Recognition: unknown
Shuffling the Data, Stretching the Step-size: Sharper Bias in constant step-size SGD
Pith reviewed 2026-05-10 15:09 UTC · model grok-4.3
The pith
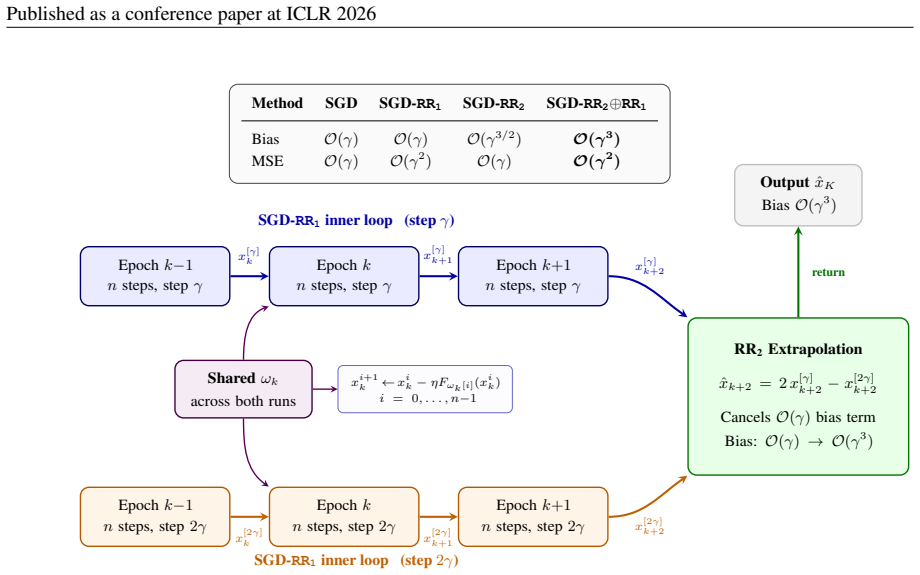
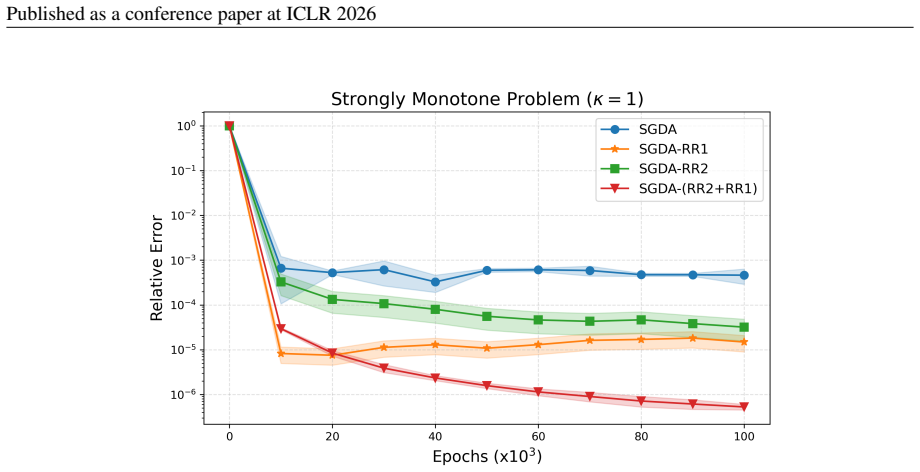
Combining random reshuffling with Richardson-Romberg extrapolation in constant-step SGD produces a cubic-order bias reduction while preserving the improved mean-squared error from shuffling alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In structured non-monotone variational inequalities, the composition of random reshuffling and Richardson-Romberg extrapolation applied to constant step-size stochastic gradient descent achieves a cubic refinement in bias while maintaining the enhanced mean-squared error guarantees of reshuffling. The analysis first smooths the discrete noise induced by reshuffling using continuous-state Markov chain tools to derive a law of large numbers and central limit theorem for the iterates, then employs spectral tensor techniques to prove that extrapolation further debiases and sharpens the asymptotic expansion even under the biased gradient oracle from reshuffling.
What carries the argument
The composition of random reshuffling (which smooths discrete noise via Markov chain analysis) and Richardson-Romberg extrapolation (which debiases via spectral tensor methods) applied to the iterates of constant step-size SGD.
Load-bearing premise
The problems belong to the class of structured non-monotone variational inequalities for which the discrete noise from reshuffling admits a continuous-state Markov chain smoothing that produces the stated law of large numbers and central limit theorem.
What would settle it
A numerical counter-example on a structured non-monotone VIP where the combined method fails to exhibit cubic bias reduction or loses the mean-squared error improvement shown by reshuffling alone.
Figures






read the original abstract
From adversarial robustness to multi-agent learning, many machine learning tasks can be cast as finite-sum min-max optimization or, more generally, as variational inequality problems (VIPs). Owing to their simplicity and scalability, stochastic gradient methods with constant step size are widely used, despite the fact that they converge only up to a constant term. Among the many heuristics adopted in practice, two classical techniques have recently attracted attention to mitigate this issue: \emph{Random Reshuffling} of data and \emph{Richardson--Romberg extrapolation} across iterates. Random Reshuffling sharpens the mean-squared error (MSE) of the estimated solution, while Richardson-Romberg extrapolation acts orthogonally, providing a second-order reduction in its bias. In this work, we show that their composition is strictly better than both, not only maintaining the enhanced MSE guarantees but also yielding an even greater cubic refinement in the bias. To the best of our knowledge, our work provides the first theoretical guarantees for such a synergy in structured non-monotone VIPs. Our analysis proceeds in two steps: (i) we smooth the discrete noise induced by reshuffling and leverage tools from continuous-state Markov chain theory to establish a novel law of large numbers and a central limit theorem for its iterates; and (ii) we employ spectral tensor techniques to prove that extrapolation debiases and sharpens the asymptotic behavior even under the biased gradient oracle induced by reshuffling. Finally, extensive experiments validate our theory, consistently demonstrating substantial speedups in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that composing random reshuffling of data with Richardson-Romberg extrapolation on constant step-size iterates yields strictly better performance than either technique alone for structured non-monotone variational inequality problems: it preserves the improved MSE from reshuffling while achieving an additional cubic-order bias refinement. The analysis proceeds in two steps—smoothing the discrete reshuffling noise into a continuous-state Markov chain to obtain a law of large numbers and central limit theorem, then applying spectral-tensor arguments to show that extrapolation debiases the resulting asymptotic expansion even under the biased reshuffled oracle—followed by experimental validation.
Significance. If the two-step argument is sound, the result would be a meaningful advance by supplying the first rigorous guarantees for the synergy of these heuristics in the non-monotone VIP setting, where standard monotonicity-based ergodicity arguments do not apply. The use of continuous-state Markov-chain tools for the reshuffling noise and spectral tensors for the bias expansion constitutes a technically interesting approach that could be reusable; the experimental section, if it reports concrete speed-ups on representative min-max problems, would further strengthen the practical relevance.
major comments (2)
- [Abstract (two-step proof strategy) and the Markov-chain analysis section] The headline cubic-refinement claim rests on the Markov-chain step producing a CLT whose asymptotic expansion is sufficiently regular for the spectral-tensor extrapolation to remove the cubic term. The abstract states only that the problems are “structured non-monotone VIPs,” yet provides no explicit Lyapunov function, uniform spectral gap, or mixing-rate bound that survives the lack of monotonicity. Without such a condition the CLT may hold only in a weaker topology, rendering the cubic term ill-defined or non-removable by extrapolation. This is load-bearing for the central claim.
- [Spectral-tensor debiasing section] The spectral-tensor argument in the second step assumes the bias expansion obtained from the reshuffled Markov chain is valid up to order three. If the mixing conditions required for that expansion are not verified under the stated “structured” assumption, the claimed cubic debiasing does not follow. A concrete counter-example or additional hypothesis that guarantees the required regularity should be supplied.
minor comments (2)
- [Experimental section] The abstract mentions “extensive experiments” but supplies no information on the concrete VIP instances, dimension, step-size schedules, or quantitative metrics (e.g., bias vs. iteration plots). Adding a table or figure with explicit MSE and bias values for the three methods (plain SGD, RR, RR+RRom) would make the validation reproducible.
- [Introduction / Preliminaries] The precise definition of “structured non-monotone VIP” (e.g., the form of the operator and the noise model) should be stated in the introduction or preliminaries rather than deferred, as it is the only assumption used to justify the Markov-chain smoothing.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the two major comments below, clarifying the role of the structured assumption in guaranteeing the required regularity and indicating the revisions we will make to improve transparency.
read point-by-point responses
-
Referee: [Abstract (two-step proof strategy) and the Markov-chain analysis section] The headline cubic-refinement claim rests on the Markov-chain step producing a CLT whose asymptotic expansion is sufficiently regular for the spectral-tensor extrapolation to remove the cubic term. The abstract states only that the problems are “structured non-monotone VIPs,” yet provides no explicit Lyapunov function, uniform spectral gap, or mixing-rate bound that survives the lack of monotonicity. Without such a condition the CLT may hold only in a weaker topology, rendering the cubic term ill-defined or non-removable by extrapolation. This is load-bearing for the central claim.
Authors: We agree that the regularity of the CLT is essential for the subsequent cubic debiasing. The structured assumption (Assumption 2.3) is designed to ensure the existence of a Lyapunov function and uniform spectral gap for the reshuffled continuous-state Markov chain, even without monotonicity; this is used to derive the mixing-rate bound in Lemma 3.2 and the CLT in Theorem 3.3. To make the dependence explicit, we will revise the abstract and add a short remark after Assumption 2.3 that directly links the structure to the Lyapunov function and spectral gap employed in the Markov-chain analysis. revision: partial
-
Referee: [Spectral-tensor debiasing section] The spectral-tensor argument in the second step assumes the bias expansion obtained from the reshuffled Markov chain is valid up to order three. If the mixing conditions required for that expansion are not verified under the stated “structured” assumption, the claimed cubic debiasing does not follow. A concrete counter-example or additional hypothesis that guarantees the required regularity should be supplied.
Authors: The bias expansion up to cubic order is obtained from the CLT under the structured assumption, which supplies the higher-moment bounds and regularity needed for the spectral-tensor argument (Theorem 4.1). We do not provide a counter-example because the structured non-monotone setting is chosen precisely to satisfy these conditions. We will add a brief paragraph in Section 4 that verifies the mixing conditions under Assumption 2.3 and explains why they suffice for the order-three expansion. revision: partial
Circularity Check
No circularity; derivation applies external Markov-chain and spectral tools
full rationale
The paper derives its LLN/CLT for reshuffled iterates by smoothing discrete noise into a continuous-state Markov chain and then applies spectral-tensor analysis to obtain the cubic bias refinement under Richardson-Romberg extrapolation. These steps invoke standard external theory (Markov-chain ergodic theorems, central-limit results, and tensor-based asymptotic expansions) rather than re-deriving any quantity from a fitted parameter, self-defined ansatz, or self-citation chain. No equation or claim in the provided abstract reduces by construction to its own inputs; the central synergy result therefore rests on independent analytic content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On a perturbation approach for the analysis of stochastic tracking algorithms
Rafik Aguech, Eric Moulines, and Pierre Priouret. On a perturbation approach for the analysis of stochastic tracking algorithms. SIAM Journal on Control and Optimization, 39 0 (3): 0 872--899, 2000
2000
-
[2]
Sgd with shuffling: optimal rates without component convexity and large epoch requirements
Kwangjun Ahn, Chulhee Yun, and Suvrit Sra. Sgd with shuffling: optimal rates without component convexity and large epoch requirements. In NeurIPS, 2020
2020
-
[3]
Computing the bias of constant-step stochastic approximation with markovian noise
Sebastian Allmeier and Nicolas Gast. Computing the bias of constant-step stochastic approximation with markovian noise. Advances in Neural Information Processing Systems, 37: 0 137873--137902, 2024
2024
-
[4]
Adagrad avoids saddle points
Kimon Antonakopoulos, Panayotis Mertikopoulos, Georgios Piliouras, and Xiao Wang. Adagrad avoids saddle points. In International Conference on Machine Learning, pp.\ 731--771. PMLR, 2022
2022
-
[5]
Wasserstein generative adversarial networks
Martin Arjovsky, Soumith Chintala, and L \'e on Bottou. Wasserstein generative adversarial networks. In ICML, 2017
2017
-
[6]
What is the long-run distribution of stochastic gradient descent? a large deviations analysis
Wa \" ss Azizian, Franck Iutzeler, J \'e r \^o me Malick, and Panayotis Mertikopoulos. What is the long-run distribution of stochastic gradient descent? a large deviations analysis. arXiv preprint arXiv:2406.09241, 2024
-
[7]
The law of the euler scheme for stochastic differential equations: I
Vlad Bally and Denis Talay. The law of the euler scheme for stochastic differential equations: I. convergence rate of the distribution function. Probability theory and related fields, 104 0 (1): 0 43--60, 1996
1996
-
[8]
Convex analysis and monotone operator theory in hilbert spaces, 2011 springer
HH Bauschke and PL Combettes. Convex analysis and monotone operator theory in hilbert spaces, 2011 springer. New York, 2017
2011
-
[9]
A dynamical system approach to stochastic approximations
Michel Benaim. A dynamical system approach to stochastic approximations. SIAM Journal on Control and Optimization, 34 0 (2): 0 437--472, 1996
1996
-
[10]
Dynamics of stochastic approximation algorithms
Michel Bena \" m. Dynamics of stochastic approximation algorithms. In Seminaire de probabilites XXXIII, pp.\ 1--68. Springer, 2006
2006
-
[11]
Dynamics of morse-smale urn processes
Michel Bena \" m and Morris W Hirsch. Dynamics of morse-smale urn processes. Ergodic Theory and Dynamical Systems, 15 0 (6): 0 1005--1030, 1995
1995
-
[12]
Practical Recommendations for Gradient-Based Training of Deep Architectures
Yoshua Bengio. Practical Recommendations for Gradient-Based Training of Deep Architectures . Neural Networks: Tricks of the Trade, pp.\ 437–478, 2012. ISSN 1611-3349. doi:10.1007/978-3-642-35289-8_26
-
[13]
Bertsekas
Dimitri P. Bertsekas. Incremental Gradient, Subgradient, and Proximal Methods for Convex Optimization: A Survey . In Suvrit Sra, Sebastan Nowozin, and Stephen J. Wright (eds.), Optimization for Machine Learning, chapter 4. The MIT Press, 2011. ISBN 9780262298773
2011
-
[14]
Dimitri P. Bertsekas and John N. Tsitsiklis. Gradient Convergence in Gradient methods with Errors . SIAM Journal on Optimization , 10 0 (3): 0 627--642, January 2000 a . doi:10.1137/s1052623497331063
-
[15]
Gradient convergence in gradient methods with errors
Dimitri P Bertsekas and John N Tsitsiklis. Gradient convergence in gradient methods with errors. SIAM Journal on Optimization, 10 0 (3): 0 627--642, 2000 b
2000
-
[16]
Curiously fast convergence of some stochastic gradient descent algorithms
L\' e on Bottou. Curiously fast convergence of some stochastic gradient descent algorithms. Unpublished open problem offered to the attendance of the SLDS 2009 conference, 2009. URL http://leon.bottou.org/papers/bottou-slds-open-problem-2009
2009
-
[17]
Stochastic gradient descent tricks
L \'e on Bottou. Stochastic gradient descent tricks. In Neural Networks, 2012 a
2012
-
[18]
Stochastic gradient descent tricks
L \'e on Bottou. Stochastic gradient descent tricks. In Neural networks: tricks of the trade: second edition, pp.\ 421--436. Springer, 2012 b
2012
-
[19]
Optimization methods for large-scale machine learning
L \'e on Bottou, Frank E Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning. SIAM review, 60 0 (2): 0 223--311, 2018
2018
-
[20]
Les algorithmes stochastiques contournent-ils les pieges? In Annales de l'IHP Probabilit \'e s et statistiques , volume 32, pp.\ 395--427, 1996
Odile Brandi \`e re and Marie Duflo. Les algorithmes stochastiques contournent-ils les pieges? In Annales de l'IHP Probabilit \'e s et statistiques , volume 32, pp.\ 395--427, 1996
1996
-
[21]
Sampling from a log-concave distribution with compact support with proximal langevin monte carlo
Nicolas Brosse, Alain Durmus, \'E ric Moulines, and Marcelo Pereyra. Sampling from a log-concave distribution with compact support with proximal langevin monte carlo. In Conference on learning theory, pp.\ 319--342. PMLR, 2017
2017
-
[22]
Sampling from a log-concave distribution with projected langevin monte carlo
S \'e bastien Bubeck, Ronen Eldan, and Joseph Lehec. Sampling from a log-concave distribution with projected langevin monte carlo. Discrete & Computational Geometry, 59 0 (4): 0 757--783, 2018
2018
-
[23]
Robust multi-agent reinforcement learning via adversarial regularization: Theoretical foundation and stable algorithms
Alexander Bukharin et al. Robust multi-agent reinforcement learning via adversarial regularization: Theoretical foundation and stable algorithms. In Advances in Neural Information Processing Systems (NeurIPS), volume 36, pp.\ 68121--68133, 2023
2023
-
[24]
Empirical risk minimization with shuffled sgd: A primal-dual perspective and improved bounds
Xufeng Cai, Cheuk Yin Lin, and Jelena Diakonikolas. Empirical risk minimization with shuffled sgd: A primal-dual perspective and improved bounds. arXiv:2306.12498, 2023
-
[25]
Convergence diagnostics for stochastic gradient descent with constant learning rate
Jerry Chee and Panos Toulis. Convergence diagnostics for stochastic gradient descent with constant learning rate. In International Conference on Artificial Intelligence and Statistics, pp.\ 1476--1485. PMLR, 2018
2018
-
[26]
Convergence rates in forward--backward splitting
George HG Chen and R Tyrrell Rockafellar. Convergence rates in forward--backward splitting. SIAM Journal on Optimization, 7 0 (2): 0 421--444, 1997
1997
-
[27]
Xiang Cheng, Niladri S Chatterji, Yasin Abbasi-Yadkori, Peter L Bartlett, and Michael I Jordan. Sharp convergence rates for langevin dynamics in the nonconvex setting. arXiv preprint arXiv:1805.01648, 2018 a
-
[28]
Underdamped langevin mcmc: A non-asymptotic analysis
Xiang Cheng, Niladri S Chatterji, Peter L Bartlett, and Michael I Jordan. Underdamped langevin mcmc: A non-asymptotic analysis. In Conference on learning theory, pp.\ 300--323. PMLR, 2018 b
2018
-
[29]
SGDA with shuffling: faster convergence for nonconvex-p minimax optimization
Hanseul Cho and Chulhee Yun. SGDA with shuffling: faster convergence for nonconvex-p minimax optimization. In ICLR, 2023
2023
-
[30]
Single-call stochastic extragradient methods for structured non-monotone variational inequalities: Improved analysis under weaker conditions
Sayantan Choudhury, Eduard Gorbunov, and Nicolas Loizou. Single-call stochastic extragradient methods for structured non-monotone variational inequalities: Improved analysis under weaker conditions. In NeurIPS, 2023
2023
-
[31]
On a stochastic approximation method
Kai Lai Chung. On a stochastic approximation method. The Annals of Mathematical Statistics, pp.\ 463--483, 1954
1954
-
[32]
Theoretical guarantees for approximate sampling from smooth and log-concave densities
Arnak S Dalalyan. Theoretical guarantees for approximate sampling from smooth and log-concave densities. Journal of the Royal Statistical Society Series B: Statistical Methodology, 79 0 (3): 0 651--676, 2017
2017
-
[33]
User-friendly guarantees for the langevin monte carlo with inaccurate gradient
Arnak S Dalalyan and Avetik Karagulyan. User-friendly guarantees for the langevin monte carlo with inaccurate gradient. Stochastic Processes and their Applications, 129 0 (12): 0 5278--5311, 2019
2019
-
[34]
On sampling from a log-concave density using kinetic langevin diffusions
Arnak S Dalalyan and Lionel Riou-Durand. On sampling from a log-concave density using kinetic langevin diffusions. 2020
2020
-
[35]
Complementary pivot theory of
George B Dantzig and RW Cottle. Complementary pivot theory of. mathematical programming. Mathematics of the decision sciences, part, 1: 0 115--136, 1968
1968
-
[36]
Sampling without replacement leads to faster rates in finite-sum minimax optimization
Aniket Das, Bernhard Sch \"o lkopf, and Michael Muehlebach. Sampling without replacement leads to faster rates in finite-sum minimax optimization. In NeurIPS, 2022
2022
-
[37]
Constantinos Daskalakis, Andrew Ilyas, Vasilis Syrgkanis, and Haoyang Zeng. Training gans with optimism. arXiv preprint arXiv:1711.00141, 2017
-
[38]
The complexity of constrained min-max optimization
Constantinos Daskalakis, Stratis Skoulakis, and Manolis Zampetakis. The complexity of constrained min-max optimization. In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, pp.\ 1466--1478, 2021
2021
-
[39]
Bridging the gap between constant step size stochastic gradient descent and markov chains
Aymeric Dieuleveut, Alain Durmus, and Francis Bach. Bridging the gap between constant step size stochastic gradient descent and markov chains. 2020
2020
-
[40]
The Complexity of Finding Stationary Points with Stochastic Gradient Descent
Yoel Drori and Ohad Shamir. The Complexity of Finding Stationary Points with Stochastic Gradient Descent . arXiv preprint arXiv:1910.01845, 2019
-
[41]
Gradient descent finds global minima of deep neural networks
Simon Du, Jason Lee, Haochuan Li, Liwei Wang, and Xiyu Zhai. Gradient descent finds global minima of deep neural networks. In International conference on machine learning, pp.\ 1675--1685. PMLR, 2019
2019
-
[42]
Nonasymptotic convergence analysis for the unadjusted langevin algorithm
Alain Durmus and Eric Moulines. Nonasymptotic convergence analysis for the unadjusted langevin algorithm. 2017
2017
-
[43]
Stochastic gradient richardson-romberg markov chain monte carlo
Alain Durmus, Umut Simsekli, Eric Moulines, Roland Badeau, and Ga \"e l Richard. Stochastic gradient richardson-romberg markov chain monte carlo. Advances in neural information processing systems, 29, 2016
2016
-
[44]
Log-concave sampling: Metropolis-hastings algorithms are fast
Raaz Dwivedi, Yuansi Chen, Martin J Wainwright, and Bin Yu. Log-concave sampling: Metropolis-hastings algorithms are fast. Journal of Machine Learning Research, 20 0 (183): 0 1--42, 2019
2019
-
[45]
Stochastic extragradient with random reshuffling: Improved convergence for variational inequalities
Konstantinos Emmanouilidis, Ren \'e Vidal, and Nicolas Loizou. Stochastic extragradient with random reshuffling: Improved convergence for variational inequalities. In International Conference on Artificial Intelligence and Statistics, pp.\ 3682--3690. PMLR, 2024
2024
-
[46]
On the convergence of langevin monte carlo: The interplay between tail growth and smoothness
Murat A Erdogdu and Rasa Hosseinzadeh. On the convergence of langevin monte carlo: The interplay between tail growth and smoothness. In Conference on Learning Theory, pp.\ 1776--1822. PMLR, 2021
2021
-
[47]
Global non-convex optimization with discretized diffusions
Murat A Erdogdu, Lester Mackey, and Ohad Shamir. Global non-convex optimization with discretized diffusions. Advances in Neural Information Processing Systems, 31, 2018
2018
-
[48]
On asymptotic normality in stochastic approximation
Vaclav Fabian. On asymptotic normality in stochastic approximation. The Annals of Mathematical Statistics, pp.\ 1327--1332, 1968
1968
-
[49]
Finite-dimensional variational inequalities and complementarity problems
Francisco Facchinei and Jong-Shi Pang. Finite-dimensional variational inequalities and complementarity problems. Springer, 2003
2003
-
[50]
Online bootstrap confidence intervals for the stochastic gradient descent estimator
Yixin Fang, Jinfeng Xu, and Lei Yang. Online bootstrap confidence intervals for the stochastic gradient descent estimator. Journal of Machine Learning Research, 19 0 (78): 0 1--21, 2018
2018
-
[51]
Asymptotic behavior of a markovian stochastic algorithm with constant step
Jean-Claude Fort and Gilles Pages. Asymptotic behavior of a markovian stochastic algorithm with constant step. SIAM journal on control and optimization, 37 0 (5): 0 1456--1482, 1999
1999
-
[52]
On the convergence of policy gradient methods to nash equilibria in general stochastic games
Angeliki Giannou, Kyriakos Lotidis, Panayotis Mertikopoulos, and Emmanouil-Vasileios Vlatakis-Gkaragkounis. On the convergence of policy gradient methods to nash equilibria in general stochastic games. Advances in Neural Information Processing Systems, 35: 0 7128--7141, 2022
2022
-
[53]
Ppad-complete pure approximate nash equilibria in lipschitz games
Paul W Goldberg and Matthew Katzman. Ppad-complete pure approximate nash equilibria in lipschitz games. In International Symposium on Algorithmic Game Theory, pp.\ 169--186. Springer, 2022
2022
-
[54]
Goodfellow, J
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NeurIPS, 2014
2014
-
[55]
Extragradient method: O (1/k) last-iterate convergence for monotone variational inequalities and connections with cocoercivity
Eduard Gorbunov, Nicolas Loizou, and Gauthier Gidel. Extragradient method: O (1/k) last-iterate convergence for monotone variational inequalities and connections with cocoercivity. In AISTATS, 2022 a
2022
-
[56]
Last-iterate convergence of optimistic gradient method for monotone variational inequalities
Eduard Gorbunov, Adrien Taylor, and Gauthier Gidel. Last-iterate convergence of optimistic gradient method for monotone variational inequalities. In NeurIPS, 2022 b
2022
-
[57]
Sgd: General analysis and improved rates
Robert Mansel Gower, Nicolas Loizou, Xun Qian, Alibek Sailanbayev, Egor Shulgin, and Peter Richtarik. Sgd: General analysis and improved rates. In AISTATS, 2019
2019
-
[58]
A class of unconstrained minimization methods for neural network training
Luigi Grippo. A class of unconstrained minimization methods for neural network training . Optimization Methods and Software, 4 0 (2): 0 135--150, January 1994. doi:10.1080/10556789408805583
-
[59]
Mert G\" u rb\" u zbalaban, Asuman \" O zda g lar, and Pablo A. Parrilo. Why random reshuffling beats stochastic gradient descent . Mathematical Programming, Oct 2019. ISSN 1436-4646. doi:10.1007/s10107-019-01440-w
-
[60]
Why random reshuffling beats stochastic gradient descent
Mert G \"u rb \"u zbalaban, Asu Ozdaglar, and Pablo A Parrilo. Why random reshuffling beats stochastic gradient descent. Mathematical Programming, 186: 0 49--84, 2021
2021
-
[61]
Nonconvex-nonconcave min-max optimization on riemannian manifolds
Andi Han et al. Nonconvex-nonconcave min-max optimization on riemannian manifolds. Transactions on Machine Learning Research, 2023
2023
-
[62]
A gradient descent method for solving a system of nonlinear equations
Wenrui Hao. A gradient descent method for solving a system of nonlinear equations. Applied Mathematics Letters, 112: 0 106739, 2021
2021
-
[63]
Random Shuffling Beats SGD after Finite Epochs
Jeff Haochen and Suvrit Sra. Random Shuffling Beats SGD after Finite Epochs . In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp.\ 2624--2633, Long Beach, California, USA, 09--15 Jun 2019. PMLR
2019
-
[64]
Introduction to numerical analysis
Francis Begnaud Hildebrand. Introduction to numerical analysis. Courier Corporation, 1987
1987
-
[65]
The limits of min-max optimization algorithms: Convergence to spurious non-critical sets
Ya-Ping Hsieh, Panayotis Mertikopoulos, and Volkan Cevher. The limits of min-max optimization algorithms: Convergence to spurious non-critical sets. In International Conference on Machine Learning, pp.\ 4337--4348. PMLR, 2021
2021
-
[66]
Riemannian stochastic optimization methods avoid strict saddle points
Ya-Ping Hsieh, Mohammad Reza Karimi Jaghargh, Andreas Krause, and Panayotis Mertikopoulos. Riemannian stochastic optimization methods avoid strict saddle points. Advances in Neural Information Processing Systems, 36: 0 29580--29601, 2023
2023
-
[67]
On the convergence of single-call stochastic extra-gradient methods
Yu-Guan Hsieh, Franck Iutzeler, J \'e r \^o me Malick, and Panayotis Mertikopoulos. On the convergence of single-call stochastic extra-gradient methods. In NeurIPS, 2019
2019
-
[68]
Bias and extrapolation in markovian linear stochastic approximation with constant stepsizes
Dongyan Huo, Yudong Chen, and Qiaomin Xie. Bias and extrapolation in markovian linear stochastic approximation with constant stepsizes. In Abstract Proceedings of the 2023 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, pp.\ 81--82, 2023
2023
-
[69]
The linear complementarity problem, lemke algorithm, perturbation, and the complexity class ppad
UC IEOR. The linear complementarity problem, lemke algorithm, perturbation, and the complexity class ppad. 2011
2011
-
[70]
Chi Jin, Praneeth Netrapalli, and Michael I. Jordan. What is local optimality in nonconvex-nonconcave minimax optimization? In Proceedings of the 37th International Conference on Machine Learning (ICML), PMLR, 2020
2020
-
[71]
The variational formulation of the fokker--planck equation
Richard Jordan, David Kinderlehrer, and Felix Otto. The variational formulation of the fokker--planck equation. SIAM journal on mathematical analysis, 29 0 (1): 0 1--17, 1998
1998
-
[72]
Stochastic estimation of the maximum of a regression function
Jack Kiefer and Jacob Wolfowitz. Stochastic estimation of the maximum of a regression function. The Annals of Mathematical Statistics, pp.\ 462--466, 1952
1952
-
[73]
Random perturbations of dynamical systems
Yuri Kifer. Random perturbations of dynamical systems. Nonlinear Problems in Future Particle Accelerators, 189, 1988
1988
-
[74]
Semi-implicit hybrid gradient methods with application to adversarial robustness
Beomsu Kim and Junghoon Seo. Semi-implicit hybrid gradient methods with application to adversarial robustness. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), PMLR, 2022
2022
-
[75]
The extragradient method for finding saddle points and other problems
Galina M Korpelevich. The extragradient method for finding saddle points and other problems. Matecon, 12: 0 747--756, 1976
1976
-
[76]
Two-timescale linear stochastic approximation: Constant stepsizes go a long way
Jeongyeol Kwon, Luke Dotson, Yudong Chen, and Qiaomin Xie. Two-timescale linear stochastic approximation: Constant stepsizes go a long way. arXiv preprint arXiv:2410.13067, 2024
-
[77]
Recht-R\' e Noncommutative Arithmetic-Geometric Mean Conjecture is False
Zehua Lai and Lek-Heng Lim. Recht-R\' e Noncommutative Arithmetic-Geometric Mean Conjecture is False . arXiv preprint arXiv:2006.01510, 2020
-
[78]
Stochastic runge-kutta accelerates langevin monte carlo and beyond
Xuechen Li, Yi Wu, Lester Mackey, and Murat A Erdogdu. Stochastic runge-kutta accelerates langevin monte carlo and beyond. Advances in neural information processing systems, 32, 2019
2019
-
[79]
Finite-time last-iterate convergence for multi-agent learning in games
Tianyi Lin, Zhengyuan Zhou, Panayotis Mertikopoulos, and Michael Jordan. Finite-time last-iterate convergence for multi-agent learning in games. In ICML, 2020
2020
-
[80]
Aiming towards the minimizers: fast convergence of sgd for overparametrized problems
Chaoyue Liu, Dmitriy Drusvyatskiy, Misha Belkin, Damek Davis, and Yian Ma. Aiming towards the minimizers: fast convergence of sgd for overparametrized problems. Advances in neural information processing systems, 36: 0 60748--60767, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.