Recognition: 2 theorem links
· Lean TheoremAttention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
Pith reviewed 2026-05-10 16:12 UTC · model grok-4.3
The pith
Attention sink, where transformers disproportionately attend to uninformative tokens, receives its first comprehensive survey organized by utilization, mechanistic interpretation, and strategic mitigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that attention sink research forms a coherent landscape that can be organized along three axes—Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation—thereby consolidating scattered findings into a single reference that clarifies key concepts and outlines evolution and trends in the field.
What carries the argument
The three-dimensional organizing framework of Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation, which structures the consolidation of all cited attention sink studies.
If this is right
- Practitioners gain a map for deciding when to harness attention sink in model design rather than treat it only as a flaw.
- Mechanistic accounts can be used to improve interpretability of transformer decisions.
- Mitigation techniques can be applied to reduce hallucinations and stabilize inference.
- The survey supplies a baseline for evaluating whether new transformer variants still exhibit attention sink.
Where Pith is reading between the lines
- The same three-axis structure could be applied to attention anomalies observed in non-transformer architectures.
- Testing whether mitigation methods remain effective at larger scales would directly extend the survey's guidance.
- The consolidated view may help identify which utilization patterns are worth preserving versus eliminating in next-generation models.
Load-bearing premise
The body of published attention sink research can be fully collected and accurately represented without major omissions or mischaracterizations of individual works.
What would settle it
An important un-cited paper on attention sink mechanisms or mitigation whose findings contradict the survey's synthesis would show the consolidation is incomplete.
Figures






































read the original abstract
As the foundational architecture of modern machine learning, Transformers have driven remarkable progress across diverse AI domains. Despite their transformative impact, a persistent challenge across various Transformers is Attention Sink (AS), in which a disproportionate amount of attention is focused on a small subset of specific yet uninformative tokens. AS complicates interpretability, significantly affecting the training and inference dynamics, and exacerbates issues such as hallucinations. In recent years, substantial research has been dedicated to understanding and harnessing AS. However, a comprehensive survey that systematically consolidates AS-related research and offers guidance for future advancements remains lacking. To address this gap, we present the first survey on AS, structured around three key dimensions that define the current research landscape: Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation. Our work provides a pivotal contribution by clarifying key concepts and guiding researchers through the evolution and trends of the field. We envision this survey as a definitive resource, empowering researchers and practitioners to effectively manage AS within the current Transformer paradigm, while simultaneously inspiring innovative advancements for the next generation of Transformers. The paper list of this work is available at https://github.com/ZunhaiSu/Awesome-Attention-Sink.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to be the first survey on Attention Sink (AS) in Transformers. It organizes the literature around three dimensions—Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation—with the goals of clarifying concepts, tracing evolution and trends, and guiding future work on managing AS. An accompanying GitHub repository lists the surveyed papers.
Significance. If the coverage is accurate and reasonably complete, the survey would be a useful consolidation of research on a phenomenon that affects interpretability, training/inference dynamics, and hallucinations in Transformers. The GitHub paper list is a concrete strength that supports accessibility and reproducibility of the cited works.
major comments (1)
- [Abstract/Introduction] Abstract and Introduction: The claim of presenting a 'comprehensive survey' and 'definitive resource' is not supported by any description of literature search strategy, databases used, keywords, inclusion/exclusion criteria, date range, or number of papers reviewed. This information is load-bearing for evaluating the survey's completeness and potential selection bias.
minor comments (2)
- [Section 1 or 2] Ensure that each of the three taxonomy dimensions is explicitly defined early in the paper so that readers can verify how individual works are assigned without ambiguity.
- [Conclusion] The GitHub link is helpful; consider adding a brief note in the paper on how the list will be maintained or updated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the survey's potential utility. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract/Introduction] Abstract and Introduction: The claim of presenting a 'comprehensive survey' and 'definitive resource' is not supported by any description of literature search strategy, databases used, keywords, inclusion/exclusion criteria, date range, or number of papers reviewed. This information is load-bearing for evaluating the survey's completeness and potential selection bias.
Authors: We agree that a transparent description of the literature search process is necessary to support claims of comprehensiveness and to enable assessment of scope and bias. The submitted manuscript did not include this detail. In the revised version, we will add a dedicated 'Literature Search Methodology' subsection (placed after the Introduction) that specifies: primary databases (arXiv, Google Scholar, ACL Anthology); search keywords ('attention sink', 'attention sink transformers', 'sink token', 'attention sink phenomenon'); date range (2023 onward, reflecting the emergence of the topic); inclusion criteria (works explicitly analyzing, utilizing, interpreting, or mitigating attention sink in Transformer architectures, including preprints and conference papers); exclusion criteria (non-English works, tangential mentions without substantive discussion); and total papers reviewed (approximately 50, as catalogued in the GitHub repository). This addition will provide the requested transparency while preserving the survey's structure and contributions. revision: yes
Circularity Check
No significant circularity in survey structure
full rationale
This is a literature survey paper that organizes existing external research on Attention Sink into three axes (Fundamental Utilization, Mechanistic Interpretation, Strategic Mitigation) without performing any new derivations, predictions, or parameter fits. The central claim of being the 'first survey' is a factual assertion about coverage of prior work, not a result derived from the paper's own inputs or self-citations. No equations, ansatzes, uniqueness theorems, or reductions appear in the provided text; all content rests on citations to independent papers. The taxonomy is presented as an organizing framework rather than a self-defining or fitted construct, leaving the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we present the first survey on AS, structured around three key dimensions: Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Softmax Limitations and No-Op Theory; Outlier Circuits; Implicit Attention Bias
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Priming: Hybrid State Space Models From Pre-trained Transformers
Priming transfers knowledge from pre-trained Transformers to hybrid SSM-attention models, recovering performance with minimal additional tokens and showing Gated KalmaNet outperforming Mamba-2 on long-context reasonin...
-
When Does Value-Aware KV Eviction Help? A Fixed-Contract Diagnostic for Non-Monotone Cache Compression
A fixed-contract probe shows value-aware KV eviction recovers needed evidence in 72.6% of accuracy-improving cases on LongBench but only 32.4% otherwise, suggesting an order of recover evidence, rank value, then prese...
Reference graph
Works this paper leans on
-
[1]
Attentionisallyouneed
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, andIlliaPolosukhin. Attentionisallyouneed. InProceedingsofthe31stInternationalConference on Neural Information Processing Systems, page 6000–6010, 2017
2017
-
[2]
A survey of transformers.AI open, 3:111–132, 2022
Tianyang Lin, Yuxin Wang, Xiangyang Liu, and Xipeng Qiu. A survey of transformers.AI open, 3:111–132, 2022
2022
-
[3]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Be- ichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2), 2023
work page internal anchor Pith review arXiv 2023
-
[4]
A survey on vision transformer.IEEE transactions on pattern analysis and machine intelligence, 45(1):87–110, 2022
KaiHan, YunheWang, HantingChen, XinghaoChen, JianyuanGuo, ZhenhuaLiu, YehuiTang, AnXiao, Chunjing Xu, Yixing Xu, et al. A survey on vision transformer.IEEE transactions on pattern analysis and machine intelligence, 45(1):87–110, 2022
2022
-
[5]
A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
2024
-
[6]
A survey of embodied ai: From simulators to research tasks.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(2):230–244, 2022
Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, and Cheston Tan. A survey of embodied ai: From simulators to research tasks.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(2):230–244, 2022
2022
-
[7]
arXiv preprint arXiv:2509.01322 , year=
Meituan LongCat Team, Bei Li, Bingye Lei, Bo Wang, Bolin Rong, Chao Wang, Chao Zhang, Chen Gao, Chen Zhang, Cheng Sun, et al. Longcat-flash technical report.arXiv preprint arXiv:2509.01322, 2025
-
[8]
Longcat-flash-omni technical report.ArXiv, abs/2511.00279,
Meituan LongCat Team, Bairui Wang, Bin Xiao, Bo Zhang, Bolin Rong, Borun Chen, Chang Wan, Chao Zhang, Chen Huang, Chen Chen, et al. Longcat-flash-omni technical report.arXiv preprint arXiv:2511.00279, 2025
-
[9]
Introducing longcat-flash-thinking: A technical report.arXiv preprint arXiv:2509.18883,
Meituan LongCat Team, Anchun Gui, Bei Li, Bingyang Tao, Bole Zhou, Borun Chen, Chao Zhang, Chengcheng Han, Chenhui Yang, Chi Zhang, et al. Introducing longcat-flash-thinking: A technical report.arXiv preprint arXiv:2509.18883, 2025
-
[10]
arXiv preprint arXiv:2601.16725 , year=
Meituan LongCat Team, Anchun Gui, Bei Li, Bingyang Tao, Bole Zhou, Borun Chen, Chao Zhang, Chen Gao, Chen Zhang, Chengcheng Han, et al. Longcat-flash-thinking-2601 technical report.arXiv preprint arXiv:2601.16725, 2026
-
[11]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[12]
Zunhai Su, Weihao Ye, Hansen Feng, Keyu Fan, Jing Zhang, Dahai Yu, Zhengwu Liu, and Ngai Wong. Xstreamvggt: Extremely memory-efficient streaming vision geometry grounded transformer with kv cache compression.arXiv preprint arXiv:2601.01204, 2026
-
[13]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed- forward metric 3d reconstruction.CoRR, abs/2509.13414, 2025. 82 Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
work page internal anchor Pith review arXiv 2025
-
[14]
A survey on model compression for large language models.Transactions of the Association for Computational Linguistics, 12:1556–1577, 2024
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. A survey on model compression for large language models.Transactions of the Association for Computational Linguistics, 12:1556–1577, 2024
2024
-
[15]
Efficient large language models: A survey.Transactions on Machine Learning Research, 2024
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, et al. Efficient large language models: A survey.Transactions on Machine Learning Research, 2024
2024
-
[16]
Kvquant: Towards 10 million context length llm inference with kv cache quantization
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun S Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization. InProceedings of the 38th International Conference on Neural Information Processing Systems, 2024
2024
-
[17]
Hengyuan Zhang, Zhihao Zhang, Mingyang Wang, Zunhai Su, Yiwei Wang, Qianli Wang, Shuzhou Yuan, Ercong Nie, Xufeng Duan, Qibo Xue, et al. Locate, steer, and improve: A practical survey of actionable mechanistic interpretability in large language models.arXiv preprint arXiv:2601.14004, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Efficient attention mechanisms for large language models: A survey.Visual Intelligence, 2025
Yutao Sun, Zhenyu Li, Yike Zhang, Tengyu Pan, Bowen Dong, Yuyi Guo, and Jianyong Wang. Efficient attention mechanisms for large language models: A survey.Visual Intelligence, 2025
2025
-
[19]
Weigao Sun, Jiaxi Hu, Yucheng Zhou, Jusen Du, Disen Lan, Kexin Wang, Tong Zhu, Xiaoye Qu, Yu Zhang, Xiaoyu Mo, et al. Speed always wins: A survey on efficient architectures for large language models.arXiv preprint arXiv:2508.09834, 2025
-
[20]
Gated delta networks: Improving mamba2 with delta rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[21]
Kimi Linear: An Expressive, Efficient Attention Architecture
Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, et al. Kimi linear: An expressive, efficient attention architecture.arXiv preprint arXiv:2510.26692, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
Titans: Learning to memorize at test time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[23]
SnapMLA: Efficient Long-Context MLA Decoding via Hardware-Aware FP8 Quantized Pipelining
Yifan Zhang, Zunhai Su, Shuhao Hu, Rui Yang, Wei Wu, Yulei Qian, Yuchen Xie, and Xunliang Cai. Snapmla: Efficient long-context mla decoding via hardware-aware fp8 quantized pipelining.arXiv preprint arXiv:2602.10718, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Efficientstreaminglanguage models with attention sinks
GuangxuanXiao, YuandongTian, BeidiChen, SongHan, andMikeLewis. Efficientstreaminglanguage models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[25]
When attention sink emerges in language models: An empirical view
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 83 Attention Sink in Transformers: A Survey on Utilization, ...
2025
-
[27]
Why do llms attend to the first token? InSecond Conference on Language Modeling, 2025
Federico Barbero, Alvaro Arroyo, Xiangming Gu, Christos Perivolaropoulos, Michael Bronstein, Petar Veličković, and Razvan Pascanu. Why do llms attend to the first token? InSecond Conference on Language Modeling, 2025
2025
-
[28]
Kvsink: Understanding and enhancing the preservation of attention sinks in kv cache quantization for llms
Zunhai Su and Kehong Yuan. Kvsink: Understanding and enhancing the preservation of attention sinks in kv cache quantization for llms. InSecond Conference on Language Modeling, 2025
2025
-
[29]
Quantizable transformers: Removing outliers by helping attention heads do nothing
Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. Quantizable transformers: Removing outliers by helping attention heads do nothing. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[30]
Pengkun Jiao, Bin Zhu, Jingjing Chen, Chong-Wah Ngo, and Yu-Gang Jiang. Don’t deceive me: Mitigating gaslighting through attention reallocation in lmms.arXiv preprint arXiv:2504.09456, 2025
-
[31]
Attention reallocation: Towards zero-cost and controllable hallucination mitigation of mllms.International Journal of Computer Vision, 134(1):22, 2026
Chongjun Tu, Peng Ye, Dongzhan Zhou, Lei Bai, Gang Yu, Tao Chen, and Wanli Ouyang. Attention reallocation: Towards zero-cost and controllable hallucination mitigation of mllms.International Journal of Computer Vision, 134(1):22, 2026
2026
-
[32]
Vasparse: Towards efficient visual hallucination mitigation via visual-aware token sparsification
Xianwei Zhuang, Zhihong Zhu, Yuxin Xie, Liming Liang, and Yuexian Zou. Vasparse: Towards efficient visual hallucination mitigation via visual-aware token sparsification. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4189–4199, 2025
2025
-
[33]
Bingqi Shang, Yiwei Chen, Yihua Zhang, Bingquan Shen, and Sijia Liu. Forgetting to forget: Attention sink as a gateway for backdooring llm unlearning.arXiv preprint arXiv:2510.17021, 2025
-
[34]
Interpreting the repeated token phenomenon in large language models
Itay Yona, Ilia Shumailov, Jamie Hayes, Federico Barbero, and Yossi Gandelsman. Interpreting the repeated token phenomenon in large language models. InForty-second International Conference on Machine Learning, 2025
2025
-
[35]
Leveraging registers in vision trans- formers for robust adaptation
Srikar Yellapragada, Kowshik Thopalli, Vivek Narayanaswamy, Wesam Sakla, Yang Liu, Yamen Mubarka, Dimitris Samaras, and Jayaraman J Thiagarajan. Leveraging registers in vision trans- formers for robust adaptation. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[36]
Nosa: Native and offloadable sparse attention.arXiv preprint arXiv:2510.13602, 2025
Yuxiang Huang, Chaojun Xiao, Xu Han, and Zhiyuan Liu. Nosa: Native and offloadable sparse attention.arXiv preprint arXiv:2510.13602, 2025
-
[37]
Yuzhe Gu, Xiyu Liang, Jiaojiao Zhao, and Enmao Diao. Obcache: Optimal brain kv cache pruning for efficient long-context llm inference.arXiv preprint arXiv:2510.07651, 2025
-
[38]
SALS: Sparse attention in latent space for KV cache compression
Junlin Mu, Hantao Huang, Jihang Zhang, Minghui Yu, Tao Wang, and Yidong Li. SALS: Sparse attention in latent space for KV cache compression. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[39]
OjaKV: Context-Aware Online Low-Rank KV Cache Compression
Yuxuan Zhu, David H Yang, Mohammad Mohammadi Amiri, Keerthiram Murugesan, Tejaswini Pedapati, and Pin-Yu Chen. Ojakv: Context-aware online low-rank kv cache compression with oja’s rule.arXiv preprint arXiv:2509.21623, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Umberto Cappellazzo, Stavros Petridis, Maja Pantic, et al. Mitigating attention sinks and massive activations in audio-visual speech recognition with llms.arXiv preprint arXiv:2510.22603, 2025. 84 Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
-
[41]
Attention sinks and compression valleys in llms are two sides of the same coin
Enrique Queipo-de Llano, Álvaro Arroyo, Federico Barbero, Xiaowen Dong, Michael Bronstein, Yann LeCun, and Ravid Shwartz-Ziv. Attention sinks and compression valleys in llms are two sides of the same coin. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[42]
Outlier-safe pre-training for robust 4-bit quantization of large language models
Jungwoo Park, Taewhoo Lee, Chanwoong Yoon, Hyeon Hwang, and Jaewoo Kang. Outlier-safe pre-training for robust 4-bit quantization of large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12582–12600, 2025
2025
-
[43]
Unveiling super experts in mixture-of-experts large language models
Zunhai Su, Qingyuan Li, Hao Zhang, Weihao Ye, Qibo Xue, YuLei Qian, Yuchen Xie, Ngai Wong, and Kehong Yuan. Unveiling super experts in mixture-of-experts large language models. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[44]
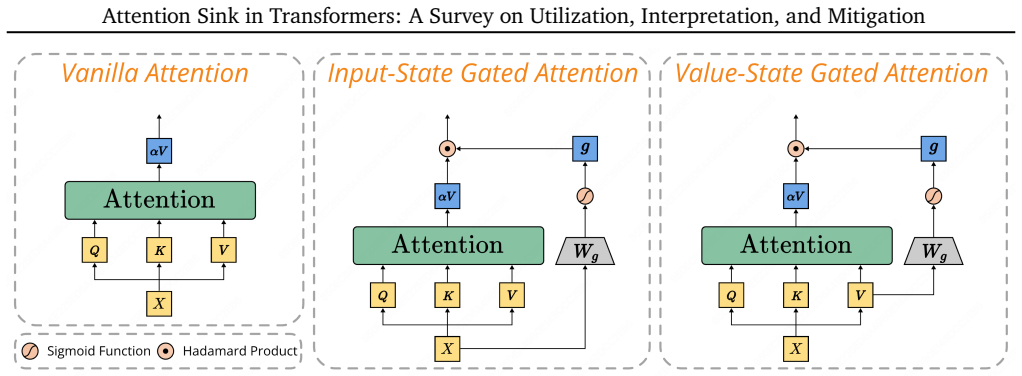
Rui Bu, Haofeng Zhong, Wenzheng Chen, and Yangyan Li. Value-state gated attention for mitigating extreme-token phenomena in transformers.arXiv preprint arXiv:2510.09017, 2025
-
[45]
Research and latest advancements, 2026
Qwen AI. Research and latest advancements, 2026. Accessed: 2026-01-22
2026
-
[46]
What are you sinking? a geometric approach on attention sink
Valeria Ruscio, Umberto Nanni, and Fabrizio Silvestri. What are you sinking? a geometric approach on attention sink. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[47]
Zixuan Li, Binzong Geng, Jing Xiong, Yong He, Yuxuan Hu, Jian Chen, Dingwei Chen, Xiyu Chang, Liang Zhang, Linjian Mo, et al. Ctr-sink: Attention sink for language models in click-through rate prediction.arXiv preprint arXiv:2508.03668, 2025
-
[48]
Does roberta perform better than bert in continual learning: An attention sink perspective
Xueying Bai, Yifan Sun, and Niranjan Balasubramanian. Does roberta perform better than bert in continual learning: An attention sink perspective. InFirst Conference on Language Modeling, 2025
2025
-
[49]
Outlier dimensions that disrupttransformersaredrivenbyfrequency
Giovanni Puccetti, Anna Rogers, Aleksandr Drozd, and Felice Dell’Orletta. Outlier dimensions that disrupttransformersaredrivenbyfrequency. InFindingsoftheAssociationforComputationalLinguistics: EMNLP 2022, pages 1286–1304, 2022
2022
-
[50]
Understanding and overcoming the challenges of efficient transformer quantization
Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. Understanding and overcoming the challenges of efficient transformer quantization. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7947–7969, 2021
2021
-
[51]
Bert busters: Outlier dimensions that disrupt transformers
Olga Kovaleva, Saurabh Kulshreshtha, Anna Rogers, and Anna Rumshisky. Bert busters: Outlier dimensions that disrupt transformers. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 3392–3405, 2021
2021
-
[52]
Positional artefacts propagate through masked language model embeddings
Ziyang Luo, Artur Kulmizev, and Xiaoxi Mao. Positional artefacts propagate through masked language model embeddings. InProceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 5312–5327, 2021
2021
-
[53]
What does bert look at? an analysis of bert’s attention
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D Manning. What does bert look at? an analysis of bert’s attention. InProceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 5312–5327, 2019
2019
-
[54]
MiMo-V2-Flash Technical Report
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026. 85 Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
work page internal anchor Pith review arXiv 2026
-
[55]
Zichuan Fu, Wentao Song, Guojing Li, Yejing Wang, Xian Wu, Yimin Deng, Hanyu Yan, Yefeng Zheng, and Xiangyu Zhao. Attention needs to focus: A unified perspective on attention allocation.arXiv preprint arXiv:2601.00919, 2026
-
[56]
On the existence and behaviour of secondary attention sinks.arXiv preprint arXiv:2512.22213, 2025
Jeffrey TH Wong, Cheng Zhang, Louis Mahon, Wayne Luk, Anton Isopoussu, and Yiren Zhao. On the existence and behaviour of secondary attention sinks.arXiv preprint arXiv:2512.22213, 2025
-
[57]
Sliding window attention adaptation
Yijiong Yu, Jiale Liu, Qingyun Wu, Huazheng Wang, and Ji Pei. Sliding window attention adaptation. arXiv preprint arXiv:2512.10411, 2025
-
[58]
Dope: Denoising rotary position embedding.arXiv preprint arXiv:2511.09146, 2025
Jing Xiong, Liyang Fan, Hui Shen, Zunhai Su, Min Yang, Lingpeng Kong, and Ngai Wong. Dope: Denoising rotary position embedding.arXiv preprint arXiv:2511.09146, 2025
-
[59]
Guang Liang, Jie Shao, Ningyuan Tang, Xinyao Liu, and Jianxin Wu. Tweo: Transformers without extreme outliers enables fp8 training and quantization for dummies.arXiv preprint arXiv:2511.23225, 2025
-
[60]
Nikolaus Salvatore, Hao Wang, and Qiong Zhang. Lost in the middle: An emergent property from information retrieval demands in llms.arXiv preprint arXiv:2510.10276, 2025
-
[61]
Hybrid Architectures for Language Models: Systematic Analysis and Design Insights
Sangmin Bae, Bilge Acun, Haroun Habeeb, Seungyeon Kim, Chien-Yu Lin, Liang Luo, Junjie Wang, and Carole-Jean Wu. Hybrid architectures for language models: Systematic analysis and design insights.arXiv preprint arXiv:2510.04800, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Cacheclip: Accelerating rag with effective kv cache reuse.arXiv preprint arXiv:2510.10129, 2025
Bin Yang, Qiuyu Leng, Jun Zeng, and Zhenhua Wu. Cacheclip: Accelerating rag with effective kv cache reuse.arXiv preprint arXiv:2510.10129, 2025
-
[63]
Yunhao Fang, Weihao Yu, Shu Zhong, Qinghao Ye, Xuehan Xiong, and Lai Wei. Artificial hippocampus networks for efficient long-context modeling.arXiv preprint arXiv:2510.07318, 2025
-
[64]
vattention: Verified sparse attention via sampling
Aditya Desai, Kumar Krishna Agrawal, Shuo Yang, Alejandro Cuadron, Luis Gaspar Schroeder, Matei Zaharia, Joseph E Gonzalez, and Ion Stoica. vattention: Verified sparse attention via sampling. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[65]
All for one: Llms solve mental math at the last token with information transferred from other tokens
Siddarth Mamidanna, Daking Rai, Ziyu Yao, and Yilun Zhou. All for one: Llms solve mental math at the last token with information transferred from other tokens. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30735–30748, 2025
2025
-
[66]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Integral transformer: Denoising attention, not too much not too little
Ivan Kobyzev, Abbas Ghaddar, Dingtao Hu, and Boxing Chen. Integral transformer: Denoising attention, not too much not too little. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2337–2354, 2025
2025
-
[68]
H2eal: Hybrid-bonding architecture with hybrid sparse attention for efficient long-context llm inference
Zizhuo Fu, Xiaotian Guo, Wenxuan Zeng, Shuzhang Zhong, Yadong Zhang, Peiyu Chen, Runsheng Wang, Le Ye, and Meng Li. H2eal: Hybrid-bonding architecture with hybrid sparse attention for efficient long-context llm inference. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD), pages 1–9. IEEE, 2025. 86 Attention Sink in Transformers: A ...
2025
-
[69]
Accelerating Prefilling via Decoding-time Contribution Sparsity
ZhiyuanHe,YikeZhang,ChengruidongZhang,HuiqiangJiang,YuqingYang,andLiliQiu. Trianglemix: Accelerating prefilling via decoding-time contribution sparsity.arXiv preprint arXiv:2507.21526, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Orthorank: Token selection via sink token orthogonality for efficient llm inference
Seungjun Shin, Jaehoon Oh, and Dokwan Oh. Orthorank: Token selection via sink token orthogonality for efficient llm inference. InForty-second International Conference on Machine Learning, 2025
2025
-
[71]
Earn: Efficient inference acceleration for llm-based generative recommendation by register tokens
Chaoqun Yang, Xinyu Lin, Wenjie Wang, Yongqi Li, Teng Sun, Xianjing Han, and Tat-Seng Chua. Earn: Efficient inference acceleration for llm-based generative recommendation by register tokens. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2, pages 3483–3494, 2025
2025
-
[72]
Jiawen Qi, Chang Gao, Zhaochun Ren, and Qinyu Chen. Deltallm: A training-free framework exploiting temporal sparsity for efficient edge llm inference.arXiv preprint arXiv:2507.19608, 2025
-
[73]
Hantao Yu and Josh Alman. Two heads are better than one: simulating large transformers with small ones.arXiv preprint arXiv:2506.12220, 2025
-
[74]
Feiyu Yao and Qian Wang. Learn from the past: Fast sparse indexing for large language model decoding.arXiv preprint arXiv:2506.15704, 2025
-
[75]
Zerotuning: Unlocking the initial token’s power to enhance large language models without training
Feijiang Han, Xiaodong Yu, Jianheng Tang, Delip Rao, Weihua Du, and Lyle Ungar. Zerotuning: Unlocking the initial token’s power to enhance large language models without training. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[76]
Jeffrey Willette, Heejun Lee, and Sung Ju Hwang. Delta attention: Fast and accurate sparse attention inference by delta correction.arXiv preprint arXiv:2505.11254, 2025
-
[77]
Softpick: No Attention Sink, No Massive Activations with Rectified Softmax
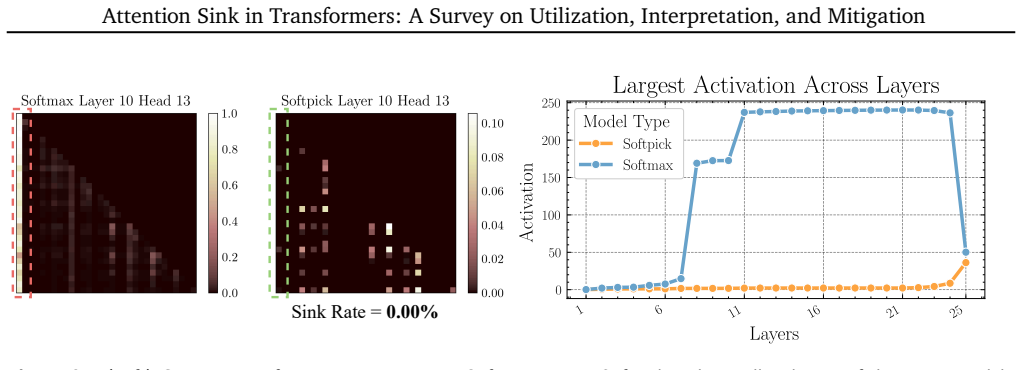
Zayd MK Zuhri, Erland Hilman Fuadi, and Alham Fikri Aji. Softpick: No attention sink, no massive activations with rectified softmax.arXiv preprint arXiv:2504.20966, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Keydiff: Key similarity-based kv cache eviction for long-context llm inference in resource-constrained environments
JunyoungPark, DaltonJones, MatthewJMorse, RaghavvGoel, MinguLee, andChrisLott. Keydiff: Key similarity-based kv cache eviction for long-context llm inference in resource-constrained environments. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[79]
Edgeinfinite: A memory-efficient infinite-context transformer for edge devices
Jiyu Chen, Shuang Peng, Daxiong Luo, Fan Yang, Renshou Wu, Fangyuan Li, and Xiaoxin Chen. Edgeinfinite: A memory-efficient infinite-context transformer for edge devices. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track), pages 568–575, 2025
2025
-
[80]
Efficient many-shot in-context learning with dynamic block-sparse attention
Emily Xiao, Chin-Jou Li, Yilin Zhang, Graham Neubig, and Amanda Bertsch. Efficient many-shot in-context learning with dynamic block-sparse attention. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.