Investigating Vaccine Buyer's Remorse: Post-Vaccination Decision Regret in COVID-19 Social Media Using Politically Diverse Human Annotation
Pith reviewed 2026-05-15 08:25 UTC · model grok-4.3
The pith
Vaccine buyer's remorse appears in under 2% of COVID-19 discourse but clusters in skeptic communities via personal health stories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that vaccine buyer's remorse appears in only less than 2% of public discourse on COVID-19 vaccination. It is disproportionately concentrated in vaccine-skeptic influencer communities and is predominantly expressed through first-person narratives citing adverse health events. The study also measures differences between personal and vicarious experiences and checks for biases across different LLMs used for detection.
What carries the argument
A curated YouTube news corpus on COVID-19 vaccination paired with politically diverse human annotations that serve as ground truth for LLM-based identification of regret posts.
If this is right
- Public health messaging can prioritize the small share of cases tied to adverse events instead of assuming widespread regret.
- First-person stories of health issues should receive specific attention in communication to address the main form of expressed remorse.
- Quantifying vicarious versus direct regret shows how personal experiences may amplify online compared with shared accounts.
- Evaluating LLM detection biases on this topic highlights the need for calibration when monitoring politicized health discussions.
Where Pith is reading between the lines
- The annotated dataset could be cross-checked against official adverse event reporting systems to test whether self-reported health issues align with documented outcomes.
- The same curation and diverse-annotation approach could be applied to study decision regret around other interventions such as treatments or preventive measures.
- Concentration in particular online communities suggests that broad messaging may be less effective than community-specific outreach.
- Politically balanced annotation panels offer a practical way to reduce slant when analyzing sensitive or polarized social media topics.
Load-bearing premise
The curated YouTube corpus and LLM-based identification accurately reflect the true prevalence and nature of vaccine regret without major biases from platform selection or model limitations.
What would settle it
A large-scale representative survey of vaccinated individuals that directly asks about regret, its reasons, and personal versus observed experiences would confirm or contradict the social-media prevalence and concentration patterns.
Figures



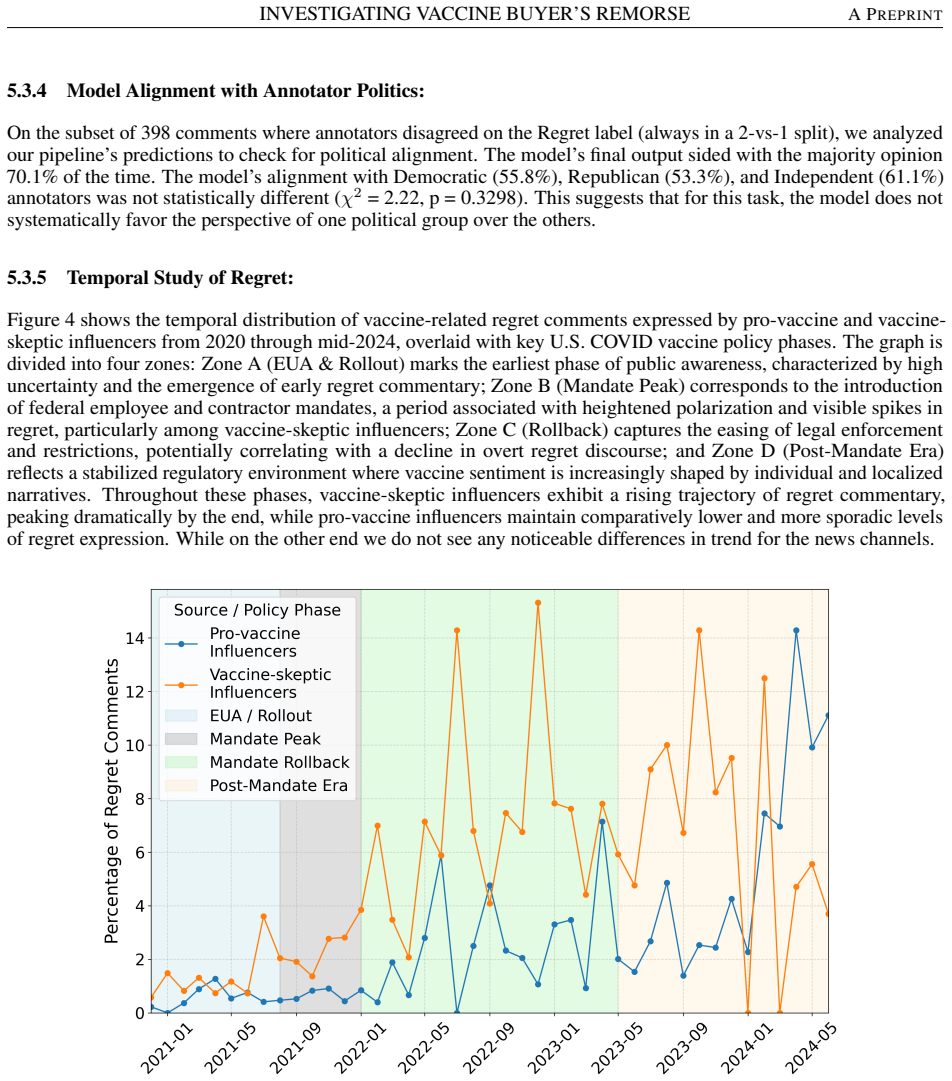






read the original abstract
A significant gap exists in datasets regarding post-COVID-19 vaccination experiences, particularly ``vaccine buyer's remorse''. Understanding the prevalence and nature of vaccine regret, whether based on personal or vicarious experiences, is vital for addressing vaccine hesitancy and refining public health communication. In this paper, we curate a novel dataset from a large YouTube news corpus capturing COVID-19 vaccination experiences, and construct a benchmark subset focused on vaccine regret, annotated by a politically diverse panel to account for the subjective and often politicized nature of the topic. We utilize large language models (LLMs) to identify posts expressing vaccine regret, analyze the reasons behind this regret, and quantify its occurrence in both first and second-person accounts. This paper aims to (1) quantify the prevalence of vaccine regret; (2) identify common reasons for this sentiment; (3) analyze differences between first-person and vicarious experiences; and (4) assess potential biases introduced by different LLMs. We find that while vaccine buyer's remorse appears in only $<2\%$ of public discourse, it is disproportionately concentrated in vaccine-skeptic influencer communities and is predominantly expressed through first-person narratives citing adverse health events.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper curates a novel YouTube news corpus on COVID-19 vaccination experiences, builds a politically diverse human-annotated benchmark subset for vaccine regret, and applies LLMs to detect regret expressions. It reports that vaccine buyer's remorse occurs in <2% of the discourse, is disproportionately concentrated in vaccine-skeptic influencer communities, and is mostly conveyed via first-person narratives citing adverse health events. The work also examines differences between first- and second-person accounts and potential LLM biases.
Significance. If the core methodological gaps are closed, the study supplies a useful annotated dataset and quantitative evidence on the low overall prevalence yet community-specific concentration of vaccine regret. The politically diverse annotation panel is a clear strength for a politicized topic. The findings could help calibrate public-health messaging, provided the prevalence and concentration claims rest on validated detection.
major comments (3)
- [Methods (LLM-based identification and benchmark construction)] The manuscript states that a human-annotated benchmark subset was created but reports neither precision, recall, F1, nor a confusion matrix for the LLM regret classifier on that subset. Because the headline <2% prevalence figure is produced by this classifier, the absence of these metrics makes the absolute prevalence and the 'disproportionate concentration' claims impossible to evaluate.
- [Corpus curation and data collection] No sampling frame, channel-selection criteria, or coverage statistics are supplied for the curated YouTube corpus. Without these, it is impossible to determine whether the corpus over-samples high-engagement skeptic channels, which would directly affect both the <2% prevalence estimate and the claim of disproportionate concentration.
- [Results (prevalence quantification)] The <2% prevalence result is presented without stating the exact regret-detection threshold, prompt template, or exclusion rules applied to the LLM output. Sensitivity of the headline figure to these choices is therefore unknown.
minor comments (1)
- [Abstract] The abstract mentions 'politically diverse human annotation' but does not report inter-annotator agreement statistics (e.g., Fleiss' kappa or pairwise agreement).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that greater methodological transparency is required and will revise the manuscript to address the concerns about LLM evaluation metrics, corpus documentation, and detection parameters. These changes will strengthen the interpretability of the prevalence and concentration findings without altering the core claims.
read point-by-point responses
-
Referee: The manuscript states that a human-annotated benchmark subset was created but reports neither precision, recall, F1, nor a confusion matrix for the LLM regret classifier on that subset. Because the headline <2% prevalence figure is produced by this classifier, the absence of these metrics makes the absolute prevalence and the 'disproportionate concentration' claims impossible to evaluate.
Authors: We agree that performance metrics are essential for validating the classifier. In the revised manuscript we will report precision, recall, F1-score, and a confusion matrix for the LLM regret detector on the human-annotated benchmark subset. This will allow direct assessment of the reliability of the <2% prevalence estimate and the concentration claims. revision: yes
-
Referee: No sampling frame, channel-selection criteria, or coverage statistics are supplied for the curated YouTube corpus. Without these, it is impossible to determine whether the corpus over-samples high-engagement skeptic channels, which would directly affect both the <2% prevalence estimate and the claim of disproportionate concentration.
Authors: We acknowledge the omission. The revised methods section will specify the sampling frame, explicit channel-selection criteria (including subscriber thresholds, content focus, and efforts to achieve political diversity), and available coverage statistics. We will also discuss potential selection effects and how they were mitigated. revision: yes
-
Referee: The <2% prevalence result is presented without stating the exact regret-detection threshold, prompt template, or exclusion rules applied to the LLM output. Sensitivity of the headline figure to these choices is therefore unknown.
Authors: We will add the exact prompt templates, classification threshold, and exclusion rules to the methods. We will also include a sensitivity analysis showing how the prevalence estimate varies with reasonable changes to these parameters, confirming robustness of the <2% figure. revision: yes
Circularity Check
No circularity: purely empirical data-driven analysis with no derivations or fitted inputs
full rationale
The paper is a self-contained empirical study that curates a YouTube corpus, obtains human annotations from a politically diverse panel on a benchmark subset, and applies LLMs to classify vaccine regret. No equations, parameters, or predictions are derived; prevalence (<2%), concentration in skeptic communities, and first-person narrative patterns are computed directly from the annotated outputs. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear. The derivation chain consists only of explicit data collection and classification steps that do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Regret detection threshold
axioms (2)
- domain assumption YouTube comments represent a valid sample of public discourse on vaccination.
- domain assumption Politically diverse annotation mitigates bias in subjective labeling.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We find that while vaccine buyer's remorse appears in only <2% of public discourse, it is disproportionately concentrated in vaccine-skeptic influencer communities and is predominantly expressed through first-person narratives citing adverse health events.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We utilize large language models (LLMs) to identify posts expressing vaccine regret...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
M.-M. Becerra-Perez, M. Menear, S. Turcotte, M. Labrecque, and F. Légaré. More primary care patients regret health decisions if they experienced decisional conflict in the consultation: a secondary analysis of a multicenter descriptive study.BMC Family Practice, 17(1):156, 2016
work page 2016
-
[3]
J. C. Brehaut, A. M. O’Connor, T. J. Wood, T. F. Hack, L. Siminoff, E. Gordon, and D. Feldman-Stewart. Validation of a decision regret scale.Medical decision making, 23(4):281–292, 2003. 10 INVESTIGATING V ACCINE BUYER’S REMORSEA PREPRINT
work page 2003
- [4]
-
[5]
E. K. Brunson. The impact of social networks on parents’ vaccination decisions.Pediatrics, 131(5):e1397–e1404, 2013
work page 2013
-
[6]
K. S. Clemens, K. Faasse, W. Tan, B. Colagiuri, L. Colloca, R. Webster, L. Vase, E. Jason, and A. L. Geers. Social communication pathways to COVID-19 vaccine side-effect expectations and experience.Journal of Psychosomatic Research, 164:111081, 2023
work page 2023
- [7]
-
[8]
T. Davidson, D. Warmsley, M. Macy, and I. Weber. Automated hate speech detection and the problem of offensive language. InProceedings of the international AAAI conference on web and social media, volume 11, pages 512–515, 2017
work page 2017
-
[9]
I. J. B. do Nascimento, A. B. Pizarro, J. M. Almeida, N. Azzopardi-Muscat, M. A. Gonçalves, M. Björklund, and D. Novillo-Ortiz. Infodemics and health misinformation: a systematic review of reviews.Bulletin of the World Health Organization, 100(8):544–561, 2022
work page 2022
-
[10]
A. J. Dolman, T. Fraser, C. Panagopoulos, D. P. Aldrich, and D. Kim. Opposing views: associations of political polarization, political party affiliation, and social trust with covid-19 vaccination intent and receipt.Journal of Public Health, 45(1):36–39, 2023
work page 2023
- [11]
- [12]
-
[13]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
L. He, S. Omranian, S. McRoy, and K. Zheng. Using large language models for sentiment analysis of health- related social media data: empirical evaluation and practical tips.Journal of the American Medical Informatics Association, 2024. Working paper/Preprint
work page 2024
-
[15]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models. arxiv 2021.arXiv preprint arXiv:2106.09685, 10, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
T. Islam and D. Goldwasser. Understanding covid-19 vaccine campaign on Facebook using minimal supervision. In2022 IEEE-Big Data, pages 585–595. IEEE, 2022
work page 2022
-
[18]
T. Islam and D. Goldwasser. Discovering latent themes in social media messaging: A machine-in-the-loop approach integrating LLMs. InICWSM, volume 19, pages 859–884, 2025
work page 2025
-
[19]
T. Islam and D. Goldwasser. Uncovering latent arguments in social media messaging by employing llms-in-the- loop strategy. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 7397–7429, 2025
work page 2025
-
[20]
D. Jain, S. Rai, J. Mittal, A. Andy, A. M. Buttenheim, and S. C. Guntuku. Twitter reveals spatio-temporal variation in vaccine concerns in sub-saharan africa.medRxiv, pages 2025–08, 2025
work page 2025
-
[21]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de Las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed. Mistral 7b.ArXiv, abs/2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. de Las Casas, E. B. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. R. Lavaud, L. Saulnier, M.-A. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. L. Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed. Mixtral of experts.ArXiv, abs/24...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
A. R. KhudaBukhsh, R. Sarkar, M. S. Kamlet, and T. Mitchell. We don’t speak the same language: Interpreting polarization through machine translation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 14893–14901, 2021
work page 2021
-
[25]
A. R. KhudaBukhsh, R. Sarkar, M. S. Kamlet, and T. M. Mitchell. Fringe news networks: Dynamics of US news viewership following the 2020 presidential election. InWebSci ’22: 14th ACM Web Science Conference 2022, pages 269–278. ACM, 2022
work page 2020
-
[26]
Y . Li, D. Viswaroopan, W. He, J. Li, X. Zuo, H. Xu, and C. Tao. Enhancing relation extraction for COVID-19 vaccine shot-adverse event associations with large language models.Research Square, 2025. Preprint
work page 2025
-
[27]
E. N. Line, S. Jaramillo, M. Goldwater, and Z. Horne. Anecdotes impact medical decisions even when presented with statistical information or decision aids.Cognitive Research: Principles and Implications, 9(1):51, 2024
work page 2024
-
[28]
Y . Liu, Y . Wang, A. Sun, X. Meng, J. Li, and J. Guo. A dual-channel framework for sarcasm recognition by detecting sentiment conflict. InFindings of the Association for Computational Linguistics: NAACL 2022, pages 1670–1680, 2022
work page 2022
-
[29]
Llama Team, AI @ Meta. The llama 3 herd of models. Technical report, Meta, 2024. Technical Report
work page 2024
-
[30]
C. Luo, W. Jiang, H.-X. Chen, and T.-H. Tung. Post-vaccination adverse reactions, decision regret, and willingness to pay for the booster dose of COVID-19 vaccine among healthcare workers: A mediation analysis.Human Vaccines & Immunotherapeutics, 18(6):e2146964, 2022
work page 2022
-
[31]
Mistral small 3.2 24b instruct (2506)
MistralAI. Mistral small 3.2 24b instruct (2506). https://huggingface.co/mistralai/Mistral-Small-3. 2-24B-Instruct-2506, 2025
work page 2025
- [32]
- [33]
- [34]
-
[35]
D. Pandita, T. C. Weerasooriya, S. Dutta, S. Luger, T. Ranasinghe, A. R. KhudaBukhsh, M. Zampieri, and C. Homan. Rater cohesion and quality from a vicarious perspective. InFindings of the Association for Computa- tional Linguistics: EMNLP 2024, pages 5149–5162, 2024
work page 2024
-
[36]
J. Pofcher, C. M. Homan, R. Sell, and A. R. KhudaBukhsh. Hope vs. hate: Understanding user interactions with lgbtq+ news content in mainstream us news media through the lens of hope speech. InEMNLP 2025, pages 19873–19899, 2025
work page 2025
-
[37]
B. Portelli, S. Scaboro, R. Tonino, E. Chersoni, E. Santus, and G. Serra. Monitoring user opinions and side effects on COVID-19 vaccines in the twittersphere: Infodemiology study of tweets.Journal of Medical Internet Research, 24(5):e35115, 2022
work page 2022
-
[38]
N. K. Sehgal, S. Rai, M. Tonneau, A. K. Agarwal, J. Cappella, M. Kornides, L. Ungar, A. Buttenheim, and S. C. Guntuku. Conversations with ai chatbots increase short-term vaccine intentions but do not outperform standard public health messaging.arXiv preprint arXiv:2504.20519, 2025
work page internal anchor Pith review arXiv 2025
-
[39]
T. T. Shimabukuro, M. Nguyen, D. Martin, and F. DeStefano. Safety monitoring in the vaccine adverse event reporting system (V AERS).Vaccine, 33(36):4398–4405, 2015
work page 2015
-
[40]
D. Sileo. tasksource: A large collection of NLP tasks with a structured dataset preprocessing framework. In LREC-COLING 2024, pages 15655–15684, May 2024
work page 2024
-
[41]
E. Souvatzi, M. Katsikidou, A. Arvaniti, S. Plakias, A. Tsiakiri, and M. Samakouri. Trust in healthcare, medical mistrust, and health outcomes in times of health crisis: A narrative review.Societies, 14(12):269, 2024
work page 2024
- [42]
-
[43]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, M. Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
D. Wawrzuta, M. Jaworski, J. Gotlib, and M. Panczyk. What arguments against covid-19 vaccines run on facebook in poland: content analysis of comments.Vaccines, 9(5):481, 2021
work page 2021
-
[45]
T. C. Weerasooriya, S. Dutta, T. Ranasinghe, M. Zampieri, C. Homan, and A. R. KhudaBukhsh. Vicarious offense and noise audit of offensive speech classifiers: Unifying human and machine disagreement on what is offensive. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, pages 11648–11668, 2023. 12 INVESTI...
work page 2023
-
[46]
M. Wiegand, J. Ruppenhofer, and T. Kleinbauer. Detection of abusive language: the problem of biased datasets. InNAACL-HLT, pages 602–608, 2019
work page 2019
-
[47]
L. Yin, M. Han, and X. Nie. Unlocking blended emotions and underlying drivers: A deep dive into COVID-19 vaccination insights on twitter across digital and physical realms in new york, using ChatGPT.Urban Science, 8(4):222, 2024
work page 2024
-
[48]
C. H. Yoo and A. R. KhudaBukhsh. Auditing and robustifying covid-19 misinformation datasets via anticontent sampling. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 15260–15268, 2023
work page 2023
-
[49]
M. Zeelenberg and J. Beattie. Consequences of regret aversion 2: Additional evidence for effects of feedback on decision making.Organizational Behavior and Human Decision Processes, 72(1):63–78, 1997
work page 1997
- [50]
- [51]
-
[52]
D. Zimmermann, A. Klee, and K. Kaspar. Political news on instagram: influencer versus traditional magazine and the role of their expertise in consumers’ credibility perceptions and news engagement.Frontiers in Psychology, 14:1257994, 2023. 7 Supplementary Information A Data Collection and Filtering Details Full List of YouTube Channels Table 6 and Table 7...
work page 2023
-
[53]
GoalThe purpose of this project is to carefully read user comments about vaccines and classify them based on three key pieces of information: who the comment is about, their vaccination status, and their feelings about their decision
-
[54]
I got the shot and I feel fine
The Annotation TaskFor each comment you are shown, you will answer a series of up to three questions. Please note that some questions will only appear based on your answer to the previous question. Question 1: Who is the subject of the comment?This question asks you to identify the main person or group being discussed in the comment. •self:The author of t...
-
[55]
Final Reminders • Prioritization:If a comment mentions multiple subjects, prioritize the subject who was vaccinated and expresses regret. • Uncertainty:When in doubt, choose the "unspecified" or "unclear" option. It is better to choose an unclear option than to guess an incorrect label. • Focus on Text:Base your judgment only on the text provided. Do not ...
-
[56]
**Regret Scope:** ‘regret‘ = 1 may ONLY be assigned to a specific subject (‘"self"‘ or ‘"other"‘) that has taken the vaccine (‘vaccinated‘ = 1). For general statements about groups, regret MUST be 0
-
[58]
**Vaccination Status:** ‘vaccinated‘ = 1 may ONLY be assigned to a specific subject (‘"self"‘ or ‘"other"‘) that has taken the vaccine. **JSON Schema & Values:** - ‘subject‘: "self" | "other" | "unspecified" - ‘vaccinated‘: 0 | 1 - ‘regret‘: 0 | 1 **Regret Definitions:** - 1: A specific subject (‘self‘/‘other‘) explicitly states regret, warns others based...
-
[59]
For general statements about groups, regret MUST be 0
**Regret Scope:** ‘regret‘ = 1 may ONLY be assigned to a specific subject that has taken the vaccine. For general statements about groups, regret MUST be 0
-
[60]
**Regret Perspective:** The regret must be the subject’s own reported feeling, not the commenter’s projected opinion. **JSON Schema:** - ‘regret‘: 0 | 1 **Regret Definitions:** - 1: A specific subject explicitly states regret, warns others based on their outcome, or describes severe negative health results from the vaccine. - 0: The subject doesn’t expres...
-
[61]
**Regret Scope:** ‘regret‘ = 1 may ONLY be assigned to a specific subject (‘\"self\"‘ or ‘\"other\"‘) that has taken the vaccine (‘vaccinated‘ = 1). For general statements about groups, regret MUST be 0
-
[62]
**Regret Perspective:** The regret must be the subject’s own reported feeling, not the commenter’s projected opinion
-
[63]
**Vaccination Status:** ‘vaccinated‘ = 1 may ONLY be assigned to a specific subject (‘\"self\"‘ or ‘\"other\"‘) that has taken the vaccine. **JSON Schema & Values:** - ‘subject‘: "self" | "other" | "unspecified" - ‘vaccinated‘: 0 | 1 - ‘regret‘: 0 | 1 **Regret Definitions:** - 1: A specific subject (‘self‘/‘other‘) explicitly states regret, warns others b...
-
[64]
my friend regrets getting the vaccine. her period every 2 weeks isn’t normal
**Comment:** "my friend regrets getting the vaccine. her period every 2 weeks isn’t normal." **JSON:** {"subject": "other", "vaccinated": 1, "regret": 1}
-
[65]
My brother got his second dose last week
**Comment:** "My brother got his second dose last week." **JSON:** {"subject": "other", "vaccinated": 1, "regret": 0}
-
[66]
don’t get the vaccine, ever since i got it i have felt tired and had rashes
**Comment:** "don’t get the vaccine, ever since i got it i have felt tired and had rashes." **JSON:** {"subject": "self", "vaccinated": 1, "regret": 1}
-
[67]
**Comment:** "I wonder if the people getting the vaccine will regret it in 10 years when they have serious side effects" **JSON:** {"subject": "unspecified", "vaccinated": 0, "regret": 0}
-
[68]
cnn should interview the people who got the vaccine and regret it after serious side effect
**Comment:** "cnn should interview the people who got the vaccine and regret it after serious side effect" **JSON:** {"subject": "unspecified", "vaccinated": 0, "regret": 0} Now, analyze the following user comment and provide only the JSON output without any commentary. **Comment:** {comment} Figure 8: Few shot prompt Table 12: Examples of Pipeline Classi...
work page 2021
- [70]
-
[71]
The value for this key must be ONE of the following exact strings: * ‘"Adverse_Health_Event"‘ * ‘"Perceived_Coercion"‘ * ‘"Lack_of_Efficacy"‘ * ‘"Shift_in_Beliefs"‘ * ‘"Vague_or_Unspecified"‘ --- **CATEGORY DEFINITIONS & RULES:** * **‘"Adverse_Health_Event"‘** * Assign this category if the regret is linked to any negative physical health outcome. * **Look...
-
[72]
Your output MUST be ONLY a single, raw JSON object
-
[73]
The JSON object must contain a single key: ‘"relationship_to_author"‘
-
[74]
The value for this key must be ONE of the following exact strings: * ‘"Spouse_or_Partner"‘ * ‘"Family_Member"‘ * ‘"Friend"‘ * ‘"Health_Care_Provider"‘ * ‘"Public_Figure"‘ * ‘"Other_Acquaintance"‘ * ‘"Unspecified"‘ --- **CATEGORY DEFINITIONS & RULES:** * **‘"Spouse_or_Partner"‘** * Assign this for a spouse or romantic partner. * **Look for:** "husband," "w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.