Toward using Speech to Sense Student Emotion in Remote Learning Environments
Pith reviewed 2026-05-10 15:56 UTC · model grok-4.3
The pith
Speech from self-control tasks can indicate students' emotions during remote learning
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
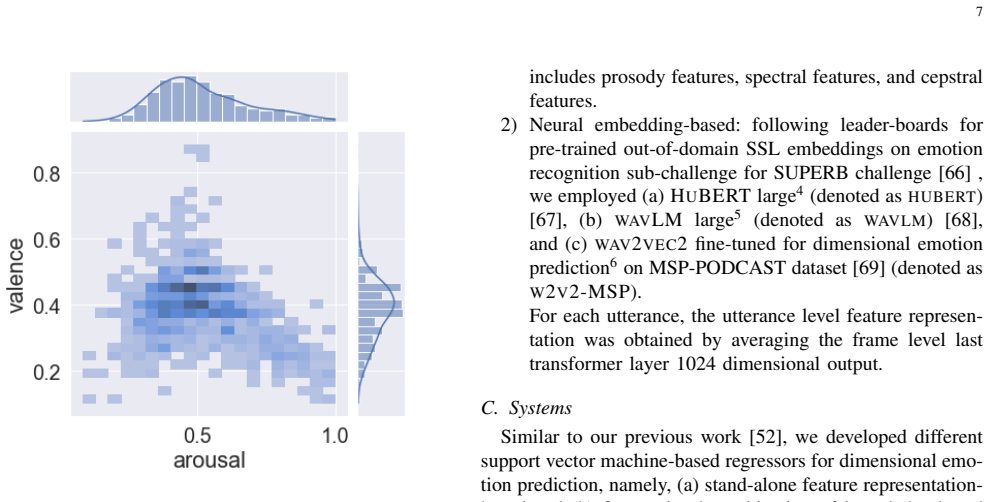
The central claim is that speech acquired through self-control tasks shows perceptible variation along valence, arousal, and dominance dimensions, and that these variations can be automatically predicted from the speech signals.
What carries the argument
A newly developed dataset of spontaneous monologue speech obtained as open responses to self-control tasks, used to study dimensional emotion prediction.
If this is right
- Speech-based emotion sensing supports instructional design adjustments in remote learning.
- Feedback generation can incorporate paralinguistic information from self-control task speech.
- This integration enhances learning experiences in asynchronous environments.
Where Pith is reading between the lines
- One could test whether using these tasks actually leads to improved learning outcomes or student satisfaction.
- The approach might extend to other asynchronous communication scenarios beyond education.
Load-bearing premise
Speech variations observed in the tasks mainly come from changes in emotional state instead of task wording, personal speaking habits, or how the audio was recorded.
What would settle it
A follow-up experiment with a larger and more varied group of students that measures emotions independently, for example with questionnaires right after the tasks, and finds no matching pattern in the speech data would show the approach does not work as claimed.
Figures



read the original abstract
With advancements in multimodal communication technologies, remote learning environments such as, distance universities are increasing. Remote learning typically happens asynchronously. As a consequence, unlike face-to-face in-person classroom teaching, this lacks availability of sufficient emotional cues for making learning a pleasant experience. Motivated by advances made in the paralinguistic speech processing community on emotion prediction, in this paper we explore use of speech for sensing students' emotions by building upon speech-based self-control tasks developed to aid effective remote learning. More precisely, we investigate: (a) whether speech acquired through self-control tasks exhibit perceptible variation along valence, arousal, and dominance dimensions? and (b) whether those dimensional emotion variations can be automatically predicted? We address these two research questions by developing a dataset containing spontaneous monologue speech acquired as open responses to self-control tasks and by carrying out subjective listener evaluations and automatic dimensional emotion prediction studies on that dataset. Our investigations indicate that speech-based self-control tasks can be a means to sense student emotion in remote learning environment. This opens potential venues to seamlessly integrate paralinguistic speech processing technologies in the remote learning loop for enhancing learning experiences through instructional design and feedback generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper explores the use of speech collected via self-control tasks in remote learning environments to sense student emotions. It develops a new dataset of spontaneous monologue speech as open responses to these tasks, conducts subjective listener evaluations of valence-arousal-dominance (VAD) variations, and performs automatic dimensional emotion prediction experiments. The central claim is that speech-based self-control tasks can serve as a means to sense student emotion, enabling integration of paralinguistic technologies for instructional design and feedback in asynchronous remote learning.
Significance. If the empirical results hold with proper controls and generalization, the work could open avenues for embedding speech emotion recognition into educational platforms to address the lack of emotional cues in remote settings. The approach builds on established paralinguistic methods and introduces a task-specific dataset, which has potential for practical impact in distance education if the attribution to emotion (rather than confounds) is convincingly demonstrated.
major comments (2)
- [Dataset collection and experimental design sections] The manuscript provides no description of controls to isolate emotional state from linguistic content of the open responses, individual speaking styles, or recording conditions (e.g., no matched neutral vs. emotional prompts, content-independent features, or speaker-normalized baselines). This is load-bearing for the central claim that observed VAD variations and predictions arise primarily from emotion, as subjective ratings and automatic predictions could succeed for non-emotional reasons.
- [Subjective listener evaluations and automatic prediction studies] No sample sizes, participant demographics, number of tasks/responses, or statistical tests (e.g., significance of VAD differences or prediction performance metrics like CCC, RMSE with baselines) are reported. This prevents verification of whether the subjective evaluations and automatic predictions support the generalization that self-control tasks can sense student emotion.
minor comments (2)
- [Introduction] The abstract and introduction could more clearly distinguish the self-control tasks from standard emotion elicitation protocols to highlight novelty.
- [Automatic prediction experiments] Notation for VAD dimensions and any feature sets used in prediction should be defined consistently if not already standard.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for strengthening the experimental design description and statistical reporting, which we address point by point below. We have revised the manuscript to incorporate the requested details and clarifications where feasible.
read point-by-point responses
-
Referee: [Dataset collection and experimental design sections] The manuscript provides no description of controls to isolate emotional state from linguistic content of the open responses, individual speaking styles, or recording conditions (e.g., no matched neutral vs. emotional prompts, content-independent features, or speaker-normalized baselines). This is load-bearing for the central claim that observed VAD variations and predictions arise primarily from emotion, as subjective ratings and automatic predictions could succeed for non-emotional reasons.
Authors: We agree that explicit discussion of controls is necessary to support attribution of VAD variations to emotion rather than confounds. The self-control tasks were intentionally open-ended to capture spontaneous emotional responses tied to the remote learning context, but the original manuscript did not detail mitigation strategies. In the revision, we have added a subsection describing the use of prosodic and spectral features that are relatively content-independent, along with speaker-level normalization applied during feature extraction to account for individual styles. Recording conditions were standardized across participants via the same remote platform and equipment guidelines. We acknowledge that matched neutral prompts were not included and have added this as an explicit limitation with suggestions for future controlled studies. These changes better ground the central claim without altering the core findings. revision: yes
-
Referee: [Subjective listener evaluations and automatic prediction studies] No sample sizes, participant demographics, number of tasks/responses, or statistical tests (e.g., significance of VAD differences or prediction performance metrics like CCC, RMSE with baselines) are reported. This prevents verification of whether the subjective evaluations and automatic predictions support the generalization that self-control tasks can sense student emotion.
Authors: We apologize for these omissions in the initial version, which are critical for reproducibility and assessment of the results. The revised manuscript now includes the full details: sample sizes and demographics for listeners and speakers, the total number of tasks and responses collected, and the results of statistical tests (including p-values for VAD differences). Automatic prediction results are expanded with CCC, RMSE, and other metrics, plus comparisons against baseline models. These additions directly enable verification and strengthen support for the generalization regarding self-control tasks in remote learning. revision: yes
Circularity Check
Empirical study with no circular derivations or self-referential reductions
full rationale
The paper describes an empirical investigation that collects a new dataset of spontaneous monologue speech from self-control tasks, conducts subjective listener evaluations on valence-arousal-dominance dimensions, and runs standard automatic prediction experiments. No equations, derivations, fitted parameters, or self-citations are presented that reduce the central claims (perceptible variation and automatic predictability) to tautologies or inputs by construction. The results rest on new data and external evaluation protocols rather than any self-definitional or load-bearing circular step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Speech contains paralinguistic cues that vary with emotional valence, arousal, and dominance
Reference graph
Works this paper leans on
-
[1]
Emotions as drivers of learning and cognitive development,
R. Pekrun, “Emotions as drivers of learning and cognitive development,” inNew perspectives on affect and learning technologies. Springer, 2011, pp. 23–39
work page 2011
-
[2]
M. McConnell and K. W. Eva, “Emotions and learning: cognitive theoretical and methodological approaches to studying the influence of emotions on learning,”Researching medical education, pp. 279–290, 2022
work page 2022
-
[3]
Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends,
B. W. Schuller, “Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends,”Communications of the ACM, 2018
work page 2018
-
[4]
Adaptive motivation and emotion in education: Research and principles for instructional design,
L. Linnenbrink-Garcia, E. A. Patall, and R. Pekrun, “Adaptive motivation and emotion in education: Research and principles for instructional design,”Policy Insights from the Behavioral and Brain Sciences, vol. 3, no. 2, pp. 228–236, 2016
work page 2016
-
[5]
Designing instructional technology from an emotional perspective,
H. Astleitner and D. Leutner, “Designing instructional technology from an emotional perspective,”Journal of research on computing in educa- tion, vol. 32, no. 4, pp. 497–510, 2000
work page 2000
-
[6]
K. M. Chuah, C. J. Chen, and C. S. Teh, “Kansei engineering concept in instructional design. a novel perspective in guiding the design of instructional materials,” inFifth International Cyberspace Conference on Ergonomics, 2008, pp. 1–8
work page 2008
-
[7]
Empathic design: Imagining the cognitive and emotional learner experience,
M. W. Tracey and A. Hutchinson, “Empathic design: Imagining the cognitive and emotional learner experience,”Educational Technology Research and Development, vol. 67, pp. 1259–1272, 2019
work page 2019
-
[8]
J. A. Kumar, B. Muniandy, and W. A. J. Wan Yahaya, “Exploring the effects of emotional design and emotional intelligence in multimedia- based learning: an engineering educational perspective,”New Review of Hypermedia and Multimedia, vol. 25, no. 1-2, pp. 57–86, 2019
work page 2019
-
[9]
M. Gl ¨aser-Zikuda, S. Fuß, M. Laukenmann, K. Metz, and C. Randler, “Promoting students’ emotions and achievement–instructional design and evaluation of the ecole-approach,”Learning and instruction, vol. 15, no. 5, pp. 481–495, 2005
work page 2005
-
[10]
Oral presentation competence in virtual reality,
C. Hou, “Oral presentation competence in virtual reality,” 10.17615/d5ce-bs51, 2022
-
[11]
Positive emotion elicitation in chat-based dialogue systems,
N. Lubis, S. Sakti, K. Yoshino, and S. Nakamura, “Positive emotion elicitation in chat-based dialogue systems,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 4, pp. 866–877, 2019
work page 2019
-
[12]
K. Tomita, “Visual design as a holistic experience: How students’ emotional responses to the visual design of instructional materials are formed,”Educational technology research and development, vol. 70, no. 2, pp. 469–502, 2022
work page 2022
-
[13]
S. Jarvel ¨a, E. Lehtinen, and P. Salonen, “Socio-emotional orientation as a mediating variable in the teaching-learning interaction: Implications for instructional design,”Scandinavian journal of educational research, vol. 44, no. 3, pp. 293–306, 2000. 10
work page 2000
-
[14]
E. Werlen and D. J. Laubscher, “Experiences with speech input in open questions: A digital innovation to foster self-directed learning,” in Empowering self-directed learner through digital innovation. AOSIS, 2025
work page 2025
-
[15]
Squeezing lemons - emotions in impersonal non-fiction texts. emotional analyses of students’ texts,
E. Werlen, T. Panar, B. Parsaeifard, and C. Imhof, “Squeezing lemons - emotions in impersonal non-fiction texts. emotional analyses of students’ texts,” inEARLI SIG27 Conference 2022: Online measures at the crossroad of ethical and methodological challenges. Southampton, UK, 30 August – 1 September 2022., 2022
work page 2022
-
[16]
Multi-modal emotion recognition from speech and text,
Z.-J. Chuang and C.-H. Wu, “Multi-modal emotion recognition from speech and text,” inInternational Journal of Computational Linguistics & Chinese Language Processing, V olume 9, Number 2, August 2004: Special Issue on New Trends of Speech and Language Processing, 2004, pp. 45–62
work page 2004
-
[17]
R. Mobbs, D. Makris, and V . Argyriou, “Emotion recognition and gen- eration: A comprehensive review of face, speech, and text modalities,” arXiv preprint arXiv:2502.06803, 2025
-
[18]
Desperately seeking emotions or: Actors, wizards, and human beings,
A. Batliner, K. Fischer, R. Huber, J. Spilker, and E. N ¨oth, “Desperately seeking emotions or: Actors, wizards, and human beings,” inISCA tutorial and research workshop (ITRW) on speech and emotion, 2000
work page 2000
-
[19]
H. Gunes and B. Schuller, “Categorical and dimensional affect analysis in continuous input: Current trends and future directions,”Image and Vision Computing, vol. 31, no. 2, pp. 120–136, 2013
work page 2013
-
[20]
A database of German emotional speech
F. Burkhardt, A. Paeschke, M. Rolfes, W. F. Sendlmeier, B. Weisset al., “A database of German emotional speech.” inInterspeech, vol. 5, 2005, pp. 1517–1520
work page 2005
-
[21]
Ekman,Are there basic emotions?American Psychological Associ- ation, 1992
P. Ekman,Are there basic emotions?American Psychological Associ- ation, 1992
work page 1992
-
[22]
SmartKom: Multimodal communication with a life-like character,
W. Wahlster, N. Reithinger, and A. Blocher, “SmartKom: Multimodal communication with a life-like character,” inSeventh European Confer- ence on Speech Communication and Technology, 2001
work page 2001
-
[23]
Universal methods of design: 100 ways to research complex problems,
B. Martin, B. Hanington, and B. M. Hanington, “Universal methods of design: 100 ways to research complex problems,”Develop Innovative Ideas, and Design Effective Solutions, pp. 12–13, 2012
work page 2012
-
[24]
Heading toward to the natural way of human-machine interaction: the NIMITEK project,
B. Vlasenko and A. Wendemuth, “Heading toward to the natural way of human-machine interaction: the NIMITEK project,” in2009 IEEE International Conference on Multimedia and Expo. IEEE, 2009, pp. 950–953
work page 2009
-
[25]
Social functions of emotions at four levels of analysis,
D. Keltner and J. Haidt, “Social functions of emotions at four levels of analysis,”Cognition & Emotion, vol. 13, no. 5, pp. 505–521, 1999
work page 1999
-
[26]
J. K. Burgoon, D. B. Buller, L. Dillman, and J. B. Walther, “Interper- sonal deception: IV . Effects of suspicion on perceived communication and nonverbal behavior dynamics,”Human Communication Research, vol. 22, no. 2, pp. 163–196, 1995
work page 1995
-
[27]
Exploring cross-modality affective re- actions for audiovisual emotion recognition,
S. Mariooryad and C. Busso, “Exploring cross-modality affective re- actions for audiovisual emotion recognition,”IEEE Transactions on affective computing, vol. 4, no. 2, pp. 183–196, 2013
work page 2013
-
[28]
A. Alghamdi, A. C. Karpinski, A. Lepp, and J. Barkley, “Online and face-to-face classroom multitasking and academic performance: Moderated mediation with self-efficacy for self-regulated learning and gender,”Computers in Human Behavior, vol. 102, pp. 214–222, 2020
work page 2020
-
[29]
H. Mori, T. Satake, M. Nakamura, and H. Kasuya, “Constructing a spo- ken dialogue corpus for studying paralinguistic information in expressive conversation and analyzing its statistical/acoustic characteristics,”Speech Communication, vol. 53, no. 1, pp. 36–50, 2011
work page 2011
-
[30]
X. Zhu and G. Penn, “Comparing the roles of textual, acoustic and spoken-language features on spontaneous-conversation summarization,” inProceedings of the Human Language Technology Conference of the NAACL, Companion V olume: Short Papers, 2006, pp. 197–200
work page 2006
-
[31]
An argument for basic emotions,
P. Ekman, “An argument for basic emotions,”Cognition & emotion, vol. 6, no. 3-4, pp. 169–200, 1992
work page 1992
-
[32]
Evidence for a three-factor theory of emotions,
J. A. Russell and A. Mehrabian, “Evidence for a three-factor theory of emotions,”Journal of research in Personality, vol. 11, no. 3, pp. 273– 294, 1977
work page 1977
-
[33]
The vera am mittag german audio-visual emotional speech database,
M. Grimmet al., “The vera am mittag german audio-visual emotional speech database,” inProc. ICME. IEEE, 2008, pp. 865–868
work page 2008
-
[34]
Iemocap: Interactive emotional dyadic motion capture database,
C. Bussoet al., “Iemocap: Interactive emotional dyadic motion capture database,”Language resources and evaluation, 2008
work page 2008
-
[35]
Introducing the recola multimodal corpus of remote collaborative and affective interac- tions,
F. Ringeval, A. Sonderegger, J. Sauer, and D. Lalanne, “Introducing the recola multimodal corpus of remote collaborative and affective interac- tions,” in2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), 2013, pp. 1–8
work page 2013
-
[36]
’FEELTRACE’: An instrument for recording per- ceived emotion in real time,
R. Cowie, E. Douglas-Cowie, S. Savvidou*, E. McMahon, M. Sawey, and M. Schr ¨oder, “’FEELTRACE’: An instrument for recording per- ceived emotion in real time,” inISCA tutorial and research workshop (ITRW) on speech and emotion, 2000
work page 2000
-
[37]
Gtrace: General trace program compatible with EmotionML,
R. Cowie, M. Sawey, C. Doherty, J. Jaimovich, C. Fyans, and P. Sta- pleton, “Gtrace: General trace program compatible with EmotionML,” in2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, 2013, pp. 709–710
work page 2013
-
[38]
MSP-IMPROV: An acted corpus of dyadic inter- actions to study emotion perception,
C. Busso, S. Parthasarathy, A. Burmania, M. AbdelWahab, N. Sadoughi, and E. M. Provost, “MSP-IMPROV: An acted corpus of dyadic inter- actions to study emotion perception,”IEEE Transactions on Affective Computing, 2017
work page 2017
-
[39]
R. Lotfian and C. Busso, “Building naturalistic emotionally balanced speech corpus by retrieving emotional speech from existing podcast recordings,”IEEE Transactions on Affective Computing, vol. 10, no. 4, pp. 471–483, October-December 2019
work page 2019
-
[40]
UMEME: University of michigan emotional mcgurk effect data set,
E. M. Provost, Y . Shangguan, and C. Busso, “UMEME: University of michigan emotional mcgurk effect data set,”IEEE Transactions on Affective Computing, vol. 6, no. 4, pp. 395–409, 2015
work page 2015
-
[41]
Crema-d: Crowd-sourced emotional multimodal actors dataset,
H. Cao, D. G. Cooper, M. K. Keutmann, R. C. Gur, A. Nenkova, and R. Verma, “Crema-d: Crowd-sourced emotional multimodal actors dataset,”IEEE transactions on affective computing, vol. 5, no. 4, pp. 377–390, 2014
work page 2014
-
[42]
A. Tarasov, S. J. Delany, and C. Cullen,Using crowdsourcing for labelling emotional speech assets. Technological University Dublin, 2010
work page 2010
-
[43]
Cheap and fast–but is it good? evaluating non-expert annotations for natural language tasks,
R. Snow, B. O’connor, D. Jurafsky, and A. Y . Ng, “Cheap and fast–but is it good? evaluating non-expert annotations for natural language tasks,” inProceedings of the 2008 conference on empirical methods in natural language processing, 2008, pp. 254–263
work page 2008
-
[44]
R. Lotfian and C. Busso, “Building naturalistic emotionally balanced speech corpus by retrieving emotional speech from existing podcast recordings,”IEEE Transactions on Affective Computing, vol. 10, no. 4, pp. 471–483, 2017
work page 2017
-
[45]
Salman, Wei-Cheng Lin, and others
C. Busso, R. Lotfian, K. Sridhar, A. N. Salman, W.-C. Lin, L. Goncalves, S. Parthasarathy, A. R. Naini, S.-G. Leem, L. Martinez-Lucaset al., “The msp-podcast corpus,”arXiv preprint arXiv:2509.09791, 2025
-
[46]
A. M. Rahman, M. I. Tanveer, A. I. Anam, and M. Yeasin, “Imaps: A smart phone based real-time framework for prediction of affect in natural dyadic conversation,” in2012 Visual Communications and Image Processing. IEEE, 2012, pp. 1–6
work page 2012
-
[47]
On the acoustics of emotion in audio: what speech, music, and sound have in common,
F. Weninger, F. Eyben, B. W. Schuller, M. Mortillaro, and K. R. Scherer, “On the acoustics of emotion in audio: what speech, music, and sound have in common,”Frontiers in psychology, vol. 4, p. 292, 2013
work page 2013
-
[48]
A. Sayedelahl, R. Araujo, and M. S. Kamel, “Audio-visual feature- decision level fusion for spontaneous emotion estimation in speech conversations,” in2013 IEEE International Conference on Multimedia and Expo Workshops (ICMEW). IEEE, 2013, pp. 1–6
work page 2013
-
[49]
Jointly predicting arousal, valence and dominance with multi-task learning
S. Parthasarathy and C. Busso, “Jointly predicting arousal, valence and dominance with multi-task learning.” inInterspeech, vol. 2017, 2017, pp. 1103–1107
work page 2017
-
[50]
Towards robust speech emotion recognition using deep resid- ual networks for speech enhancement,
A. Triantafyllopoulos, G. Keren, J. Wagner, I. Steiner, and B. W. Schuller, “Towards robust speech emotion recognition using deep resid- ual networks for speech enhancement,” inInterspeech 2019, 2019, pp. 1691–1695
work page 2019
-
[51]
Dawn of the Transformer Era in Speech Emotion Recognition: Closing the Valence Gap,
J. Wagner, A. Triantafyllopoulos, H. Wierstorf, M. Schmitt, F. Burkhardt, F. Eyben, and B. W. Schuller, “Dawn of the Transformer Era in Speech Emotion Recognition: Closing the Valence Gap,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 9, pp. 10 745– 10 759, 2023
work page 2023
-
[52]
Comparing data-driven and handcrafted features for dimensional emotion recognition,
B. Vlasenko, S. Vyas, and M. M. Doss, “Comparing data-driven and handcrafted features for dimensional emotion recognition,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 11 841–11 845
work page 2024
-
[53]
Opel: Online prompting in elearning. a new tool to foster skills and knowledge,
E. Werlen and P. Bergamin, “Opel: Online prompting in elearning. a new tool to foster skills and knowledge,” inEuropean Conference on Education Research - ECER 2014: ”The Past, the Present and Future of Educational Research in Europe”. EERA, 2014
work page 2014
-
[54]
Self-control tasks with self-explanation prompts as a component of self-directed online learning,
E. Werlen, V . Mirata, D. Jagals, and N. Bergamin, “Self-control tasks with self-explanation prompts as a component of self-directed online learning,” inBlended learning environments to foster selfdirected learn- ing.AOSIS, 2021, pp. 199–227
work page 2021
-
[55]
The Kaldi speech recognition toolkit,
D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y . Qian, P. Schwarzet al., “The Kaldi speech recognition toolkit,” inIEEE 2011 workshop on automatic speech recognition and understanding. IEEE Signal Processing Society, 2011
work page 2011
-
[56]
Montreal forced aligner: Trainable text-speech alignment using Kaldi
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Sonderegger, “Montreal forced aligner: Trainable text-speech alignment using Kaldi.” inProc. of Interspeech, 2017. 11
work page 2017
-
[57]
Comparing the performance of forced aligners used in sociophonetic research,
S. Gonzalez, J. Grama, and C. E. Travis, “Comparing the performance of forced aligners used in sociophonetic research,”Linguistics V anguard, vol. 6, no. 1, p. 20190058, 2020
work page 2020
-
[58]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” 2019
work page 2019
-
[59]
Training a broad-coverage german sentiment classification model for dialog sys- tems,
O. Guhr, A.-K. Schumann, F. Bahrmann, and H. J. B ¨ohme, “Training a broad-coverage german sentiment classification model for dialog sys- tems,” inProceedings of the Twelfth Language Resources and Evaluation Conference, 2020, pp. 1627–1632
work page 2020
-
[60]
Measuring emotion: The self- assessment manikin and the semantic differential,
M. M. Bradley and P. J. Lang, “Measuring emotion: The self- assessment manikin and the semantic differential,”Journal of Behavior Therapy and Experimental Psychiatry, vol. 25, no. 1, p. 49–59, 1994. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ 0005791694900639
work page 1994
-
[61]
C. Sainz-de Baranda Andujar, L. Guti ´errez-Mart´ın, J. ´A. Miranda- Calero, M. Blanco-Ruiz, and C. L ´opez-Ongil, “Gender biases in the training methods of affective computing: Redesign and validation of the self-assessment manikin in measuring emotions via audiovisual clips,” Frontiers in psychology, vol. 13, p. 955530, 2022
work page 2022
-
[62]
Evaluation of natural emotions using self assessment manikins,
M. Grimm and K. Kroschel, “Evaluation of natural emotions using self assessment manikins,” inIEEE Workshop on Automatic Speech Recognition and Understanding, 2005., 2005, pp. 381–385
work page 2005
-
[63]
Primitives-based evaluation and estimation of emo- tions in speech,
M. Grimmet al., “Primitives-based evaluation and estimation of emo- tions in speech,”Speech communication, vol. 49, no. 10-11, pp. 787–800, 2007
work page 2007
-
[64]
B. Schuller, S. Steidl, A. Batliner, A. Vinciarelli, K. Scherer, F. Ringeval, M. Chetouani, F. Weninger, F. Eyben, E. Marchiet al., “The INTER- SPEECH 2013 computational paralinguistics challenge: Social signals, conflict, emotion, autism,” inProceedings INTERSPEECH 2013, Lyon, France, 2013
work page 2013
-
[65]
Opensmile: the Munich versatile and fast open-source audio feature extractor,
F. Eybenet al., “Opensmile: the Munich versatile and fast open-source audio feature extractor,” inProc. ACMM MM, 2010, pp. 1459–1462
work page 2010
-
[66]
SUPERB: Speech processing Universal PERfor- mance Benchmark,
S. wen Yanget al., “SUPERB: Speech processing Universal PERfor- mance Benchmark,” inProc. Interspeech, 2021, pp. 1194–1198
work page 2021
-
[67]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsuet al., “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021
work page 2021
-
[68]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chenet al., “WavLM: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, pp. 1505–1518, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:239885872
work page 2021
-
[69]
Model for Dimensional Speech Emotion Recognition based on Wav2vec 2.0
J. Wagneret al., “Model for Dimensional Speech Emotion Recognition based on Wav2vec 2.0.” [Online]. Available: https://doi.org/10.5281/ zenodo.6221127
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.