Recognition: unknown
A Modularized Framework for Piecewise-Stationary Restless Bandits
Pith reviewed 2026-05-10 15:51 UTC · model grok-4.3
The pith
A modular framework lets any restless bandit algorithm adapt to unknown mean shifts with regret scaling as the square root of mixing time times segments times arms times horizon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed modular framework integrates an arbitrary RMAB base algorithm with a change detector and a diminishing exploration mechanism, achieving a regret bound of tilde O of the square root of L M K T under the refined regret notion that measures excess regret due to exploration and detection, benchmarked against an oracle that restarts at true change points.
What carries the argument
The modular integration of a base RMAB algorithm, a change detector, and diminishing exploration, which controls the exploration-detection delay trade-off while allowing black-box use of existing solvers.
If this is right
- Any existing RMAB solver can be dropped in without internal modification.
- The method requires no advance knowledge of the number or locations of mean shifts.
- Regret stays sublinear in the horizon even when the number of segments grows, as long as M remains small relative to T.
- Empirical performance approaches the segment-oracle benchmark in simulations.
Where Pith is reading between the lines
- The same wrapping technique could be tested on non-restless bandits or on problems with continuous state spaces.
- In deployed systems the framework would allow periodic swapping of the base solver without retuning the change-detection layer.
- The refined regret definition separates detection cost from ordinary exploration cost, which may help diagnose failures in other non-stationary settings.
Load-bearing premise
The analysis assumes that arbitrary RMAB base algorithms and change detectors can be integrated in a black-box manner and that all Markov chains possess a finite maximum mixing time L across segments.
What would settle it
A concrete instance using a valid base algorithm and detector where the observed refined regret grows faster than the square root of L M K T, or a Markov chain whose mixing time grows without bound and produces linear regret.
Figures



read the original abstract
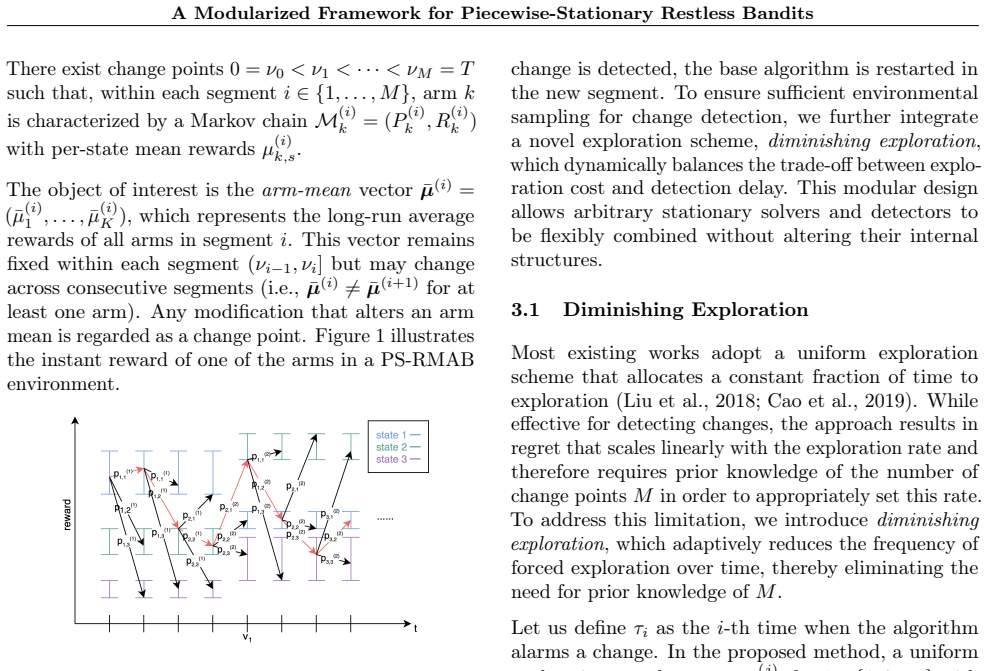
We study the piecewise-stationary restless multi-armed bandit (PS-RMAB) problem, where each arm evolves as a Markov chain but \emph{mean rewards may change across unknown segments}. To address the resulting exploration--detection delay trade-off, we propose a modular framework that integrates arbitrary RMAB base algorithms with change detection and a novel diminishing exploration mechanism. This design enables flexible plug-and-play use of existing solvers and detectors, while efficiently adapting to mean changes without prior knowledge of their number. To evaluate performance, we introduce a refined regret notion that measures the \emph{excess regret due to exploration and detection}, benchmarked against an oracle that restarts the base algorithm at the true change points. Under this metric, we prove a regret bound of $\tilde{O}(\sqrt{LMKT})$, where $L$ denotes the maximum mixing time of the Markov chains across all arms and segments, $M$ the number of segments, $K$ the number of arms, and $T$ the horizon. Simulations confirm that our framework achieves regret close to that of the segment oracle and consistently outperforms base solvers that do not incorporate any mechanism to handle environmental changes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the piecewise-stationary restless multi-armed bandit (PS-RMAB) setting in which each arm is a Markov chain whose mean reward changes across an unknown number of segments. It proposes a modular framework that combines any existing RMAB base algorithm with a change detector and a diminishing-exploration schedule. Performance is measured by a refined regret that isolates the excess cost of exploration and detection relative to an oracle that restarts the base algorithm at the true change points. The central theoretical result is a Õ(√(L M K T)) bound on this refined regret, where L is the uniform maximum mixing time, M the number of segments, K the number of arms, and T the horizon. Simulations are reported to show that the framework nearly matches the oracle and outperforms non-adaptive baselines.
Significance. If the modular construction and bound hold under the stated assumptions, the work supplies a practical plug-and-play method for adapting existing RMAB solvers to non-stationary environments while preserving a clean, interpretable regret guarantee. The refined regret metric usefully separates adaptation cost from the inherent difficulty of the stationary segments. The dependence on natural parameters L, M, K, T is reasonable, and the empirical results provide supporting evidence of near-oracle performance.
major comments (2)
- [Framework description and main theorem] The abstract and framework description assert that arbitrary RMAB base algorithms and change detectors can be integrated in a black-box manner. However, the Õ(√(L M K T)) refined-regret bound is load-bearing only if the base algorithm itself delivers sublinear regret on each stationary segment (otherwise the oracle benchmark incurs linear regret and the excess term is meaningless) and if the detector satisfies controlled false-alarm and detection-delay probabilities. These requirements on the black-box components are not explicitly listed as assumptions in the problem statement or theorem, yet they are necessary for the concentration arguments that rely on the uniform mixing time L.
- [Assumptions and proof outline] The analysis uses a single finite mixing time L that is assumed to hold uniformly across all arms and all segments. If any segment violates this (i.e., has mixing time > L), the deviation bounds employed both for change detection and for the diminishing-exploration schedule cease to hold. This assumption should be stated explicitly as part of the problem class rather than left implicit.
minor comments (2)
- [Simulation section] The abstract states that simulations confirm near-oracle performance but supplies no information on the number of independent runs, error-bar computation, specific base algorithms and detectors tested, or how post-hoc parameter choices were avoided. These details are needed for reproducibility.
- [Notation and preliminaries] Notation for L, M, K, T and the refined regret should be introduced with a single clear definition early in the paper rather than scattered across sections.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address each major comment below and will revise the manuscript to make the necessary assumptions explicit while preserving the modular framework.
read point-by-point responses
-
Referee: [Framework description and main theorem] The abstract and framework description assert that arbitrary RMAB base algorithms and change detectors can be integrated in a black-box manner. However, the Õ(√(L M K T)) refined-regret bound is load-bearing only if the base algorithm itself delivers sublinear regret on each stationary segment (otherwise the oracle benchmark incurs linear regret and the excess term is meaningless) and if the detector satisfies controlled false-alarm and detection-delay probabilities. These requirements on the black-box components are not explicitly listed as assumptions in the problem statement or theorem, yet they are necessary for the concentration arguments that rely on the uniform mixing time L.
Authors: We agree that the sublinear-regret property of the base algorithm and the controlled error probabilities of the detector are essential for the refined-regret bound and should be stated explicitly rather than left implicit. The framework remains modular in the sense that any base algorithm or detector meeting these standard conditions can be plugged in, but the theorem statement and abstract will be updated in revision to qualify the term 'arbitrary' accordingly and to list the two requirements as formal assumptions preceding the main result. revision: yes
-
Referee: [Assumptions and proof outline] The analysis uses a single finite mixing time L that is assumed to hold uniformly across all arms and all segments. If any segment violates this (i.e., has mixing time > L), the deviation bounds employed both for change detection and for the diminishing-exploration schedule cease to hold. This assumption should be stated explicitly as part of the problem class rather than left implicit.
Authors: We concur that the uniform upper bound L on mixing times must be stated explicitly as part of the problem class. Although the manuscript defines L as the maximum mixing time across arms and segments, we will add it as a numbered assumption in the problem formulation section of the revision and reference it clearly in the theorem statement and proof outline. revision: yes
Circularity Check
No significant circularity in modular regret derivation
full rationale
The paper introduces a refined regret metric explicitly benchmarked against an external oracle that restarts at true change points, then derives the bound Õ(√(LMKT)) from the modular construction under the finite mixing time L and black-box assumptions on base algorithms. No quoted equation or step reduces the final bound to a fitted parameter, self-citation chain, or input by construction; the result remains a standard concentration-based guarantee expressed in problem parameters. The modular claim carries implicit requirements on base solvers, but these are stated assumptions rather than a self-referential reduction, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption All Markov chains possess a finite maximum mixing time L across all arms and segments
- domain assumption The number of segments M is finite and unknown
Reference graph
Works this paper leans on
-
[1]
ISSN 0364765X, 15265471. URLhttp://www. jstor.org/stable/3690486. Keqin Liu and Qing Zhao. A restless bandit for- mulation of opportunistic access: Indexablity and index policy. In2008 5th IEEE Annual Communi- cations Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks Workshops, pages 1–5, 2008. doi: 10.1109/SAHCNW.2008.12. Aditya M...
-
[2]
Online Learning of Whittle Indices for Restless Bandits with Non-Stationary Transition Kernels
Springer International Publishing. ISBN 978-3- 319-67235-9. Yu-Pin Hsu. Age of information: Whittle index for scheduling stochastic arrivals. In2018 IEEE Inter- national Symposium on Information Theory (ISIT). IEEE, 2018. Sudipto Guha, Kamesh Munagala, and Peng Shi. Ap- proximation algorithms for restless bandit problems. Journal of the ACM (JACM), 58(1):...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
wX ℓ=1 f ′ k,ℓ(Vk,ℓ)− w 2 ≤ bd 2 # (88c) = 1−P
URLhttps://arxiv.org/abs/2405.00950. Levente Kocsis and Csaba Szepesvári. Discounted UCB. In2nd PASCAL Challenges Workshop, vol- ume 2, pages 51–134, 2006. Aurélien Garivier and Eric Moulines. On upper- confidence bound policies for switching bandit prob- lems. InProceedings of International Conference on Algorithmic Learning Theory (ALT), pages 174–188, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.