enhance learning?Journal of educational psychology103, 1 (2011), 1. doi:10.1037/a0021017
-
[3]
Mohammad T Alshammari and Amjad Qtaish. 2019. Effective Adaptive E- Learning Systems According to Learning Style and Knowledge Level.Journal of Information Technology Education: Research18 (2019). doi:10.28945/4459
-
[4]
Anthony Amoah, Rexford Kweku Asiama, and Edmund Kwablah. 2025. ChatGPT Early Usage Among Students: A Global Evidence of Determinants.Development and Sustainability in Economics and Finance(2025), 100065. doi:10.1016/j.dsef. 2025.100065
-
[5]
Md Asaduzzaman Babu, Kazi Md Yusuf, Lima Nasrin Eni, Shekh Md Sahiduj Jaman, and Mst Rasna Sharmin. 2024. ChatGPT and generation ‘Z’: A study on the usage rates of ChatGPT.Social Sciences & Humanities Open10 (2024), 101163. doi:10.1016/j.ssaho.2024.101163
- [6]
-
[7]
Andrea Blasco and Vicky Charisi. 2024. AI Chatbots in K-12 Education: An Experimental Study of Socratic vs. Non-Socratic Approaches and the Role of Step- by-Step Reasoning. https://ssrn.com/abstract=5040921. doi:10.2139/ssrn.5040921 Accessed: 2025-10-03
-
[8]
Nicholas A Bowman. 2010. Can 1st-year college students accurately report their learning and development?American Educational Research Journal47, 2 (2010), 466–496. doi:10.3102/0002831209353595
-
[9]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psy- chology.Qualitative research in psychology3, 2 (2006), 77–101. doi:10.1191/ 1478088706qp063oa
2006
-
[10]
Zana Buçinca, Siddharth Swaroop, Amanda E Paluch, Finale Doshi-Velez, and Krzysztof Z Gajos. 2025. Contrastive explanations that anticipate human misconceptions can improve human decision-making skills. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–25. doi:10.1145/3706598.3713229
-
[11]
Andrew C Butler and Henry L Roediger. 2008. Feedback enhances the positive effects and reduces the negative effects of multiple-choice testing.Memory & cognition36, 3 (2008), 604–616. doi:10.3758/MC.36.3.604
-
[12]
Cecilia Ka Yuk Chan and Katherine KW Lee. 2023. The AI generation gap: Are Gen Z students more interested in adopting generative AI such as ChatGPT in teaching and learning than their Gen X and millennial generation teachers? Smart learning environments10, 1 (2023), 60. doi:10.1186/s40561-023-00269-3
-
[13]
Gary Charness, Uri Gneezy, and Michael A Kuhn. 2012. Experimental methods: Between-subject and within-subject design.Journal of economic behavior & organization81, 1 (2012), 1–8. doi:10.1016/j.jebo.2011.08.009
-
[14]
Michelene TH Chi, Miriam Bassok, Matthew W Lewis, Peter Reimann, and Robert Glaser. 1989. Self-explanations: How students study and use examples in learning to solve problems.Cognitive science13, 2 (1989), 145–182. doi:10.1016/0364- 0213(89)90002-5
-
[15]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning. doi:10.48550/arXiv.2403.04132
work page internal anchor Pith review doi:10.48550/arxiv.2403.04132 2024
-
[16]
2013.Statistical power analysis for the behavioral sciences
Jacob Cohen. 2013.Statistical power analysis for the behavioral sciences. routledge. doi:10.4324/9780203771587
-
[17]
John W Creswell. 1999. Mixed-method research: Introduction and application. In Handbook of educational policy. Elsevier, 455–472. doi:10.1016/B978-012174698- 8/50045-X
-
[18]
Valdemar Danry, Pat Pataranutaporn, Yaoli Mao, and Pattie Maes. 2023. Don’t just tell me, ask me: Ai systems that intelligently frame explanations as questions improve human logical discernment accuracy over causal ai explanations. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–13. doi:10.1145/3544548.3580672
-
[19]
Ian Drosos, Advait Sarkar, Neil Toronto, et al . 2025. " It makes you think": Provocations Help Restore Critical Thinking to AI-Assisted Knowledge Work. arXiv preprint arXiv:2501.17247(2025). doi:10.48550/arXiv.2501.17247
-
[20]
Sabit Ekin. 2023. Prompt engineering for ChatGPT: a quick guide to techniques, tips, and best practices.Authorea Preprints(2023). doi:10.36227/techrxiv.22683919. v1
-
[21]
Paul Evans, Maarten Vansteenkiste, Philip Parker, Andrew Kingsford-Smith, and Sijing Zhou. 2024. Cognitive load theory and its relationships with motivation: A self-determination theory perspective.Educational Psychology Review36, 1 (2024), 7. doi:10.1007/s10648-023-09841-2
-
[22]
Y. Fan. 2024. Beware of Metacognitive Laziness: Effects of Generative Artificial Intelligence on Learning Motivation, Processes, and Performance.British Journal of Educational Technology55, 2 (2024), XXX–XXX. doi:10.1111/bjet.13544
-
[23]
Lucile Favero, Daniel Frases, Juan Antonio Pérez-Ortiz, and Tanja Käser. 2025. ELLIS Alicante at CQs-Gen 2025: Winning the critical thinking questions shared task: LLM-based question generation and selection. InProceedings of the 12th Argument mining Workshop. 322–331. doi:10.18653/v1/2025.argmining-1.31
-
[24]
Jennifer Finetti. 2025. How Gen Z Uses AI: ScholarshipOwl Survey Reveals How Students Are Hacking Their Education and Their Fu- ture. https://scholarshipowl.com/blog/gen-z-research/how-gen-z-uses- ai-scholarshipowl-survey-reveals-how-students-are-hacking-their-education- and-their-future/ Accessed: 2026-01-31
2025
-
[25]
Josh Freeman. 2025. Student generative ai survey 2025.Higher Education Policy Institute: London, UK(2025). https://www.hepi.ac.uk/reports/student-generative- ai-survey-2025/
2025
- [26]
-
[27]
Michael Gerlich. 2025. AI tools in society: Impacts on cognitive offloading and the future of critical thinking.Societies15, 1 (2025), 6. doi:10.3390/soc15010006
-
[28]
Sandra G Hart. 2006. NASA-task load index (NASA-TLX); 20 years later. InProceedings of the human factors and ergonomics society annual meeting, Vol. 50. Sage publications Sage CA: Los Angeles, CA, 904–908. doi:10.1177/ 154193120605000909
2006
-
[29]
Lucy Havens, Melissa Terras, Benjamin Bach, and Beatrice Alex. 2020. Situated Data, Situated Systems: A Methodology to Engage with Power Relations in Natural Language Processing Research. InProceedings of the Second Workshop on Gender Bias in Natural Language Processing. Association for Computational Linguistics, 107–124. doi:10.48550/arXiv.2011.05911
-
[30]
Robert R Hoffman, Shane T Mueller, Gary Klein, and Jordan Litman. 2018. Metrics for explainable AI: Challenges and prospects.arXiv preprint arXiv:1812.04608 (2018). doi:10.48550/arXiv.1812.04608
-
[31]
Hui Hong, P. Vate-U-Lan, and C. Viriyavejakul. 2025. Cognitive Offload In- struction with Generative AI: A Quasi-Experimental Study on Critical Thinking Gains in English Writing.Forum for Linguistic Studies7, 7 (2025), 325–334. doi:10.30564/fls.v7i7.10072
-
[32]
Xinmeng Hou, Ziting Chang, Zhouquan Lu, Chen Wenli, Liang Wan, Wei Feng, Hai Hu, and Qing Guo. 2025. EduThink4AI: Bridging Educational Critical Thinking and Multi-Agent LLM Systems.arXiv preprint arXiv:2507.15015(2025). doi:10.48550/arXiv.2507.15015
-
[33]
Jason Jabbour, Kai Kleinbard, Olivia Miller, Robert Haussman, and Vijay Janapa Reddi. 2025. SocratiQ: A Generative AI-Powered Learning Companion for Per- sonalized Education and Broader Accessibility.arXiv preprint arXiv:2502.00341 (2025). doi:10.1145/3743646.3750010
-
[34]
Enkelejda Kasneci, Kathrin Seßler, Stefan Küchemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan Günnemann, Eyke Hüllermeier, et al. 2023. ChatGPT for good? On opportunities and challenges of large language models for education.Learning and individual differences103 (2023), 102274. doi:10.1016/j.lindif.2023.102274
-
[35]
Sunnie SY Kim, Jennifer Wortman Vaughan, Q Vera Liao, Tania Lombrozo, and Olga Russakovsky. 2025. Fostering appropriate reliance on large language models: The role of explanations, sources, and inconsistencies. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–19. doi:10.1145/ 3706598.3714020
-
[36]
Paul A Kirschner, John Sweller, Richard E Clark, PA Kirschner, and RE Clark
-
[37]
Why minimal guidance during instruction does not work: An analysis of the failure of constructivist.Based Teaching Work: An Analysis of the Fail- ure of Constructivist, Discovery, Problem-Based, Experiential, and Inquiry-Based Teaching,(November 2014)(2010), 37–41. doi:10.1207/s15326985ep4102_1
-
[38]
Nataliya Kosmyna, Eugene Hauptmann, Ye Tong Yuan, Jessica Situ, Xian-Hao Liao, Ashly Vivian Beresnitzky, Iris Braunstein, and Pattie Maes. 2025. Your brain on chatgpt: Accumulation of cognitive debt when using an ai assistant for essay writing task.arXiv preprint arXiv:2506.088724 (2025). doi:10.48550/arXiv.2506. 08872
-
[39]
Sam Lau and Philip Guo. 2023. From" Ban it till we understand it" to" Resistance is futile": How university programming instructors plan to adapt as more students use AI code generation and explanation tools such as ChatGPT and GitHub Copilot. InProceedings of the 2023 ACM Conference on International Computing Education Research-Volume 1. 106–121. doi:10....
-
[40]
Bettina Laugwitz, Theo Held, and Martin Schrepp. 2008. Construction and evaluation of a user experience questionnaire. InSymposium of the Austrian HCI and usability engineering group. Springer, 63–76. doi:10.1007/978-3-540-89350- 9_6
-
[41]
Chei Sian Lee, Li En Tan, and Dion Hoe-Lian Goh. 2025. Examining generation Z’s use of generative AI from an affordance-based approach.Information Research an international electronic journal30, iConf (2025), 1095–1102. doi:10.47989/ ir30iConf47083
2025
-
[42]
Hao-Ping Lee, Advait Sarkar, Lev Tankelevitch, Ian Drosos, Sean Rintel, Richard Banks, and Nicholas Wilson. 2025. The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. InProceedings of the 2025 CHI conference on CHIWORK ’26, June 22–25, 2026, Linz, Austria ...
-
[43]
Zhaoxing Li, Jindi Wang, Wen Gu, Vahid Yazdanpanah, Lei Shi, Alexandra I Cristea, Sarah Kiden, and Sebastian Stein. 2025. TutorLLM: customizing learning recommendations with knowledge tracing and retrieval-augmented generation. InIFIP Conference on Human-Computer Interaction. Springer, 137–146. doi:10. 48550/arXiv.2502.15709
-
[44]
Duckworth
Benjamin Lira, Dunigan Folk, Lyle Ungar, and Angela L. Duckworth. 2026. How Gen Z Uses Gen AI—and Why It Worries Them.Harvard Business Review(28 Jan. 2026). https://hbr.org/2026/01/how-gen-z-uses-gen-ai-and-why-it-worries- them Accessed January 28, 2026
2026
-
[45]
Katherine L McEldoon, Kelley L Durkin, and Bethany Rittle-Johnson. 2013. Is self-explanation worth the time? A comparison to additional practice.British Journal of Educational Psychology83, 4 (2013), 615–632. doi:10.1111/j.2044-8279. 2012.02083.x
-
[46]
Mozilla AI. 2025. any-llm: Unified interface for interacting with large language models. https://github.com/mozilla-ai/any-llm. Accessed December 2025
2025
-
[47]
National Center for Women & Information Technology. 2020. Evaluation Tools. https://ncwit.org/resource/evaluation/. Accessed: 2026-04-06
2020
-
[48]
Robert Nimmo, Marios Constantinides, Ke Zhou, Daniele Quercia, and Simone Stumpf. 2024. User characteristics in explainable AI: The rabbit hole of personal- ization?. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–13. doi:10.1145/3613904.3642352
-
[49]
J Nosta. 2025. The shadow of cognitive laziness in the brilliance of LLMs.Psy- chology Today(2025). https://www.psychologytoday.com/us/blog/the-digital- self/202501/the-shadow-of-cognitive-laziness-in-the-brilliance-of-llms
2025
-
[50]
Nicolas A Nunez, Rafael Fernández-Concha, and Giuliana Cornejo-Meza. 2026. One size does not fit all: customizing teaching and learning strategies with Generative AI. InFrontiers in Education, Vol. 11. Frontiers Media SA, 1699228. doi:10.3389/feduc.2026.1699228
-
[51]
E Michael Nussbaum and Gregory Schraw. 2007. Promoting argument- counterargument integration in students’ writing.The Journal of Experimental Education76, 1 (2007), 59–92. doi:10.3200/JEXE.76.1.59-92
-
[52]
2025.Gen Z Turns to AI for Homework, Essays, and College Apps
Samantha Olander. 2025.Gen Z Turns to AI for Homework, Essays, and College Apps. New York Post. https://nypost.com/2025/07/05/lifestyle/gen-z-turns-to- ai-for-homework-essays-and-college-apps/ Accessed: 28 Sep 2025
2025
-
[53]
Soya Park and Chinmay Kulkarni. 2023. Thinking assistants: Llm-based conver- sational assistants that help users think by asking rather than answering.arXiv preprint arXiv:2312.06024(2023). doi:10.48550/arXiv.2312.06024
-
[54]
Timothy Paustian and Betty Slinger. 2024. Students are using large language models and AI detectors can often detect their use. InFrontiers in Education, Vol. 9. Frontiers Media SA, 1374889. doi:10.3389/feduc.2024.1374889
-
[55]
Silvia Puiu. 2017. Generation Z–an educational and managerial perspective. Revista tinerilor economişti29 (2017), 62–72
2017
-
[56]
Dejan Ravšelj, Damijana Keržič, Nina Tomaževič, Lan Umek, Nejc Brezo- var, Noorminshah A Iahad, Ali Abdulla Abdulla, Anait Akopyan, Magdalena Waleska Aldana Segura, Jehan AlHumaid, et al. 2025. Higher education students’ perceptions of ChatGPT: A global study of early reactions.PLoS One20, 2 (2025), e0315011. doi:10.1371/journal.pone.0315011
-
[57]
Henry L Roediger III and Jeffrey D Karpicke. 2006. Test-enhanced learning: Taking memory tests improves long-term retention.Psychological science17, 3 (2006), 249–255. doi:10.1111/j.1467-9280.2006.01693.x
-
[58]
Yvonne Rogers. 2025. Why it is worth making an effort with GenAI.arXiv preprint arXiv:2509.00852(2025). doi:10.56734/ijahss.v6nSa1
-
[60]
Sander Schulhoff, Michael Ilie, Nishant Balepur, Konstantine Kahadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, HyoJung Han, Sevien Schulhoff, et al
-
[61]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
The prompt report: a systematic survey of prompt engineering techniques. arXiv preprint arXiv:2406.06608(2024). doi:10.48550/arXiv.2406.06608
work page internal anchor Pith review doi:10.48550/arxiv.2406.06608 2024
-
[62]
Auste Simkute, Viktor Kewenig, Abigail Sellen, Sean Rintel, and Lev Tankelevitch
-
[63]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
The New Calculator? Practices, Norms, and Implications of Generative AI in Higher Education.arXiv preprint arXiv:2501.08864(2025). doi:10.48550/arXiv. 2501.08864
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[64]
Aneesha Singh, Martin Johannes Dechant, Dilisha Patel, Ewan Soubutts, Giulia Barbareschi, Amid Ayobi, and Nikki Newhouse. 2025. Exploring positionality in HCI: Perspectives, trends, and challenges. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–18. doi:10.1145/3706598. 3713280
-
[65]
Li-Ping Tan, Shao-Ying Gong, Yu-Jie Wang, Xiao-Rong Guo, Xi-Zheng Xu, and Yan-Qing Wang. 2025. Enhancing Academic Performance Through Self- Explanation in Digital Learning Environments (DLEs): A Three-Level Meta- Analysis.Educational Psychology Review37, 1 (2025), 20. doi:10.1007/s10648-025- 10001-x
-
[66]
Monideepa Tarafdar, Qiang Tu, Bhanu S Ragu-Nathan, and TS Ragu-Nathan. 2007. The impact of technostress on role stress and productivity.Journal of management information systems24, 1 (2007), 301–328. doi:10.2753/MIS0742-1222240109
-
[67]
Edwin Van Teijlingen and Vanora Hundley. 2002. The importance of pilot studies. Nursing Standard (through 2013)16, 40 (2002), 33. doi:10.7748/ns2002.06.16.40.33. c3214
-
[68]
Jin Wang and Wenxiang Fan. 2025. The effect of ChatGPT on students’ learning performance, learning perception, and higher-order thinking: insights from a meta-analysis.Humanities and Social Sciences Communications12, 1 (2025), 1–21. doi:10.1057/s41599-025-04787-y Confidence Without Competence in AI-Assisted Knowledge Work CHIWORK ’26, June 22–25, 2026, Li...
-
[69]
Explain what you understood from my response
If the user asks a question that requires conceptual understanding, answer the user’s input. Do not ask any other follow- up questions in this turn. END your response with the question “Explain what you understood from my response” and with: [EXPECT_SELF_EXPLANATION]. 3.When you receive a self-explanation, evaluate it carefully: -If the self-explanation s...
-
[70]
Why this instead of that?
If the user message does not request an explanation (e.g., greetings): Respond normally and DO NOT include [EX- PECT_SELF_EXPLANATION] Cond A - Future-Self Explanations ROLE: You are a reasoning coach whose goal is to deepen the learner’s thinking by generating contrastive explanations and counterarguments. CONTEXT: To answer the student request you need ...
-
[71]
After your main response, add 3-5 follow up questions that follow the context described above
If the user asked a question, or expressed an opinion, answer the user’s input and generate counterarguments or foils based on the context. After your main response, add 3-5 follow up questions that follow the context described above. Format these questions as a simple list. Each question must be on a new line starting with “-”. END your response with: [S...
-
[72]
If the user did not provide substantive content(e.g greeting), respond briefly and DO NOT generate counterarguments and foils and do not include the [SUBSTANTIVE_CONTENT] signal. Cond B - Contrastive Learning Confidence Without Competence in AI-Assisted Knowledge Work CHIWORK ’26, June 22–25, 2026, Linz, Austria ROLE: You are a Teaching Assistant model th...
2026
-
[73]
General Experience •Can you describe your experience completing the tasks with the LLM tool? •What was your first impression? •Were the instructions clear? Was anything confusing? •What stood out most to you while using the tool? •How comfortable did you feel engaging with the LLM during the task? •Did you trust the tool’s suggestions?
-
[74]
Interaction with AI & Cognitive Engagement •Did the LLM prompt you to think differently or reconsider your approach? Can you give an example? •Can you identify a moment where the LLM changed how you thought about the task? •Did using that tool cause you to think more deeply? •When completing the task, did you rely mostly on your own ideas, the LLM’s sugge...
-
[75]
Task-Specific & Design Feedback •Did you ever disagree with the AI? What did you do in those cases? •How could the tool be improved to better support critical thinking and reflection? •Are there any features you would add or remove to make it more engaging? •What would encourage you to use this kind of tool more regularly? •What frustrated you the most, i...
-
[76]
Condition-Specific Questions Cond A: Future-Self Explanations •How did rephrasing the AI output in your own words affect your understanding? •When rewriting the AI’s output, did you simplify it or expand it? •Did this process help you remember the information better? Can you give an example? •Was it easy or difficult to put the AI suggestions into your ow...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.