Recognition: unknown
WaveMoE: A Wavelet-Enhanced Mixture-of-Experts Foundation Model for Time Series Forecasting
Pith reviewed 2026-05-10 15:38 UTC · model grok-4.3
The pith
WaveMoE processes time series and wavelet tokens together through shared mixture-of-experts routing to capture frequency patterns in forecasting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WaveMoE adopts a dual-path architecture that jointly processes time series tokens and wavelet tokens aligned along a unified temporal axis, and coordinates them through a shared expert routing mechanism that enables consistent expert specialization while efficiently scaling model capacity. This setup supplies explicit frequency-domain representations that help model periodicity and localized high-frequency dynamics prevalent in real-world series.
What carries the argument
Dual-path architecture with time series tokens and wavelet tokens aligned on a shared temporal axis and dispatched by the same mixture-of-experts router.
If this is right
- Explicit wavelet inputs allow the model to represent periodic and localized high-frequency structures more directly than time-domain tokens alone.
- Shared expert routing maintains specialization across domains while still permitting model capacity to grow.
- Adding wavelet-domain corpora to pretraining yields measurable forecasting improvements on diverse benchmarks.
- The approach avoids the need for separate frequency preprocessing pipelines by embedding the information inside the foundation model.
Where Pith is reading between the lines
- The same alignment-and-routing pattern could be tested with other frequency decompositions such as Fourier or empirical mode decomposition.
- Consistent cross-domain experts might reduce the data hunger of future time-series foundation models by letting one expert pool serve multiple signal representations.
- Long-horizon forecasts, where repeating cycles dominate, are a natural next test bed for the dual-path idea.
- If the gains hold, foundation-model designers may shift from purely learned embeddings toward explicit multi-domain token streams.
Load-bearing premise
Routing wavelet tokens through the identical experts as time tokens will produce consistent specialization and net forecasting gains rather than conflicting signals.
What would settle it
Retraining the identical model on the same 16 datasets but removing the wavelet path or breaking the temporal alignment and measuring no accuracy lift or a drop would falsify the claimed benefit of the dual-path design.
Figures



read the original abstract
Time series foundation models (TSFMs) have recently achieved remarkable success in universal forecasting by leveraging large-scale pretraining on diverse time series data. Complementing this progress, incorporating frequency-domain information yields promising performance in enhancing the modeling of complex temporal patterns, such as periodicity and localized high-frequency dynamics, which are prevalent in real-world time series. To advance this direction, we propose a new perspective that integrates explicit frequency-domain representations into scalable foundation models, and introduce WaveMoE, a wavelet-enhanced mixture-of-experts foundation model for time series forecasting. WaveMoE adopts a dual-path architecture that jointly processes time series tokens and wavelet tokens aligned along a unified temporal axis, and coordinates them through a shared expert routing mechanism that enables consistent expert specialization while efficiently scaling model capacity. Preliminary experimental results on 16 diverse benchmark datasets indicate that WaveMoE has the potential to further improve forecasting performance by incorporating wavelet-domain corpora.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WaveMoE, a wavelet-enhanced mixture-of-experts foundation model for time series forecasting. It proposes a dual-path architecture that jointly processes time-series tokens and wavelet tokens aligned along a unified temporal axis, coordinated via a shared expert routing mechanism intended to enable consistent expert specialization while scaling model capacity. The authors report that preliminary results on 16 diverse benchmark datasets indicate potential improvements in forecasting performance through the incorporation of wavelet-domain information.
Significance. If the empirical claims hold under rigorous evaluation, the work could advance time-series foundation models by providing a scalable mechanism to integrate explicit frequency-domain representations without separate model pathways. The shared-routing design for dual-domain tokens is a conceptually interesting approach to multi-scale temporal modeling that, if validated, might generalize beyond wavelets.
major comments (3)
- [Abstract] Abstract: The central claim that WaveMoE 'has the potential to further improve forecasting performance' rests on 'preliminary experimental results on 16 diverse benchmark datasets,' yet no quantitative metrics, baseline comparisons, ablation studies, error bars, or statistical tests are supplied. This absence leaves the performance contribution unsupported and directly undermines assessment of the architecture's value.
- [Methods] Methods (architecture description): The dual-path design asserts that wavelet tokens are 'aligned along a unified temporal axis' and routed through the same experts as time tokens, but no equations, pseudocode, or details are given for the wavelet decomposition, token projection, temporal alignment procedure, or the shared router formulation (e.g., gating function or expert activation). Without these, it is impossible to verify whether alignment preserves scale-specific information or whether shared routing produces coherent specialization rather than interference.
- [Experiments] Experiments: No details are provided on model scale, pretraining corpus, comparison models, or any analysis of expert routing behavior (e.g., activation histograms or specialization metrics across time vs. wavelet tokens). This omission makes the assertion of 'consistent expert specialization' and 'efficiently scaling model capacity' untestable from the manuscript.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly specified the wavelet transform (e.g., discrete wavelet transform family and decomposition levels) used to generate the wavelet tokens.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the current version of the manuscript requires substantial additions to support the claims and enable verification of the proposed architecture. We will perform a major revision to incorporate quantitative results, detailed methodological specifications, and experimental analyses as outlined below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that WaveMoE 'has the potential to further improve forecasting performance' rests on 'preliminary experimental results on 16 diverse benchmark datasets,' yet no quantitative metrics, baseline comparisons, ablation studies, error bars, or statistical tests are supplied. This absence leaves the performance contribution unsupported and directly undermines assessment of the architecture's value.
Authors: We agree that the abstract's reference to preliminary results is insufficient without supporting numbers. In the revision we will insert concise quantitative statements (e.g., average MSE reduction and win-rate against baselines across the 16 datasets) while directing readers to the expanded Experiments section for full tables, error bars, ablations, and significance tests. This keeps the abstract within length limits yet makes the performance claim verifiable. revision: yes
-
Referee: [Methods] Methods (architecture description): The dual-path design asserts that wavelet tokens are 'aligned along a unified temporal axis' and routed through the same experts as time tokens, but no equations, pseudocode, or details are given for the wavelet decomposition, token projection, temporal alignment procedure, or the shared router formulation (e.g., gating function or expert activation). Without these, it is impossible to verify whether alignment preserves scale-specific information or whether shared routing produces coherent specialization rather than interference.
Authors: We acknowledge the omission of formal specifications. The revised Methods section will include: (1) the exact discrete wavelet transform equations and chosen mother wavelets, (2) linear projection layers that map wavelet coefficients to tokens, (3) the temporal alignment procedure (zero-padding and linear interpolation to a common sequence length), and (4) the shared router formulation (top-k gating function with auxiliary load-balancing loss). Pseudocode for the dual-path forward pass will be added as an algorithm box to demonstrate preservation of scale information and routing behavior. revision: yes
-
Referee: [Experiments] Experiments: No details are provided on model scale, pretraining corpus, comparison models, or any analysis of expert routing behavior (e.g., activation histograms or specialization metrics across time vs. wavelet tokens). This omission makes the assertion of 'consistent expert specialization' and 'efficiently scaling model capacity' untestable from the manuscript.
Authors: We agree these details are essential. The revised manuscript will add an Experimental Setup subsection specifying model dimensions, number of experts, pretraining corpus size and sources, the full list of baselines, and quantitative routing analyses (activation histograms, specialization scores, and load metrics separated by token type). These additions will directly substantiate the claims of consistent specialization and scalable capacity. revision: yes
Circularity Check
No circularity: architectural proposal with external benchmark support
full rationale
The paper introduces WaveMoE as a dual-path MoE architecture that aligns wavelet tokens to the temporal axis of time-series tokens and routes both through shared experts. This is presented as a design choice whose value is assessed via empirical results on 16 external benchmarks rather than any closed-form derivation, fitted parameter renamed as prediction, or load-bearing self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked that reduce the claimed performance gains to the inputs by construction. The central claim therefore remains an independent architectural hypothesis.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Wavelet transforms can be aligned to the same temporal grid as raw time-series tokens without loss of information.
- ad hoc to paper Shared expert routing will produce consistent specialization across time and wavelet paths.
invented entities (1)
-
Wavelet tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Taha Aksu, Gerald Woo, Juncheng Liu, Xu Liu, Chenghao Liu, Silvio Savarese, Caiming Xiong, and Doyen Sahoo. Gift-eval: A benchmark for general time series forecasting model evaluation. arXiv preprint arXiv:2410.10393,
-
[2]
Chronos-2: From Univariate to Universal Forecasting
Abdul Fatir Ansari, Oleksandr Shchur, Jaris K ¨uken, Andreas Auer, Boran Han, Pedro Mercado, Syama Sundar Rangapuram, Huibin Shen, Lorenzo Stella, Xiyuan Zhang, et al. Chronos-2: From univariate to universal forecasting.arXiv preprint arXiv:2510.15821,
work page internal anchor Pith review arXiv
-
[3]
Toto: Time series optimized transformer for observability, 2024
Ben Cohen, Emaad Khwaja, Kan Wang, Charles Masson, Elise Ram ´e, Youssef Doubli, and Oth- mane Abou-Amal. Toto: Time series optimized transformer for observability.arXiv preprint arXiv:2407.07874,
-
[4]
Oats: Online data augmentation for time series foundation models.arXiv preprint arXiv:2601.19040,
Junwei Deng, Chang Xu, Jiaqi W Ma, Ming Jin, Chenghao Liu, and Jiang Bian. Oats: Online data augmentation for time series foundation models.arXiv preprint arXiv:2601.19040,
-
[5]
Kun Feng, Shaocheng Lan, Yuchen Fang, Wenchao He, Lintao Ma, Xingyu Lu, and Kan Ren. Kairos: Towards adaptive and generalizable time series foundation models.arXiv preprint arXiv:2509.25826,
work page internal anchor Pith review arXiv
-
[6]
Peiliang Gong, Emadeldeen Eldele, Min Wu, Zhenghua Chen, Xiaoli Li, and Daoqiang Zhang. Bridging distribution gaps in time series foundation model pretraining with prototype-guided nor- malization.arXiv preprint arXiv:2504.10900,
-
[7]
FlowState: Sampling Rate Invariant Time Series Forecasting
Lars Graf, Thomas Ortner, Stanis ´L Wo ´Ls ¸niak, Angeliki Pantazi, et al. Flowstate: Sampling rate invariant time series forecasting.arXiv preprint arXiv:2508.05287,
-
[8]
B., M ¨uller, S., Salinas, D., and Hutter, F
Shi Bin Hoo, Samuel M¨uller, David Salinas, and Frank Hutter. From tables to time: How tabpfn-v2 outperforms specialized time series forecasting models.arXiv preprint arXiv:2501.02945,
-
[9]
Lstm–transformer-based robust hybrid deep learning model for financial time series forecasting.Sci, 7(1):7,
6 ICLR 2026 Workshop on Time Series in the Age of Large Models (TSALM) Md R Kabir, Dipayan Bhadra, Moinul Ridoy, and Mariofanna Milanova. Lstm–transformer-based robust hybrid deep learning model for financial time series forecasting.Sci, 7(1):7,
2026
-
[10]
arXiv preprint arXiv:2511.11698 , year=
Chenghao Liu, Taha Aksu, Juncheng Liu, Xu Liu, Hanshu Yan, Quang Pham, Silvio Savarese, Doyen Sahoo, Caiming Xiong, and Junnan Li. Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025a. Mengna Liu, Dong Xiang, Xu Cheng, Xiufeng Liu, Dalin Zhang, Shengyong Chen, and Christian S Jensen. Disentangling imperfect: A w...
-
[11]
Timeexpert: Boosting long time series forecasting with temporal mix of experts
Xiaowen Ma, Shuning Ge, Fan Yang, Xiangyu Li, Yun Chen, Mengting Ma, Wei Zhang, and Zhipeng Liu. Timeexpert: Boosting long time series forecasting with temporal mix of experts. arXiv preprint arXiv:2509.23145,
-
[12]
N-beats: Neural ba- sis expansion analysis for interpretable time series forecasting
7 ICLR 2026 Workshop on Time Series in the Age of Large Models (TSALM) Boris N Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-beats: Neural ba- sis expansion analysis for interpretable time series forecasting. InInternational Conference on Learning Representations,
2026
-
[13]
Xue Wang, Tian Zhou, Jinyang Gao, Bolin Ding, and Jingren Zhou. Output scaling: Yinglong- delayed chain of thought in a large pretrained time series forecasting model.arXiv preprint arXiv:2506.11029,
-
[14]
Time- moe: Billion-scale time series foundation models with mixture of experts
Shi Xiaoming, Wang Shiyu, Nie Yuqi, Li Dianqi, Ye Zhou, Wen Qingsong, and Ming Jin. Time- moe: Billion-scale time series foundation models with mixture of experts. InICLR 2025: The Thirteenth International Conference on Learning Representations. International Conference on Learning Representations,
2025
-
[15]
Towards neural scaling laws for time series foundation models
Qingren Yao, Chao-Han Huck Yang, Renhe Jiang, Yuxuan Liang, Ming Jin, and Shirui Pan. Towards neural scaling laws for time series foundation models. InThe Thirteenth International Confer- ence on Learning Representations (ICLR 2025). International Conference on Learning Represen- tations,
2025
-
[16]
Ziyu Zhou, Jiaxi Hu, Qingsong Wen, James T Kwok, and Yuxuan Liang. Multi-order wavelet derivative transform for deep time series forecasting.arXiv preprint arXiv:2505.11781,
-
[17]
8 ICLR 2026 Workshop on Time Series in the Age of Large Models (TSALM) A PRETRAININGDATACONSTRUCTION A.1 DATASETCOMPOSITION ANDDOMAINCOVERAGE WaveMoE is pretrained on a large-scale dataset built upon the Time-300B corpus (Xiaoming et al., 2025). Specifically, the pretraining data are derived from the publicly available Time-300B dataset after domain balan...
2026
-
[18]
Missing-Value Handling.For windows that pass quality filtering, a unified missing-value handling strategy is applied
and ensure that retained windows exhibit sufficient temporal variation, preventing the model from learning trivial or static patterns. Missing-Value Handling.For windows that pass quality filtering, a unified missing-value handling strategy is applied. All NaN and Inf values are replaced with zero to ensure numerical stability. In addition, a correspondin...
2026
-
[19]
Performance is evaluated using Mean Squared Error (MSE) and Mean Absolute Error (MAE) for consistent comparison across models. Overall, the results on these additional benchmarks are consistent with the main experimental findings. WaveMoE achieves competitive or leading performance across the majority of datasets and maintains strong stability under diver...
-
[20]
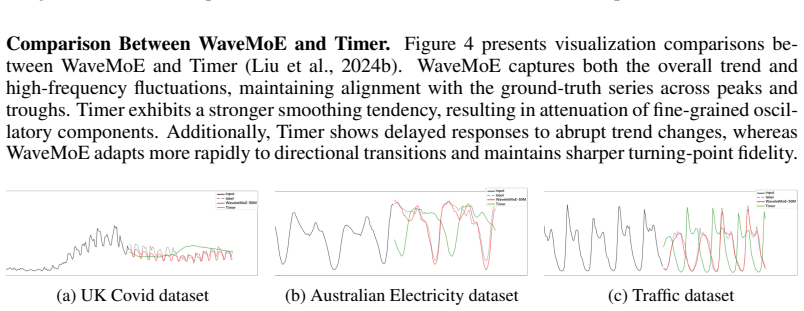
on example time series from three benchmark datasets. Overall, WaveMoE demonstrates closer alignment with the ground-truth series, partic- ularly in terms of peak and trough localization, amplitude reconstruction, and trend consistency. While Time-MoE generally captures the overall trajectory, noticeable deviations remain around ex- treme values. In cases...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.