Energy-Efficient Federated Edge Learning For Small-Scale Datasets in Large IoT Networks
Pith reviewed 2026-05-10 15:41 UTC · model grok-4.3
The pith
Deriving expected learning loss from sample counts enables a stochastic algorithm to optimize energy and performance in federated edge learning for small IoT datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that its collaborative optimization framework, starting with a derivation of expected learning loss tied to training sample numbers, followed by a stochastic online learning algorithm that adapts to data changes and a resource optimization formulation with convergence bound, solved via an online distributed algorithm, leads to significantly better learning performance and resource efficiency in large IoT networks handling small-scale datasets, as validated through simulations and autonomous navigation case studies involving collision avoidance.
What carries the argument
The expected learning loss derivation that connects the quantity of training samples to learning objectives, which supports formulating and solving the joint learning and resource optimization problem with convergence assurances.
If this is right
- Edge nodes collaborate on model training without sharing raw data, maintaining data privacy in IoT settings.
- Resource use decreases while maintaining or improving model accuracy for small datasets.
- The distributed algorithm ensures scalability for networks with many devices.
- Convergence remains assured even with varying data across the network.
- Real-world applications such as collision avoidance in navigation achieve better outcomes.
Where Pith is reading between the lines
- Extending this to dynamic network topologies could further improve adaptability in mobile IoT scenarios.
- Similar derivations might help in other machine learning paradigms where data is limited and distributed.
- Combining this with hardware-aware optimizations could yield additional energy savings in practice.
Load-bearing premise
The mathematical derivation of expected learning loss from the number of training samples accurately represents the performance impact of heterogeneous small-scale datasets, allowing the stochastic algorithm to operate without exceeding the convergence bound.
What would settle it
A direct test would be to implement the framework on a physical large-scale IoT testbed with small heterogeneous datasets and check whether the observed learning performance and energy consumption match the predicted improvements or if the convergence bound is violated.
Figures







read the original abstract
Large-scale Internet of Things (IoT) networks enable intelligent services such as smart cities and autonomous driving, but often face resource constraints. Collecting heterogeneous sensory data, especially in small-scale datasets, is challenging, and independent edge nodes can lead to inefficient resource utilization and reduced learning performance. To address these issues, this paper proposes a collaborative optimization framework for energy-efficient federated edge learning with small-scale datasets. We first derive an expected learning loss to quantify the relationship between the number of training samples and learning objectives. A stochastic online learning algorithm is then designed to adapt to data variations, and a resource optimization problem with a convergence bound is formulated. Finally, an online distributed algorithm efficiently solves large-scale optimization problems with high scalability. Extensive simulations and autonomous navigation case studies with collision avoidance demonstrate that the proposed approach significantly improves learning performance and resource efficiency compared to state-of-the-art benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a collaborative optimization framework for energy-efficient federated edge learning tailored to small-scale heterogeneous datasets in large IoT networks. It first derives an expected learning loss to relate the number of training samples to learning objectives, then designs a stochastic online learning algorithm to adapt to data variations. A resource optimization problem incorporating a convergence bound is formulated, which is solved via an online distributed algorithm claimed to offer high scalability. The approach is evaluated via extensive simulations and an autonomous navigation case study involving collision avoidance, with claims of significant improvements in learning performance and resource efficiency over state-of-the-art benchmarks.
Significance. If the expected-loss derivation and convergence-bound preservation hold under the stated conditions, and if the experimental gains are reproducible, the work could meaningfully advance practical federated learning deployments in resource-constrained IoT settings such as smart cities and autonomous systems. The emphasis on small-scale datasets and the inclusion of a concrete navigation case study with collision avoidance are strengths that enhance applicability beyond purely theoretical contributions.
major comments (2)
- [Section 3 (expected learning loss derivation)] The derivation of the expected learning loss (central to quantifying performance from training-sample counts) appears to rest on assumptions about data heterogeneity that may not generalize across distributed small-scale IoT nodes; without explicit statement of these assumptions or verification that the quantity remains non-self-referential, the subsequent resource-optimization step and convergence bound rest on shaky ground.
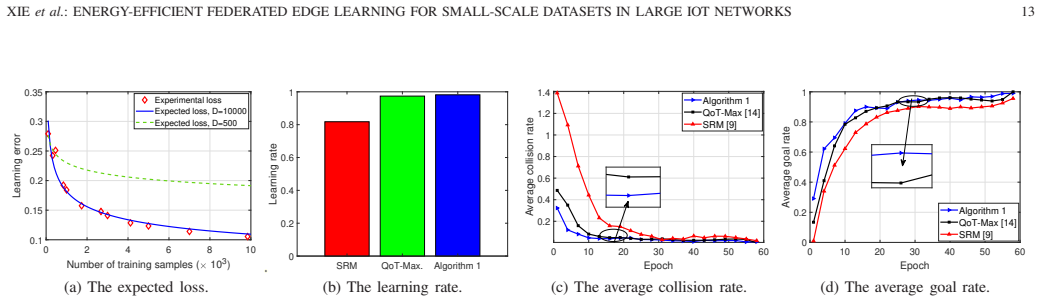
- [Section 5 (simulation results and case study)] The experimental claims of significant improvements (simulations and autonomous-navigation case study) are load-bearing for the paper's main contribution, yet no details are provided on the precise baselines, error bars, statistical significance tests, or exact hyper-parameter settings and data-partitioning schemes used; this prevents verification that the stochastic algorithm indeed adapts without violating the convergence bound.
minor comments (2)
- [Algorithm 1 and surrounding text] Notation for the convergence bound and the online distributed algorithm could be clarified with an explicit pseudocode listing and a table summarizing the key parameters and their roles.
- [Abstract] The abstract would benefit from one or two concrete quantitative improvement figures (e.g., percentage reduction in energy or latency) to give readers an immediate sense of the claimed gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas for improving clarity and reproducibility. We address each major comment below and will incorporate the necessary revisions in the updated manuscript.
read point-by-point responses
-
Referee: [Section 3 (expected learning loss derivation)] The derivation of the expected learning loss (central to quantifying performance from training-sample counts) appears to rest on assumptions about data heterogeneity that may not generalize across distributed small-scale IoT nodes; without explicit statement of these assumptions or verification that the quantity remains non-self-referential, the subsequent resource-optimization step and convergence bound rest on shaky ground.
Authors: We agree that the assumptions in the expected learning loss derivation should be stated explicitly to support generalizability across heterogeneous IoT nodes. In the revised manuscript, we will add a new paragraph in Section 3 that clearly lists the assumptions (bounded variance of local data distributions, finite second moments, and the small-scale dataset regime) and provides a short proof that the expected loss depends only on sample counts and instantaneous model parameters, with no circular dependence on the resource variables. This will directly support the validity of the subsequent optimization and convergence analysis. revision: yes
-
Referee: [Section 5 (simulation results and case study)] The experimental claims of significant improvements (simulations and autonomous-navigation case study) are load-bearing for the paper's main contribution, yet no details are provided on the precise baselines, error bars, statistical significance tests, or exact hyper-parameter settings and data-partitioning schemes used; this prevents verification that the stochastic algorithm indeed adapts without violating the convergence bound.
Authors: We concur that additional experimental details are required for reproducibility and to confirm that the stochastic algorithm respects the convergence bound. In the revised Section 5, we will include: explicit definitions of all baselines (FedAvg, local training, and energy-unaware variants); error bars from 10 independent runs with standard deviations; results of paired t-tests for statistical significance; complete hyper-parameter tables (learning rates, batch sizes, local epochs, and convergence thresholds); and precise descriptions of the data-partitioning scheme used for the small-scale heterogeneous datasets. We will also add a short analysis verifying that the observed adaptation does not violate the derived convergence bound. revision: yes
Circularity Check
No significant circularity; derivation remains independent of fitted inputs
full rationale
The abstract describes deriving an expected learning loss from training sample counts, then formulating a resource optimization problem with a convergence bound, followed by a stochastic algorithm and distributed solver. No equations or self-citations are provided that reduce the loss derivation or bound to a fitted parameter renamed as prediction, nor does any step invoke a self-citation chain or uniqueness theorem that collapses the central claim back to its inputs. The derivation chain is presented as proceeding from first-principles quantification to algorithmic solution without the self-referential reductions required for a positive circularity finding. This is the normal case for an optimization paper whose core steps (loss model, bound, solver) can be externally validated against standard federated learning theory.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Q. Duan, J. Huang, S. Hu, R. Deng, Z. Lu, and S. Y u, “Combini ng federated learning and edge computing toward ubiquitous in telligence in 6G network: Challenges, recent advances, and future direct ions,” IEEE Commun. Surv. Tutor ., vol. 25, no. 4, pp. 2892–2950, 2023
work page 2023
-
[2]
Robust federa ted learning for unreliable and resource-limited wireless networks,
Z. Chen, W. Yi, Y . Liu, and A. Nallanathan, “Robust federa ted learning for unreliable and resource-limited wireless networks,” IEEE Trans. Wireless Commun., vol. 23, no. 8, pp. 9793–9809, Feb. 2024
work page 2024
-
[3]
Dynamic schedul ing for over-the-air federated edge learning with energy constrai nts,
Y . Sun, S. Zhou, Z. Niu, and D. G¨ und¨ uz, “Dynamic schedul ing for over-the-air federated edge learning with energy constrai nts,” IEEE J. Sel. Areas Commun. , vol. 40, no. 1, pp. 227–242, Jan. 2022
work page 2022
-
[4]
E fficient federated meta-learning over multi-access wireless netwo rks,
S. Y ue, J. Ren, J. Xin, D. Zhang, Y . Zhang, and W. Zhuang, “E fficient federated meta-learning over multi-access wireless netwo rks,” IEEE J. Sel. Areas Commun. , vol. 40, no. 5, pp. 1556–1570, May 2022
work page 2022
-
[5]
Accelerating DNN training in w ireless federated edge learning systems,
J. Ren, G. Y u, and G. Ding, “Accelerating DNN training in w ireless federated edge learning systems,” IEEE J. Sel. Areas Commun. , vol. 39, no. 1, pp. 219–232, Jan. 2021
work page 2021
-
[6]
Fast-convergent federated learning,
H. T. Nguyen, V . Sehwag, S. Hosseinalipour, C. G. Brinton , M. Chiang, and H. V . Poor, “Fast-convergent federated learning,” IEEE J. Sel. Areas Commun., vol. 39, no. 1, pp. 201–218, Jan. 2021
work page 2021
-
[7]
Hybrid multica st/unicast design in noma-based vehicular caching system,
X. Pei, H. Y u, Y . Chen, M. Wen, and G. Chen, “Hybrid multica st/unicast design in noma-based vehicular caching system,” IEEE Trans. V eh. Technol., vol. 69, no. 12, pp. 16 304–16 308, Dec. 2020
work page 2020
-
[8]
S. Y u, X. Gong, Q. Shi, X. Wang, and X. Chen, “ EC-SAGINs: Ed ge- computing-enhanced space-air-ground-integrated networ ks for Internet of V ehicles,” IEEE Internet Things J. , vol. 9, no. 8, pp. 5742–5754, Dec. 2022
work page 2022
-
[9]
On the maximum achievable sum-rate of the RIS-aided MIMO broad cast channel,
N. S. Perovic, L. Tran, M. D. Renzo, and M. F. Flanagan, “On the maximum achievable sum-rate of the RIS-aided MIMO broad cast channel,” IEEE Trans. Signal Process. , vol. 70, no. 23, pp. 6316–6331, Jan. 2022
work page 2022
-
[10]
Edge artificial in telligence for 6G: Vision, enabling technologies, and applications,
K. B. Letaief, Y . Shi, J. Lu, and J. Lu, “Edge artificial in telligence for 6G: Vision, enabling technologies, and applications,” IEEE J. Sel. Areas Commun., vol. 40, no. 1, pp. 5–36, Jan. 2022
work page 2022
-
[11]
Machin e intelligence at the edge with learning centric power alloca tion,
S. Wang, Y .-C. Wu, M. Xia, R. Wang, and H. V . Poor, “Machin e intelligence at the edge with learning centric power alloca tion,” IEEE Trans. Wireless Commun. , vol. 19, no. 11, pp. 7293–7308, Nov. 2020
work page 2020
-
[12]
Edge learni ng for large-scale Internet of Things with task-oriented efficien t communica- tion,
H. Xie, M. Xia, P . Wu, S. Wang, and H. V . Poor, “Edge learni ng for large-scale Internet of Things with task-oriented efficien t communica- tion,” IEEE Trans. Wireless Commun. , vol. 22, no. 12, pp. 9517–9532, Dec. 2023
work page 2023
-
[13]
Decentraliz ed federated learning with asynchronous parameter sharing fo r large-scale IoT networks,
H. Xie, M. Xia, P . Wu, S. Wang, and K. Huang, “Decentraliz ed federated learning with asynchronous parameter sharing fo r large-scale IoT networks,” IEEE Internet Things J. , vol. 11, no. 21, pp. 34 123– 34 139, 2024
work page 2024
-
[14]
La rge-scale bandwidth and power optimization for multi-modal edge inte lligence autonomous driving,
X. Li, T. Zhang, S. Wang, G. Zhu, R. Wang, and T. Chang, “La rge-scale bandwidth and power optimization for multi-modal edge inte lligence autonomous driving,” IEEE Wirel. Commun. Lett. , vol. 12, no. 6, pp. 1096–1100, Jun. 2023
work page 2023
-
[15]
Learning task-oriented c ommunication for edge inference: An information bottleneck approach,
J. Shao, Y . Mao, and J. Zhang, “Learning task-oriented c ommunication for edge inference: An information bottleneck approach,” IEEE J. Sel. Areas Commun. , vol. 40, no. 1, pp. 197–211, Nov. 2022
work page 2022
-
[16]
Task- oriented sensing, computation, and communication integra tion for multi- device edge AI,
D. Wen, P . Liu, G. Zhu, Y . Shi, J. Xu, Y . C. Eldar, and S. Cui , “Task- oriented sensing, computation, and communication integra tion for multi- device edge AI,” IEEE Trans. Wireless Commun. , vol. 23, no. 3, pp. 2486–2502, Mar. 2024
work page 2024
-
[17]
P . Liu, G. Zhu, S. Wang, W. Jiang, W. Luo, H. V . Poor, and S. Cui, “To- ward ambient intelligence: Federated edge learning with ta sk-oriented sensing, computation, and communication integration,” IEEE J. Sel. Topics Signal Process. , vol. 17, no. 1, pp. 158–172, Jan. 2023
work page 2023
-
[18]
C. Liu, M. Xia, J. Zhao, H. Li, and Y . Gong, “Optimal resou rce allocation for integrated sensing and communications in In ternet of V ehicles: A deep reinforcement learning approach,” IEEE Trans. V eh. Technol., vol. 74, no. 2, pp. 3028–3038, Feb. 2025
work page 2025
-
[19]
Task-oriented multi-user s emantic communications for VQA,
H. Xie, Z. Qin, and G. Y . Li, “Task-oriented multi-user s emantic communications for VQA,” IEEE Wireless Comm. Lett. , vol. 11, no. 3, pp. 553–557, Mar. 2022
work page 2022
-
[20]
Edge intelligence: The confluence of edge computing and art ificial intelligence,
S. Deng, H. Zhao, W. Fang, J. Yin, S. Dustdar, and A. Y . Zom aya, “Edge intelligence: The confluence of edge computing and art ificial intelligence,” IEEE Internet Things J. , vol. 7, no. 8, pp. 7457–7469, Aug. 2020
work page 2020
-
[21]
Importance-aware data selection and resource allocation in federated edge learning system,
Y . He, J. Ren, G. Y u, and J. Y uan, “Importance-aware data selection and resource allocation in federated edge learning system, ” IEEE Trans. V eh. Technol., vol. 69, no. 11, pp. 13 593–13 605, Nov. 2020
work page 2020
-
[22]
Coded computing for low-latency federated learning over wireless edge networks,
S. Prakash, S. Dhakal, M. R. Akdeniz, Y . Y ona, S. Talwar, S. Avestimehr, and N. Himayat, “Coded computing for low-latency federated learning over wireless edge networks,” IEEE J. Sel. Areas Commun. , vol. 39, no. 1, pp. 233–250, Jan. 2021
work page 2021
-
[23]
Federated deep learning meets autonomous vehicle pe rception: Design and verification,
S. Wang, C. Li, D. W. K. Ng, Y . C. Eldar, H. V . Poor, Q. Hao, a nd C. Xu, “Federated deep learning meets autonomous vehicle pe rception: Design and verification,” IEEE Netw. , vol. 37, no. 3, pp. 16–25, May 2023. 16 IEEE TRANSACTIONS ON WIRELESS COMMUNICA TIONS
work page 2023
-
[24]
W. Kou, S. Wang, G. Zhu, B. Luo, Y . Chen, D. W. K. Ng, and Y .- C. Wu, “Communication resources constrained hierarchical federated learning for end-to-end autonomous driving,” in IEEE Int. Conf. Intell. Robot. Syst. (IROS) , Oct. 2023, pp. 9383–9390
work page 2023
-
[25]
C. Qiao, M. Li, Y . Liu, and Z. Tian, “Transitioning from f ederated learning to quantum federated learning in Internet of Thing s: A compre- hensive survey,” IEEE Commun. Surv. Tutor ., vol. 27, no. 1, pp. 509–545, Feb. 2025
work page 2025
-
[26]
DASP: hierarchical offline reinforcement learning via diffusion autodecoder and skil l primitive,
S. Liu, Y . Zhang, W. Chen, and P . Wu, “DASP: hierarchical offline reinforcement learning via diffusion autodecoder and skil l primitive,” IEEE Robotics Autom. Lett. , vol. 10, no. 2, pp. 1649–1655, Dec. 2025
work page 2025
-
[27]
Applications of multi-agent reinforcement learning in fu ture Internet: A comprehensive survey,
T. Li, K. Zhu, N. C. Luong, D. Niyato, Q. Wu, Y . Zhang, and B . Chen, “Applications of multi-agent reinforcement learning in fu ture Internet: A comprehensive survey,” IEEE Commun. Surv. Tutorials , vol. 24, no. 2, pp. 1240–1279, Mar. 2022
work page 2022
-
[28]
J. Zhao, H. Quan, M. Xia, and D. Wang, “Adaptive resource allocation for mobile edge computing in Internet of V ehicles: A deep rei nforcement learning approach,” IEEE Trans. V eh. Technol., vol. 73, no. 4, pp. 5834– 5848, Apr. 2024
work page 2024
-
[29]
Goal-driven autonom ous explo- ration through deep reinforcement learning,
R. Cimurs, I. H. Suh, and J. H. Lee, “Goal-driven autonom ous explo- ration through deep reinforcement learning,” IEEE Robot. Automat. Lett., vol. 7, no. 2, pp. 730–737, Dec. 2022
work page 2022
-
[30]
Optimization m ethods for large- scale machine learning,
L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization m ethods for large- scale machine learning,” SIAM Rev., vol. 60, no. 2, pp. 223–311, May 2018
work page 2018
-
[31]
UGV-assisted wirel ess powered backscatter communications for large-scale IoT networks,
E. Chen, P . Wu, Y .-C. Wu, and M. Xia, “UGV-assisted wirel ess powered backscatter communications for large-scale IoT networks, ” IEEE Trans. Wireless Commun., vol. 21, no. 5, pp. 3147–3161, May 2022
work page 2022
-
[32]
System-level simulation framework for NB-IoT: Key features and performance evaluation,
S. Zhang, W. Wen, P . Wu, H. Huang, L. Zhu, Y . Guo, T. Y ang, a nd M. Xia, “System-level simulation framework for NB-IoT: Key features and performance evaluation,” IEEE Syst. J. , vol. 19, no. 2, pp. 577–588, Jun. 2025
work page 2025
-
[33]
S. Shalev-Shwartz and S. Ben-David, Understanding Machine Learning: From Theory to Algorithms . Cambridge, U.K.: Cambridge University Press, 2014
work page 2014
-
[34]
Bubeck, Convex Optimization: Algorithms and Complexity
S. Bubeck, Convex Optimization: Algorithms and Complexity. Hanover, MA, USA: Now Publishers, 2015
work page 2015
-
[35]
Lipschitz regularity of deep neural net- works: Analysis and efficient estimation,
A. Virmaux and K. Scaman, “Lipschitz regularity of deep neural net- works: Analysis and efficient estimation,” in Proc. Neural Information Processing Systems (NIPS) , Dec. 2018, pp. 3839–3848
work page 2018
-
[36]
On the con vergence of fedavg on non-iid data,
X. Li, K. Huang, W. Y ang, S. Wang, and Z. Zhang, “On the con vergence of fedavg on non-iid data,” in Proc. Int. Conf. Learn. Representations (ICLR), Apr. 2020
work page 2020
-
[37]
A unified alternating d irection method of multipliers by majorization minimization,
C. Lu, J. Feng, S. Y an, and Z. Lin, “A unified alternating d irection method of multipliers by majorization minimization,” IEEE Trans. Pattern Anal. Mach. Intell. , vol. 40, no. 3, pp. 527–541, Mar. 2018
work page 2018
-
[38]
D. R. Hunter and K. Lange, “A tutorial on MM algorithms,” Am. Stat. , vol. 58, no. 1, pp. 30–37, 2004
work page 2004
-
[39]
Nesterov, Introductory Lectures on Convex Optimization: A Basic Course
Y . Nesterov, Introductory Lectures on Convex Optimization: A Basic Course. Boston, MA, USA: Kluwer Academic Publishers, 2004
work page 2004
-
[40]
A fast iterative shrinkage-th resholding algorithm for linear inverse problems,
A. Beck and M. Teboulle, “A fast iterative shrinkage-th resholding algorithm for linear inverse problems,” SIAM J. Imaging Sci. , vol. 2, no. 1, pp. 183–202, 2009
work page 2009
-
[41]
R. Han, S. Wang, S. Wang, Z. Zhang, Q. Zhang, Y . C. Eldar, Q . Hao, and J. Pan, “RDA: An accelerated collision free motion plann er for au- tonomous navigation in cluttered environments,” IEEE Robot. Automat. Lett., vol. 8, no. 3, pp. 1715–1722, Mar. 2023
work page 2023
-
[42]
Z. Ji, Y . Wan, G. Li, S. Wang, K. Y e, D. W. K. Ng, and C. Xu, “Robotic sensor network: Achieving mutual communication c ontrol assistance with fast cross-layer optimization,” IEEE Wireless Commun. Lett., vol. 14, no. 2, pp. 385–389, Feb. 2025. Haihui Xie received the B.S. degree and the M.S. degree in photonic and electronic engineering from Fujian Norm...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.